One: Target Site Information
Desktop on the other side The web address is: Desktop Wallpaper PC Desktop Wallpaper HD Wallpaper Download Desktop Background Picture On the Other Desktop
2: Target Site Analysis
(1): Construct a list of URL s for a page
What we need to do is crawl pictures of a given number of pages on the site, so first we need to look at the relationships between the links on each page and construct a list of URLs that need to crawl pages.
Links on the first page: http://www.netbian.com/ Links on page 2: http://www.netbian.com/index_2.htm
As you can see, page links from the beginning of the second page are just different numbers, so we can write a simple code to get a list of URLs for the page
# Initialized list of page links
page_links_list=['http://www.netbian.com/']
#Get the number of pages crawled and page links
pages = int(input('Enter the number of pages you want to crawl:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
print(page_links_list)Please enter the number of pages you want to crawl:5 ['http://www.netbian.com/', 'http://www.netbian.com/index_2.htm', 'http://www.netbian.com/index_3.htm', 'http://www.netbian.com/index_4.htm', 'http://www.netbian.com/index_5.htm']
(2): Get links to all pictures on a page
We've got links to all the pages, but we haven't got links to every picture, so what we need to do next is get links to all the pictures on one page. Here, let's take the first page as an example and get a link to each picture. Other pages are similar.
First right-click on the page - > View the element, then click the small cursor on the left side of the viewer, and then place the mouse over any picture, so that you can locate the code location of the picture. We know that there are 18 pictures on each page. Next, we need to use tags to locate the exact location of the pictures on the page. As shown in the image below, we used div.list li a img to locate exactly 18 img tags. The img tag contains the image links we need.
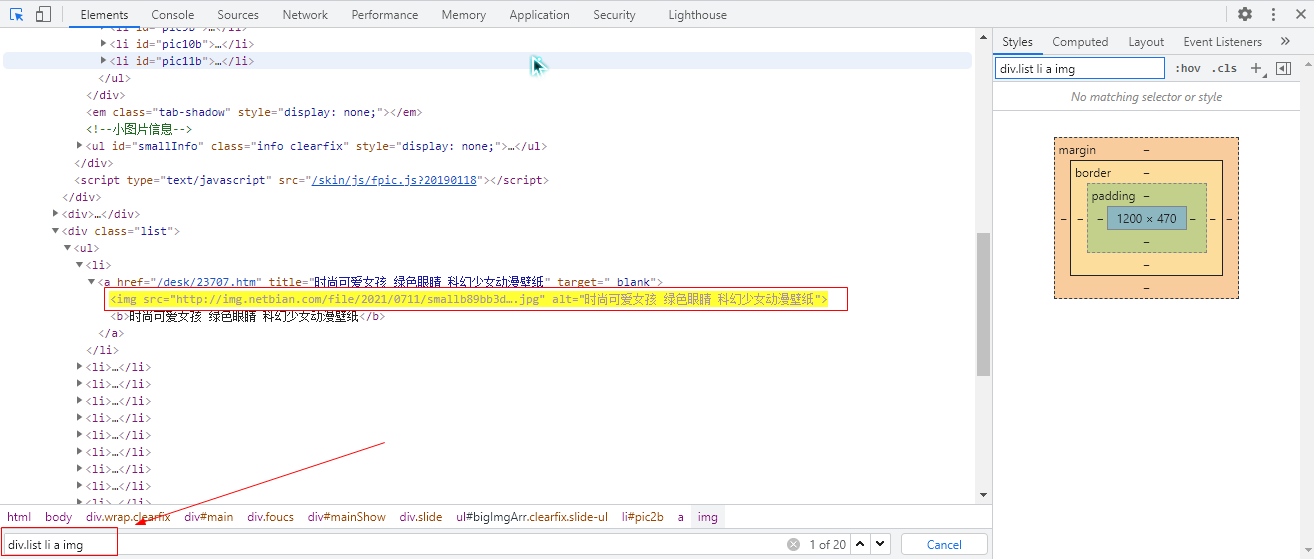
Next, let's take the first page as an example to get a link to each picture.
