cookie handling of requests module
Stateless HTTP
HTTP statelessness means that the HTTP protocol has no memory ability for transaction processing, that is, the server does not know what the state of the client is. When we send a request to the server, the server parses the request and then returns the corresponding response. The server is responsible for completing this process, and this process is completely independent. The server will not record the changes in the state before and after, that is, the state record is missing. This means that if the previous information needs to be processed later, it must be retransmitted, which leads to the need to pass some previous repeated requests in order to obtain the subsequent response. However, this effect is obviously not what we want. In order to maintain the front and back status, we certainly can't retransmit all the previous requests once, which is a waste of resources, and it's even more difficult for users to log in to the page.
At this time, two technologies to maintain http connection appear, namely session and cookie. The session is on the server side and is used to save the user's session information. The cookie is on the client side. With a cookie, the browser will automatically attach a cookie and send it to the server the next time it visits the web page. The server identifies the cookie and identifies which user it is, then judges the relevant status of the user, and then returns the corresponding response.
- Session: session (object) is used to store the attributes and configuration information required for a specific user to have a session.
- cookie: refers to the data stored on the user's local terminal by some websites in order to identify the user's identity and track the session.
- Session maintenance: when the client requests the server for the first time, the server will return a response object with a set cookie field in the response header. The cookie will be stored by the client. This field indicates that the server has created a session object for the client user to store the relevant attributes and machine configuration information of the user. When the browser next requests the website, the browser will put the cookie in the request header and submit it to the server. The cookie carries the ID information of the corresponding session. The server will check the cookie to find out what the corresponding session is, and then judge the session to identify the user status.
Cookie processing
-
Manual processing: obtain the cookie value through the packet capture tool and encapsulate the value into headers. (not recommended)
-
Automatic processing:
-
session object:
- effect:
- 1 can send the request
- 2 if a cookie is generated during the request process, the cookie will be automatically stored / carried in the session object
- effect:
-
Create a session object: session=requests.Session()
-
Send the simulated Login post request using the session object (the cookie will be stored in the session)
-
The session object sends the get request corresponding to the personal home page (carrying a cookie)
-
Actual combat - log in to github
Capturing packets during login and discovering session
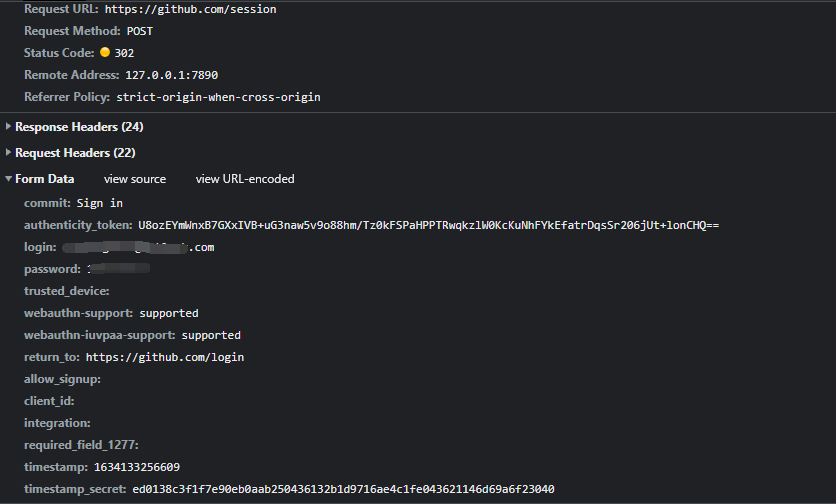
The data in this page is the data sent by the page to the server
However, we need to note that when using a session to initiate a login request
'authenticity_token': 'U8ozEYmWnxB7GXxIVB+uG3naw5v9o88hm/Tz0kFSPaHPPTRwqkzlW0KcKuNhFYkEfatrDqsSr206jUt+lonCHQ==',
The value value of the parameter looks like a set of ciphertext data, so the data is likely to change dynamically, so it needs to be captured and assigned dynamically. If this parameter is not processed, the login will fail. So where should the value be captured dynamically? This value can be uniformly called the dynamic token parameter. Generally, this value will be dynamically stored in the foreground page corresponding to the request. Therefore, we search in the source code of the login page. Then use xpath statements to match
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Connection': 'close',
}
#Create a session object that can call get and post to initiate requests
session = requests.Session()
#Make a request to the login page using the session face
page_text = session.get(url='https://github.com/login',headers=headers).text
#Resolve the dynamic token value
tree = etree.HTML(page_text)
t = tree.xpath('//*[@id="login"]/form/input[2]/@value')[0]
#Specifies the url of the simulated login request
url = 'https://github.com/session'
#Parameter encapsulation (handling dynamic token values)
data = {
'commit': 'Sign in',
'authenticity_token': t,
'login': 'xxxxxxxxxxxx',
'password': 'xxxxxxxxxxx',
'webauthn-support': 'supported',
'webauthn-iuvpaa-support': 'supported',
'return_to': 'https://github.com/login',
'timestamp': '1634133256609',
'timestamp_secret': 'ed0138c3f1f7e90eb0aab250436132b1d9716ae4c1fe043621146d69a6f23040'
}
#Send simulated login request using session object (with cookie)
page_text = session.post(url=url,headers=headers,data=data).text
#Persistent storage
with open('./git.html','w',encoding='utf-8') as fp:
fp.write(page_text)
Note: this note is a study note and the content is a tutorial of station b