Data Acquisition for Public Comments - Basic Version
Popular Reviews is a third-party food-related review website that is very popular with the general public.
Therefore, the site's data is also very valuable.Preferential offers, number of evaluations, positive reviews and other data are also very popular with data companies.
Today I wrote a simple demo for data capture on the public comment list page.
I hope it will be helpful to your friends who read this article.
- Environment and Toolkit:
- python 3.6
- Self-built IP pool (proxy) (using ipidea Domestic Agents)
- parsel (page parsing)
- loguru (error alert)
Let me see how to start exploring
Step 1, Page Parsing
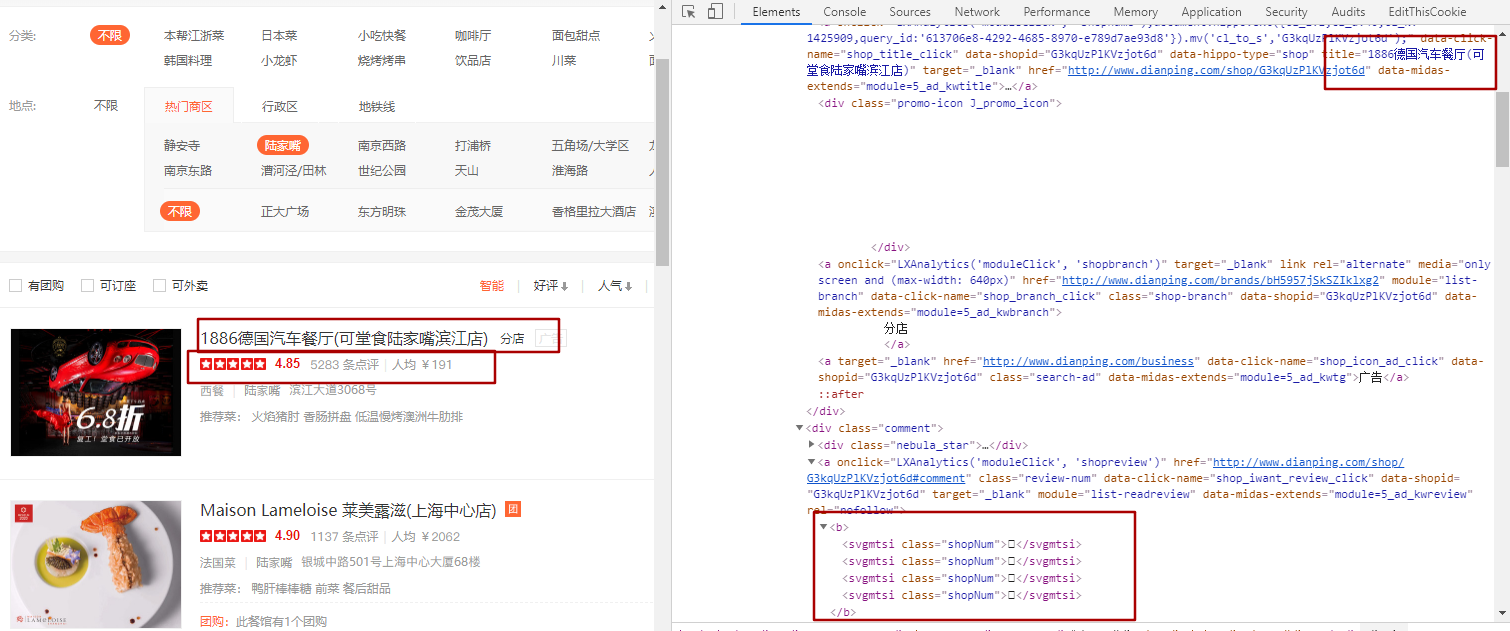
As you can see from the diagram, the corresponding numbers are boxes.What exactly is that?
The following image is what the console outputs after I have simply processed it.And right-click directly in html to view the web page source


Here you can see the next link
{'Name': 'Maison Lameloise Lemerooze(Shanghai Central Shop)', 'score': '4.90', 'Number of evaluations': '11\ueeb5\ue753', 'Per capita expenditure': '¥\uf802\uf0b6\ue753\ue867', 'Recommend': ['Duck Liver Lollipop', 'Front dish', 'Dessert after dinner']}<b>11<svgmtsi class="shopNum"></svgmtsi><svgmtsi class="shopNum"></svgmtsi></b> <b>¥<svgmtsi class="shopNum"></svgmtsi><svgmtsi class="shopNum"></svgmtsi><svgmtsi class="shopNum"></svgmtsi><svgmtsi class="shopNum"></svgmtsi></b>
That is, both the evaluation data and the per capita consumer price data should be hidden.
This focuses on svg mapping.
So how do you get this data?
First we need to find the woff font file they refer to when the web page opens.
In F12, select Network, and then Font in the third line of the menu bar.There are only a few woff files in the gossip of web access right now.
The next step is to open the file.
