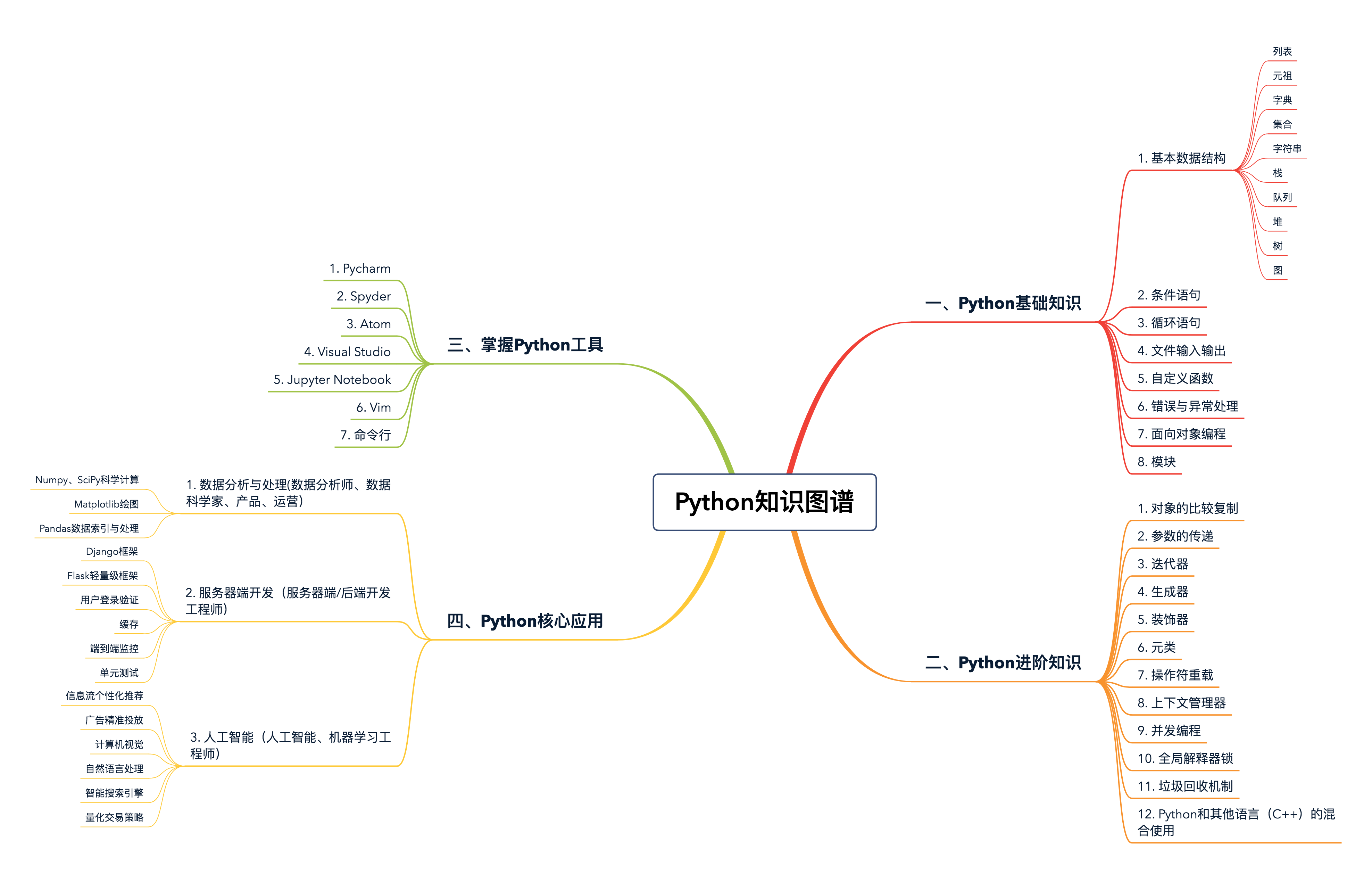
Basic articles
Jupyter Notebook
Advantage
- Integrate all resources
- Interactive programming experience
- Zero Cost Reproduction Results
Practice site
Lists and tuples
Lists and tuples are ordered collections that can place arbitrary data types.
l = [1, 2, 'hello', 'world'] # The list contains both int and string elements
l
[1, 2, 'hello', 'world']
tup = ('jason', 22) # Tuples contain both int and string elements
tup
('jason', 22)- Lists are dynamic, with varying lengths and sizes, and can be added, deleted, or changed at will.
