Unlogged Pictures on American Airlines Network--Brief Introduction
The last article has been written for a long time. Next, I will continue to finish the crawler of American Airlines. The crawler in this set of tutorials may not add much valuable technical points to your actual work, because it is only a set of introductory tutorials, you can automatically bypass the old bird, or take me with you.
The Unlogged Picture of American Air Network--Crawler Analysis
First of all, we have crawled to more than N users'personal homepages, which I got through link splicing.
http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/list.html
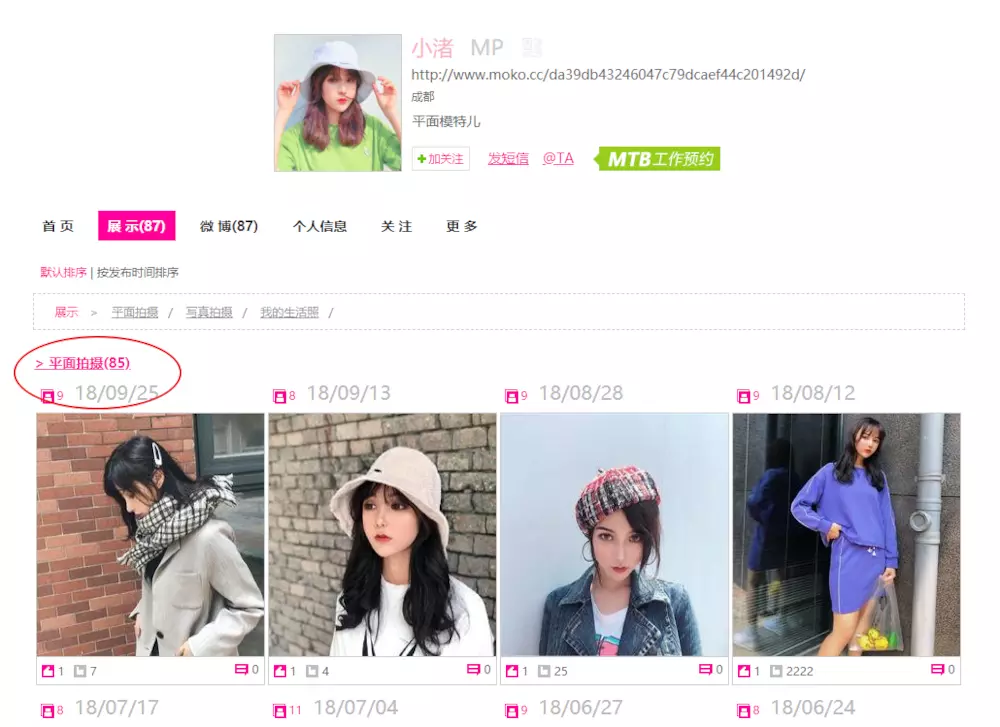
In this page, we need to find several key points, we found that the plane photography click into the picture list page. Next, start the code.
Get all list pages
I got 70,000 user data (50,000 +) from my last blog and read it into python.
This place, I used a better python library pandas, if you are not familiar with, you can imitate my code first, I write the comments are complete.
import pandas as pd # User Picture List Page Template user_list_url = "http://www.moko.cc/post/{}/list.html" # Store list pages for all users user_profiles = [] def read_data(): # pandas reads data from csv df = pd.read_csv("./moko70000.csv") #Files can be downloaded at the end of this article # Remove duplicate nickname data df = df.drop_duplicates(["nikename"]) # Decline the order according to the number of fans profiles = df.sort_values("follows", ascending=False)["profile"] for i in profiles: # Stitching links user_profiles.append(user_list_url.format(i)) if __name__ == '__main__': read_data() print(user_profiles) Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
The data is already available. Next, we need to get the picture list page, find out the rules, and see the key information as follows. Finding the right place is the matter of regular expressions.
