This article is for reference only:
Bili Bili video capture
The video capture of station b is still relatively difficult. Compared with the video capture of other websites, it is also relatively difficult because of my curiosity and fear of death. I intend to analyze and analyze the video of station b. the specific capture process is as follows:
The initial analysis page is as follows: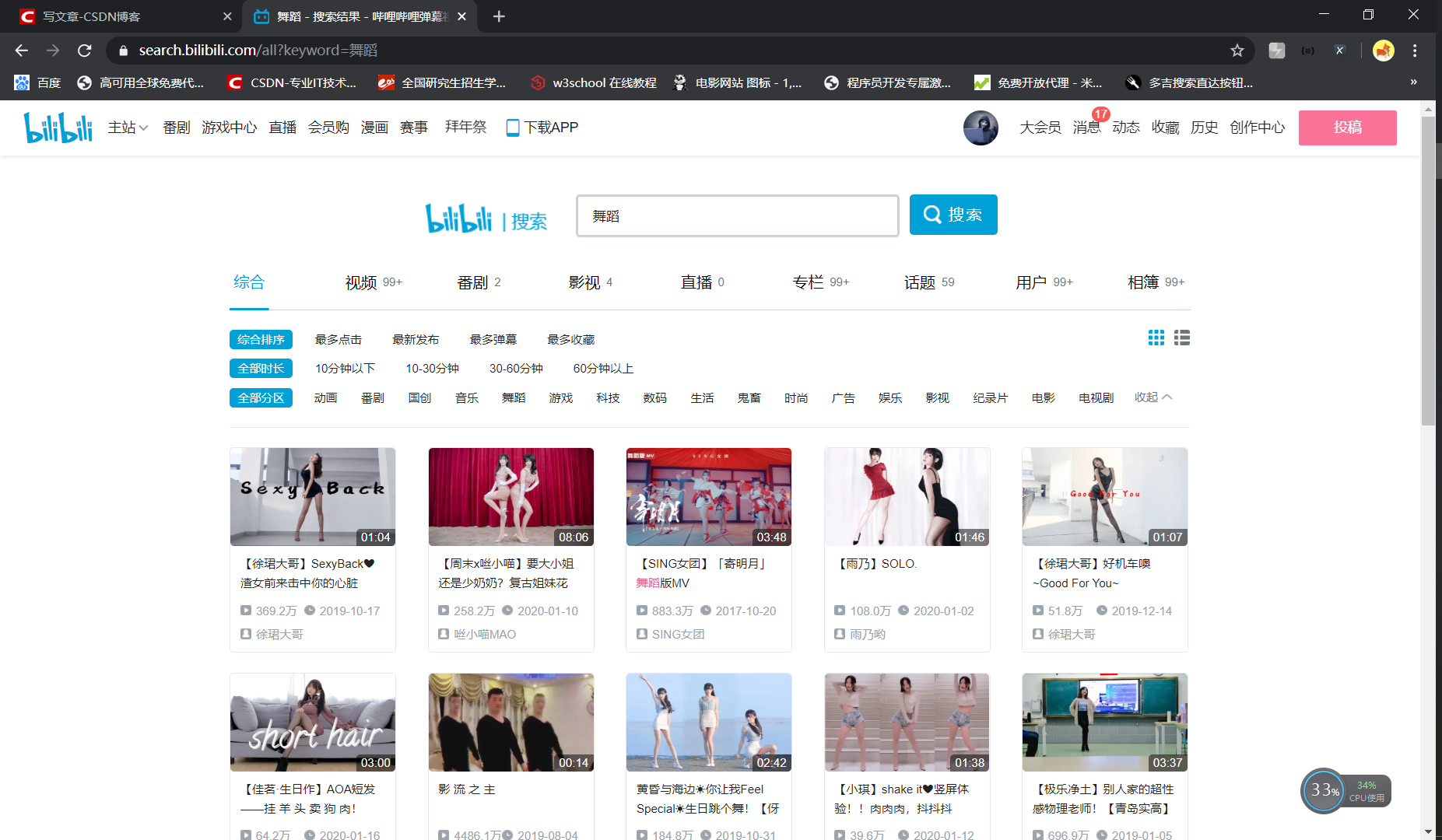
This page is a little eye-catching, from this start. The request and response information of this page is easy to capture and analyze, mainly to obtain page tags and the url address of the video jump to the specified playing interface (as shown in the figure below)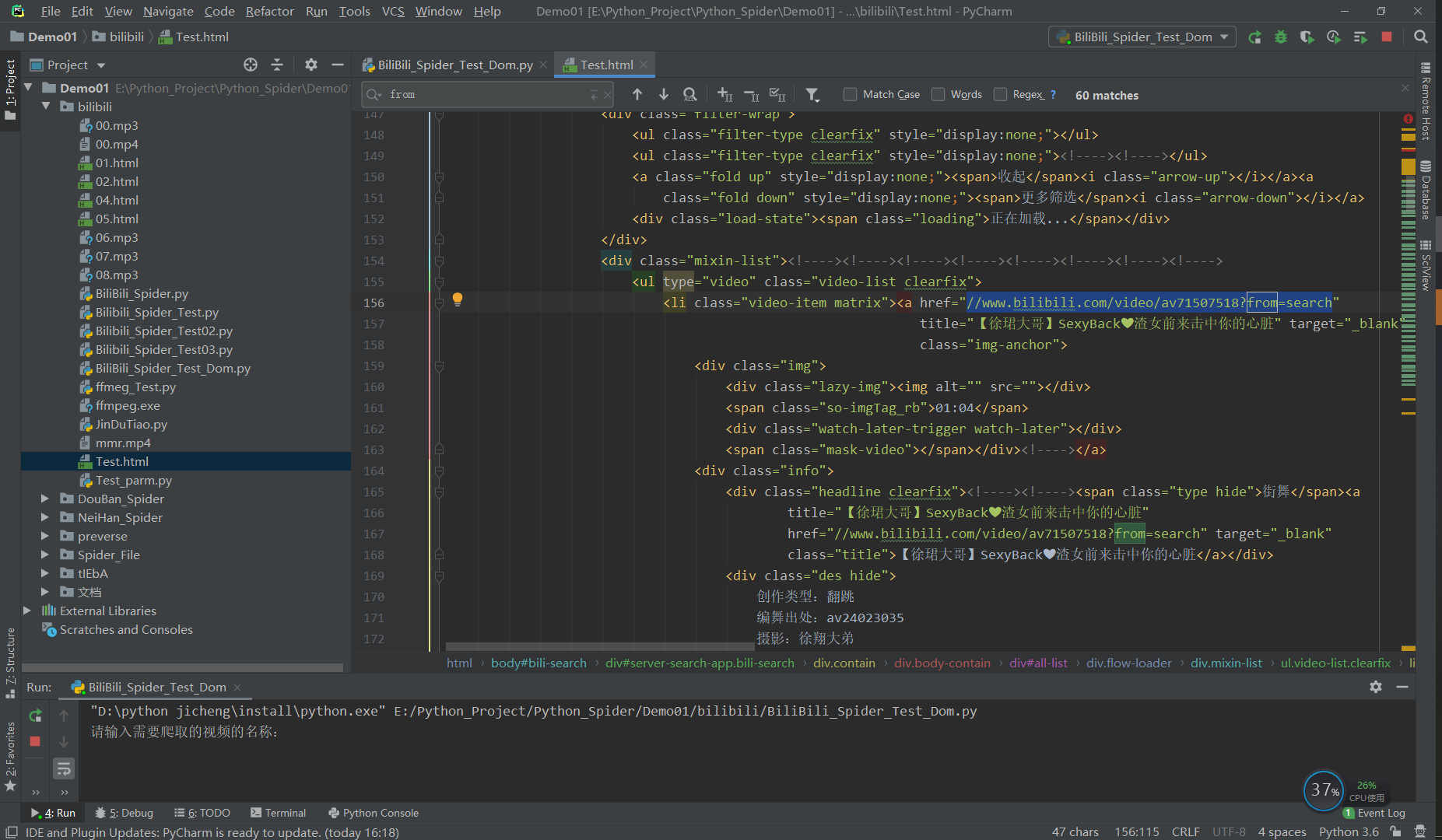