- The tuple is static, the size of the site is fixed, and it cannot be added, deleted or changed (immutable).
- Negative index is supported.
- All support slicing operation.
- They can be nested at will.
- They can be converted to each other by list() and tuple() functions.
Differences between List and Tuple Storage
Because the list is dynamic, it needs to store pointers to point to the corresponding elements. The time complexity of add/delete is O(1).
l = [] l.__sizeof__() // The empty list has 40 bytes of storage space 40 l.append(1) l.__sizeof__() 72 // After adding element 1, the list allocates space for four elements (72 - 40)/8 = 4 l.append(2) l.__sizeof__() 72 // Since space was previously allocated, element 2 was added, and the list space remained unchanged. l.append(3) l.__sizeof__() 72 // Ditto l.append(4) l.__sizeof__() 72 // Ditto l.append(5) l.__sizeof__() 104 // After adding element 5, the list has insufficient space, so additional space is allocated to store four elements.
Usage scenarios
- If the amount of data stored remains unchanged, tuples are certainly more appropriate.
- If the amount and data stored are variable, lists are more appropriate.
Difference
- Lists are dynamic, variable in length, and can add, delete or change elements at will; the storage space of lists is slightly larger than tuples, and the performance is slightly worse than tuples.
- Tuples are static, with fixed length and size, and can not add, delete or modify elements. Tuples are lighter and have better performance than lists.
Thinking questions
# Create an empty list # option A: list() is a function call. Python's function call creates a stack and performs a series of parameter checks to compare expensive. empty_list = list() # option B:[] is a built-in C function that can be called directly, so it is efficient. empty_list = []
Dictionaries and Collections
Dictionary is a combination of a series of disordered elements, whose length and size are variable, and elements can be deleted and changed arbitrarily. Compared with list and tuple, dictionary has better performance. Especially for search, add and delete operations, dictionary can be completed in constant time complexity. The set and dictionary are basically the same, the only difference is that the set has no pairing of parts and values, and is a series of disorderly and unique elements combination.
# Definition dictionary
d = {'name': 'jason', 'age': 20}
# Add elements to'gender':'male'
d['gender'] = 'male'
# Add element pairs to'dob':'1999-02-01'
d['dob'] = '1999-02-01'
d
{'name': 'jason', 'age': 20, 'gender': 'male', 'dob': '1999-02-01'}
# Update key'dob'corresponding value
d['dob'] = '1998-01-01'
# Delete element pairs with key'dob'
d.pop('dob')
'1998-01-01'
d
{'name': 'jason', 'age': 20, 'gender': 'male'}
# Definition set
s = {1, 2, 3}
# Add element 4 to the collection
s.add(4)
s
{1, 2, 3, 4}
# Delete element 4 from the collection
s.remove(4)
s
{1, 2, 3}
d = {'b': 1, 'a': 2, 'c': 10}
# Sort by ascending order of dictionary keys
d_sorted_by_key = sorted(d.items(), key=lambda x: x[0])
# Sort by ascending order of dictionary values
d_sorted_by_value = sorted(d.items(), key=lambda x: x[1])You can use the get(key,default) function for dictionary indexing. If the key does not exist, calling the function returns a default value.
Collections do not support indexing because they are essentially a hash table, unlike lists.
Dictionary and Collection Performance
Dictionaries and collections are highly performance-optimized data structures, especially for lookup, addition, and deletion operations.
How Dictionaries and Collections Work
The internal structure of dictionaries and collections is a hash table
- For dictionaries, this hash table stores three elements: hash value, key and value.
- For collections, the difference is that there is no pairing of keys and values in the hash table, only a single element.
Insert operation
Each time an element is inserted into a dictionary or collection, Python first calculates the hash(key) of the key, and then does the operation with mask = PyDicMinSize - 1, calculating the location index of the element that should be inserted into the hash table = hash(key) & mask. If this position in the hash table is empty, the element is inserted into it. If this location is occupied, Python compares the hash values and keys of the two elements.
- If both are equal, it indicates that the element already exists, and if the values are different, it updates the values.
- If one of the two elements is not equal, we usually call it hash collision, which means that the keys of the two elements are not equal, but the hash values are equal. In this case, Python will continue to find the empty position in the table until it finds the position.