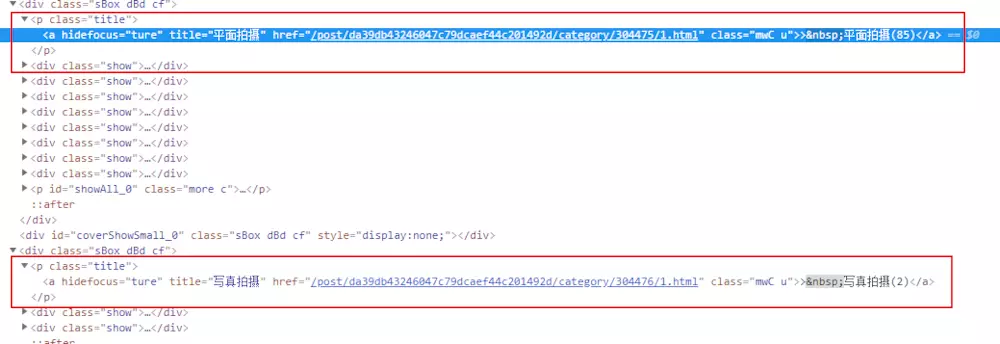
Write a regular expression quickly <p class="title"><a hidefocus="ture".*?href="(.*?)" class="mwC u">.*?\((\d+?)\)</a></p>
Introducing re,requests module
import requests import re
# Get the picture list page def get_img_list_page(): # Fixed an address for easy testing test_url = "http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/list.html" response = requests.get(test_url,headers=headers,timeout=3) page_text = response.text pattern = re.compile('<p class="title"><a hidefocus="ture".*?href="(.*?)" class="mwC u">.*?\((\d+?)\)</a></p>') # Get page_list page_list = pattern.findall(page_text)
Operational results
[('/post/da39db43246047c79dcaef44c201492d/category/304475/1.html', '85'), ('/post/da39db43246047c79dcaef44c201492d/category/304476/1.html', '2'), ('/post/da39db43246047c79dcaef44c201492d/category/304473/1.html', '0')]
Continue to improve the code, we found that the data obtained above, there is a "0" generation, need to filter out.
# Get the picture list page def get_img_list_page(): # Fixed an address for easy testing test_url = "http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/list.html" response = requests.get(test_url,headers=headers,timeout=3) page_text = response.text pattern = re.compile('<p class="title"><a hidefocus="ture".*?href="(.*?)" class="mwC u">.*?\((\d+?)\)</a></p>') # Get page_list page_list = pattern.findall(page_text) # Filtering data for page in page_list: if page[1] == '0': page_list.remove(page) print(page_list)
To get the entrance to the list page, we need to get all the list pages below. This place needs to click on the link below to see.
http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/1.html
This page has four pages, each page shows data 4*7=28. So the basic formula is math.ceil(85/28) Next, the links are generated. We need to convert the above links into
http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/1.html http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/2.html http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/3.html http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/4.html
page_count = math.ceil(int(totle)/28)+1 for i in range(1,page_count): # Regular expression substitution pages = re.sub(r'\d+?\.html',str(i)+".html",start_page) all_pages.append(base_url.format(pages))
When we go back to enough links, for beginners, you can do this step first, and store these links in a csv file for subsequent development.
# Get all the pages def get_all_list_page(start_page,totle): page_count = math.ceil(int(totle)/28)+1 for i in range(1,page_count): pages = re.sub(r'\d+?\.html',str(i)+".html",start_page) all_pages.append(base_url.format(pages)) print("Acquired{}Bar data".format(len(all_pages))) if(len(all_pages)>1000): pd.DataFrame(all_pages).to_csv("./pages.csv",mode="a+") all_pages.clear()
Let the crawler fly for a while. I got 80,000 + pieces of data here.

Okay, there's the list data. Next, let's continue to work on this data. Does it feel a bit slow and the code is a bit LOW? Okay, I admit that it's actually lazy for novice writers. I'll go back and change it to object-oriented and multi-threaded in an article.

Next, we will analyze it again based on the crawled data.
for example http://www.moko.cc/post/nimusi/category/31793/1.html In this page, we need to get the address of the red box, why or this? Because clicking on this image and entering it is the complete picture list.