The way I use is to download the page frame information in the response, and then compare it with the original merged Element page to find the url. This step is easy to find, not to say much, and directly go to the code (en In general, the code is like this, and I'm too lazy to separate it a little bit):
html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8") seconed_url_list = set( re.findall(r'''href="//(www\.bilibili\.com/video/.*?\?from=search)"''', html_str01, re.S))
Next, after finding the initial url, we can analyze the original video capture:
Here is the page to analyze: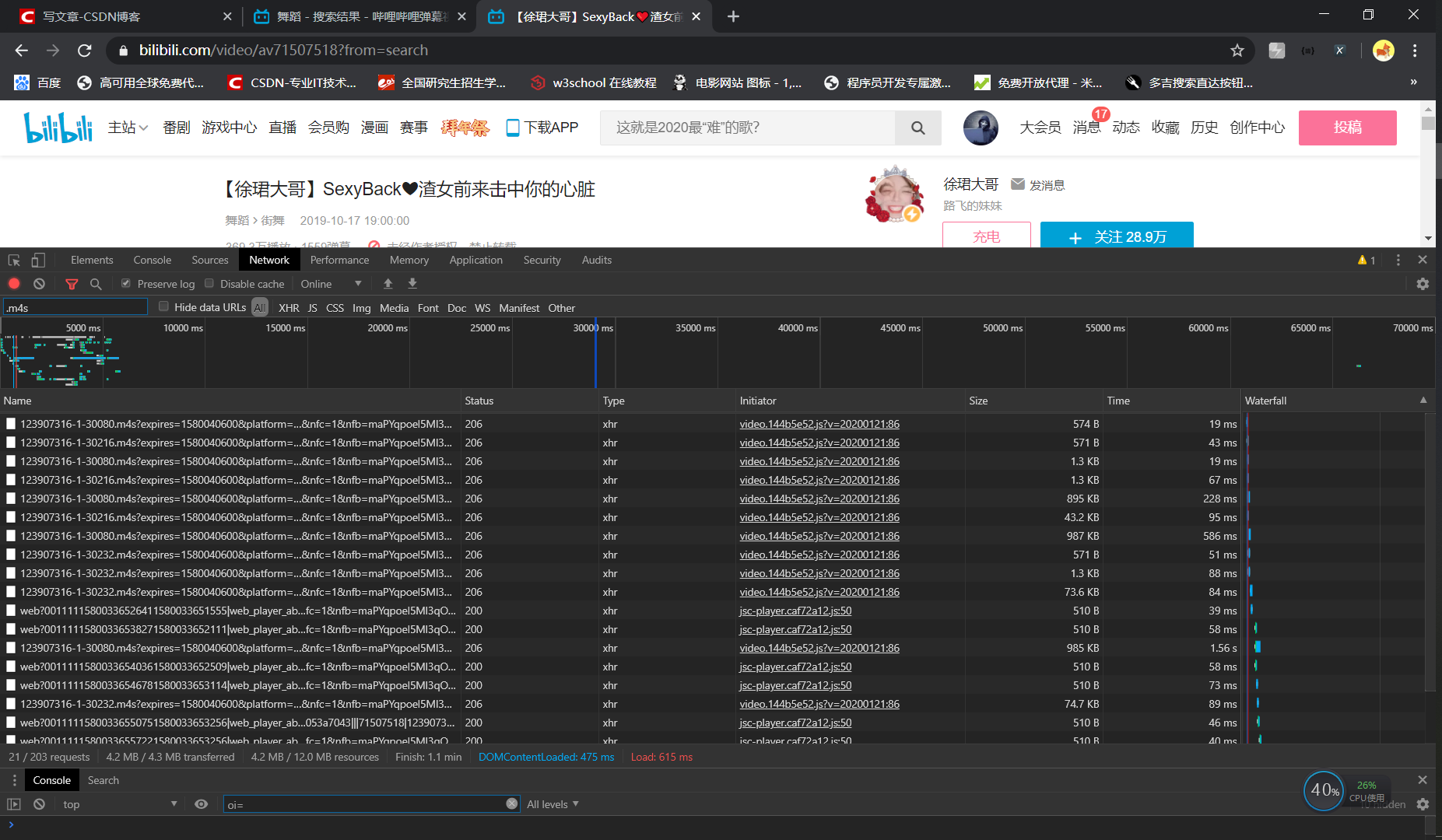
We can not get the complete video request address through packet capturing, but get a large number of requests in. m4s format. The initial guess is that. m4s format file is the video file we need, but