There are two ways to open it
-
Mode 1:
-
Download the target woff first, right-click the access content directly, and select "Open in new tab" to download the woff file
-
Open https://www.fontke.com/tool/convfont/this address and convert it to a ttf file online
-
Open the address http://fontstore.baidu.com/static/editor/index.html to parse the newly opened ttf file online
-
You can see this:
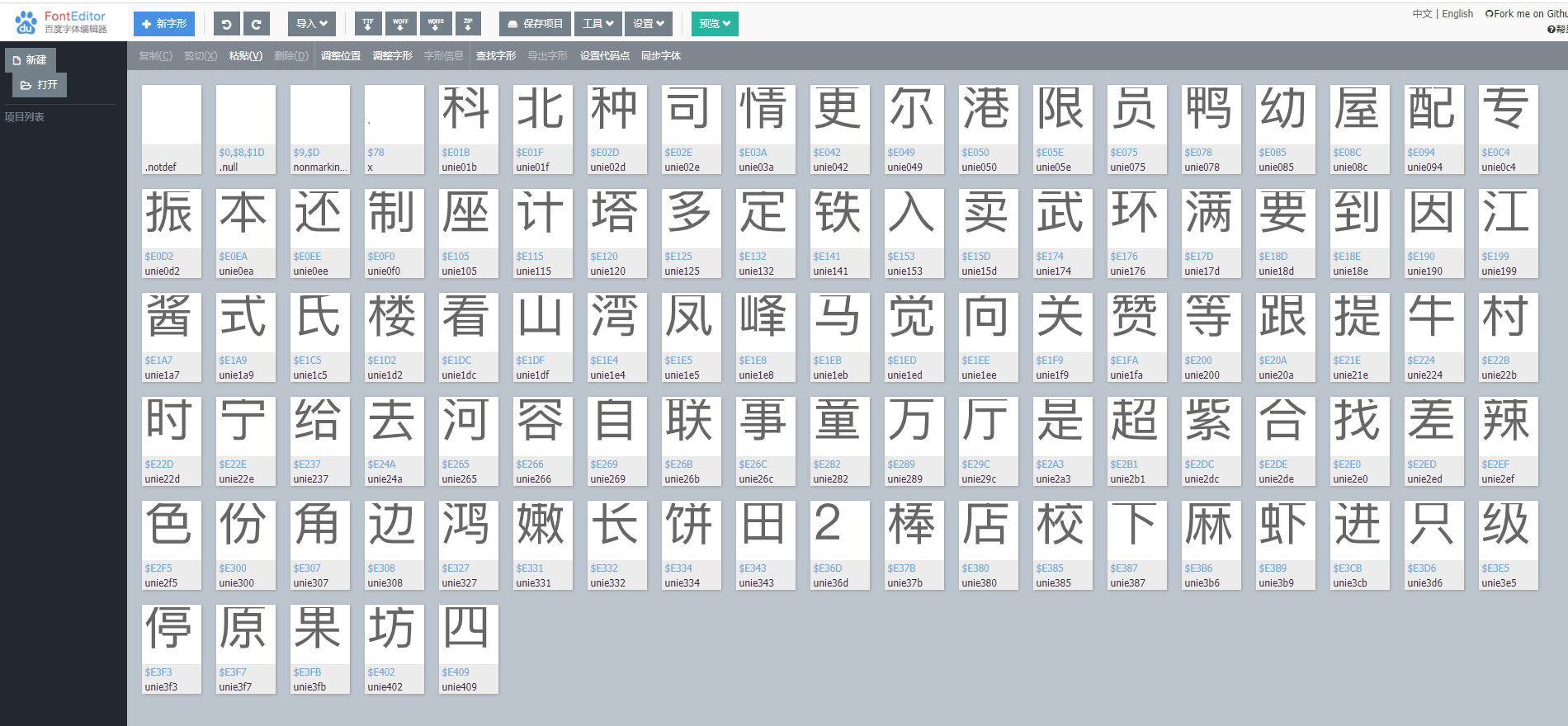
- By finding glyphs:
Through observation, we can see that the text codes in Baidu font parsing all start with "unie". Then we can verify if the codes correspond to the numbers displayed on the web page correctly by combining the codes we saw before and searching in the font file.
such as
 By mapping one to one, it's easy to know that'\ueeb5'is 3,'ue753' is 7, and why do you bother to do it all?
By mapping one to one, it's easy to know that'\ueeb5'is 3,'ue753' is 7, and why do you bother to do it all? There are two purposes, one is to verify this idea, the other is to lay an ambush for the next complex piece of content.

