Scratch is an application framework for crawling website data and extracting structural data. More details about the use of the framework can be found in the official documents. This article shows the general implementation process of crawling cartoon pictures.
Scrapy environment configuration
The first is the installation of scratch. The blogger uses the Mac system and runs the command line directly:
pip install Scrapy
For the extraction of html node information, the Beautiful Soup library is used. For the approximate usage, see the previous article. Install directly through the command:
pip install beautifulsoup4
The html5lib interpreter is required for the initialization of the Beautiful Soup object of the target web page. The command to install is as follows:
pip install html5lib
After installation, run the command directly on the command line:
scrapy
You can see the following output results. At this time, it is proved that the scratch installation is complete.
Scrapy 1.2.1 - no active project Usage: scrapy <command> [options] [args] Available commands: bench Run quick benchmark test commands fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values ...
Project creation
Create a project named Comics in the current path through the command line
scrapy startproject Comics
After creation, the corresponding project folder appears in the current directory. You can see that the generated Comics file structure is:
|____Comics | |______init__.py | |______pycache__ | |____items.py | |____pipelines.py | |____settings.py | |____spiders | | |______init__.py | | |______pycache__ |____scrapy.cfg
Ps. the command to print the current file structure is:
find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'
The specific functions corresponding to each file can refer to the official documents. This implementation does not involve many of these files, so the following table is not available.
1, Create Spider class
Create a class to implement the specific crawling function. All our processing implementations will be implemented in this class. It must be scrapy.Spider Subclass of.
Create in Comics/spiders file path comics.py Documents.
comics.py Specific implementation of:
#coding:utf-8 import scrapy class Comics(scrapy.Spider): name = "comics" def start_requests(self): urls = ['http://www.xeall.com/shenshi'] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): self.log(response.body);
The custom class is scrapy.Spider The name attribute is the unique identifier of the crawler, which is the parameter of the crawl command. The properties of other methods will be explained later.
2. Operation
After creating the custom class, switch to Comics path, run the command, start the crawler task and start crawling the web page.
scrapy crawl comics
The result of printing is the information in the process of running the crawler, and the html source code of the target crawling web page.
2016-11-26 22:04:35 [scrapy] INFO: Scrapy 1.2.1 started (bot: Comics) 2016-11-26 22:04:35 [scrapy] INFO: Overridden settings: {'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'Comics', 'NEWSPIDER_MODULE': 'Comics.spiders', 'SPIDER_MODULES': ['Comics.spiders']} 2016-11-26 22:04:35 [scrapy] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.logstats.LogStats'] ...
At this point, a basic crawler is created. The following is the implementation of the specific process.
Crawling cartoon pictures
1. Starting address
The starting address of the crawler is:
Our main focus is on the comic list in the middle of the page. There are controls showing the number of pages under the list. As shown in the figure below
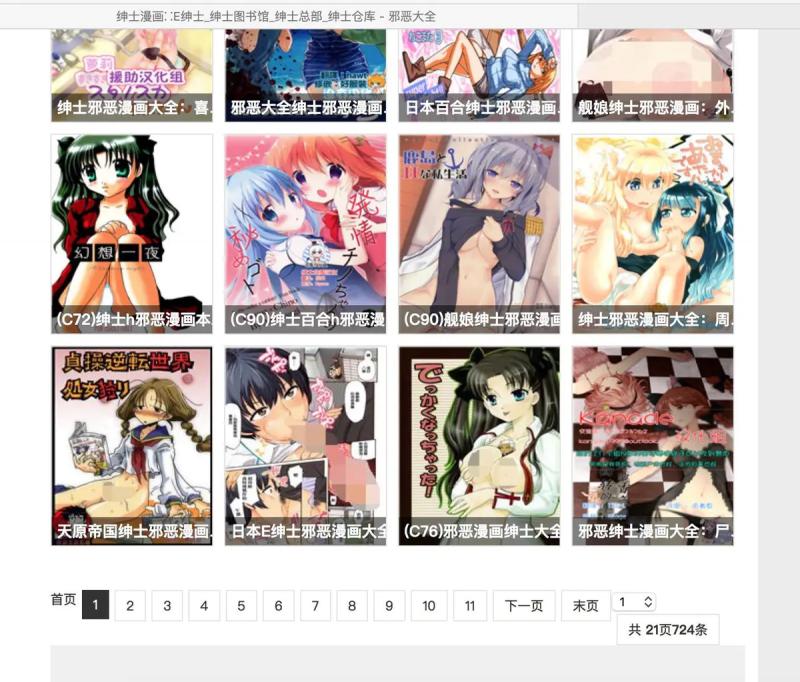
The main task of the crawler is to crawl the pictures of each comic in the list. After crawling the current page, enter the next page of the comic list to continue crawling the comic, and continue to cycle until all comic crawling is completed.
