http://blog.csdn.net/qiqiyingse http://blog.csdn.net/qiqiyingse/article/details/78501034
People who often visit stations A and B are certainly familiar with a program.< Common GIF Dynamic Diagrams on the Network>
Today I'm going to share how to automatically store these actions in my computer through the crawler (in fact, this program was written in May, and it's been delayed until now to share it).
I. Thought Analysis
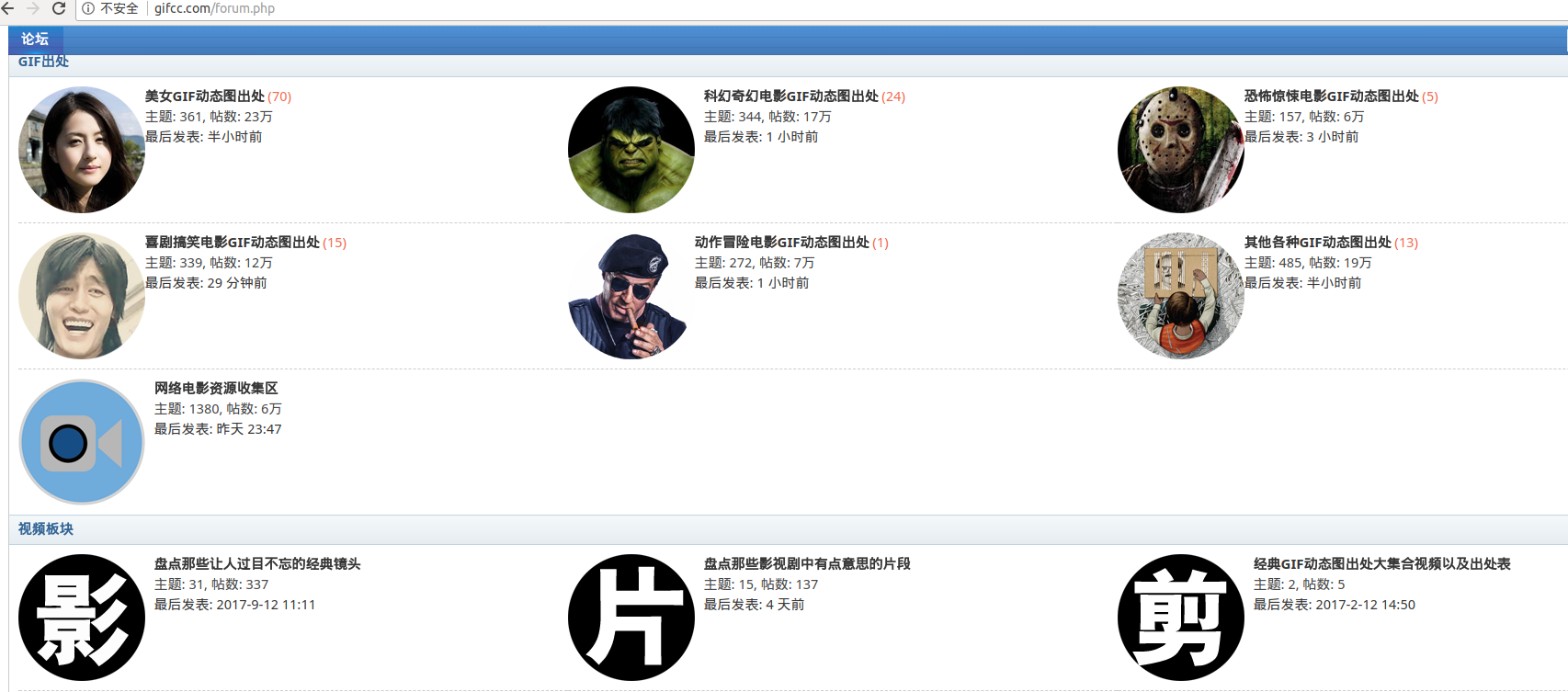
'http://gifcc.com/forum-38-1.html', #Beauty GIF Dynamic Map Origin
