Now the regular expression is explained here
1). *? Is a fixed collocation. And * represent that any infinite number of characters can be matched, plus "*"? It means to use non greedy pattern to match, that is, we will match as short as possible, and we will use a lot of. *? Matching in the future.
2) (. *?) represents a group. In this regular expression, we match five groups. In the following traversal item, item[0] represents the content of the first (. *?), item[1] represents the content of the second (. *?), and so on.
3) the re.S flag represents any point matching mode when matching, and point. Can also represent line break.
In this way, we get the publisher, release time, release content, additional pictures and likes.
Note here that if the content we want to get is with pictures, it's cumbersome to output it directly, so here we only get the paragraphs without pictures.
So, here we need to filter the segments with pictures.
We can find that the segment with picture will have the following code, while the segment without picture will not. Therefore, the item[3] of our regular expression gets the following content. If there is no picture, the item[3] gets the empty content.
|
1
2
3
4
5
6
7
|
<div class="thumb">
<a href="/article/112061287?list=hot&s=4794990" target="_blank">
< img SRC = "http://pic.qiushibaike.com/system/pictures/11206/112061287/medium/app112061287. JPG" ALT = "but they are still optimistic" >
</a>
</div>
|
So we just need to judge whether the item[3] contains img tags.
The complete code of this article is as follows:
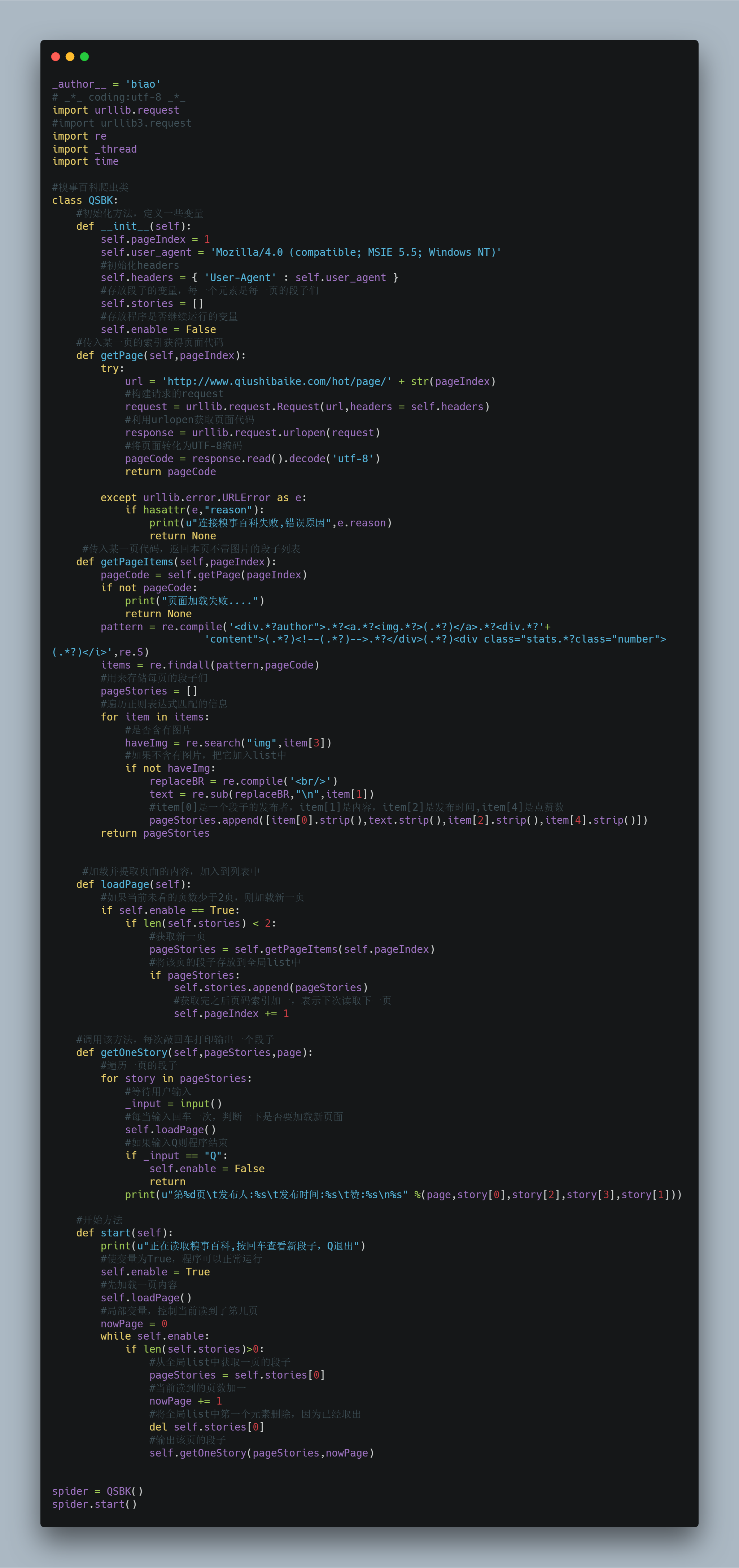
1 _author__ = 'biao' 2 # _*_ coding:utf-8 _*_ 3 import urllib.request 4 #import urllib3.request 5 import re 6 import _thread 7 import time 8 9 #Embarrassing encyclopedia reptiles 10 class QSBK: 11 #Initialization method, defining some variables 12 def __init__(self): 13 self.pageIndex = 1 14 self.user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' 15 #Initialization headers 16 self.headers = { 'User-Agent' : self.user_agent } 17 #The variables that store the segments. Each element is the segments on each page 18 self.stories = [] 19 #Variables to store whether the program continues to run 20 self.enable = False 21 #Get the page code by passing in the index of a page 22 def getPage(self,pageIndex): 23 try: 24 url = 'http://www.qiushibaike.com/hot/page/' + str(pageIndex) 25 #Build requested request 26 request = urllib.request.Request(url,headers = self.headers) 27 #utilize urlopen Get page code 28 response = urllib.request.urlopen(request) 29 #Convert page to UTF-8 Code 30 pageCode = response.read().decode('utf-8') 31 return pageCode 32 33 except urllib.error.URLError as e: 34 if hasattr(e,"reason"): 35 print(u"Failed to connect to Encyclopedia of embarrassing events,Error reason",e.reason) 36 return None 37 #Pass in a page code to return the segment sublist without picture on this page 38 def getPageItems(self,pageIndex): 39 pageCode = self.getPage(pageIndex) 40 if not pageCode: 41 print("Page load failed....") 42 return None 43 pattern = re.compile('<div.*?author">.*?<a.*?<img.*?>(.*?)</a>.*?<div.*?'+ 44 'content">(.*?)<!--(.*?)-->.*?</div>(.*?)<div class="stats.*?class="number">(.*?)