in terms of number, it's a video clip. However, not all. m4s format requests are the same, roughly divided into (as shown in the figure below) such several requests, which one is definitely not crossed out, because the response is null, so there are three types of requests left (30080 / 30216 / 30232).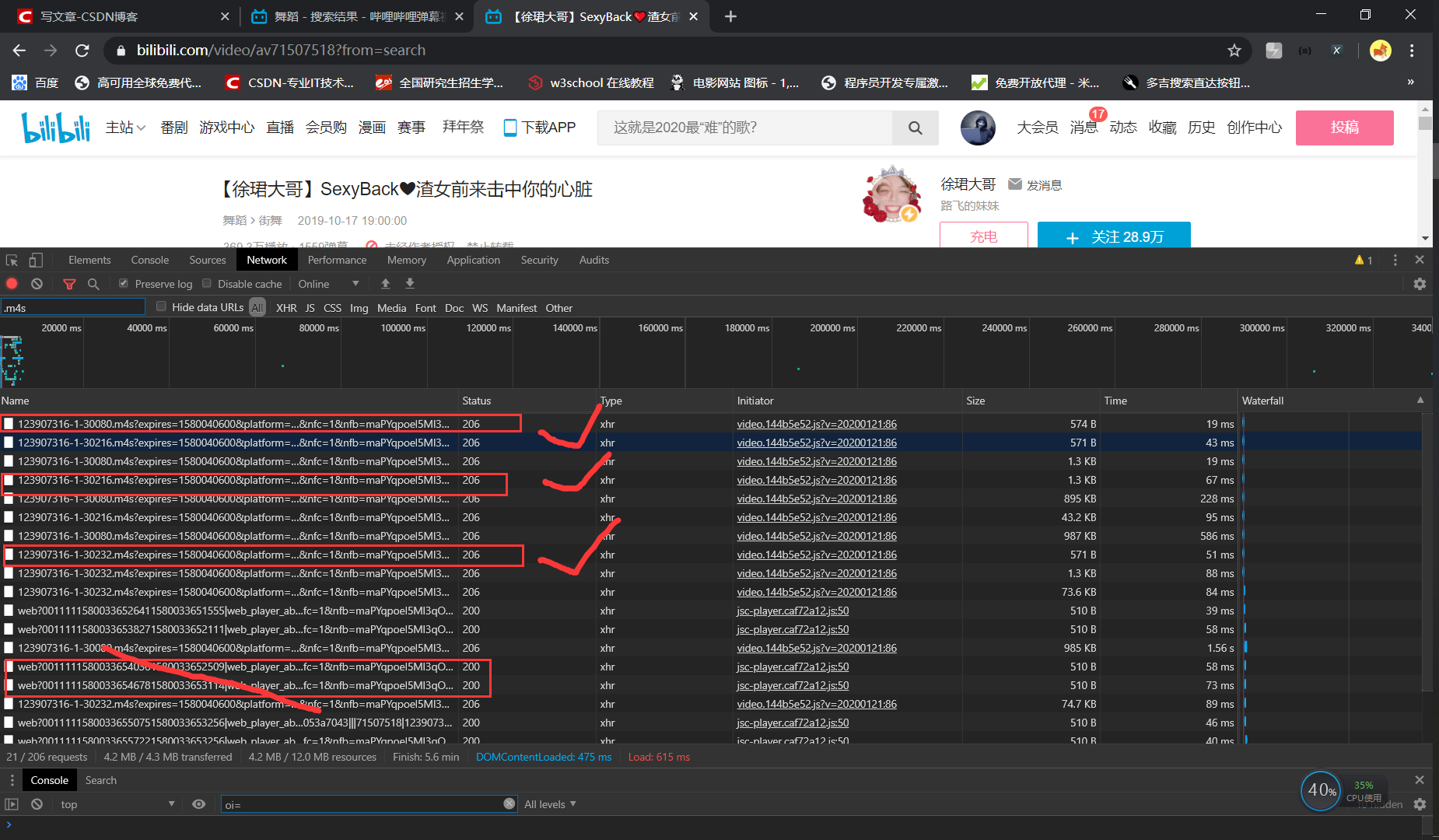
Three requests, which one do I need? Continue to analyze, find a lot of data, and come to the conclusion that most of the returned request data is in video format, and the less data is in audio file (as shown in the figure below)
30080 total data size of requests required
30216 total requested data size
30232 total data size of requests required
By comparison, the number of data requests for 30080 > 30232 > 30216