#python3 -m pip install bs4
#python3 -m pip install lxml
import requests
from bs4 import BeautifulSoup
# Initialized list of page links
url='http://www.netbian.com/'
# Picture Link List
img_links_list = []
#Get img tags, get links to pictures
html = requests.get(url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
print(img_links_list)
print(len(img_links_list))['http://img.netbian.com/file/2019/0817/smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg', 'http://img.netbian.com/file/2019/0817/small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg', 'http://img.netbian.com/file/2018/1225/604a688cd6f79161236e6250189bc25b.jpg', 'http://img.netbian.com/file/2019/0817/smallab7249d18e67c9336109e3bedc094f381566034907.jpg', 'http://img.netbian.com/file/2019/0817/small5816e940e6957f7db5e499de9978bda41566031298.jpg', 'http://img.netbian.com/file/2019/0817/smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg', 'http://img.netbian.com/file/2019/0817/small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg', 'http://img.netbian.com/file/2019/0817/smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg', 'http://img.netbian.com/file/2019/0817/smalld1f07e215f0da059b44d27623ec6fa8f1566029835.jpg', 'http://img.netbian.com/file/2019/0817/small1674b7b97714672be3165bd31de418eb1566014363.jpg', 'http://img.netbian.com/file/2019/0814/small1a5c2fe49dec02929f219d0bdb680e9c1565786931.jpg', 'http://img.netbian.com/file/2019/0814/smalle333c0a8e9fe18324d793ce7258abbbf1565786718.jpg', 'http://img.netbian.com/file/2019/0814/smallb0c9494b4042ac9c9d25b6e4243facfd1565786402.jpg', 'http://img.netbian.com/file/2019/0814/small19dfd078dd820bb1598129bbe4542eff1565786204.jpg', 'http://img.netbian.com/file/2019/0808/smallea41cb48c796ffd3020514994fc3e8391565274057.jpg', 'http://img.netbian.com/file/2019/0808/small3998c40805ea6811d81b7c57d8d235fc1565273792.jpg', 'http://img.netbian.com/file/2019/0808/smallb505448b1318dbb2820dcb212eb39e191565273639.jpg', 'http://img.netbian.com/file/2019/0808/small0f04af422502a40b6c8dc19d53d1f3481565273554.jpg'] 18
(3): Download pictures locally
With the link to the picture, we need to download the picture locally. Here we will download the first picture as an example
url: http://img.netbian.com/file/2019/0817/smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
import urllib.request url='http://img.netbian.com/file/2019/0817/smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg' urllib.request.urlretrieve(url, filename='test.jpg')
(4): A simple crawler to get pictures
Combine the above three sections to construct a url list of pages, get links to all pictures on a page, and download pictures locally. Construct a complete but inefficient crawl.
import requests
from bs4 import BeautifulSoup
import lxml
import urllib
import os
import time
#Get pictures and download them locally
def GetImages(url):
html=requests.get(url, timeout = 2).content.decode('gbk')
soup=BeautifulSoup(html,'lxml')
imgs=soup.select("div.list li a img")
for img in imgs:
link=img['src']
display=link.split('/')[-1]
print('Downloading:',display)
filename='./images/'+display
urllib.request.urlretrieve(link,filename)
#Get the number of pages crawled, return the number of links
def GetUrls(page_links_list):
pages = int(input('Enter the number of pages you want to crawl:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
if __name__ == '__main__':
page_links_list=['http://www.netbian.com/']
GetUrls(page_links_list)
os.mkdir('./images')
print("Start downloading pictures!!!")
start = time.time()
for url in page_links_list:
GetImages(url)
print('Picture download successful!!!')
end = time.time() - start
print('The time consumed is:', end)Please enter the number of pages you want to crawl:5 Start downloading pictures!!! Downloading: smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg Downloading: small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg Downloading: 604 a688cd6f79161236e6250189bc25b.jpg Downloading: smallab7249d18e67c9336109e3bedc094f381566034907.jpg Downloading: small5816e940e6957f7db5e499de9978bda41566031298.jpg Downloading: smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg Downloading: small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg Downloading: smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg . . . . . . Picture download successful!!! Time consumed is: 21.575999975204468
This part of the code above can run completely, but it is not efficient because you need a queue to download pictures. So to solve this problem, the code below uses multithreading to crawl and download pictures.