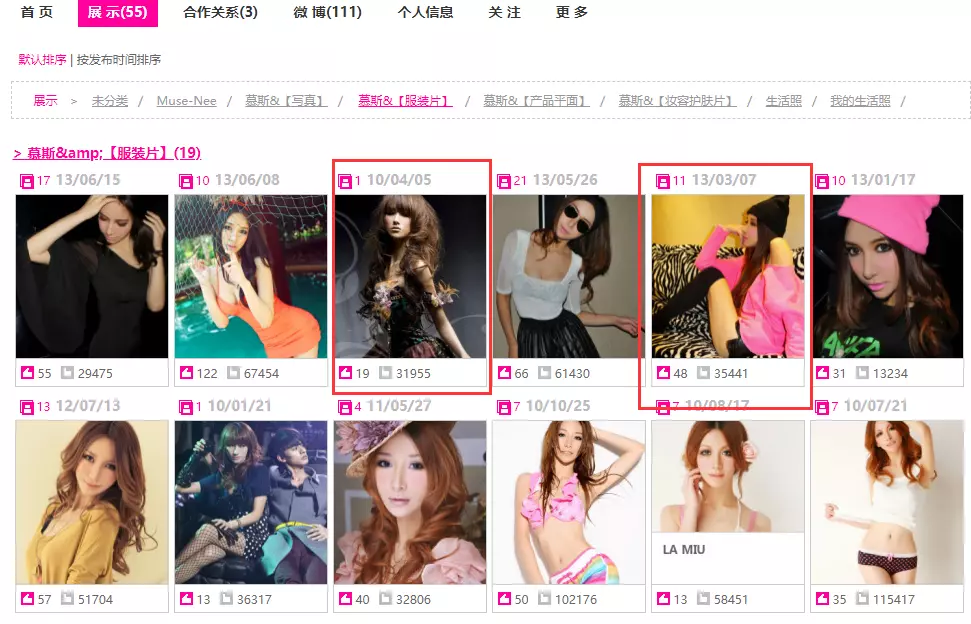
We're still using crawlers to get it. Several steps
- Loop through the list of data we just had
- Crawl Web Source
- Regular expressions match all links
def read_list_data(): # Read data img_list = pd.read_csv("./pages.csv",names=["no","url"])["url"] # Cyclic operation data for img_list_page in img_list: try: response = requests.get(img_list_page,headers=headers,timeout=3) except Exception as e: print(e) continue # Regular Expressions Get Picture List Pages pattern = re.compile('<a hidefocus="ture" alt="(.*?)".*? href="(.*?)".*?>VIEW MORE</a>') img_box = pattern.findall(response.text) need_links = [] # Picture folders to be crawled for img in img_box: need_links.append(img) # Create directories file_path = "./downs/{}".format(str(img[0]).replace('/', '')) if not os.path.exists(file_path): os.mkdir(file_path) # Create directories for need in need_links: # Get Details Page Picture Links get_my_imgs(base_url.format(need[1]), need[0])
Several key points of the above code
pattern = re.compile('<a hidefocus="ture" alt="(.*?)".*? href="(.*?)".*?>VIEW MORE</a>') img_box = pattern.findall(response.text) need_links = [] # Picture folders to be crawled for img in img_box: need_links.append(img)
Get the crawl directory, where I matched two parts, mainly for creating folders To create folders, you need to use the os module. Remember to import it.
# Create directories file_path = "./downs/{}".format(str(img[0]).replace('/', '')) if not os.path.exists(file_path): os.mkdir(file_path) # Create directories
After getting the picture links on the details page, grab all the picture links in one visit
#Get Details Page Data def get_my_imgs(img,title): print(img) headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"} response = requests.get(img, headers=headers, timeout=3) pattern = re.compile('<img src2="(.*?)".*?>') all_imgs = pattern.findall(response.text) for download_img in all_imgs: downs_imgs(download_img,title)
Finally, write a method of downloading pictures, all the code is completed, the pictures save the local address, using a timestamp.
