Use the requests library to capture the contents of the cat-eye movie TOPl100.
Target site: https://maoyan.com/board/4
1. Grab Home Page
Define the get_one_page method and pass it a url parameter
Note: Cat Eye Movie website has anti-crawling measures, you can crawl after setting headers
import requests headers = { 'Content-Type': 'text/plain; charset=UTF-8', 'Origin': 'https://maoyan.com', 'Referer': 'https://maoyan.com/board/4', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } def get_one_page(url, headers): try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None except RequestsException: return None def main(): url = "https://maoyan.com/board/4" html = get_one_page(url, headers) print(html) if __name__ == '__main__': main()
Run Discovery to get source code successfully
2. Regular Extraction
Here we define the def parse_one_page method
import requests import re from requests.exceptions import RequestException headers = { 'Content-Type': 'text/plain; charset=UTF-8', 'Origin': 'https://maoyan.com', 'Referer': 'https://maoyan.com/board/4', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } def get_one_page(url, headers): try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None except RequestsException: return None def parse_one_page(html): pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S) items = re.findall(pattern, html) for item in items: yield { 'index': item[0], 'image': item[1], 'title': item[2], 'actor': item[3].strip()[3:], 'time': item[4].strip()[5:], 'score': item[5] + item[6] } def main(): url = "https://maoyan.com/board/4" html = get_one_page(url, headers) for item in parse_one_page(html): print(item) if __name__ == '__main__': main()
Run Results
3. Write files
We write the extracted results to a file, which is written directly to a text file.
import requests import re import json from requests.exceptions import RequestException headers = { 'Content-Type': 'text/plain; charset=UTF-8', 'Origin': 'https://maoyan.com', 'Referer': 'https://maoyan.com/board/4', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } def get_one_page(url, headers): try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None except RequestsException: return None def parse_one_page(html): pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S) items = re.findall(pattern, html) for item in items: yield { 'index': item[0], 'image': item[1], 'title': item[2], 'actor': item[3].strip()[3:], 'time': item[4].strip()[5:], 'score': item[5] + item[6] } def write_to_file(content): with open('result.txt', 'a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) + '\n') f.close() def main(): url = "https://maoyan.com/board/4" html = get_one_page(url, headers) for item in parse_one_page(html): print(item) write_to_file(item) if __name__ == '__main__': main()
Found successfully written to file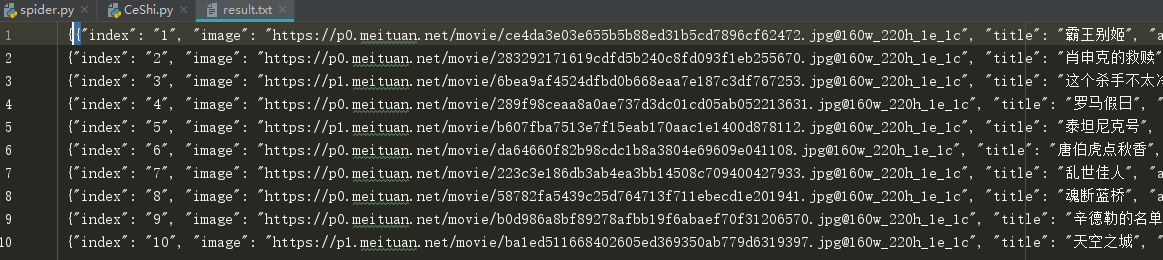
6. Paging Crawl
In the steps above, we found and successfully crawled the movie rankings on the first page, because we need to capture the TOP100 movie, and we need to crawl 90 other movies.