(5) Use Python multithreading to crawl pictures and download them locally
Multithreaded We use the threading module that comes with Python. And we've used a model called Producer and Consumer, where producers store download links to get pictures from each page in a global list. Consumers download images specifically from this global list.
It is important to note that global variables are used in multiple threads with locks to ensure data consistency.
import urllib
import threading
from bs4 import BeautifulSoup
import requests
import os
import time
import lxml
# Initialized list of page links
page_links_list=['http://www.netbian.com/']
# Picture Link List
img_links_list = []
#Get the number of pages crawled and page links
def GetUrls(page_links_list):
pages = int(input('Enter the number of pages you want to crawl:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
#Initialize lock, create a lock
gLock=threading.Lock()
#Producer, responsible for getting links to pictures from each page
class Producer(threading.Thread):
def run(self):
while len(page_links_list)>0:
#Uplock
gLock.acquire()
#The last element in the list is removed by default
page_url=page_links_list.pop()
#Release lock
gLock.release()
#Get img Tags
html = requests.get(page_url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
#Lock 3
gLock.acquire()
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
#Release lock
gLock.release()
#print(len(img_links_list))
#Consumer, responsible for downloading pictures from the obtained picture link
class Consumer(threading.Thread,):
def run(self):
print("%s is running"%threading.current_thread())
while True:
#print(len(img_links_list))
#Uplock
gLock.acquire()
if len(img_links_list)==0:
#In any case, release the lock
gLock.release()
continue
else:
img_url=img_links_list.pop()
#print(img_links_list)
gLock.release()
filename=img_url.split('/')[-1]
print('Downloading:', filename)
path = './images/'+filename
urllib.request.urlretrieve(img_url, filename=path)
if len(img_links_list)==0:
end=time.time()
print("The time consumed is:", (end - start))
exit()
if __name__ == '__main__':
GetUrls(page_links_list)
os.mkdir('./images')
start=time.time()
# 5 producer threads to crawl image links from the page
for x in range(5):
Producer().start()
# 10 consumer threads to extract download links from and download
for x in range(10):
Consumer().start()Please enter the number of pages you want to crawl:5 <Consumer(Thread-6, started 5764)> is running <Consumer(Thread-7, started 9632)> is running <Consumer(Thread-8, started 9788)> is running <Consumer(Thread-9, started 5468)> is running <Consumer(Thread-10, started 9832)> is running <Consumer(Thread-11, started 3320)> is running <Consumer(Thread-12, started 6456)> is running <Consumer(Thread-13, started 10080)> is running <Consumer(Thread-14, started 3876)> is running <Consumer(Thread-15, started 9224)> is running Downloading: small9e75d6ac9506efe1d87e96062791fb261564149099.jpg Downloading: small02961cac5e02a901b77779eaed43c6f91564156941.jpg Downloading: small117c84b2f427c981bf33184c1c5c4bb91564193581.jpg Downloading: smallfedb420af6f753512c169021587982621564455847.jpg Downloading: small14d3739bf11dd92055abb56e3f792d3f1564456102.jpg Downloading: smallaf755644af7d114d4cbf36fbe0e84d0c1564456347.jpg Downloading: small9f7af6d0e2372a4d9e536d8ea9fc40341564456537.jpg . . . . . . Time consumed is:1.635000228881836 #10 process end times Time consumed is:1.6419999599456787 Time consumed is:1.6560001373291016 Time consumed is:1.684000015258789 Time consumed is:1.7009999752044678 Time consumed is:1.7030000686645508 Time consumed is:1.7060000896453857 Time consumed is:1.7139999866485596 Time consumed is:1.7350001335144043 Time consumed is:1.748000144958496