The url of the starting address is in start_ In the urls array of the requests function. Where start_requests is a method that overloads the parent class, which is executed at the beginning of the crawler task.
start_ The main implementation of the requests method is in this line of code: the requested url is specified, and the corresponding callback function is invoked after the request is completed. self.parse
scrapy.Request(url=url, callback=self.parse)
There is actually another way to implement the previous code:
#coding:utf-8 import scrapy class Comics(scrapy.Spider): name = "comics" start_urls = ['http://www.xeall.com/shenshi'] def parse(self, response): self.log(response.body);
start_urls are the properties provided in the framework. For an array containing the url of the target web page, start is set_ After the value of URLs, start does not need to be overloaded_ Requests method, and the crawler will crawl start in turn_ URLs and automatically call parse as the callback method after the request is completed.
However, in order to call other callback functions conveniently in the process, the former implementation method is used in demo.
2. Crawl the comic url
From the start page, first we need to crawl to the url of each cartoon.
Current page comic list
The starting page is the first page of the comic list. We need to extract the required information from the current page, and use the callback parse method.
Import the beautifulsop library at the beginning
from bs4 import BeautifulSoup
The html source code returned by the request is used to initialize beautifulsop.
def parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
Initialization specifies the html5lib interpreter. If it is not installed, an error will be reported.
If the specified interpreter is not provided during the initialization of beautifulsop, the best interpreter that you think matches will be used automatically. Here is a pit. The default best interpreter for the source code of the target web page is lxml. At this time, there will be problems with the parsed results, which will result in the inability to extract the next data. So when it is found that sometimes there is a problem in extracting the results, print the soup to see if it is correct.
Looking at the html source code, we can see that the part of the comic list displayed on the page is the ul tag named listcon, which can uniquely confirm the corresponding tag through the listcon class
Extract tags that contain a list of comics
listcon_tag = soup.find('ul', class_='listcon')
The find method above means to find the ul tag whose class is listcon, and returns all the contents of the corresponding tag. Find all the a tags with the attribute of href in the list tags, and these a tags are the corresponding information of each comic.
com_a_list = listcon_tag.find_all('a', attrs={'href': True})
After that, the href attribute of each comic book is synthesized into a complete accessible url address, which is saved in an array.
comics_url_list = [] base = 'http://www.xeall.com' for tag_a in com_a_list: url = base + tag_a['href'] comics_url_list.append(url)
Now comics_ url_ The list array contains the URL of each comic on the current page.
3. Next page list
See the select page control at the bottom of the list. We can get the url of the next page through this place.
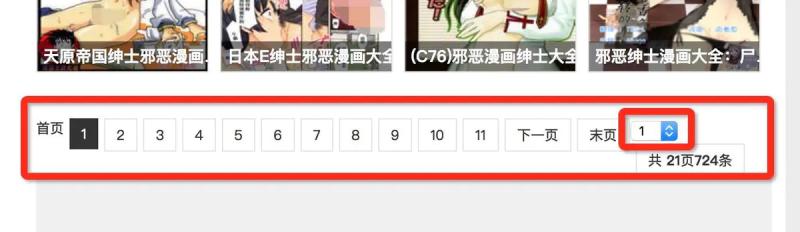
Get all the a tags with the attribute of href in the tab of the selection page
page_tag = soup.find('ul', class_='pagelist') page_a_list = page_tag.find_all('a', attrs={'href': True})
This part of the source code is as shown in the figure below. It can be seen that the last one represents the url of the last page and the last two represents the url of the next page in all a tags. Therefore, we can select the page_a_list array to get the url of the next page.
