preface 💨
The text and pictures of this article come from the network, only for learning and communication, and do not have any commercial purpose. If you have any questions, please contact us in time for handling.
Previous content 💨
Introduction to Python crawler 01: Douban Top movie crawling
Introduction to Python crawler 02: novel crawling
Introduction to Python crawler 03: second hand house data crawling
Python crawler tutorial 04: crawling Recruitment Information
Introduction to Python crawler 05: crawling of video barrage at station B
Python crawler tutorial 06: making word cloud after crawling data
Python crawler tutorial 07: Tencent video barrage crawling
Python crawler tutorial 08: crawl csdn articles and save them as PDF
Python crawler tutorial 09: multi thread crawling expression package pictures
Introduction to Python crawler tutorial 10: other bank wallpaper crawling
Introduction to Python crawler tutorial 11: crawling of the new king's glory skin picture
Introduction to Python crawler tutorial 12: crawling of hero League skin pictures
Introduction to Python crawler tutorial 13: high quality computer desktop wallpaper crawling
Python crawler tutorial 14: Audio Book crawling
Introduction to Python crawler tutorial 15: crawling of music website data
Introduction to Python crawler tutorial 17: crawling of music songs
Python crawler tutorial 18: good video crawling
Python crawling tutorial 19: YY short video crawling
Introduction to Python crawler tutorial 20: crawling and using IP proxy
Python crawler tutorial 21: crawling paid documents
Python crawler tutorial 22: Baidu translation JS decryption
Python crawler tutorial 24: download a website paid document and save PDF
Python crawler tutorial 26: Kwai Kong video website data content download
PS: if you need Python learning materials and answers, you can click the link below to get them by yourself
python free learning materials and group communication solutions. Click to join
Basic development environment 💨
- Python 3.6
- Pycharm
Use of related modules 💨
import csv import requests
Install Python and add it to the environment variable. pip can install the relevant modules required.
💥 Demand data source analysis
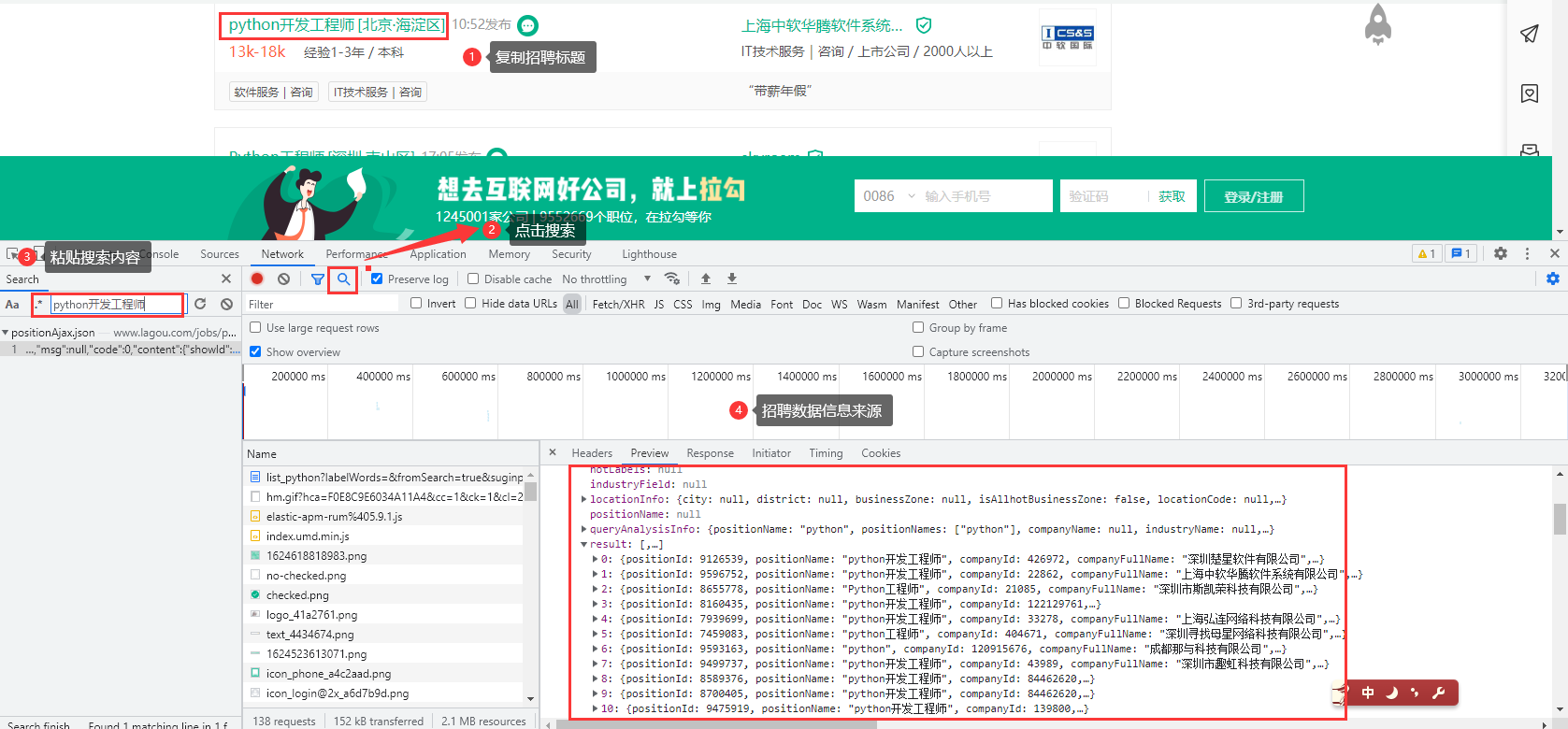
Through the developer tool, you can check the url address and request method of the request after you know where the data can be obtained after packet capture analysis
💥 code implementation
import csv
import requests
f = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'title',
'city',
'Company name',
'education',
'experience',
'salary',
'Company benefits',
'Detail page',
])
csv_writer.writeheader()
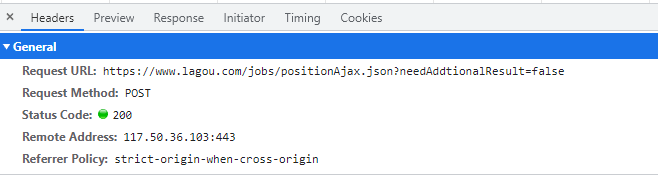
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
data = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
headers = {
'cookie': 'cookie',
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
response = requests.post(url=url, data=data, headers=headers)
result = response.json()['content']['positionResult']['result']
for index in result:
# pprint.pprint(index)
title = index['positionName'] # title
city = index['city'] # city
area = index['district'] # region
city_area = city + '-' + area
company_name = index['companyFullName'] # Company name
edu = index['education'] # education
money = index['salary'] # salary
exp = index['workYear'] # experience
boon = index['positionAdvantage'] # Company benefits
href = f'https://www.lagou.com/jobs/{index["positionId"]}.html'
job_info = index['positionDetail'].replace('<br>\n', '').replace('<br>', '')
dit = {
'title': title,
'city': city_area,
'Company name': company_name,
'education': edu,
'experience': exp,
'salary': money,
'Company benefits': boon,
'Detail page': href,
}
csv_writer.writerow(dit)
txt_name = company_name + '-' + title + '.txt'
with open(txt_name, mode='w', encoding='utf-8') as f:
f.write(job_info)
print(dit)
💥 Crawling data display