Truly, the corresponding character encoding was found in one of the files, indicating that the idea is correct
-
-
Mode 2:
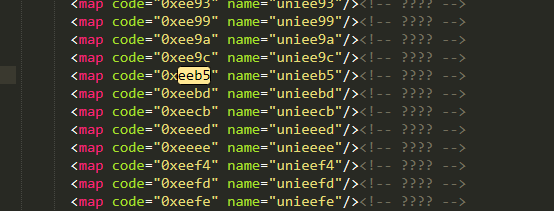
Installation required fontTools Package, not installed please ( pip install fontTools) from fontTools.ttLib import TTFont def get_xml(self): font = TTFont('dzdp.woff') font.saveXML('dzdp.xml')- Execute the above method (place it in the same directory as the script, change the name), and you'll get an xml file, then open the xml file with the tool, search directly for eeb5 globally, and you'll find this line soon.This will make it clear.The 0xeeb5 in the page and unieeb5 in the ttf file are meaningful correspondences.It also proves again that 0xxeb5 is the number 3
Construct Mapping Dictionary
From the page parsing just now, we already know that'\ueeb5'is 3 and'\ue753' is 7. So let's find other related numbers on the page again, [0-9] Ten numbers can be easily combined.Remember, 1 does not require refactoring.
self.woff = { "\uf0b6": "0", # "": "1", "\uf802": "2", "\ueeb5": "3", "\ueb5e": "4", "\uf508": "5", "\ue867": "6", "\ue753": "7", "\uf0a6": "8", "\uf506": "9", } Don't copy the data directly. The font svg of the comment changes frequently.Need to write about the situation yourselfThe savings are to process and parse the data directly.
The contents are as follows:
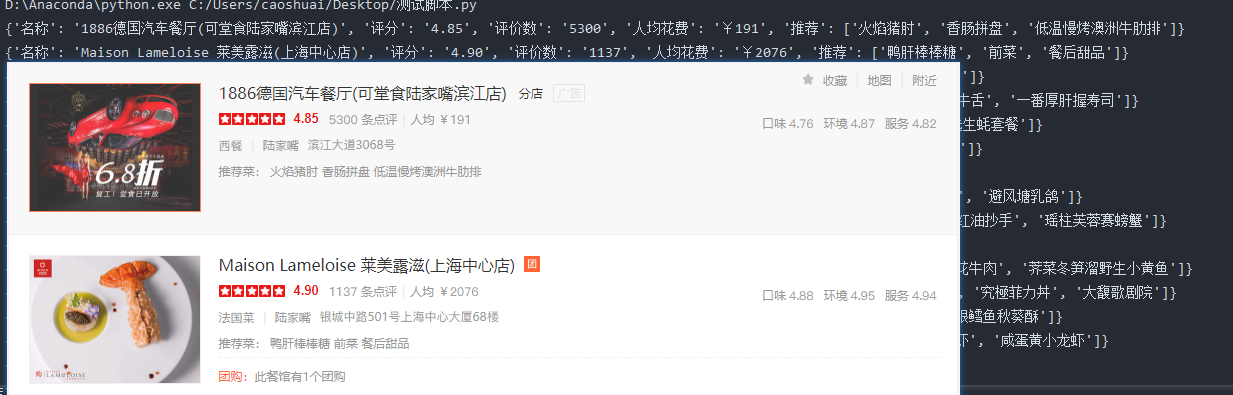
def get_count(self, uncode_list): try: count = "" for uncode in uncode_list: uncodes_ = uncode.replace('<svgmtsi class="shopNum"', "").replace("</svgmtsi", "").replace("</b>", "").replace( "</b>", "").replace("<b>", "").split('>') # pprint.pprint(uncodes_) for uncs in uncodes_: if uncs in self.woff.keys(): cc = self.woff[uncs] else: cc = uncs count += cc return count except Exception as e: logger.info("Error in number parsing") return uncode_list[0] def run(self): url = 'http://www.dianping.com/shanghai/ch10/r801' html = self.get_html(url) shop_el_list = html.css("#shop-all-list li") for shop_info in shop_el_list: item = {} shop_name = shop_info.css("div.txt div.tit a::attr(title) ").extract_first() item["Name"] = shop_name score = shop_info.css("div.txt div.comment div.nebula_star div.star_score::text").extract_first() item["score"] = score review_num = shop_info.css("div.txt div.comment>a.review-num > b ").extract() item["Number of evaluations"] = self.get_count(review_num) mean_price = shop_info.css("div.txt div.comment>a.mean-price > b ").extract() item["Per capita expenditure"]=self.get_count(mean_price) # item ["type"] # item ["address"] recommend = shop_info.css("div.txt div.recommend>a::text").extract() item["Recommend"] = recommend print(item)The above code is the two most critical parts of this demo, one is logic and the other is digital parsing.Here I'll explain without much effort.Let's see for ourselves.
Result Display
Disadvantages
-
If you comment on a different version of the map, let's redo the dictionary collection
-
Simply parse the mapping of the ten numbers [0-9].What do I want to do with the text?
There are two fields in my demo, Type and Address, that are not populated because they are text mapped, and this question will be answered in the next article.
It will also solve how to change the dynamic font on the review site.
Let's Python Crawler Comment Data Crawler Tutorial (2) See ~~
PS:
This article is intended for communication and sharing, [No reprinting without permission]