'http://gifcc.com/forum-47-1.html', # Sci-fi Fantasy Movie GIF Dynamic Map Origin
'http://gifcc.com/forum-48-1.html', #Comedy Funny Movie GIF Dynamic Map Origin
'http://gifcc.com/forum-49-1.html', #Action Adventure Movie GIF Dynamic Map Origin
'http://gifcc.com/forum-50-1.html'# Horror thriller movie GIF Dynamic Map Origin
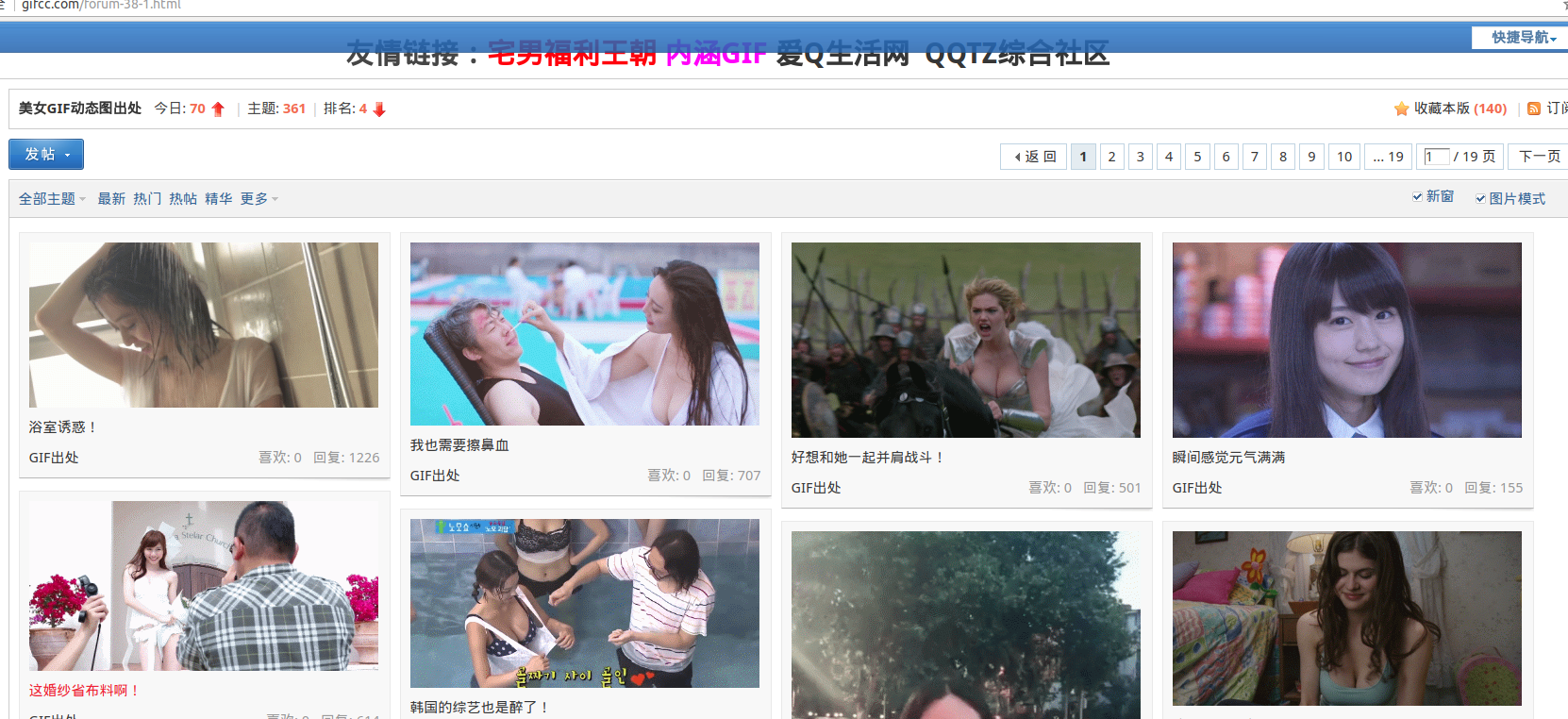
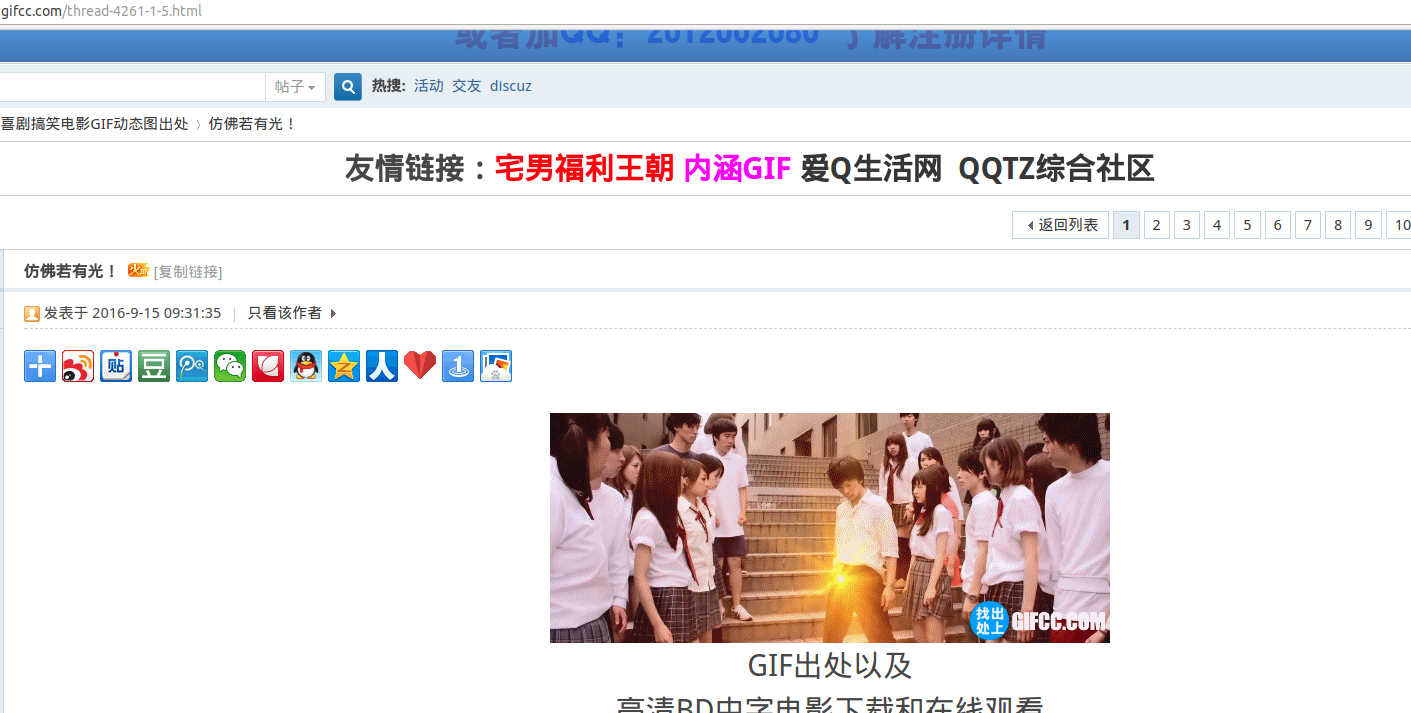
Second Start

- #Get only the content of the page
- def get_html_Pages(self,url):
- try:
- #browser = webdriver.PhantomJS(executable_path=r'C:\Python27\Scripts\phantomjs.exe')
- browser = webdriver.PhantomJS()
- browser.get(url)
- html = browser.execute_script("return document.documentElement.outerHTML")
- browser.close()
- html=HTMLParser.HTMLParser().unescape(html).decode('utf-8')
- return html
- #Catch exceptions to prevent programs from dying directly.
- except Exception,e:
- print u"Connection Failure, Error Cause",e
- return None
- #Get the page number.
