Articles Catalogue
Preface
When doing crawling, first of all, we need to understand the structure of the crawling webpage and the steps needed to reach the destination download address. Then we can get the desired data through our own ideas to combine crawling.
Knowledge content
- Understanding the simple use of python's Beautiful Soup Library
- Understanding the requests Library in python
- If you want to make your own image storage address, you also need to understand the Path-Related usage of os libraries in python
- Understanding python's file reading and writing
Dead work
- The page for the selected image is "https://www.meizitu.com/a/5110.html".
- Write code IDE for Pycharm
start
1. Browser opens destination page and F12 Analysis page structure
Open the Sister Map interface as follows: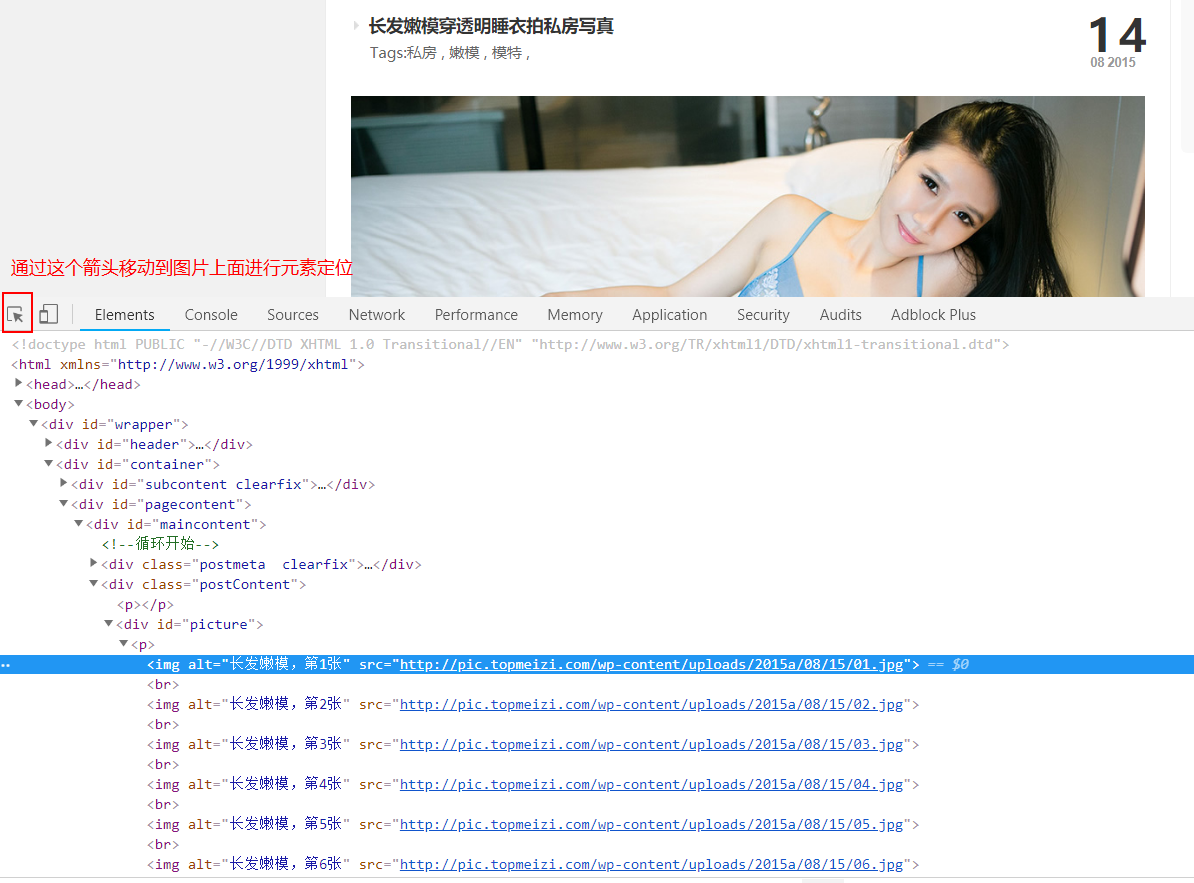
1. We select the "Elements" tab and find that all the pictures on the page are under a p tag under a div tag.
As you can see from the graph, the div has an attribute, id="picture"
2. What we want is the uri address of every picture, so we have to find a way to extract the src attribute from all img tags under the p tag.