Now we can be sure that the 30080 data request is a video file, so which of the 30232 and 30216 requests is an audio file?
Don't panic. Go ahead and analyze.
There's a problem here. There are so many fragments in the 30080 file. I can't download all of them and then synthesize them. Although it's feasible, it's complicated. There is also a simpler way to get the whole video file. In this way, you need to change the parameter Range (as shown in the figure below) to bytes 0-XXXXXXXX in the requests header. In this case, XXXXXXXX is the total number of data requests of url type analyzed above. According to my analysis, this value can only be greater than or equal to the total number of data requests, but not smaller Yu. So there are two ways to get the complete. m4s format. One is to write the Range value of the request header as big as possible. The other is to first request the shorter data such as 0-5, carry out the head back probe, get the response header, then get the accurate data value, and then send the request to get all the data of. m4s, so as to get the end Whole. m4s file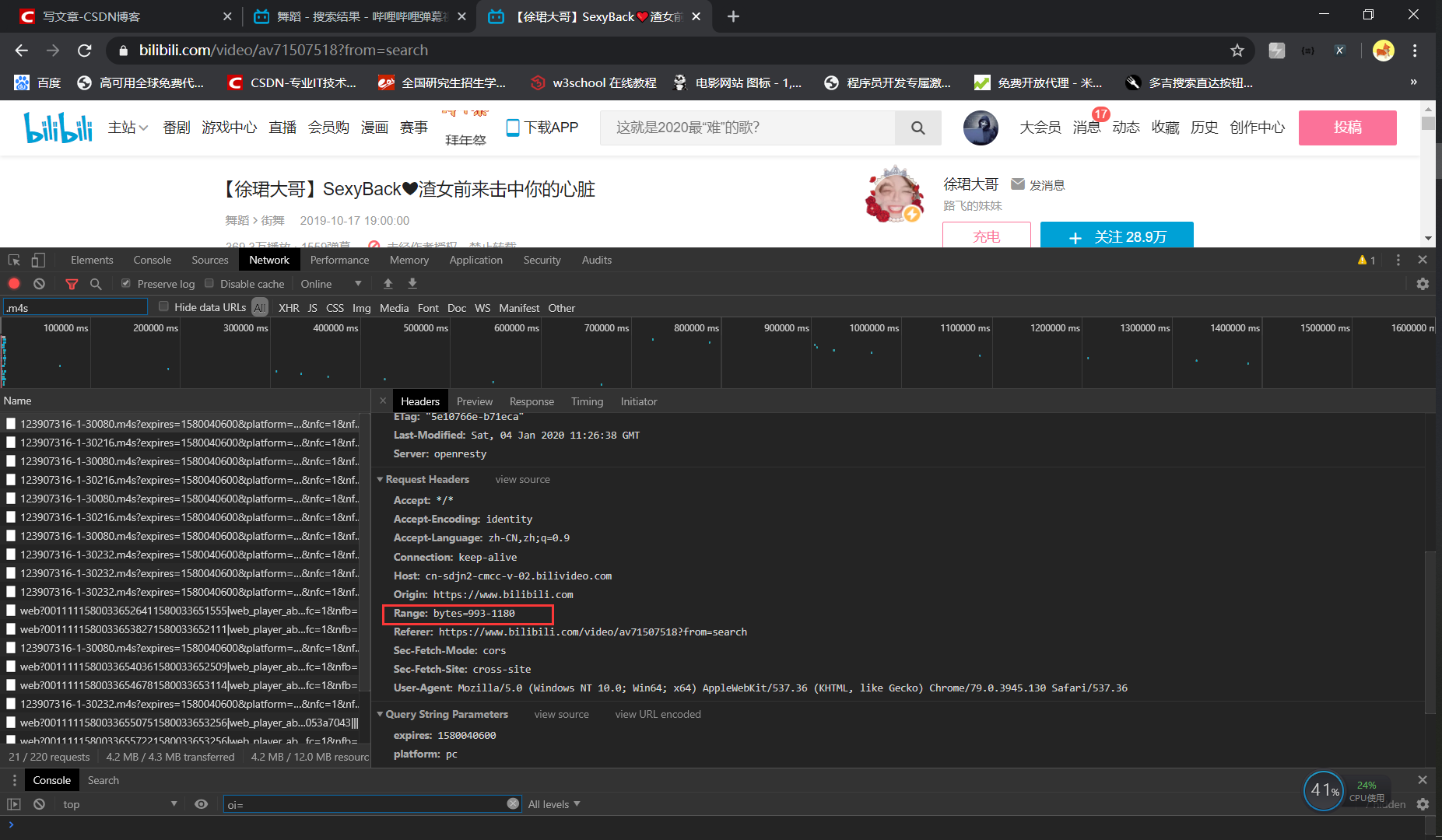
On the basis of this analysis, we compare the url requests of 30232 and 30216 formats, and test and obtain the data obtained by the two kinds of requests respectively. As shown in the figure: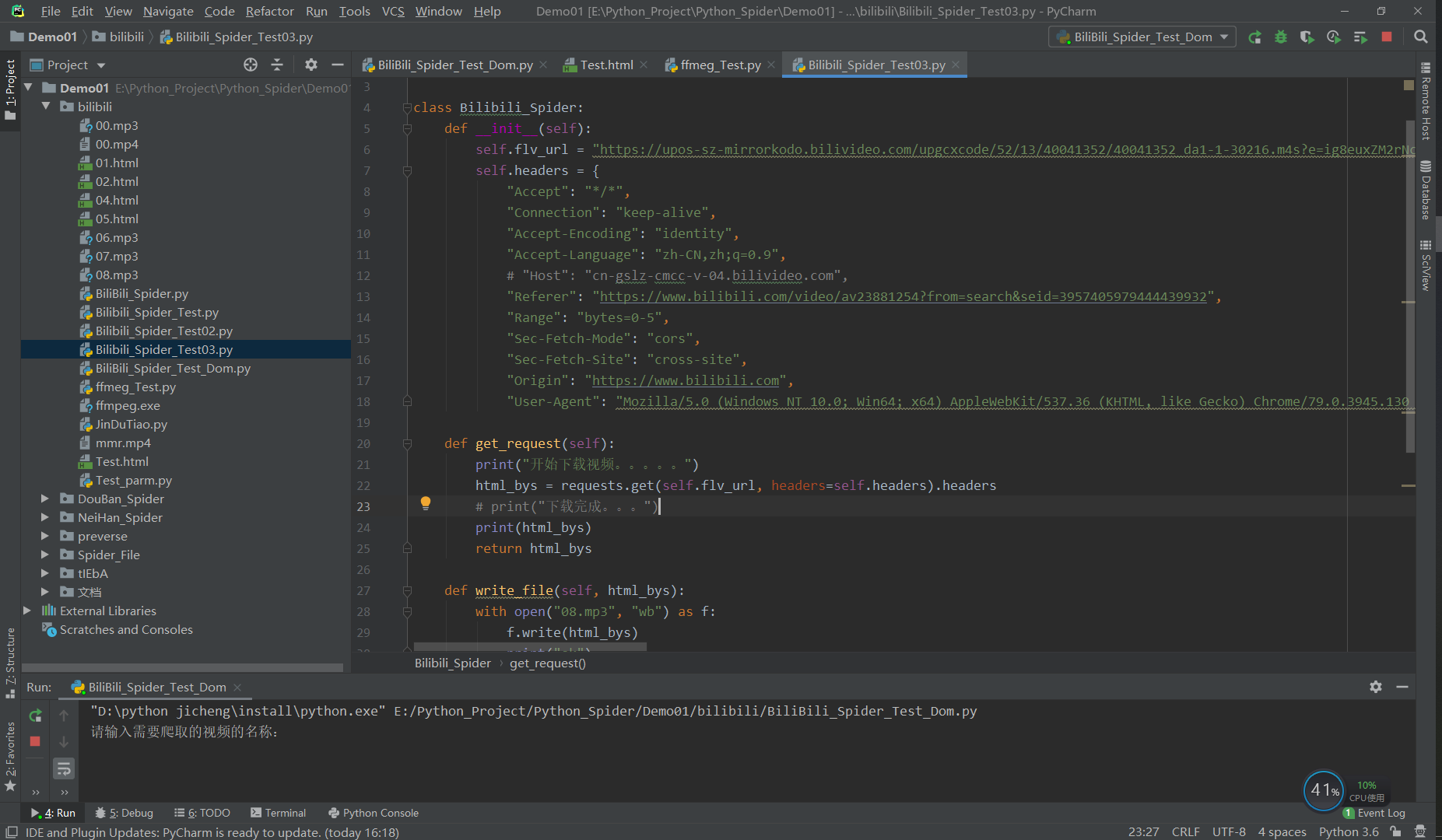
We download the two requested data and save them in mp3 file format. Through this test, we get that both files are audio files of video, and there is no difference between them. So we ask for a slightly smaller 30216.