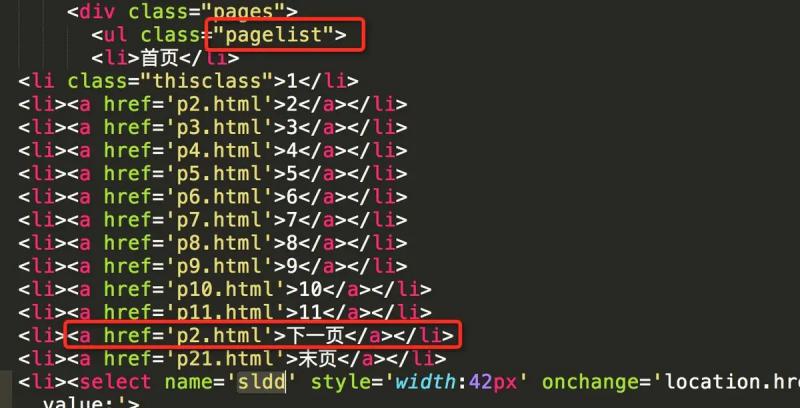
However, it should be noted that if the current page is the last one, there is no need to take the next page. So how to judge whether the current page is the last page?
It can be judged by the select control. According to the source code, the option tag corresponding to the current page will have the selected attribute. The following figure shows that the current page is the first page
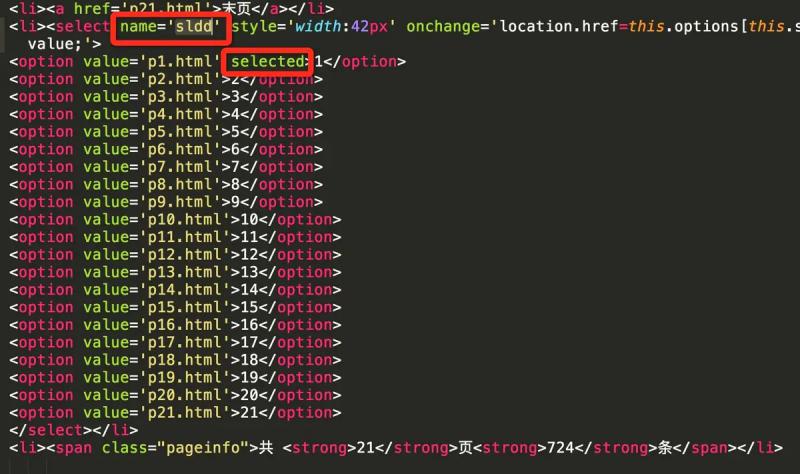
The following figure shows that the current page is the last page
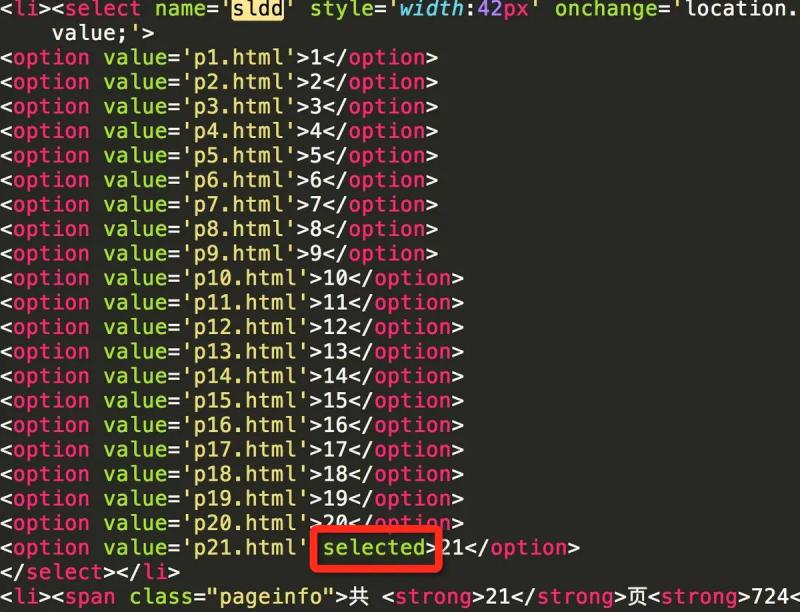
By comparing the current page number with the last page number, if it is the same, it means that the current page is the last page.
select_tag = soup.find('select', attrs={'name': 'sldd'}) option_list = select_tag.find_all('option') last_option = option_list[-1] current_option = select_tag.find('option' ,attrs={'selected': True}) is_last = (last_option.string == current_option.string)
If it is not the last page at present, continue to do the same processing for the next page. The request is still processed by calling back the parse method
if not is_last: next_page = 'http://www.xeall.com/shenshi/' + page_a_list[-2]['href'] if next_page is not None: print('\n------ parse next page --------') print(next_page) yield scrapy.Request(next_page, callback=self.parse)
Process each page in turn in the same way until all page processing is complete.