- def get_page_num(self,html):
- doc = pq(html)
- print u'Start getting the total page number'
- #print doc('head')('title').text()#Get the current title
- try:
- #If the current page is too many, more than eight pages, use another way to get the page number
- if doc('div[class="pg"]')('[class="last"]'):
- num_content= doc('div[class="pg"]')('[class="last"]').attr('href')
- print num_content.split('-')[1].split('.')[0]
- return num_content.split('-')[1].split('.')[0]
- else:
- num_content= doc('div[class="pg"]')('span')
- return filter(str.isdigit,str(num_content.text()))[0]
- #If the acquisition of the page number fails, then return 1, i.e., the value of the acquisition of a page content.
- except Exception,e:
- print u'Failed to get page number'.e
- return '1'
Here, a module pq, PyQuery, is used for page number processing.
from pyquery import PyQuery as pq
Using PyQuery to find the elements we need, it feels better and more convenient.
At the same time, the processing here is a little interesting, if you look at this page, you will find that the number of pages of each module, there is one above and below, and then I cut it here, because we only need a number of pages.
3-6 Step 3 to Step 6
In fact, it is based on the number of pages to traverse, to get the content of each page.
Then get all the picture addresses on each page.
When retrieving the content of each page, you need to reassemble the page address.
- print u'All in all %d Page content' % int(page_num)
- #3. Traversing through the content of each page
- for num in range(1,int(page_num)):
- #4. Assemble new URLs
- new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
- print u'The upcoming page is:',new_url
- #5. Load each page to get the contents of the gif list
- items=self.parse_items_by_html(self.get_all_page(new_url))
- print u'In the first place%d Page, found%d Picture content' % (num,len(items))
- #6. Processing the content of each element
- self.get_items_url(items,num)
With the new address, you can get the content of the current page and process the data to get the address list of each picture.
- #4. Assemble new URLs
- new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
- print u'The upcoming page is:',new_url
- #5. Load each page to get the contents of the gif list
- items=self.parse_items_by_html(self.get_all_page(new_url))
- print u'In the first place%d Page, found%d Picture content' % (num,len(items))
After getting the list of pictures, parse it again to get the URL of each picture.
- #Parse the page content to get the list of gif images
- def parse_items_by_html(self, html):
- doc = pq(html)
- print u'Start looking for content msg'
- return doc('div[class="c cl"]')
Here, integrate the data to prepare for writing the data to the database.
- #Parse the list of gif to process each gif content
- def get_items_url(self,items,num):
- i=1
- for article in items.items():
- print u'Start processing data(%d/%d)' % (i, len(items))
- #print article
- self.get_single_item(article,i,num)
- i +=1
- #Processing a single gif content to get its address, gif final address
- def get_single_item(self,article,num,page_num):
- gif_dict={}
- #Address of each page
- gif_url= 'http://gifcc.com/'+article('a').attr('href')
- #Title of each page
- gif_title= article('a').attr('title')
- #The specific address of each graph
- #html=self.get_html_Pages(gif_url)
- #gif_final_url=self.get_final_gif_url(html)
- gif_dict['num']=num
- gif_dict['page_num']=page_num
- gif_dict['gif_url']=gif_url
- gif_dict['gif_title']=gif_title
- self.gif_list.append(gif_dict)
- data=u'The first'+str(page_num)+'page|\t'+str(num)+'|\t'+gif_title+'|\t'+gif_url+'\n'
- self.file_flag.write(data)
7. Store pictures locally and write data to the database
So far, the general content has been completed.