Lookup operation
First find the target location by hash value, and then compare the hash value and key of the element in the hash table, whether they are equal to the element that needs to be searched, if they are equal, return directly. Otherwise, continue searching until it is empty or throws an exception.
Delete operation
Temporarily assign a special value to the element at this location, and then delete it when the hash table is resized.
Character string
- Strings in Python are represented by single quotation marks, double quotation marks or triple quotation marks, which have the same meaning and no difference. Among them, three-quoted strings are usually used in multi-line string scenarios.
- Strings in Python are immutable (the splicing operation'+='in the new version of Python mentioned earlier is an exception). Therefore, it is not allowed to change the value of the character in the string at will.
- In the new version of Python (2.5+), string splicing has become much more efficient than before, and you can rest assured that you can use it.
- String formatting (f) in Python is often used in scenarios such as output, logging, etc.
Input and output
Input and Output Basis
When using forced conversions in production environments, remember to add try except
File Input and Output
All I/O should be error-handled. Because I/O operations can occur in a variety of situations, and a robust program needs to be able to cope with the occurrence of a variety of situations, and should not crash (except in cases of intentional design).
JSON Serialization and Actual Warfare
- The json.dumps() function accepts python's basic data types and serializes them into string s.
- The json.loads() function accepts a legal string and serializes it into python's basic data type.
Conditions and Cycles
- In conditional statements, if can be used alone, but elif and else must be used together with if; and if conditional statement judgment, in addition to boolean type, other than the best display.
- In the for loop, if you need to access both indexes and elements, you can use the enumerate() function to simplify the code.
- When writing conditions and loops, it is very important to use + continue + or + break + reasonably to avoid complex nesting.
- We should pay attention to the reuse of conditions and loops. Simple functions can be accomplished directly in one line, which greatly improves the quality and efficiency of code.
exception handling
- Exceptions, usually refer to the process of running the program encountered errors, terminated and exited. We usually use try except statements to handle exceptions, so that the program will not be terminated and can continue to execute.
- When handling exceptions, if there are statements that must be executed, such as closing a file after it is opened, you can put them in the final block.
- Exception handling is usually used when you are not sure whether a piece of code can be successfully executed or can not be easily judged, such as database connection, reading and so on. Normal flow-control logic, do not use exception handling, can be solved directly with conditional statements.
Custom function
- The parameters of functions in Python can accept any data type. It should be noted when using them. If necessary, add data type checking at the beginning of functions.
- Unlike other languages, the parameters of functions in Python can be set by default.
- The use of nested functions can ensure the privacy of data and improve the efficiency of program operation.
- Rational use of closures can simplify the complexity of the program and improve readability.
Anonymous function
Advantage:
- Reduce code duplication;
- Modular code;
map(function,iterable)
Represents the use of function for each element in iterable, and finally returns a new traversable set.
def square(x):
return x**2
squared = map(square, [1, 2, 3, 4, 5]) # [2, 4, 6, 8, 10]filter(function,iterable)
Represents that every element in iterable is judged by function and returned to True or False. Finally, elements returned to True are composed into a new traversable set.
l = [1, 2, 3, 4, 5] new_list = filter(lambda x: x % 2 == 0, l) # [2, 4]
reduce(function,iterable)
It is specified that it has two parameters, representing the calculation of each element in iterable and the result after the last call, using function, so the final return is a separate value.
l = [1, 2, 3, 4, 5] product = reduce(lambda x, y: x * y, l) # 1*2*3*4*5 = 120
Object-oriented
Basic concepts
- Class: A collection of similar things;
- Object: An object in a set;
- Attribute: A static feature of an object;
- Function: A dynamic capability of an object
Three elements:
- inherit
- encapsulation
- polymorphic
Modular Programming
- Through absolute path and relative path, we can import module.
- Modularization is very important in large-scale engineering. Modular indexing is done through absolute path, which starts from the root directory of the program.
- Remember to skillfully use if__name_=="_main_" to avoid import execution;
Advanced
Comparisons and Copies of Python Objects
- The comparison operator == denotes whether the values between comparison objects are equal, and is denotes whether the identifiers of comparison objects are equal, that is, whether they point to the same memory address.
- The comparison operator is more efficient than ==, because the is operator cannot be overloaded, and performing the is operation simply takes the ID of the object and compares it, while the == operator recursively traverses all the values of the object and compares them one by one.
