Written in front
For a crawler enthusiast, there is more or less a little bit of collecting addiction - finding good pictures, finding good books, finding all kinds of things that can be stored on the computer, all like to crawl it down in batches. And then, yeah, that's it. Then slowly forget it.

Crawler analysis
Open the website http://www.allitebooks.com/and find a small page that is particularly clear. It's easy to crawl at a glance.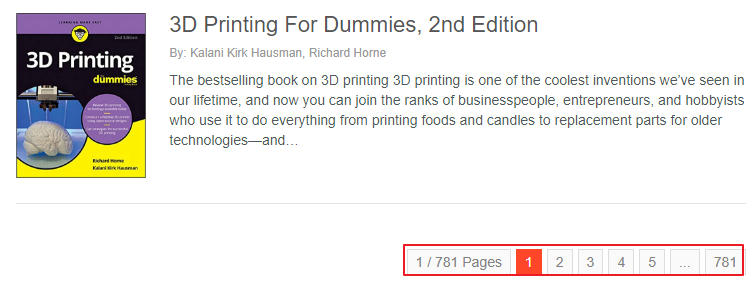
In clicking on a book to enter, we found that the downloaded links were also clearly displayed in front of us, a little excitement, such a clear and ad-free website is rare.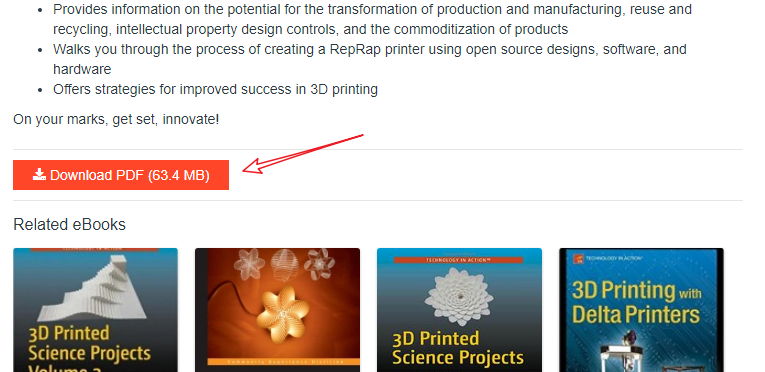
Bar code
This time I used a new module, requests-html, which was developed by the author of this module. You should be familiar with queue in thread control.
Install requests-html module
pip install requests-html
For the use of this module, you only need to search the name of this module by using search engine, and there are many drops of this article. As you can learn this blog, it is very simple to pull 65507
Let's write the core content.
from requests_html import HTMLSession from queue import Queue import requests import random import threading CARWL_EXIT = False DOWN_EXIT = False ##### # Other code #### if __name__ == '__main__': page_queue = Queue(5) for i in range(1,6): page_queue.put(i) # Store the page number in page_queue # Collection results data_queue = Queue() # Record Thread List thread_crawl = [] # Open 5 threads at a time craw_list = ["Acquisition Thread 1","Acquisition Thread 2","Acquisition Thread 3","Acquisition Thread 4","Acquisition Thread 5"] for thread_name in craw_list: c_thread = ThreadCrawl(thread_name,page_queue,data_queue) c_thread.start() thread_crawl.append(c_thread) while not page_queue.empty(): pass # If page_queue is empty, the collection thread exits the loop CARWL_EXIT = True for thread in thread_crawl: thread.join() print("Grab thread termination")
The above is the thread to crawl the book details page. I opened five threads to crawl, and the page number only crawled five pages. If you need more, you just need to modify it.
page_queue = Queue(5) for i in range(1,6): page_queue.put(i) # Store the page number in page_queue
Now let's write the ThreadCrawl class.
session = HTMLSession() # This place is User_Agents. After I configure it on the server, I can get a lot of items from this list remotely. Go to the source code and find them yourself. USER_AGENTS = [ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20" ] # Thread class to get book download links class ThreadCrawl(threading.Thread): # Constructor def __init__(self,thread_name,page_queue,data_queue): super(ThreadCrawl,self).__init__() self.thread_name = thread_name self.page_queue = page_queue self.data_queue = data_queue self.page_url = "http://www.allitebooks.com/page/{}" #URL splicing template def run(self): print(self.thread_name+" start-up*********") while not CARWL_EXIT: try: page = self.page_queue.get(block=False) page_url = self.page_url.format(page) # Splicing URL operations self.get_list(page_url) # Analysis page links except Exception as e: print(e) break # Get links to all books on the current list page def get_list(self,url): try: response = session.get(url) except Exception as e: print(e) raise e all_link = response.html.find('.entry-title>a') # Get links to all book details on the page for link in all_link: self.get_book_url(link.attrs['href']) # Get Book Links # Get Book Download Links def get_book_url(self,url): try: response = session.get(url) except Exception as e: print(e) raise e download_url = response.html.find('.download-links a', first=True) if download_url is not None: # If the download link exists, continue the following crawl link = download_url.attrs['href'] self.data_queue.put(link) # Store the book download address in data_queue for subsequent Downloads print("Grab to{}".format(link))
A very important part of the above code is to store download links of books in data_queue, which is the most basic data in another download thread.
Now we begin to write the classes and methods of book download.
I opened four threads, and the operation was very similar to that above.
class ThreadDown(threading.Thread): def __init__(self, thread_name, data_queue): super(ThreadDown, self).__init__() self.thread_name = thread_name self.data_queue = data_queue def run(self): print(self.thread_name + ' start-up************') while not DOWN_EXIT: try: book_link = self.data_queue.get(block=False) self.download(book_link) except Exception as e: pass def download(self,url): # Random Browser User-Agent headers = {"User-Agent":random.choice(USER_AGENTS)} # Get the file name filename = url.split('/')[-1] # If the url contains pdf if '.pdf' in url or '.epub' in url: file = 'book/'+filename # The file path has been written to death. Please create a book folder first with the directory. with open(file,'wb') as f: # Begin binary file writing print("Downloading {}".format(filename)) response = requests.get(url,stream=True,headers=headers) # Get file size totle_length = response.headers.get("content-length") # If the file size does not exist, the returned text is written directly if totle_length is None: f.write(response.content) else: for data in response.iter_content(chunk_size=4096): f.write(data) else: f.close() print("{}Download complete".format(filename)) if __name__ == '__main__': # Other code is on it. thread_image = [] image_list = ['Download Thread 1', 'Download Thread 2', 'Download Thread 3', 'Download Thread 4'] for thread_name in image_list: d_thread = ThreadDown(thread_name, data_queue) d_thread.start() thread_image.append(d_thread) while not data_queue.empty(): pass DOWN_EXIT = True for thread in thread_image: thread.join() print("End of download thread")
If you have combined all the above codes, you should be able to quickly crawl books, of course, these books are in English, download them, can you read them? I don't know.
Source download address, go to the last blog to find ~~