- #Use urllib2 to get the final address of the picture
- def get_final_gif_url_use_urllib2(self,url):
- try:
- html= urllib2.urlopen(url).read()
- gif_pattern=re.compile('<div align="center.*?<img id=.*?src="(.*?)" border.*?>',re.S)
- return re.search(gif_pattern,html).group(1)
- except Exception,e:
- print u'Error getting page content:',e
- #Final Processing Storage of Data
- def get_gif_url_and_save_gif(self):
- def save_gif(url,name):
- try:
- urllib.urlretrieve(url, name)
- except Exception,e:
- print 'Storage failure due to:',e
- for i in range(0,len(self.gif_list)):
- gif_dict=self.gif_list[i]
- gif_url=gif_dict['gif_url']
- gif_title=gif_dict['gif_title']
- #Still use webdriver to get the final gif address
- final_html=self.get_html_Pages(gif_url)
- gif_final_url=self.get_final_gif_url(final_html)
- #Use another way (urllib2) to get the final address
- #gif_final_url=self.get_final_gif_url_use_urllib2(gif_url)
- gif_dict['gif_final_url']=gif_final_url
- print u'Start writing to the database%d Page No.%d Item data and start storing pictures locally ' % (gif_dict['page_num'],gif_dict['num'])
- self.BookTable.insert_one(gif_dict)
- gif_name=self.dir_name+'/'+gif_title+'.gif'
- save_gif(gif_final_url,gif_name)
We can save all the dynamic maps of each module of this forum locally, and at the same time, put the data into the database.
Screening of three databases
After putting the data into the database, I thought I could save the pictures directly by calling the database.
(Why do you think so, because I found that if you store pictures directly in the main program, it runs too slowly, so it's better to put all the data in the database, and then call the database to store pictures exclusively.)
But here's a problem. There's a lot of content in the data, and then there's a lot of duplication, so we need to de-duplicate the database.
As for the content of data de-duplication, in fact, I have already written the previous article (at the time of writing that article, the crawler has been completed ~)
The main idea is to operate on the number of a certain element. There is a method in pymongo that can count the number of specified elements. If there is only one element at present, it will be deleted regardless of whether it is an element or not.
The core code is as follows:
- for url in collection.distinct('name'):#Using distinct method, get a list of each unique element
- num= collection.count({"name":url})#Statistics the number of each element
- print num
- for i in range(1,num):#According to the number of each element, delete operation, the current element has only one will not be deleted.
- print 'delete %s %d times '% (url,i)
- #Notice the latter parameter. Strangely, on the mongo command line, it deletes an element at 1:00, but here it deletes an element at 0:00.
- collection.remove({"name":url},0)
- for i in collection.find({"name":url}):#Print all current elements
- print i
- print collection.distinct('name')#Print again the elements to be duplicated
Fourth, read the contents of the database and store pictures
It's much more convenient to store pictures again after data is de-duplicated.
After that, if the image is deleted, and you don't have to run away again, or sometimes the local image takes up space, you just need to save the data in the database.
The core code is as follows:
- def save_gif(url,name):
- try:
- urllib.urlretrieve(url, name)
- except Exception,e:
- print u'Storage failure due to:',e
- client = pymongo.MongoClient('localhost', 27017)
- print client.database_names()
- db = client.GifDB
- for table in db.collection_names():
- print 'table name is ',table
- collection=db[table]
- for item in collection.find():
- try:
- if item['gif_final_url']:
- url,url_title= item['gif_final_url'],item['gif_title']
- gif_filename=table+'/'+url_title+'.gif'
- print 'start save %s, %s' % (url,gif_filename)
- save_gif(url,gif_filename)
- except Exception,e:
- print u'Reasons for error:',e
Complete code