- Elements in shallow copies are references to neutron objects of original objects. Therefore, if the elements in original objects are changeable, changing them will also affect the copied objects, and there are some side effects.
- Depth copy copies every child object in the original object recursively, so the copied object is not related to the original object. In addition, a dictionary is maintained in deep copy to record the copied objects and their ID s to improve efficiency and prevent infinite recursion.
Value passing and reference passing
There are two common parameter transfers:
- Value transfer: Usually copy the value of an object and pass it to a new variable in a function. The original variable and the new variable are independent of each other and do not affect each other.
- Reference passing: Usually refers to passing a reference to a parameter to a new variable, so that the original variable and the new variable will point to the same memory address.
To be exact, python's parameter transfer is assignment transfer, or object reference transfer. All data types in Python are objects, so when passing parameters, we just let new variables point to the same object as the original variables. There is no value transfer or reference transfer.
It should be noted that the assignment or reference transfer of objects here does not refer to a specific memory address, but to a specific object.
- If the object is changeable, when it changes, all variables pointing to the object will change.
- If the object is immutable, a simple assignment can only change the value of one of the variables, while the rest of the variables are unaffected.
Decorator
Functions are also objects
def func(message):
print('Got a message: {}'.format(message))
send_message = func
send_message('hello world')
# output
Got a message: hello worldFunctions can be used as function parameters
def get_message(message):
return 'Got a message: ' + message
def root_call(func, message):
print(func(message))
root_call(get_message, 'hello world')
# output
Got a message: hello worldFunctions can be nested
def func(message):
def get_message(message):
print('Got a message: {}'.format(message))
return get_message(message)
func('hello world')
# output
Got a message: hello worldThe return value of a function can also be a function object (closure)
def func_closure():
def get_message(message):
print('Got a message: {}'.format(message))
return get_message
send_message = func_closure()
send_message('hello world')
# output
Got a message: hello worldSimple use of decorators
def my_decorator(func):
def wrapper():
print('wrapper of decorator')
func()
return wrapper
def greet():
print('hello world')
greet = my_decorator(greet)
greet()
# output
wrapper of decorator
hello worldMore elegant writing
def my_decorator(func):
def wrapper():
print('wrapper of decorator')
func()
return wrapper
@my_decorator
def greet():
print('hello world')
greet()Decorator with parameters
def my_decorator(func):
def wrapper(message):
print('wrapper of decorator')
func(message)
return wrapper
@my_decorator
def greet(message):
print(message)
greet('hello world')
# output
wrapper of decorator
hello worldDecorator with custom parameters
def repeat(num):
def my_decorator(func):
def wrapper(*args, **kwargs):
for i in range(num):
print('wrapper of decorator')
func(*args, **kwargs)
return wrapper
return my_decorator
@repeat(4)
def greet(message):
print(message)
greet('hello world')
# Output:
wrapper of decorator
hello world
wrapper of decorator
hello world
wrapper of decorator
hello world
wrapper of decorator
hello worldAfter the above green() function is decorated, its meta-information will change, which can be viewed bravely by greet__name_. This problem can be solved with built-in decorators
import functools
def my_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print('wrapper of decorator')
func(*args, **kwargs)
return wrapper
@my_decorator
def greet(message):
print(message)
greet.__name__
# output
'greet'Class decorator
class Count:
def __init__(self, func):
self.func = func
self.num_calls = 0
def __call__(self, *args, **kwargs):
self.num_calls += 1
print('num of calls is: {}'.format(self.num_calls))
return self.func(*args, **kwargs)
@Count
def example():
print("hello world")
example()
# output
num of calls is: 1
hello world
example()
# output
num of calls is: 2
hello worldDecorator supports nested use
@decorator1
@decorator2
@decorator3
def func():
...
# Equivalent to
decorator1(decorator2(decorator3(func)))Decorator usage scenario:
- identity authentication
- Log record
- Input Rationality Check
- Caching (LRU cache)
metaclass
metaclass is a Python black magic level language feature that can change the normal Python type creation process.
