This article deals with knowledge:
1. Basic Use of request Third Party Library
2. json analysis
The objectives of this article are:
Crawl popular reviews of all songs that specify a song list
(Note: This article does not directly parse html text, but directly analyze the api to get comments, so as to get the corresponding json return. Then, parse json to get the required information.)
Trampling records:
1. The newline symbol "" causes some unknown problems. Use carefully the newline symbol ""
Analysis api
- First of all, we use the browser to open the web version of Netease Cloud Music, enter a song list casually, click into the page of a song, you can see the comments below. Then F12 enters the developer console (review elements).
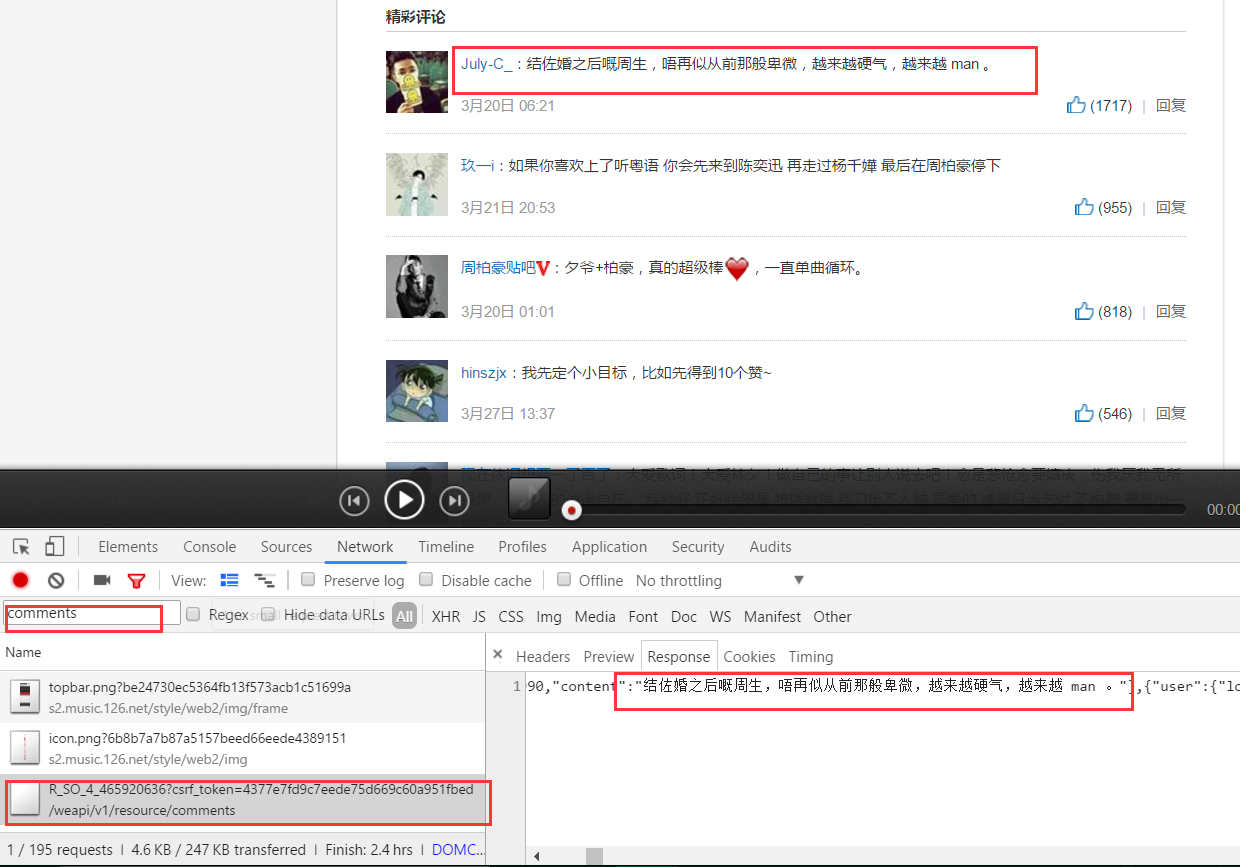
We enter comments in the search box to find the url of the corresponding api to get comments, and click on it to select Response on the right to see the returned json.
So our idea is clear. We just need to analyze the api and simulate sending requests, and get json for parsing. Right-click to copy the url.
http://music.163.com/weapi/v1/resource/comments/R_SO_4_465920636?csrf_token=4377e7fd9c7eede75d669c60a951fbed
From the browser's address, you can find that the number after R_SO_4_in the url above is the id of the song, as shown below:
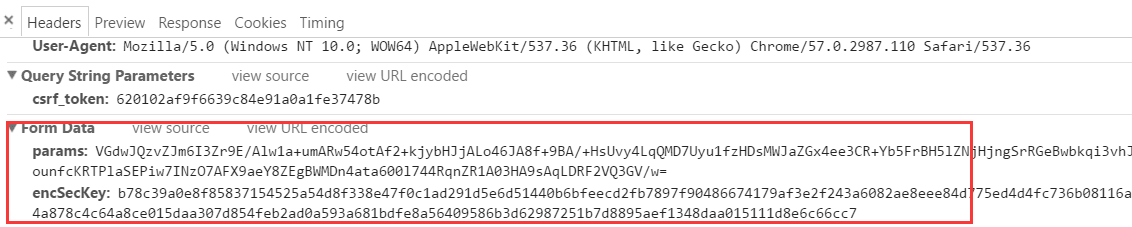
After testing, the latter csrf_tocken can also be used for other songs. In the developer console, click on headers to see that the request is post, and the form data in the request header has two encrypted parameters (params and encSecKey). But it doesn't matter. After testing, these two parameters can also be used for other songs. Just copy them directly. But only on the first page, the other pages are different, but for us to crawl popular reviews, the first page is enough.