02_delete_repeat_url_in_mongodb.py
- #coding: utf-8
- from pyquery import PyQuery as pq
- from selenium import webdriver
- import HTMLParser,urllib2,urllib,re,os
- import pymongo
- import time
- import sys
- reload(sys)
- sys.setdefaultencoding('utf-8')
- class download_gif:
- def __init__(self):
- self.url='http://gifcc.com/forum-38-1.html'
- self.url_list=['http://gifcc.com/forum-37-1.html',#Other sources of various GIF dynamic maps
- 'http://gifcc.com/forum-38-1.html', #Beauty GIF Dynamic Map Origin
- 'http://gifcc.com/forum-47-1.html',#The Origin of GIF Dynamic Map of Science Fiction Fantasy Movie
- 'http://gifcc.com/forum-48-1.html',#The Origin of GIF Dynamic Map of Comedy Funny Movie
- 'http://gifcc.com/forum-49-1.html',#Origin of Action Adventure Movie GIF Dynamic Map
- 'http://gifcc.com/forum-50-1.html'#The Origin of GIF Dynamic Map of Horror and Thriller Movie
- ]
- self.choices={'1':u'Other kinds GIF Origin of Dynamic Graph',
- '2':u'Beauty GIF Origin of Dynamic Graph',
- '3':u'Science fiction fantasy movies GIF Origin of Dynamic Graph',
- '4':u'Comedy Funny Film GIF Origin of Dynamic Graph',
- '5':u'Action Adventure Film GIF Origin of Dynamic Graph',
- '6':u'Horror thriller movies GIF Origin of Dynamic Graph'
- }
- self.dir_name=u'gif Source'
- self.gif_list=[]
- self.connection = pymongo.MongoClient()
- #BookTable.insert_one(dict_data)#Insert single data
- #BookTable.insert(dict_data)#Insert dictionary list data
- #Get the content of the page, and load JS, scroll to get more elements of the page
- def get_all_page(self,url):
- try:
- #browser = webdriver.PhantomJS(executable_path=r'C:\Python27\Scripts\phantomjs.exe')
- browser = webdriver.PhantomJS()
- browser.get(url)
- #time.sleep(3)
- #Page scroll
- js = "var q=document.body.scrollTop=100000"
- #for i in range(5): #Debugging statements, do not load too many times for the time being
- for i in range(30):
- #Loop down 50 times.
- browser.execute_script(js)
- #Load once, take a rest.
- time.sleep(1)
- print u'This is the first. %d Subscratch Page' % i
- #Executing js to get the whole page content
- html = browser.execute_script("return document.documentElement.outerHTML")
- browser.close()
- html=HTMLParser.HTMLParser().unescape(html)
- return html
- except Exception,e:
- print u'Errors occurred:',e
- #Parse the page content to get the list of gif images
- def parse_items_by_html(self, html):
- doc = pq(html)
- print u'Start looking for content msg'
- return doc('div[class="c cl"]')
- #Parse the list of gif to process each gif content
- def get_items_url(self,items,num):
- i=1
- for article in items.items():
- print u'Start processing data(%d/%d)' % (i, len(items))
- #print article
- self.get_single_item(article,i,num)
- i +=1
- #Processing a single gif content to get its address, gif final address
- def get_single_item(self,article,num,page_num):
- gif_dict={}
- #Address of each page
- gif_url= 'http://gifcc.com/'+article('a').attr('href')
- #Title of each page
- gif_title= article('a').attr('title')
- #The specific address of each graph
- #html=self.get_html_Pages(gif_url)
- #gif_final_url=self.get_final_gif_url(html)
- gif_dict['num']=num
- gif_dict['page_num']=page_num
- gif_dict['gif_url']=gif_url
- gif_dict['gif_title']=gif_title
- self.gif_list.append(gif_dict)
- data=u'The first'+str(page_num)+'page|\t'+str(num)+'|\t'+gif_title+'|\t'+gif_url+'\n'
- self.file_flag.write(data)
- #After getting the content of the page through webdriver, get the final address
- def get_final_gif_url(self,html):
- doc = pq(html)
- image_content= doc('td[class="t_f"]')
- gif_url= image_content('img').attr('src')
- return gif_url
- #Use urllib2 to get the final address of the picture
- def get_final_gif_url_use_urllib2(self,url):
- try:
- html= urllib2.urlopen(url).read()
- gif_pattern=re.compile('<div align="center.*?<img id=.*?src="(.*?)" border.*?>',re.S)
- return re.search(gif_pattern,html).group(1)
- except Exception,e:
- print u'Error getting page content:',e
