🌹 preface
Bloggers have started to update the actual combat tutorial of crawler. We look forward to your attention!!!
Part I: Python crawler actual combat (I): turn the page and crawl the data into SqlServer
Part II: Python crawler practice (2): crawling cache proxy to build proxy IP pool
Like collection bloggers have more creative power, and they will often be more creative in the future!!!

Purpose of building IP pool
When using crawlers, most websites have certain anti crawling measures. Some websites will limit the access speed or access times of each IP. If you exceed its limit, your IP will be blocked. The processing of access speed is relatively simple. It only needs to crawl once at an interval to avoid frequent access; For the number of visits, you need to use proxy IP to help. Using multiple proxy IP to access the target website in turn can effectively solve the problem.
At present, there are many agency service websites on the Internet to provide agency services and some free agents, but the availability is poor. If the demand is high, you can buy paid agents with good availability. Of course, we can also build our own proxy pool, obtain proxy IP for free from various proxy service websites, test its availability (visit Baidu), save it to a file, and call it when necessary.

Climb target
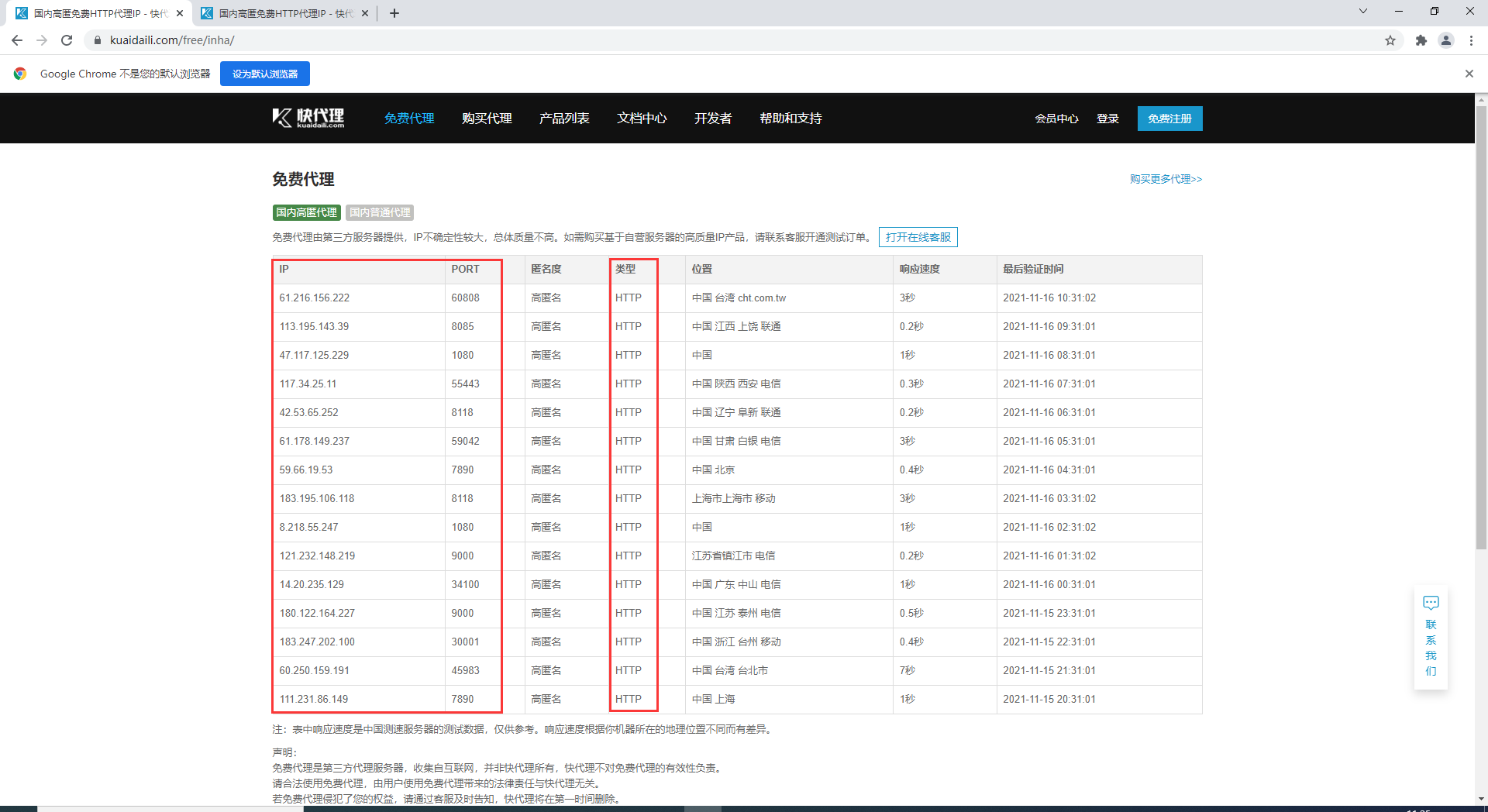
The page we want to climb is: https://www.kuaidaili.com/free/inha/
The red box is what we want to climb:
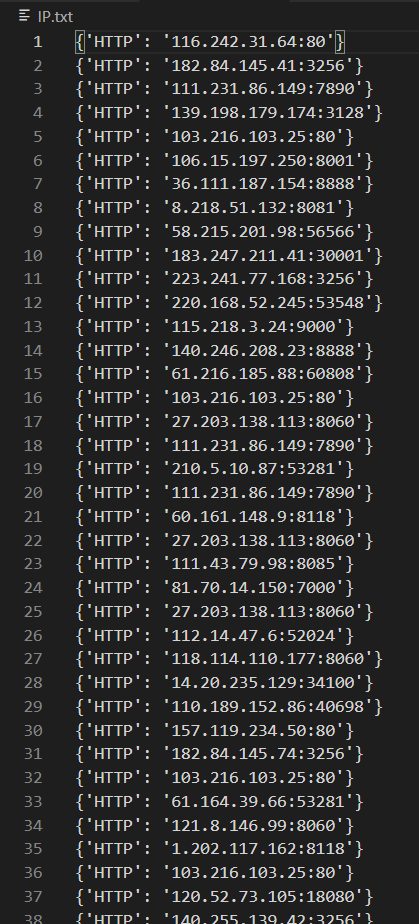
The final effect of blogger crawling is as follows:
preparation
I use Python 3.8, VScode editor, and the required libraries are: requests, etree, and time
Libraries required for import at the beginning:
import requests # python basic crawler Library from lxml import etree # You can convert a web page to an Elements object import time # Prevent climbing too fast and sleep for one second
Ready to start code analysis!
code analysis