4. Crawling cartoon pictures
When all the comic URLs of the current page are extracted in the parse method, each comic can be processed.
Getting comics_ url_ Add the following code below the list array:
for url in comics_url_list: yield scrapy.Request(url=url, callback=self.comics_parse)
Request the url of each comic. The callback processing method is self.comics_parse,comics_ The parse method is used to process each cartoon. The following is the specific implementation.
5. Picture of current page
The prime minister constructs a beautiful soup from the source code returned from the request, which is basically the same as the previous one
def comics_parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
Extract the tab of the select page control. The page display and source code are as follows
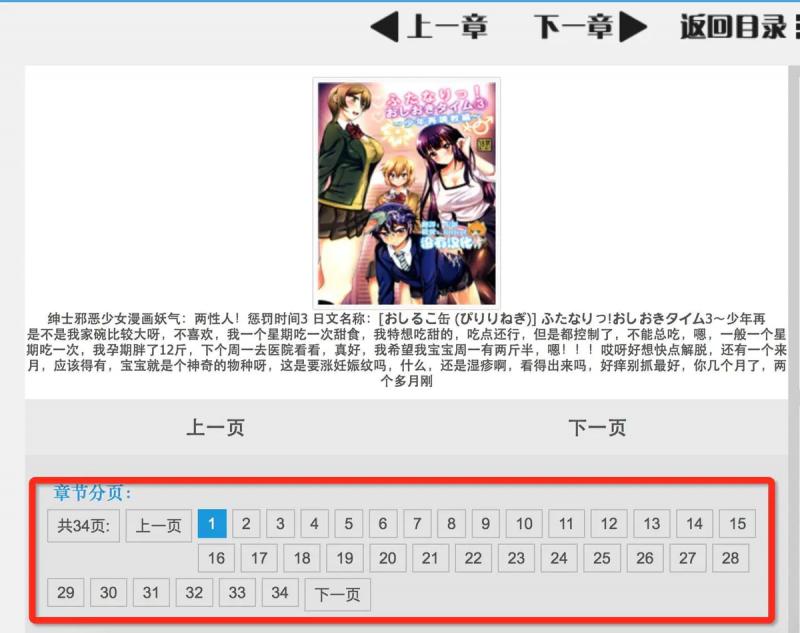
Extract ul tag whose class is pagelist
page_list_tag = soup.find('ul', class_='pagelist')
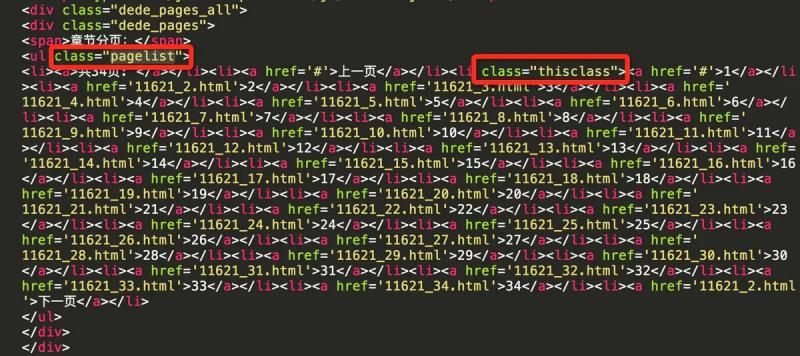
Viewing the source code, you can see the class attribute thisclass of the li tag of the current page, so as to obtain the current page number
current_li = page_list_tag.find('li', class_='thisclass') page_num = current_li.a.string
Label and corresponding source code of current page picture
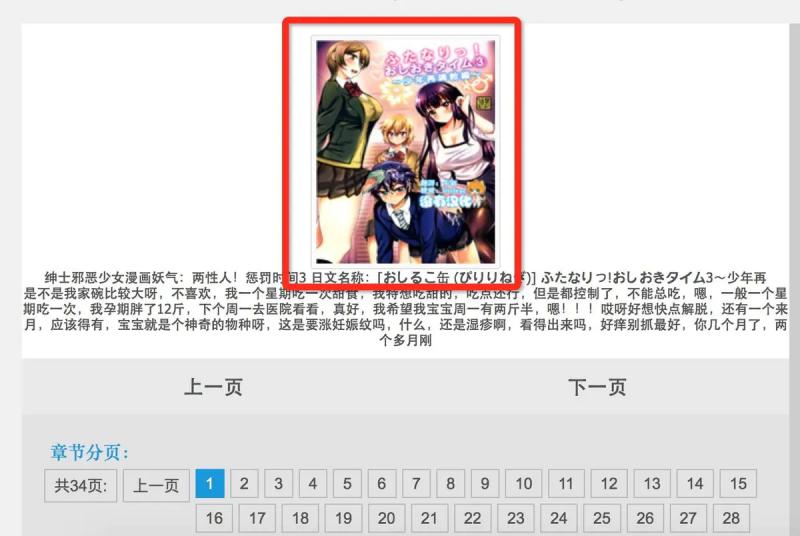
Get the url of the current page picture and the title of the comic. The title of the comic is followed by the name of the folder where the corresponding comic is stored.