By analyzing your site, see how the URL and content of your page change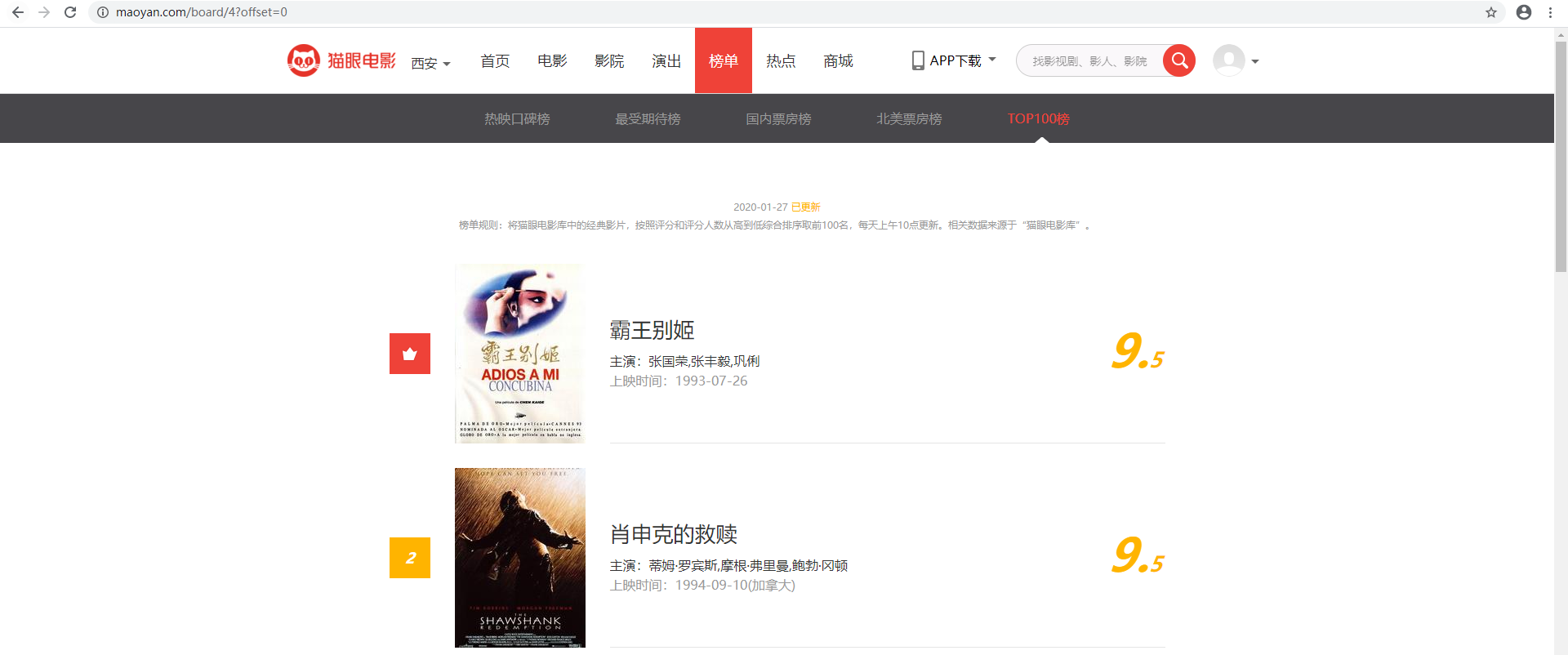
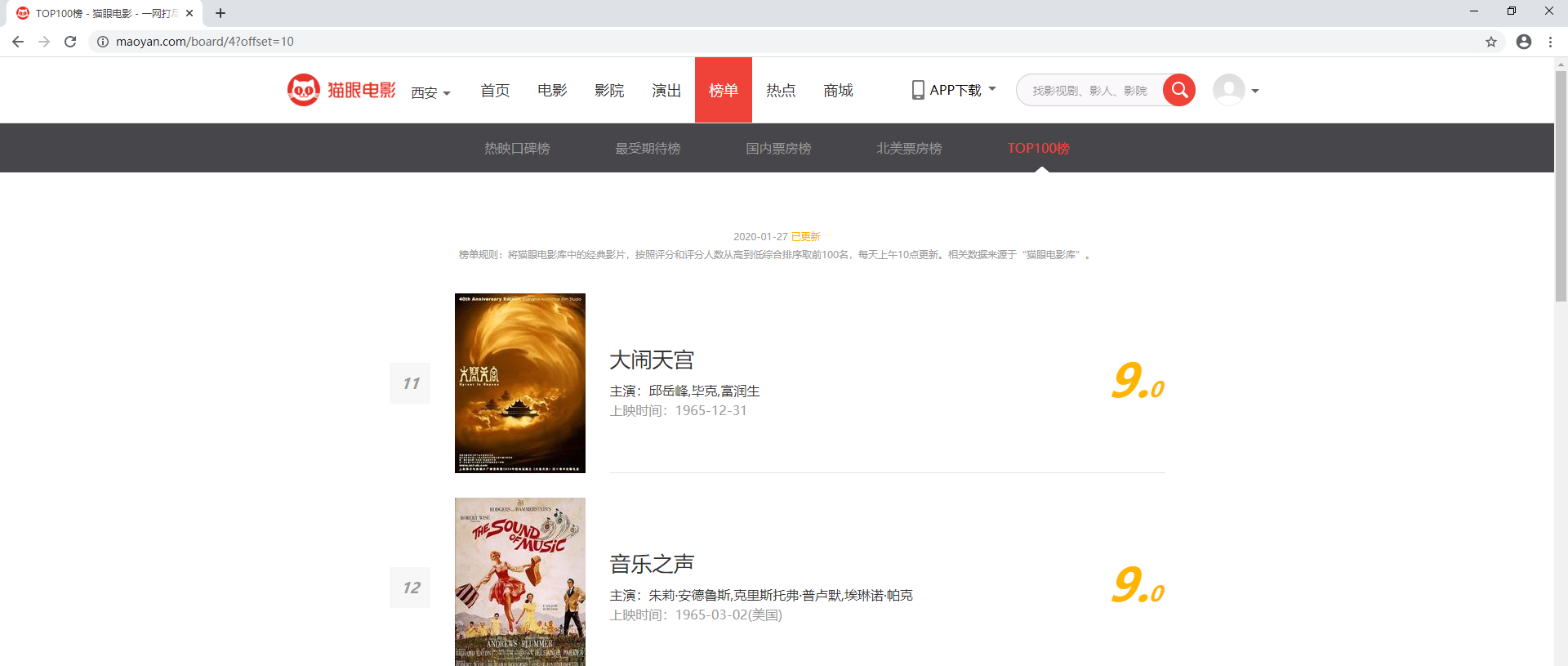
** You can see that the URL of the page changes to https://maoyan.corn/board/4?offset=10, which is one more parameter than the previous URL, offset=10. The result shown now is a movie ranking 11-20, which is presumably an offset parameter.Click on the next page and find that the URL of the page changes to http://maoyan.com/board/4? Offset=20, the offset parameter changes to 20, and the result is the movie ranking 21-30.This summarizes the rule that offset represents the offset value. If offset is n, the movie sequence numbers displayed are n+l to n+10, and 10 are displayed on each page.
Here you need to modify the main() method, receive an offset value as an offset, and construct a URL to crawl.The code is as follows
import requests import re import json from requests.exceptions import RequestException headers = { 'Content-Type': 'text/plain; charset=UTF-8', 'Origin': 'https://maoyan.com', 'Referer': 'https://maoyan.com/board/4', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36' } # Crawl Web Source Code def get_one_page(url, headers): try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None except RequestsException: return None def parse_one_page(html): pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S) items = re.findall(pattern, html) for item in items: yield { 'index': item[0], 'image': item[1], 'title': item[2], 'actor': item[3].strip()[3:], 'time': item[4].strip()[5:], 'score': item[5] + item[6] } def write_to_file(content): with open('result.txt', 'a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) + '\n') f.close() #Incoming offest parameter def main(offset): url = "https://maoyan.com/board/4?offset="+str(offset) html = get_one_page(url, headers) for item in parse_one_page(html): print(item) write_to_file(item) if __name__ == '__main__': for i in range(10): main(i*10)
So far we have finished crawling the cat-eye movie top100, and all the movie information has been saved in the text file.
- Reference: Pthon3 web crawler development practice (by Cui Qinghua)