First, let's talk about my overall idea of gradual analysis:
- Step 1: construct the homepage url address, send the request and get the response
- Step 2: analyze the data and group the data
- Step 3: extract the data of the array
- Step 4: check the availability of proxy IP
- Step 5: save to file
First step
Construct the url address of the home page and send the request to get the response
# 1. Send request and get response
def send_request(self,page):
print("=============Grabbing page{}page===========".format(page))
# Target page, add headers parameter
base_url = 'https://www.kuaidaili.com/free/inha/{}/'.format(page)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
# Send request: simulate the browser to send a request and obtain the response data
response = requests.get(base_url,headers=headers)
data = response.content.decode()
time.sleep(1)
return data
There will be little friends who don't understand. What do you mean by headers?
- Prevent the server from recognizing us as crawlers, so simulate the browser header information and send messages to the server
- This "installation" must be installed!!!

Step 2
Analyze the data and group the data
As can be seen from the figure below, all the data we need are in the tr tag:

Therefore, the grouping is taken under the tr tag:
# 2. Analyze data
def parse_data(self,data):
# data conversion
html_data = etree.HTML(data)
# Grouping data
parse_list = html_data.xpath('//table[@class="table table-bordered table-striped"]/tbody/tr')
return parse_list
Step 3
Extract the data, IP, type and port number we need in the packet
parse_list = self.parse_data(data)
for tr in parse_list:
proxies_dict = {}
http_type = tr.xpath('./td[4]/text()')
ip_num = tr.xpath('./td[1]/text()')
port_num = tr.xpath('./td[2]/text()')
http_type = ' '.join(http_type)
ip_num = ' '.join(ip_num)
port_num = ' '.join(port_num)
proxies_dict[http_type] = ip_num + ":" + port_num
proxies_list.append(proxies_dict)
Spliced here, {'HTTP':'36.111.187.154:8888 '} This form is stored in the list for our convenience!

Step 4
Check the availability of IP. Because it is a free IP, some may not work, and some access speed is slow. Here, we let the spliced IP access a certain degree for 0.1 seconds, and successfully save it in another list!
def check_ip(self,proxies_list):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
can_use = []
for proxies in proxies_list:
try:
response = requests.get('https://www.baidu.com/',headers=headers,proxies=proxies,timeout=0.1)
if response.status_code == 200:
can_use.append(proxies)
except Exception as e:
print(e)
return can_use

