Scrapy redis distributed crawler
introduce
By using the set of redis, the request queue and items queue can be realized, and by using the set of redis, the request can be de duplicated, so that the scale of crawler cluster can be realized
Scratch redis is a scratch component based on redis
• distributed Crawlers
Multiple crawler instances share a redis request queue, which is very suitable for large-scale and multi domain crawler clusters
• distributed post-processing
The items captured by the crawler are pushed to a redis items queue, which means that multiple items processes can be opened to process the captured data, such as storage in Mongodb and Mysql
• based on the scratch plug and play component
Scheduler + Duplication Filter, Item Pipeline, Base Spiders.Sketch redis architecture
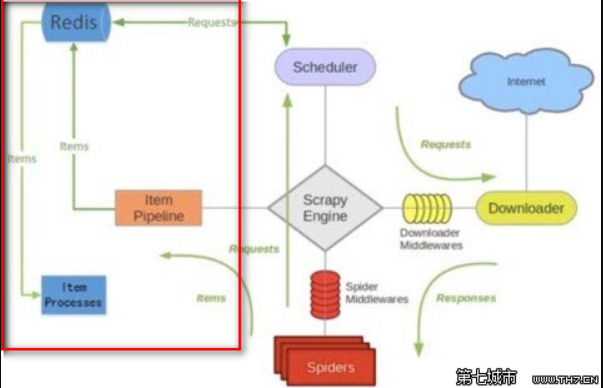
• scheduler
By virtue of the set non repetition feature of redis, the schedule redis scheduler implements the Duplication Filter de duplication (the DupeFilter set stores the crawled request s). For the newly generated request of Spider, the fingerprint of the request will be sent to the DupeFilter set of redis to check whether it is repeated, and the non repeated request will be pushed to the request queue of redis. The scheduler sends a request from the request queue of redis according to the priority pop, and sends the request to the spider for processing.
• Item Pipeline
Give the item crawled by Spider to the Item Pipeline of the summary redis, and store the crawled item into the items queue of redis. It is very convenient to extract items from the items queue to implement the items processes cluster
Summary - redis installation and use
Install the story redis
It has been installed before, so it is directly installed here
pip install scrapy-redis
Use the example of story redis to modify
First get the example of the story redis from github, and then move the example project directory to the specified address
git clone https://github.com/rolando/scrapy-redis.git cp -r scrapy-redis/example-project ./scrapy-youyuan
Or download the whole project back to scratch-redis-master.zip and unzip it
cp -r scrapy-redis-master/example-project/ ./redis-youyuan cd redis-youyuan/
tree view project directory

Modify settings.py
Note: the Chinese Notes in the settings will report an error and change to English
# Specify the Scheduler that uses the scrape redis
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# In redis, keep the queues used by scrape redis, so as to allow pause and resume after pause
SCHEDULER_PERSIST = True
# Specifies the queue to be used when sorting crawling addresses. The default is to sort by priority
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# Optional FIFO sorting
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderQueue'
# Optional LIFO sort
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderStack'
# Only when SpiderQueue or SpiderStack is used is a valid parameter, which specifies the maximum idle time when the crawler is closed
SCHEDULER_IDLE_BEFORE_CLOSE = 10
# Specify RedisPipeline to save item s in redis
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400
}
# Specify the connection parameters of redis
# REDIS_PASS is the redis connection password added by myself. You need to simply modify the source code of the story redis to support password connection to redis
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
# Custom redis client parameters (i.e.: socket timeout, etc.)
REDIS_PARAMS = {}
#REDIS_URL = 'redis://user:pass@hostname:9001'
#REDIS_PARAMS['password'] = 'itcast.cn'
LOG_LEVEL = 'DEBUG'
DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter'
#The class used to detect and filter duplicate requests.
#The default (RFPDupeFilter) filters based on request fingerprint using the scrapy.utils.request.request_fingerprint function. In order to change the way duplicates are checked you could subclass RFPDupeFilter and override its request_fingerprint method. This method should accept scrapy Request object and return its fingerprint (a string).
#By default, RFPDupeFilter only logs the first duplicate request. Setting DUPEFILTER_DEBUG to True will make it log all duplicate requests.