In this way, the acquisition of video and audio files can be completed. However, this is separate from the download. If you need to synthesize, here are two methods I tried:
[1] Video and audio synthesis using ffmpeg module
[2] Use format factory
In this program, I did not use ffmpeg to synthesize for two reasons. One is that it's too slow, and the cpu utilization of my notebook has increased to an incredible 99% during the conversion process. The other is that the format factory is so easy to use, and the synthesis speed is extremely fast. Therefore, I chose a manual format factory to synthesize video and audio.
At this point, the whole analysis process is over, and the rest is to write out the whole program. Here, we do not say how to write each module, but directly present code screenshots and running screenshots.
The screenshot of the operation is as follows: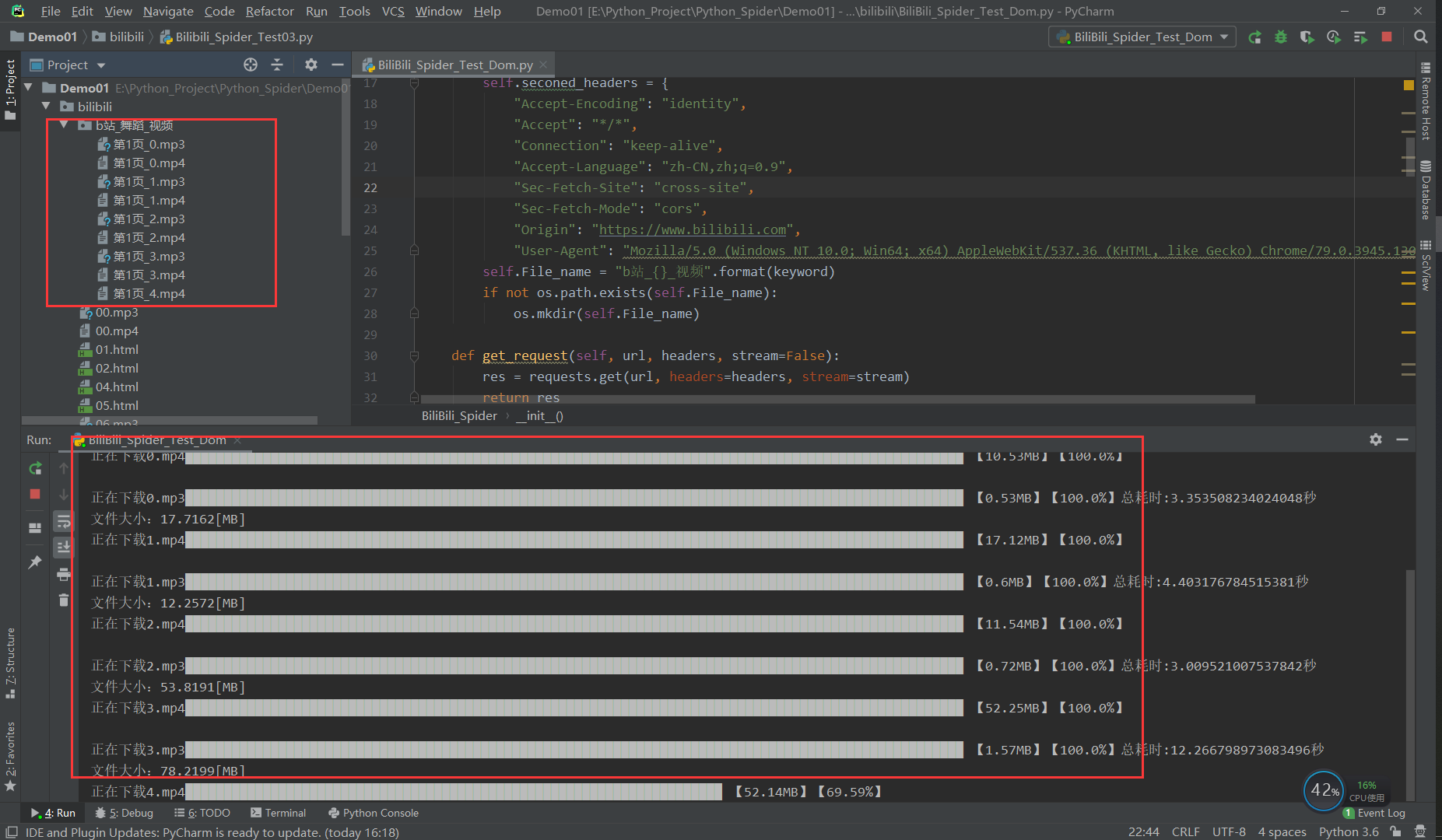
The results of saving part of the code in progress are shown as follows: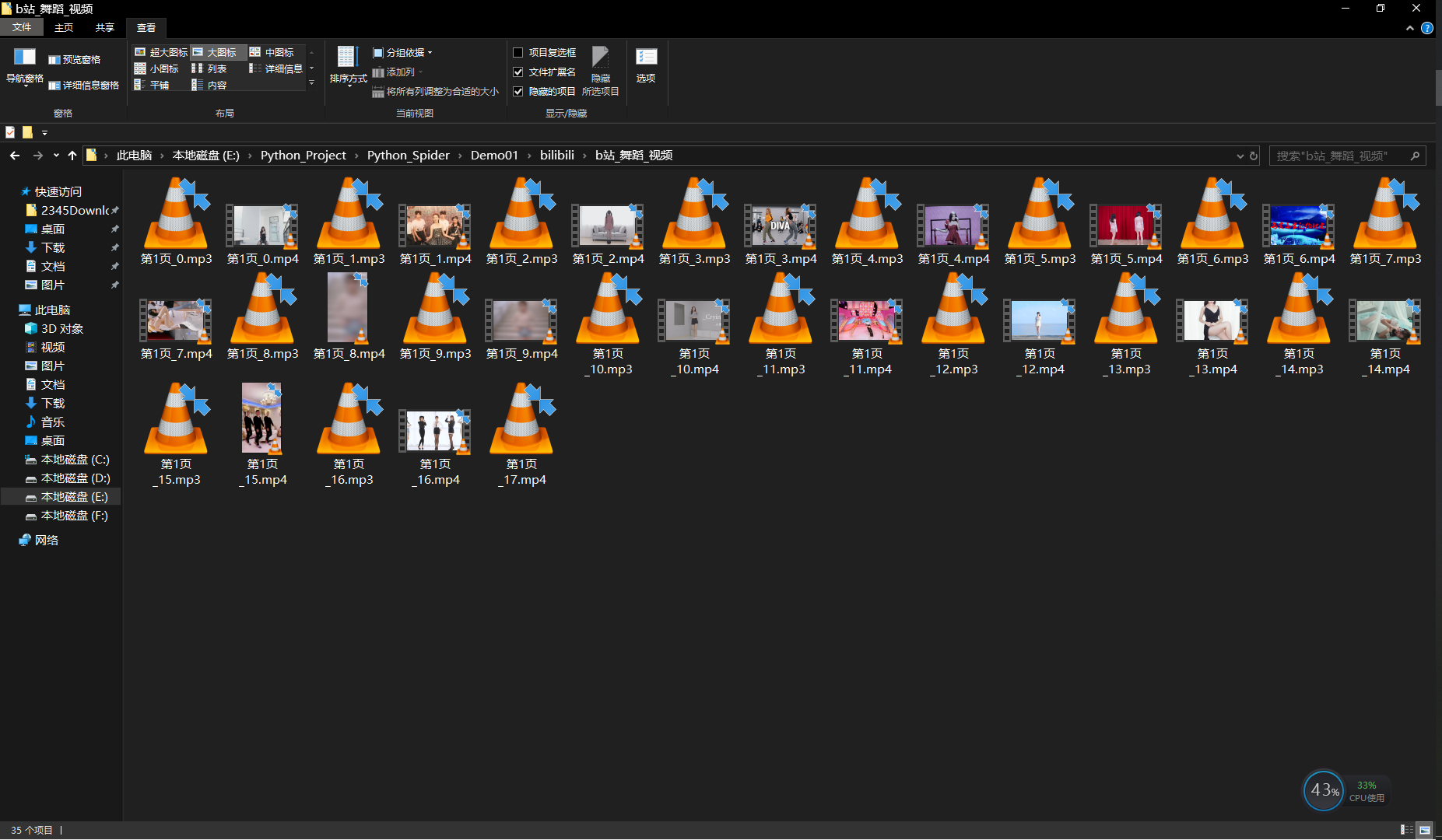
Video display: insert, it's HD, right
Therefore, the introduction of this procedure ends:
Some codes are as follows: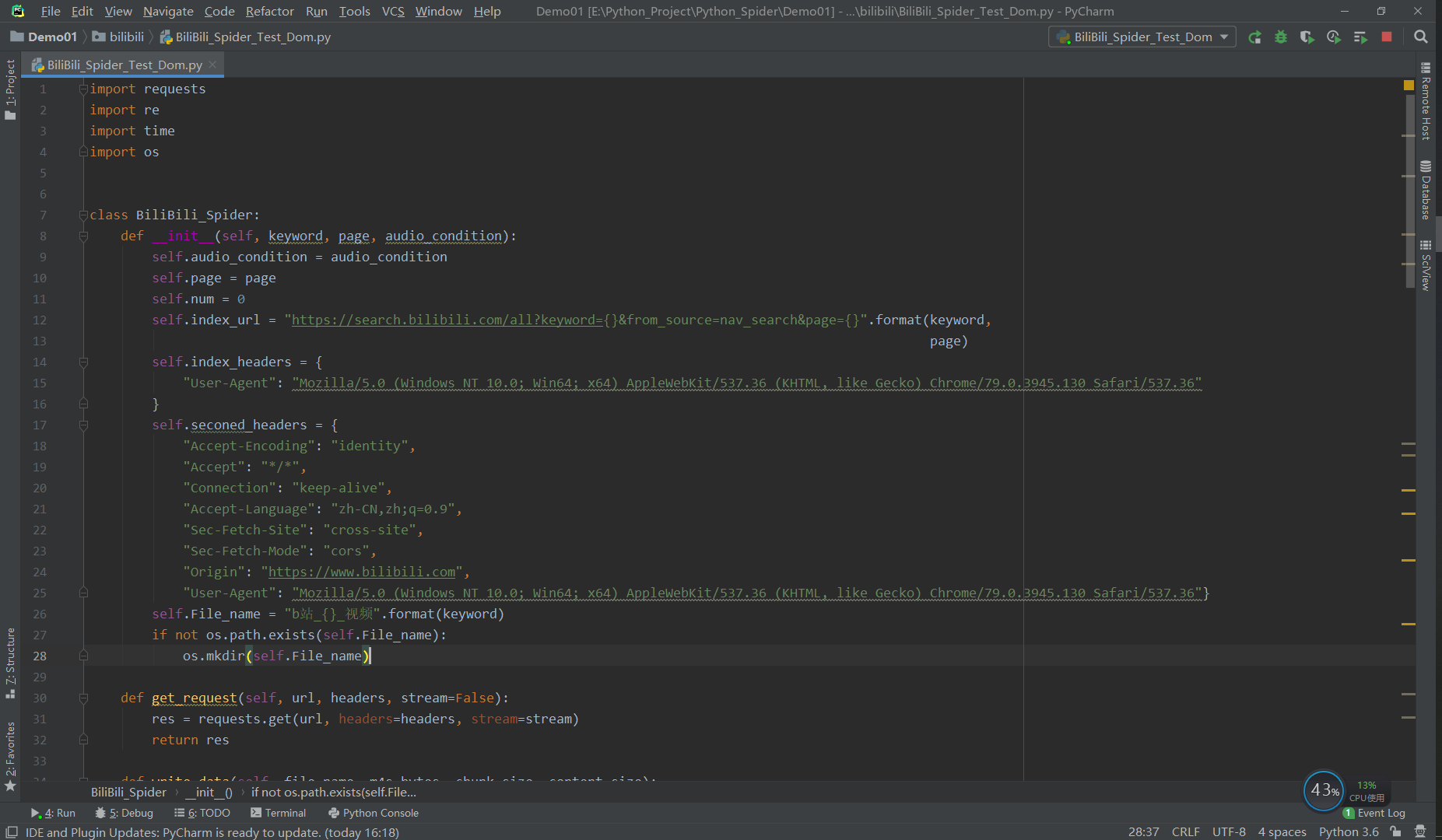