Send a request to get json
Based on the analysis in the last section, we can write the following code to get json:
import requests import json url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_465920636?csrf_token=c0f6bfdcd0526ec0ba6c207051a08960' param={'params':'wxLqdGgw16OHb6UwY/sW16VtLqAhGaDMeI2F4DaESDplHA+CPsscI4mgiKoVCPuWW8lcd9eY0YWR/iai0sJqs0NmtLubVCkGdpN\ TN3mLhevZpdZy/XM1+z7L18InFz5HbbRkq230i0aOco/3jVsMWcD3/tzzOCLkGuu5xdbo99aUjDxHwDSVfu4pz4spV2KonJ47Rt6vJhOorV7LfpIVmP/qe\ ZghfaXXuKO2chlqU54=',\ 'encSecKey':'12d3a1e221cd845231abdc0c29040e9c74a47ee32eb332a1850b6e19ff1f30218eb9e2d6d9a72bd797f75\ fa115b769ad580fc51128cc9993e51276043ccbd9ca4e1f589a2ec479ab0323c973e7f7b1fe1a7cd0a02ababe2adecadd4ac93d09744be0deafd1eef\ 0cfbc79903216b1b71a82f9698eea0f0dc594f1269b419393c0'}#The \"at the end of each line here is too long to be used for line breaking. Use it carefully. There are many lines breaking, which are prone to bug s. r=requests.post(url, param) data=r.text#What data gets is json print data
Running the output to see if the json was successfully captured. Here is the use of requests for reference requests Quick Start.
Parse json for output
We can copy json from the browser's developer console to one Online json verification formatting tool In this way, we can see the structure of json clearly, which is helpful for us to analyze. As shown in the figure:
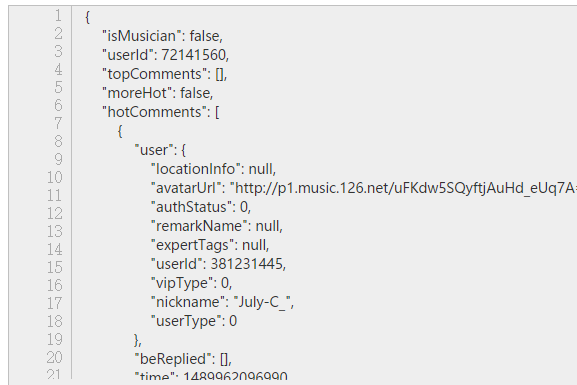
This JSON has a wealth of information, including the total number of comments, user names, reviews, comments and so on. With a clear understanding of the structure of json, it is easy to parse the desired information. JSON parsing needs to be introduced into JSON package. Knowing JSON parsing can be referred to. Parsing json in detail using python . The correspondence between json type and python type is very clear, just using dict and list. The parsing code is as follows:
import requests import json url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_465920636?csrf_token=c0f6bfdcd0526ec0ba6c207051a08960' param={'params':'wxLqdGgw16OHb6UwY/sW16VtLqAhGaDMeI2F4DaESDplHA+CPsscI4mgiKoVCPuWW8lcd9eY0YWR/iai0sJqs0NmtLubVCkGdpN\ TN3mLhevZpdZy/XM1+z7L18InFz5HbbRkq230i0aOco/3jVsMWcD3/tzzOCLkGuu5xdbo99aUjDxHwDSVfu4pz4spV2KonJ47Rt6vJhOorV7LfpIVmP/qe\ ZghfaXXuKO2chlqU54=',\ 'encSecKey':'12d3a1e221cd845231abdc0c29040e9c74a47ee32eb332a1850b6e19ff1f30218eb9e2d6d9a72bd797f75\ fa115b769ad580fc51128cc9993e51276043ccbd9ca4e1f589a2ec479ab0323c973e7f7b1fe1a7cd0a02ababe2adecadd4ac93d09744be0deafd1eef\ 0cfbc79903216b1b71a82f9698eea0f0dc594f1269b419393c0'}#The "at the end of each line here is too long to wrap. r=requests.post(url, param) data=r.text jsob=json.loads(data)#Load the acquired json data to obtain the json object hotComments=jsob['hotComments'] for i in range(len(hotComments)): user_nickname=hotComments[i]['user']['nickname'] likedCount=hotComments[i]['likedCount'] content=hotComments[i]['content'] print u'comment'+str(i+1)+u' User name:'+user_nickname+u" like:"+str(likedCount) print '------------------------------------------------------------------' print content print '------------------------------------------------------------------' print '\n'
Output results:
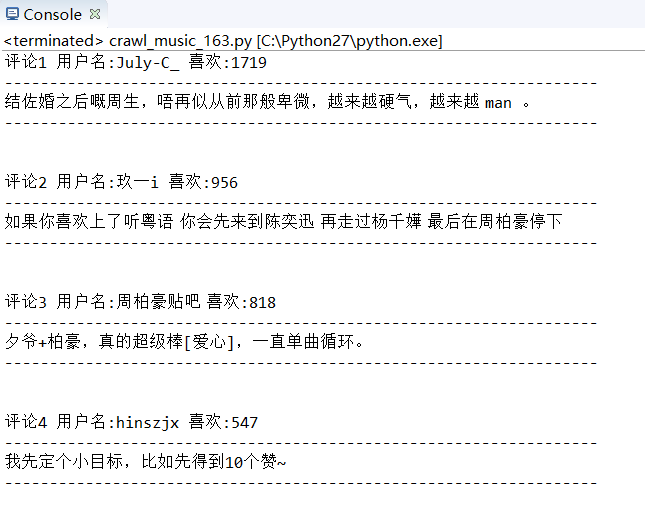
Crawl through a list of popular reviews of all songs
The above has shown how to crawl the popular reviews of a song, and then we can further crawl out the popular reviews of all the songs in a song list.