- #Final Processing Storage of Data
- def get_gif_url_and_save_gif(self):
- def save_gif(url,name):
- try:
- urllib.urlretrieve(url, name)
- except Exception,e:
- print 'Storage failure due to:',e
- for i in range(0,len(self.gif_list)):
- gif_dict=self.gif_list[i]
- gif_url=gif_dict['gif_url']
- gif_title=gif_dict['gif_title']
- #Still use webdriver to get the final gif address
- final_html=self.get_html_Pages(gif_url)
- gif_final_url=self.get_final_gif_url(final_html)
- #Use another way (urllib2) to get the final address
- #gif_final_url=self.get_final_gif_url_use_urllib2(gif_url)
- gif_dict['gif_final_url']=gif_final_url
- print u'Start writing to the database%d Page No.%d Item data and start storing pictures locally ' % (gif_dict['page_num'],gif_dict['num'])
- self.BookTable.insert_one(gif_dict)
- gif_name=self.dir_name+'/'+gif_title+'.gif'
- save_gif(gif_final_url,gif_name)
- #Get only the content of the page
- def get_html_Pages(self,url):
- try:
- #browser = webdriver.PhantomJS(executable_path=r'C:\Python27\Scripts\phantomjs.exe')
- browser = webdriver.PhantomJS()
- browser.get(url)
- html = browser.execute_script("return document.documentElement.outerHTML")
- browser.close()
- html=HTMLParser.HTMLParser().unescape(html).decode('utf-8')
- return html
- #Catch exceptions to prevent programs from dying directly.
- except Exception,e:
- print u"Connection Failure, Error Cause",e
- return None
- #Get the page number.
- def get_page_num(self,html):
- doc = pq(html)
- print u'Start getting the total page number'
- #print doc('head')('title').text()#Get the current title
- try:
- #If the current page is too many, more than eight pages, use another way to get the page number
- if doc('div[class="pg"]')('[class="last"]'):
- num_content= doc('div[class="pg"]')('[class="last"]').attr('href')
- print num_content.split('-')[1].split('.')[0]
- return num_content.split('-')[1].split('.')[0]
- else:
- num_content= doc('div[class="pg"]')('span')
- return filter(str.isdigit,str(num_content.text()))[0]
- #If the acquisition of the page number fails, then return 1, i.e., the value of the acquisition of a page content.
- except Exception,e:
- print u'Failed to get page number'.e
- return '1'
- # filter(str.isdigit,num_content)#Extracting numbers from strings
- #Create folders
- def mk_dir(self,path):
- if not os.path.exists(path):
- os.makedirs(path)
- def set_db(self,tablename):
- self.BookDB = self.connection.GifDB #Name of database db
- self.BookTable =self.BookDB[tablename] #Name of database table table
- #Main function
- def run(self):
- choice_type=5
- if choice_type:
- #for choice_type in range(len(self.choices)):
- if choice_type+1:
- self.dir_name=self.choices[str(choice_type+1)].strip()
- self.url=self.url_list[int(choice_type)]
- print self.dir_name,self.url
- #0. Create folders to store pictures and file contents
- self.mk_dir(self.dir_name)
- self.filename=self.dir_name+'/'+self.dir_name+'.txt'
- print self.filename
- self.file_flag=open(self.filename,'w')
- self.set_db(self.dir_name)
- self.BookTable .insert({'filename':self.dir_name})
- print self.url
- #1. Get the content of the entry page
- html=self.get_html_Pages(self.url)
- #2. Get the number of pages
- page_num=self.get_page_num(html)
- print u'All in all %d Page content' % int(page_num)
- #3. Traversing through the content of each page
- #page_num=3#Debugging statements, first temporarily set the content of the page a little smaller
- for num in range(1,int(page_num)):
- #4. Assemble new URLs
- new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
- print u'The upcoming page is:',new_url
- #5. Load each page to get the contents of the gif list
- items=self.parse_items_by_html(self.get_all_page(new_url))
- print u'In the first place%d Page, found%d Picture content' % (num,len(items))
- #6. Processing the content of each element
- self.get_items_url(items,num)
- #5. After all the data has been captured, we begin to process the data.