Source code part
def run(self): # print("the first request starts..... "" html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8") # file_name = re.findall(r'''<title data-vue-meta="true">(.*?)</title>''', html_str01, re.S)[0] + ".mp4" seconed_url_list = set( re.findall(r'''href="//(www\.bilibili\.com/video/.*?\?from=search)"''', html_str01, re.S)) # print(seconed_url_list) for seconed_url in seconed_url_list: html_str02 = self.get_request("http://" + seconed_url, self.index_headers).content.decode("utf-8") try: m4s_30080 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[0] except Exception as e: print(e) continue if self.audio_condition == 'Y': mp3_30216 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[-2] # print(m4s_30080) Referer_key = seconed_url # Probe request header size Range_key = 'bytes=0-5' self.seconed_headers['Referer'] = 'https://' + Referer_key self.seconed_headers['Range'] = Range_key # Probe, get the value of total html_bytes = self.get_request(m4s_30080, headers=self.seconed_headers).headers['Content-Range'] if self.audio_condition == 'Y': audio_bytes = self.get_request(mp3_30216, headers=self.seconed_headers).headers['Content-Range'] # print(html_bytes) total = re.findall(r"/(.*)", html_bytes, re.S)[0] if self.audio_condition == 'Y': audio_total = re.findall(r"/(.*)", audio_bytes, re.S)[0] # print("total: " + str(total)) self.seconed_headers['Range'] = total # print(total) stream = True chunk_size = 1024 # Each block size is 1024 content_size = int(total) if self.audio_condition == 'Y': content_size_audio = int(audio_total) print("File size:" + str(round(float((content_size + content_size_audio) / chunk_size / 1024), 4)) + "[MB]") else: print("File size:" + str(round(float(content_size / chunk_size / 1024), 4)) + "[MB]") start = time.time() m4s_bytes = self.get_request(m4s_30080, headers=self.seconed_headers, stream=stream) self.write_data(str(self.num) + ".mp4", m4s_bytes, chunk_size, content_size) if self.audio_condition == 'Y': print("\n") self.seconed_headers['Range'] = audio_total mp3_bytes = self.get_request(mp3_30216, headers=self.seconed_headers, stream=stream) self.write_data(str(self.num) + ".mp3", mp3_bytes, chunk_size, content_size_audio) end = time.time() print("Total time consuming:" + str(end - start) + "second") self.num = self.num + 1