Step 5
Save the ip with good access speed in a file for us to call
def save(self,can_use):
file = open('IP.txt', 'w')
for i in range(len(can_use)):
s = str(can_use[i])+ '\n'
file.write(s)
file.close()
Complete code
import requests
from lxml import etree
import time
class daili:
# 1. Send request and get response
def send_request(self,page):
print("=============Grabbing page{}page===========".format(page))
# Target page, add headers parameter
base_url = 'https://www.kuaidaili.com/free/inha/{}/'.format(page)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
# Send request: simulate the browser to send a request and obtain the response data
response = requests.get(base_url,headers=headers)
data = response.content.decode()
time.sleep(1)
return data
# 2. Analyze data
def parse_data(self,data):
# data conversion
html_data = etree.HTML(data)
# Grouping data
parse_list = html_data.xpath('//table[@class="table table-bordered table-striped"]/tbody/tr')
return parse_list
# 4. Detect proxy IP
def check_ip(self,proxies_list):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
can_use = []
for proxies in proxies_list:
try:
response = requests.get('https://www.baidu.com/',headers=headers,proxies=proxies,timeout=0.1)
if response.status_code == 200:
can_use.append(proxies)
except Exception as e:
print(e)
return can_use
# 5. Save to file
def save(self,can_use):
file = open('IP.txt', 'w')
for i in range(len(can_use)):
s = str(can_use[i])+ '\n'
file.write(s)
file.close()
# Implement main logic
def run(self):
proxies_list = []
# To turn the page, I only crawled four pages here (the number of 5 can be modified)
for page in range(1,5):
data = self.send_request(page)
parse_list = self.parse_data(data)
# 3. Obtain data
for tr in parse_list:
proxies_dict = {}
http_type = tr.xpath('./td[4]/text()')
ip_num = tr.xpath('./td[1]/text()')
port_num = tr.xpath('./td[2]/text()')
http_type = ' '.join(http_type)
ip_num = ' '.join(ip_num)
port_num = ' '.join(port_num)
proxies_dict[http_type] = ip_num + ":" + port_num
proxies_list.append(proxies_dict)
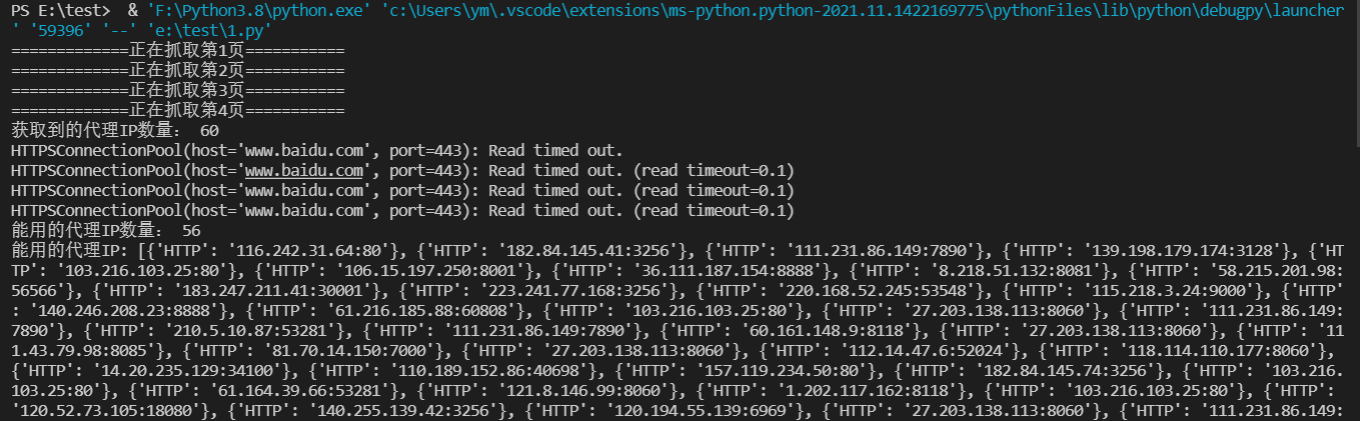
print("Obtained proxy IP number:",len(proxies_list))
can_use = self.check_ip(proxies_list)
print("Available agents IP number:",len(can_use))
print("Available agents IP:",can_use)
self.save(can_use)
if __name__ == "__main__":
dl = daili()
dl.run()
The effects after startup are as follows:
And generate files:
O o!!!

usage method
IP is saved in the file, but some small partners don't know how to use it?
Here we need to realize that we randomly take an IP from the file to access the web address, and use the random library
import random
import requests
# Open file, wrap read
f=open("IP.txt","r")
file = f.readlines()
# Traverse and store them in the list respectively to facilitate random selection of IP addresses
item = []
for proxies in file:
proxies = eval(proxies.replace('\n','')) # Split with newline character and convert to dict object
item.append(proxies)
proxies = random.choice(item) # Select an IP at random
url = 'https://www.baidu.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
response = requests.get(url,headers=headers,proxies=proxies)
print(response.status_code) # The output status code 200 indicates that the access is successful
There is something wrong, I hope you guys can correct it!!!, If you don't understand, leave a message in the comment area and reply! Brothers, give a praise collection and update the actual battle of crawler when you are free!!!