The id ea is to crawl out the IDs of all the songs in this song list, replace them with the url before, and then output the same.
In the same way, we send url access requests for song sheets and read the response's return to see what happens.
url='http://music.163.com/playlist?id=700734626' r=requests.get(url) print r.text
Output:

You can see that there is a json in the label textarea in the first line. We can locate the label with xpath, get the json and parse it. Before that, you can copy it to the online validation tool to see the structure as before.

We do have the data we need, and then we can parse it.
Here we write in an object-oriented style. The complete code is as follows:
import requests import json from lxml import html class CrawlMusic163: #Get json to parse out all song objects and return to the list of songs def getSongs(self,id):#The id here is the id of the song list. url='http://music.163.com/playlist?id='+str(id) r=requests.get(url) tree=html.fromstring(r.text) data_json=tree.xpath('//textarea[@style="display:none;"]')[0].text songs=json.loads(data_json) return songs #Get a list of popular reviews for each song def getHotComments(self,id):#The id here is the id of the song. url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_'+str(id)+'?csrf_token=c0f6bfdcd0526ec0ba6c207051a08960' param={'params':'wxLqdGgw16OHb6UwY/sW16VtLqAhGaDMeI2F4DaESDplHA+CPsscI4mgiKoVCPuWW8lcd9eY0YWR/iai0sJqs0NmtLubVCkG\ dpNTN3mLhevZpdZy/XM1+z7L18InFz5HbbRkq230i0aOco/3jVsMWcD3/tzzOCLkGuu5xdbo99aUjDxHwDSVfu4pz4spV2KonJ47Rt6vJhOorV7LfpIVmP/qeZghfaXXuKO2chlqU54=',\ 'encSecKey':'12d3a1e221cd845231abdc0c29040e9c74a47ee32eb332a1850b6e19ff1f30218eb9e2d6d9a72bd797f75fa115b769ad580fc51128cc9993e51276043ccbd9ca4e1f589a2ec479ab0323c973e7f7b1fe1a7cd0a02ababe2adecadd4ac93d09744be0deafd1eef0cfbc79903216b1b71a82f9698eea0f0dc594f1269b419393c0'} r =requests.post(url,param) data=r.text jsob=json.loads(data)#Load the acquired json data to obtain the json object hotComments=jsob['hotComments'] return hotComments crawl_music_163=CrawlMusic163() songs=crawl_music_163.getSongs(700734626)#700734626 is the id of a song list, which can be obtained at the end of the url after entering the song list in the web version. for song in songs: hotComments=crawl_music_163.getHotComments(song['id'])#Get a list of popular reviews for the song by id #Singer's Name - Song Name - Number of Popular Comments for Each Song Output print song['artists'][0]['name']+"-"+song['name']+u"-Popular Comments:"+str(len(hotComments)) print '########################################################################' #Each song circles out all the hot Reviews for i in range(len(hotComments)): user_nickname=hotComments[i]['user']['nickname'] likedCount=hotComments[i]['likedCount'] content=hotComments[i]['content'] print u'comment'+str(i+1)+u' User name:'+user_nickname+u" like:"+str(likedCount) print '------------------------------------------------------------------' print content print '------------------------------------------------------------------' print '\n' print '########################################################################'
Output results show:

(Note: There is a hollow pit here. Because param is too long, I use several "symbols to change lines at the end. It's no problem to change two lines as above code. But as long as I change lines in the line of encSecKey parameter, there will be a bug. I can't get the json text alive or dead. After many tests, it is true that the "" symbol causes the param to fail to pass in the post correctly, resulting in the inability to obtain the json text. At present, it is not clear why, so we should use this change carefully.
Reference:
requests Quick Start
Parsing json in detail using python
Python crawls millions of eCloud music reviews