def downs_imgs(img,title): headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"} response = requests.get(img,headers=headers,timeout=3) content = response.content file_name = str(int(time.time()))+".jpg" file = "./downs/{}/{}".format(str(title).replace('/','').strip(),file_name) with open(file,"wb+") as f: f.write(content) print("Complete") Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
Run the code, wait for the drawing
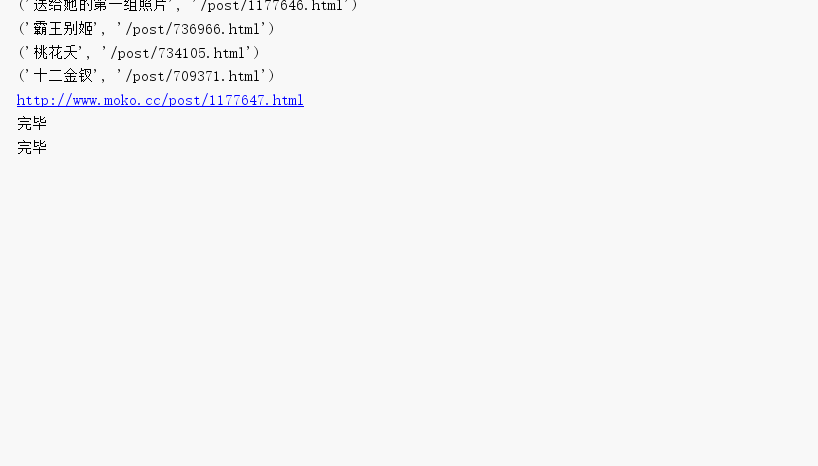
The code runs and finds an error.

The reason is the problem of the path. There is a special character in the path. We need to deal with it in a similar way. Take care of it yourself.
Data acquisition, that's what it looks like.
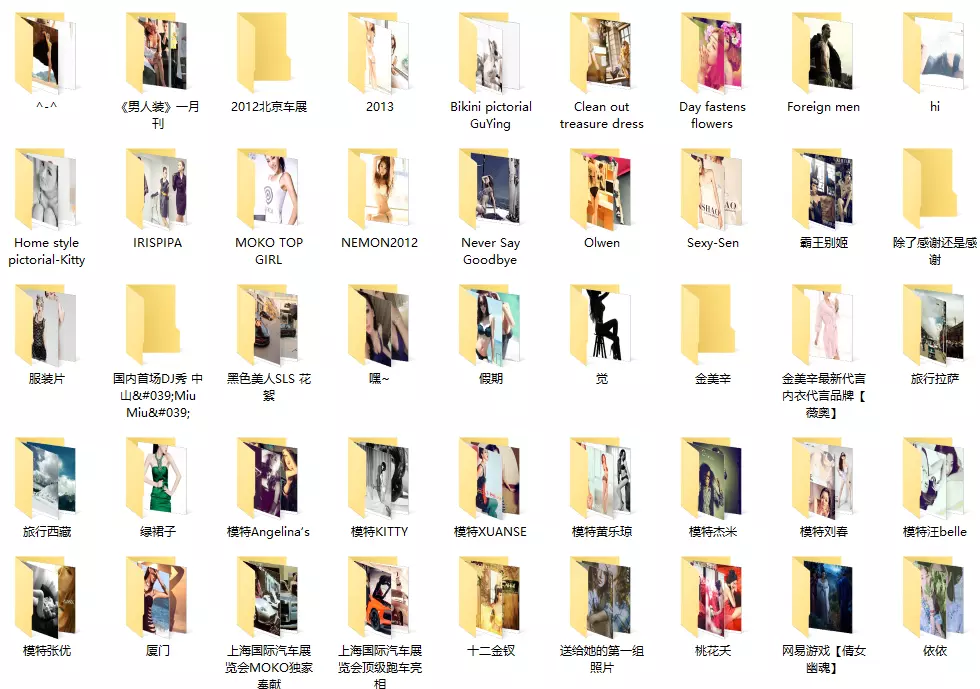
What needs to be perfected in the code
- The code is divided into two parts and process-oriented. It's very bad and needs improvement.
- There is too much duplicate code in the part of network request, which needs abstraction and error handling. At present, it is possible to report errors.
- Code single-threaded, inefficient, can be improved with reference to the previous two articles
- Without analog login, only 6 pictures can be crawled, which is why the data is saved first to facilitate later direct transformation.