li_tag = soup.find('li', id='imgshow') img_tag = li_tag.find('img') img_url = img_tag['src'] title = img_tag['alt']
6. Save to local
When the image url is extracted, the image can be requested through the url and saved locally
self.save_img(page_num, title, img_url)
This paper defines a special method save for saving pictures_ IMG is implemented as follows
# Forerunner storage import os import urllib import zlib def save_img(self, img_mun, title, img_url): # Save pictures locally self.log('saving pic: ' + img_url) # Folder to save comics document = '/Users/moshuqi/Desktop/cartoon' # The file name of each cartoon is named after the title comics_path = document + '/' + title exists = os.path.exists(comics_path) if not exists: self.log('create document: ' + title) os.makedirs(comics_path) # Each picture is named after the number of pages pic_name = comics_path + '/' + img_mun + '.jpg' # Check whether the picture has been downloaded to the local area. If it exists, it will not be downloaded again exists = os.path.exists(pic_name) if exists: self.log('pic exists: ' + pic_name) return try: user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } req = urllib.request.Request(img_url, headers=headers) response = urllib.request.urlopen(req, timeout=30) # Data returned by request data = response.read() # If the returned data is compressed data, decompress it first if response.info().get('Content-Encoding') == 'gzip': data = zlib.decompress(data, 16 + zlib.MAX_WBITS) # Pictures saved locally fp = open(pic_name, "wb") fp.write(data) fp.close self.log('save image finished:' + pic_name) except Exception as e: self.log('save image error.') self.log(e)
The function mainly uses three parameters: the number of pages of the current picture, the name of the cartoon, and the url of the picture.
The picture will be saved in the folder named after the cartoon. If there is no corresponding folder, create one. Generally, you need to create a folder when you get the first picture.
document is a local specified folder, which can be customized.
Each picture is named in the format of. jpg. If there is a picture with the same name in the local area, it will not be downloaded again. Generally, it is used to judge when the task is started repeatedly to avoid repeated requests for the existing picture.
The image data returned by the request is compressed. You can use the response.info (). Get ('content encoding ') type. Compressed pictures need to go through first zlib.decompress Unzip and save to the local, otherwise the picture cannot be opened.
The general implementation idea is as above, and comments are attached to the code.
7. Next picture
Similar to the processing method in the comic list interface, we also need to constantly obtain the pictures on the next page in the comic page, and constantly traverse until the last page.