- self.get_gif_url_and_save_gif()
- print 'success'
- self.file_flag.close()
- if __name__ == '__main__':
- print u'''''
- **************************************************
- ** Welcome to Spider of GIF Source picture **
- ** Created on 2017-05-21 **
- ** @author: Jimy _Fengqi **
- **************************************************
- '''
- print u''''' Select what you want to download gif Picture type
- 1:'Other kinds GIF Origin of Dynamic Graph'
- 2:'Beauty GIF Origin of Dynamic Graph'
- 3:'Science fiction fantasy movies GIF Origin of Dynamic Graph'
- 4:'Comedy Funny Film GIF Origin of Dynamic Graph'
- 5:'Action Adventure Film GIF Origin of Dynamic Graph'
- 6:'Horror thriller movies GIF Origin of Dynamic Graph'
- '''
- #Select the type to download.
- mydownload=download_gif()
- html=mydownload.run()
- #coding: utf-8
- from pyquery import PyQuery as pq
- from selenium import webdriver
- import HTMLParser,urllib2,urllib,re,os
- import pymongo
- import time
- import sys
- reload(sys)
- sys.setdefaultencoding('utf-8')
- import pymongo
- def save_gif(url,name):
- try:
- urllib.urlretrieve(url, name)
- except Exception,e:
- print 'Storage failure due to:',e
- def print_database_and_table_name():
- import pymongo
- client = pymongo.MongoClient('localhost', 27017)
- print client.database_names()
- for database in client.database_names():
- for table in client[database].collection_names():
- print 'table [%s] is in database [%s]' % (table,database)
- def delete_single_database_repeat_data():
- import pymongo
- client = pymongo.MongoClient('localhost', 27017)
- db=client.GifDBtemptemp2#Here's the database name for the data to be cleaned
- for table in db.collection_names():
- print 'table name is ',table
- collection=db[table]
- for url in collection.distinct('gif_title'):#Using distinct method, get a list of each unique element
- num= collection.count({"gif_title":url})#Statistics the number of each element
- print num
- for i in range(1,num):#According to the number of each element, delete operation, the current element has only one will not be deleted.
- print 'delete %s %d times '% (url,i)
- #Notice the latter parameter. Strangely, on the mongo command line, it deletes an element at 1:00, but here it deletes an element at 0:00.
- collection.remove({"gif_title":url},0)
- for i in collection.find({"gif_title":url}):#Print all current elements
- print i
- def delete_repeat_data():
- import pymongo
- client = pymongo.MongoClient('localhost', 27017)
- db = client.local
- collection = db.person
- for url in collection.distinct('name'):#Using distinct method, get a list of each unique element
- num= collection.count({"name":url})#Statistics the number of each element
- print num
- for i in range(1,num):#According to the number of each element, delete operation, the current element has only one will not be deleted.
- print 'delete %s %d times '% (url,i)
- #Notice the latter parameter. Strangely, on the mongo command line, it deletes an element at 1:00, but here it deletes an element at 0:00.
- collection.remove({"name":url},0)
- for i in collection.find({"name":url}):#Print all current elements
- print i
- print collection.distinct('name')#Print again the elements to be duplicated
- delete_single_database_repeat_data()
03_from_mongodb_save_pic.py
Github address: https://github.com/JimyFengqi/Gif_Spide
- #coding: utf-8
- from pyquery import PyQuery as pq
- from selenium import webdriver
- import HTMLParser,urllib2,urllib,re,os
- import pymongo
- import time
- import sys
- reload(sys)
- sys.setdefaultencoding('utf-8')
- import pymongo
- def save_gif(url,name):
- try:
- urllib.urlretrieve(url, name)
- except Exception,e:
- print u'Storage failure due to:',e
- client = pymongo.MongoClient('localhost', 27017)
- print client.database_names()
- db = client.GifDB
- for table in db.collection_names():
- print 'table name is ',table
- collection=db[table]
- for item in collection.find():
- try:
- if item['gif_final_url']:
- url,url_title= item['gif_final_url'],item['gif_title']
- gif_filename=table+'/'+url_title+'.gif'
- print 'start save %s, %s' % (url,gif_filename)
- save_gif(url,gif_filename)
- except Exception,e:
- print u'Reasons for error:',e
r