The analysis of the structure of the web page was completed, so we got two information we wanted.
- The image address we need is in the first **< div id= "picture"> **
- We need to get the src attribute of the img tag
So take the second step and grab the page elements.
2. Crawling page elements through Beautiful Soup
Through a simple study of the Beautiful Soup Library in python, we will use find and find_all in its powerful functions. It is a good habit to get object types through type(target), so that we can easily know what kind of objects to get.
- Find: Get the first matching that meets the criteria. For example, if there are many < div id= "picture"> tags in a page, then using find can only get the content of the first < div id= "picture"> tag in the current page, and the rest, although qualified, will not be recognized.
- find_all: Gets all matches that meet the criteria, just the opposite of find. It can get and identify all matches that meet the criteria < div id= "picture">
So we need to do the following to find the div in the page and then go to the download address after src
# Define the header header to inform the server that the request was initiated by an actual browser
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 "
"Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3588.400"
}
url = "https://www.meizitu.com/a/5110.html"
# Getting Web Content by get Method
rq = requests.get(url=url, headers=headers)
# Construct a Beautiful Soup strength (equivalent to a container), receive text content captured by get, and specify the way to analyze the page as lxml
soup = BeautifulSoup(rq.text, "lxml")
# Through page analysis, we use find to find the destination div
target = soup.find("div", id="picture")
# Through page analysis, after finding div, we need to find all IMGs under the p tag to get the src attributes under the img.
src = soup.find("div", id="picture").find_all("img")["src"]
You can get the download address of the picture by using the code above.
Note: Using type() method, we can know the type of variable, which is convenient for us to choose reasonable value (attribute value).
3. Save pictures
After getting the image address, all we have to do is download the image and save it to our local disk, so we make the following assumptions:
1. Save the picture address as "D Crawl_pictures"
2. The name of the picture we save is two random numbers.
Based on our assumptions above, we have the following code to implement:
import os import string import random # url variable store image storage directory url = "D\\Crawl_pictures" # Define two random numbers random_digit = "".join(random.simple(string.digits, 2))
When we have fulfilled our assumptions, all our preparations have been completed, so now save our pictures.
url = "D\\Crawl_pictures" random_digit = "".join(random.simple(string.digits, 2)) # Visit the picture address, which is obtained in step 2 of src here picture_content = requests.get(url=src, headers=headers) with open(url + os.sep + "%d.png" % random_digit, "wb") as p: p.write(picture_content.content)
At this point, the picture is in storage, as in the previous tutorial, you download a picture. The following is the code to crawl all the pictures on the current page:
from bs4 import BeautifulSoup
import requests
import os
import random
import string
class CrawlPicture:
base_url = "https://www.meizitu.com/a/5{}.html"
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 "
"Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3588.400"
}
save_path = "D:\\Crawl_Pictures"
def get_pic_url(self):
url_list = []
# Climb two pages
for k in range(113, 115):
page_info = requests.get(url=self.base_url.format(k), headers=self.header)
soup = BeautifulSoup(page_info.text, "lxml")
for i in range(len(soup.find('div', id="picture").find_all('img'))):
picture_url = soup.find('div', id="picture").find_all('img')[i]['src']
url_list.append(picture_url)
return url_list
def save_picture(self):
picture_name = "".join(random.sample(string.digits, 2))
for j in range(len(self.get_pic_url())):
picture = requests.get(url=self.get_pic_url()[j], headers=self.header)
with open(self.save_path + os.sep + "%d.png" % picture_name, "wb") as f:
f.write(picture.content)
if __name__ == '__main__':
CrawlPicture().save_picture()