- All Python user-defined classes are instances of the type class
- User-defined classes, just type class call operator overload
- Metaclass is a subclass of type. By replacing the _ call operator overloading mechanism of type, metaclass surpasses the deformed normal class.
class Mymeta(type):
def __init__(self, name, bases, dic):
super().__init__(name, bases, dic)
print('===>Mymeta.__init__')
print(self.__name__)
print(dic)
print(self.yaml_tag)
def __new__(cls, *args, **kwargs):
print('===>Mymeta.__new__')
print(cls.__name__)
return type.__new__(cls, *args, **kwargs)
def __call__(cls, *args, **kwargs):
print('===>Mymeta.__call__')
obj = cls.__new__(cls)
cls.__init__(cls, *args, **kwargs)
return obj
class Foo(metaclass=Mymeta):
yaml_tag = '!Foo'
def __init__(self, name):
print('Foo.__init__')
self.name = name
def __new__(cls, *args, **kwargs):
print('Foo.__new__')
return object.__new__(cls)
foo = Foo('foo')Iterator and Generator
- The iterator () function can be called by the iterator () function of the iterator. The iterator can get the next element through the next() function to support traversal
- Generator is a special iterator. Rational use of generator can reduce memory consumption, optimize program structure and improve program speed.
- Generator in Python 2 version, is an important way to achieve the collaboration; while Python 3.5 introduced async, await grammar sugar, the way generators achieve the collaboration has lagged behind.
Association
Collaboration is a way to realize concurrent programming
- The difference between co-operation and multi-threading mainly lies in two points: one is that the co-operation is single-threaded; the other is that the co-operation is decided by the user where to hand over control and switch to the next task.
- The protocol is written more concisely and clearly; the combination of async/await grammar and create_task has no pressure on small and medium-level concurrency requirements.
Producer/Consumer Model
import asyncio
import random
async def consumer(queue, id):
while True:
val = await queue.get()
print('{} get a val: {}'.format(id, val))
await asyncio.sleep(1)
async def producer(queue, id):
for i in range(5):
val = random.randint(1, 10)
await queue.put(val)
print('{} put a val: {}'.format(id, val))
await asyncio.sleep(1)
async def main():
queue = asyncio.Queue()
consumer_1 = asyncio.create_task(consumer(queue, 'consumer_1'))
consumer_2 = asyncio.create_task(consumer(queue, 'consumer_2'))
producer_1 = asyncio.create_task(producer(queue, 'producer_1'))
producer_2 = asyncio.create_task(producer(queue, 'producer_2'))
await asyncio.sleep(10)
consumer_1.cancel()
consumer_2.cancel()
await asyncio.gather(consumer_1, consumer_2, producer_1, producer_2, return_exceptions=True)
%time asyncio.run(main())
########## output ##########
producer_1 put a val: 5
producer_2 put a val: 3
consumer_1 get a val: 5
consumer_2 get a val: 3
producer_1 put a val: 1
producer_2 put a val: 3
consumer_2 get a val: 1
consumer_1 get a val: 3
producer_1 put a val: 6
producer_2 put a val: 10
consumer_1 get a val: 6
consumer_2 get a val: 10
producer_1 put a val: 4
producer_2 put a val: 5
consumer_2 get a val: 4
consumer_1 get a val: 5
producer_1 put a val: 2
producer_2 put a val: 8
consumer_1 get a val: 2
consumer_2 get a val: 8
Wall time: 10 sFutures for Concurrent Programming
Distinguishing concurrency from parallelism
- Concurrent applications often use scenarios where I/O operations are frequent. For example, you need to download multiple files from a website. I/O operations may take much longer than CPU operations. They are implemented by switching between threads and tasks, but only one thread or task is allowed to execute at the same time.
- Parallelism is more used in CPU heavy scenarios, such as parallel computing in MapReduce. In order to speed up the operation, it is usually accomplished by multiple machines and processors. It allows multiple processes to execute synchronously and simultaneously
The reason why only one thread runs at the same time in Python is actually due to the existence of global interpretative locks. But for I/O operations, when it is block ed, the global interpreter lock is released and the gas thread continues to execute.