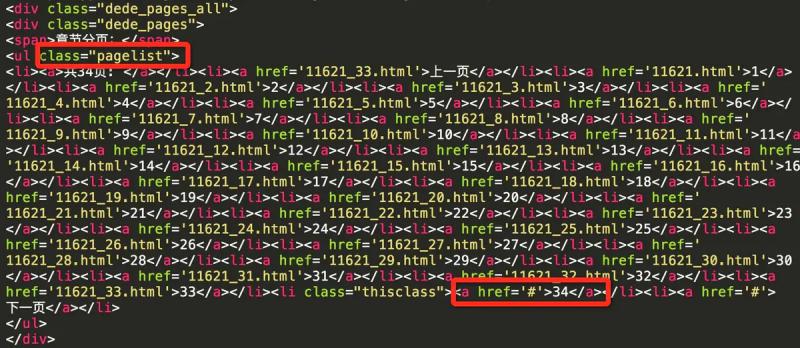
The last page of the comic book when the href attribute of the next page is ා
a_tag_list = page_list_tag.find_all('a') next_page = a_tag_list[-1]['href'] if next_page == '#': self.log('parse comics:' + title + 'finished.') else: next_page = 'http://www.xeall.com/shenshi/' + next_page yield scrapy.Request(next_page, callback=self.comics_parse)
If the current is the last page, the comic book traversal is completed, otherwise continue to process the next page in the same way
yield scrapy.Request(next_page, callback=self.comics_parse)
8. Operation results
The general implementation is basically completed. When running, you can see the printing situation of the console
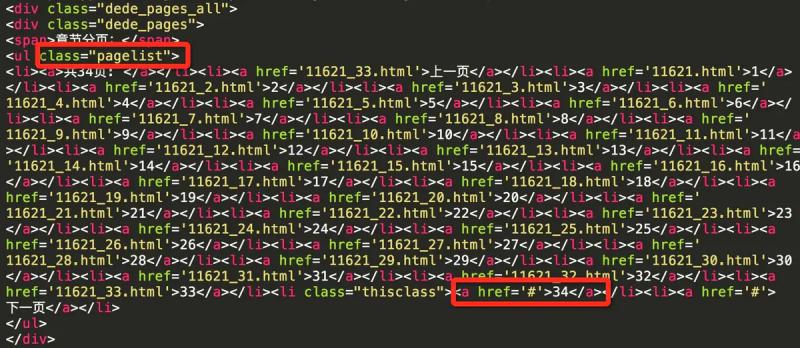
Pictures saved to local folder
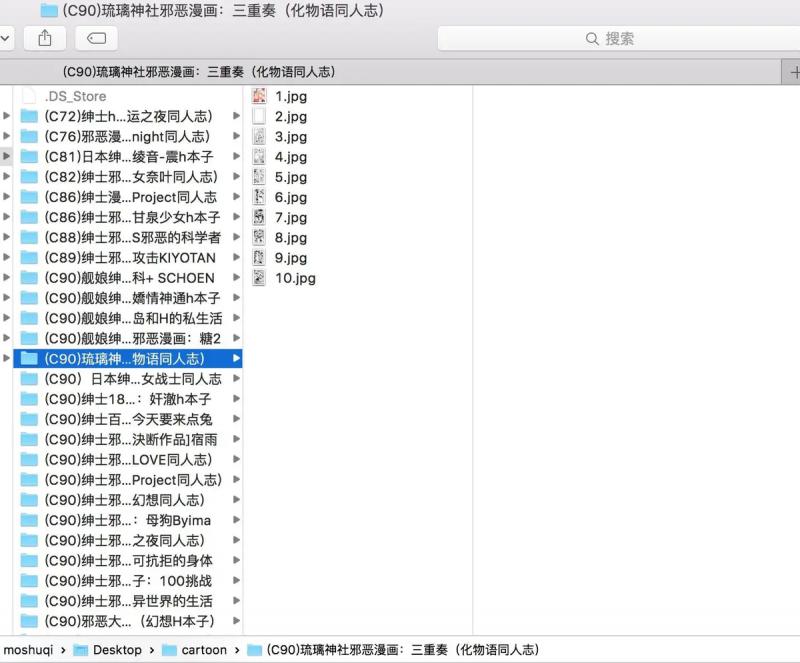
When the sketch framework is running, it uses multiple threads, and can see that multiple comics are crawling at the same time.
The resource server of the target website feels slow, and the request often times out. Please wait patiently while running.
last
This article introduces only the very basic usage of the sketch framework, as well as various detailed feature configurations.
For example, use FilesPipeline and imagesipipeline to save downloaded files or pictures.
The framework itself has an XPath class to extract web information, which is more efficient than beautiful soup. You can also save the crawled data results as a class through a special item class. Please refer to the official website for details.
Finally, the complete Demo source code is attached https://github.com/moshuqi/DemoCodes/tree/master/Comics
Original link: https://www.jianshu.com/p/c1704b4dc04d
Source network, for learning purposes only, invasion and deletion.
Don't panic. I have a set of learning materials, including 40 + E-books, 800 + teaching videos, involving Python foundation, reptile, framework, data analysis, machine learning, etc. I'm not afraid you won't learn! https://shimo.im/docs/JWCghr8prjCVCxxK/ Python learning materials
Pay attention to the official account [Python circle].