</i>',re.S) 45 items = re.findall(pattern,pageCode) 46 #Used to store every page's paragraphs 47 pageStories = [] 48 #Information of traversal regular expression matching 49 for item in items: 50 #Include pictures or not 51 haveImg = re.search("img",item[3]) 52 #If not, add it list in 53 if not haveImg: 54 replaceBR = re.compile('<br/>') 55 text = re.sub(replaceBR,"\n",item[1]) 56 #item[0]Is the publisher of a paragraph, item[1]It's content. item[2]Is the release time,item[4]It's a point of praise. 57 pageStories.append([item[0].strip(),text.strip(),item[2].strip(),item[4].strip()]) 58 return pageStories 59 60 61 #Load and extract the content of the page and add it to the list 62 def loadPage(self): 63 #If the number of pages not currently viewed is less than 2, load a new page 64 if self.enable == True: 65 if len(self.stories) < 2: 66 #Get a new page 67 pageStories = self.getPageItems(self.pageIndex) 68 #Save the segment of this page to the global list in 69 if pageStories: 70 self.stories.append(pageStories) 71 #Add one to the index of the page number after obtaining, indicating that the next page will be read next time 72 self.pageIndex += 1 73 74 #Call this method to print one segment each time you hit enter 75 def getOneStory(self,pageStories,page): 76 #Segments traversing a page 77 for story in pageStories: 78 #Waiting for user input 79 _input = input() 80 #Every time you enter a carriage return, determine whether you want to load a new page 81 self.loadPage() 82 #If input Q Then the program ends 83 if _input == "Q": 84 self.enable = False 85 return 86 print(u"The first%d page\t Publisher:%s\t Release time:%s\t Fabulous:%s\n%s" %(page,story[0],story[2],story[3],story[1])) 87 88 #Starting method 89 def start(self): 90 print(u"Reading the Encyclopedia of embarrassing things,Press enter to view the new paragraph, Q Sign out") 91 #Making variables True,The program can run normally 92 self.enable = True 93 #Load one page first 94 self.loadPage() 95 #Local variable, control current page read 96 nowPage = 0 97 while self.enable: 98 if len(self.stories)>0: 99 #From the overall situation list Get a page's paragraph from 100 pageStories = self.stories[0] 101 #Current number of pages read plus one 102 nowPage += 1 103 #Global list The first element in is deleted because it has been removed 104 del self.stories[0] 105 #Output the segment of this page 106 self.getOneStory(pageStories,nowPage) 107 108 109 spider = QSBK() 110 spider.start() 111 112 113 ''' 114 def run_demo(): 115 f=urllib.request.urlopen('http://www.baidu.com') 116 print(f.read()) 117 118 if __name__=='__main__': 119 run_demo() 120 ''' 121 122 ''' 123 page = 1 124 url = 'http://www.qiushibaike.com/hot/page/' + str(page) 125 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' 126 headers = { 'User-Agent' : user_agent } 127 try: 128 request = urllib.request.Request(url,headers = headers) 129 response = urllib.request.urlopen(request) 130 content = response.read().decode('utf-8') 131 pattern = re.compile('<div.*?author">.*?<a.*?<img.*?>(.*?)</a>.*?<div.*?'+ 132 'content">(.*?)<!--(.*?)-->.*?</div>(.*?)<div class="stats.*?class="number">(.*?)</i>',re.S) 133 items = re.findall(pattern,content) 134 for item in items: 135 haveImg = re.search("img",item[3]) 136 if not haveImg: 137 print(item[0],item[1],item[2],item[4]) 138 # print(response.read()) 139 except urllib.error.HTTPError as e: 140 if hasattr(e,"code"): 141 print(e.code) 142 if hasattr(e,"reason"): 143 print(e.reason) 144 '''