import concurrent.futures
import requests
import threading
import time
def download_one(url):
resp = requests.get(url)
print('Read {} from {}'.format(len(resp.content), url))
# Version 1
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_one, sites)
# Version 2
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
to_do = []
for site in sites:
future = executor.submit(download_one, site)
to_do.append(future)
for future in concurrent.futures.as_completed(to_do):
future.result()
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time))
if __name__ == '__main__':
main()
## output
Read 151021 from https://en.wikipedia.org/wiki/Portal:Mathematics
Read 129886 from https://en.wikipedia.org/wiki/Portal:Arts
Read 107637 from https://en.wikipedia.org/wiki/Portal:Biography
Read 224118 from https://en.wikipedia.org/wiki/Portal:Society
Read 184343 from https://en.wikipedia.org/wiki/Portal:History
Read 167923 from https://en.wikipedia.org/wiki/Portal:Geography
Read 157811 from https://en.wikipedia.org/wiki/Portal:Technology
Read 91533 from https://en.wikipedia.org/wiki/Portal:Science
Read 321352 from https://en.wikipedia.org/wiki/Computer_science
Read 391905 from https://en.wikipedia.org/wiki/Python_(programming_language)
Read 180298 from https://en.wikipedia.org/wiki/Node.js
Read 56765 from https://en.wikipedia.org/wiki/The_C_Programming_Language
Read 468461 from https://en.wikipedia.org/wiki/PHP
Read 321417 from https://en.wikipedia.org/wiki/Java_(programming_language)
Read 324039 from https://en.wikipedia.org/wiki/Go_(programming_language)
Download 15 sites in 0.19936635800002023 secondsAsyncio for Concurrent Programming
import asyncio
import aiohttp
import time
async def download_one(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
print('Read {} from {}'.format(resp.content_length, url))
async def download_all(sites):
tasks = [asyncio.create_task(download_one(site)) for site in sites]
await asyncio.gather(*tasks)
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
asyncio.run(download_all(sites))
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time))
if __name__ == '__main__':
main()
## output
Read 63153 from https://en.wikipedia.org/wiki/Java_(programming_language)
Read 31461 from https://en.wikipedia.org/wiki/Portal:Society
Read 23965 from https://en.wikipedia.org/wiki/Portal:Biography
Read 36312 from https://en.wikipedia.org/wiki/Portal:History
Read 25203 from https://en.wikipedia.org/wiki/Portal:Arts
Read 15160 from https://en.wikipedia.org/wiki/The_C_Programming_Language
Read 28749 from https://en.wikipedia.org/wiki/Portal:Mathematics
Read 29587 from https://en.wikipedia.org/wiki/Portal:Technology
Read 79318 from https://en.wikipedia.org/wiki/PHP
Read 30298 from https://en.wikipedia.org/wiki/Portal:Geography
Read 73914 from https://en.wikipedia.org/wiki/Python_(programming_language)
Read 62218 from https://en.wikipedia.org/wiki/Go_(programming_language)
Read 22318 from https://en.wikipedia.org/wiki/Portal:Science
Read 36800 from https://en.wikipedia.org/wiki/Node.js
Read 67028 from https://en.wikipedia.org/wiki/Computer_science
Download 15 sites in 0.062144195078872144 secondsAsyncio is single-threaded, but its internal event loop mechanism allows it to run multiple different tasks concurrently and enjoys greater autonomous control than multi-threading.
Tasks in Asyncio are not interrupted during operation, so race condition does not occur. Especially in the case of I/O heavy, Asyncio is more efficient than multi-threading, so the loss of task switching in Asyncio is much less than that of thread switching, and the number of tasks that Asyncio can open is much more than that of threads in multi-threading.
However, it should be noted that in many cases, the use of Asyncio requires the support of specific third-party libraries, and if I/O is fast and not heavy, it is recommended to use multi-threading to solve the problem.
GIL (Global Interpreter Lock)
CPython introduced GIL mainly because:
- Designers avoid complex competitive risks such as memory management
- Because CPython uses a large number of C libraries, most C libraries are not native thread-safe (thread-safe can reduce performance and increase complexity).
GIL is designed to facilitate CPython interpreter-level programmers, not Python application-level programmers.
Code can be compiled into bytecode using import dis
Garbage Recycling Mechanism
- Garbage collection is Python's built-in mechanism for automatically releasing memory space that will no longer be used
- Reference counting is the simplest implementation, but keep in mind that this is only a sufficient and unnecessary condition, because circular references need to be determined by unreachability to determine whether they can be recycled.
- Python's automatic recovery algorithms include tag clearance and generational collection, mainly for recycled reference garbage collection
- Debugging memory leaks is convenient, and objgraph is a good visual analysis tool.
Programming specification
Reader's Experience > Programmer's Experience > Machine's Experience
- Learn to decompose code reasonably and improve code readability
- Reasonable Use of Assert
- Enabling Context Manager and with Statements to Streamline Code
- unit testing
- pdf & cprofile