DUPEFILTER_DEBUG =True
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Accept-Encoding': 'gzip, deflate, sdch',
}View pipeline.py
from datetime import datetime
class ExamplePipeline(object):
def process_item(self, item, spider):
item["crawled"] = datetime.utcnow()
item["spider"] = spider.name
return itemTechnological process
- Concept: multiple computer components can be used for a distributed cluster to execute the same set of programs and jointly crawl the same set of network resources.
- Native scrapy Is not distributed
- Scheduler cannot be shared
- Pipeline cannot be shared
- Be based on scrapy+redis(scrapy&scrapy-redis Components) to achieve distributed
- scrapy-redis Function of components:
- Provide pipelines and schedulers that can be shared
- Environment installation:
- pip install scrapy-redis
- Coding process:
1.Create project
2.cd proName
3.Establish crawlspider Crawler files for
4.Modify the reptile class:
- Guide Kit: from scrapy_redis.spiders import RedisCrawlSpider
- Modify the parent of the current reptile class: RedisCrawlSpider
- allowed_domains and start_urls delete
- Add a new property: redis_key = 'xxxx'The name of the scheduler queue that can be shared
5.Modify configuration settings.py
- Designated pipe
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
- Specify scheduler
# The configuration of a de duplication container class is added to store the fingerprint data of the request by using the set set set of Redis, so as to realize the persistence of the request de duplication
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Using the schedule redis component's own scheduler
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Configure whether the scheduler should be persistent, that is, when the crawler is finished, whether to clear the request queue and the set of de fingerprinting in Redis. If it is True, it means that to persist storage, data will not be emptied, otherwise, data will be emptied
SCHEDULER_PERSIST = True
- Appoint redis data base
REDIS_HOST = 'redis Service ip address'
REDIS_PORT = 6379
6.To configure redis Database ( redis.windows.conf)
- Turn off default binding
- 56Line: #bind 127.0.0.1
- Turn off protection mode
- 75line: protected-mode no
7.start-up redis Service (with profile) and client
- redis-server.exe redis.windows.conf
- redis-cli
8.Execution Engineering
- scrapy runspider spider.py
9.Will start url Still queued to a scheduler that can be shared( sun)in
- stay redis-cli Medium operation: lpush sun www.xxx.com
10.redis:
- xxx:items:The stored data is the crawled dataDistributed crawling case
Crawler program
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
from fbs.items import FbsproItem
class FbsSpider(RedisCrawlSpider):
name = 'fbs_obj'
# allowed_domains = ['www.xxx.com']
# start_urls = ['http://www.xxx.com/']
redis_key = 'sun'#The name of the scheduler queue that can be shared
link = LinkExtractor(allow=r'type=4&page=\d+')
rules = (
Rule(link, callback='parse_item', follow=True),
)
print(123)
def parse_item(self, response):
tr_list = response.xpath('//*[@id="morelist"]/div/table[2]//tr/td/table//tr')
for tr in tr_list:
title = tr.xpath('./td[2]/a[2]/@title').extract_first()
status = tr.xpath('./td[3]/span/text()').extract_first()
item = FbsproItem()
item['title'] = title
item['status'] = status
print(title)
yield item
settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for fbsPro project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'fbs_obj'
SPIDER_MODULES = ['fbs_obj.spiders']
NEWSPIDER_MODULE = 'fbs_obj.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'fbsPro (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 2
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'fbsPro.middlewares.FbsproSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'fbsPro.middlewares.FbsproDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'fbsPro.pipelines.FbsproPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
#Designated pipe
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
#Specify scheduler
# The configuration of a de duplication container class is added to store the fingerprint data of the request by using the set set set of Redis, so as to realize the persistence of the request de duplication
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Using the schedule redis component's own scheduler
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Configure whether the scheduler should be persistent, that is, when the crawler is finished, whether to clear the request queue and the set of de fingerprinting in Redis. If it is True, it means that to persist storage, data will not be emptied, otherwise, data will be emptied
SCHEDULER_PERSIST = True
#Specify redis
REDIS_HOST = '192.168.16.119'
REDIS_PORT = 6379item.py
import scrapy
class FbsproItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
status = scrapy.Field()