Co process, also known as micro thread, fiber process. The English name is Coroutine.
Threads are system level and they are scheduled by the operating system, while coroutines are program level and are scheduled by the program itself as required. There are many functions in a thread. We call these functions subroutines. During the execution of subroutines, other subroutines can be interrupted to execute other subroutines, and other subroutines can also be interrupted to continue to execute the previous subroutines. This process is called cooperation. In other words, a piece of code in the same thread will be interrupted during execution, then jump to execute other code, and then continue to execute at the place interrupted before, similar to yield operation.
The association has its own register context and stack. In the process of scheduling switch, register context and stack are saved to other places, and the previously saved register context and stack are restored when switching back. Therefore: the process can retain the state of the last call (that is, a specific combination of all local states). Each time the process is re entered, it is equivalent to entering the state of the last call. In other words, it is the location of the logical flow when entering the last leave. Because the process is executed by a thread, how to use multi-core CPU? The simplest method is multi process + CO process, which can not only make full use of multi-core, but also give full play to the high efficiency of the co process, and obtain high performance.
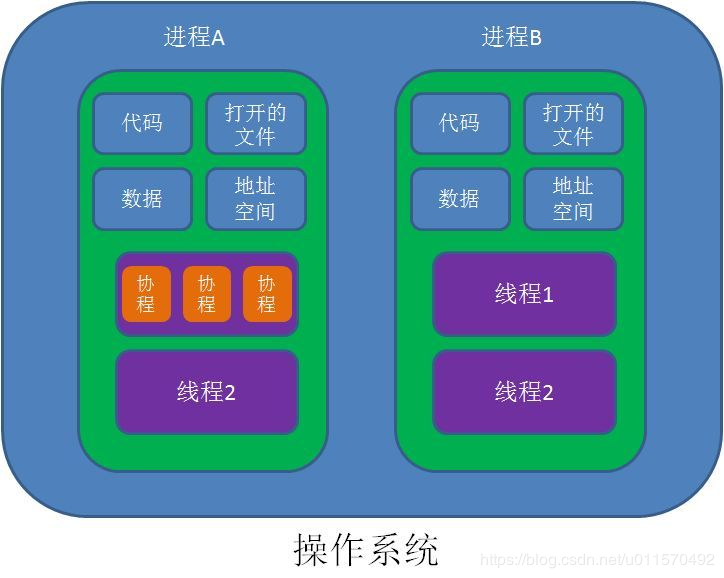
Advantages of the process:
- Without the overhead of thread context switching, the cooperation process avoids meaningless scheduling, which can improve performance (however, the programmer must take the responsibility of scheduling himself, meanwhile, the cooperation process also loses the ability of standard threads to use multi CPU)
- No overhead of atomic operation locking and synchronization
- Easy to switch control flow and simplify programming model
- High concurrency + high scalability + low cost: it is not a problem that a CPU supports tens of thousands of coprocesses. So it is suitable for high concurrency processing.
Disadvantages of cooperation:
- Can't use multi-core resources: the essence of a co program is a single thread. It can't use multiple cores of a single CPU at the same time. A co program needs to work with a process to run on multiple CPUs. Of course, most of the applications we write in our daily life don't need this, unless they are CPU intensive applications.
- Blocking operations, such as IO, block the entire program
generator
To understand a process, you first need to know what a generator is. The generator is actually a function that continuously produces values, but in the function, you need to use the keyword yield to produce values. The general function will return a value and exit after execution, but the generator function will automatically suspend, and then pick up the urgent execution again. He will use the yield keyword to close the function, return a value to the caller, and keep the current enough state, so that the function can continue to execute. The generator is closely related to the iteration protocol, and the iterator has A member method, which either returns the next item of the iteration, or causes an exception to end the iteration.
# When a function has yield, the function name + () becomes a generator # return represents the termination of the generator in the generator, and directly reports an error # The next function is to wake up and continue # The function of send is to wake up and continue, send a message to the generator def create_counter(n): print("create_counter") while True: yield n print("increment n") n += 1 if __name__ == '__main__': gen = create_counter(2) print(next(gen)) for item in gen: print('--->:{}'.format(item)) if item > 5: break print: create_counter 2 increment n --->:3 increment n --->:4 increment n --->:5 increment n --->:6
Python 2 process
Python's support for orchestrations is implemented through the generator. In generator, we can not only iterate through the for loop, but also call the next() function to get the next value returned by the yield statement. But Python's yield can not only return a value, it can also receive parameters from the caller.
The traditional producer consumer model is that a thread writes a message, a thread takes a message and controls the queue and wait through the lock mechanism, but it may deadlock if it is not careful. If the process is used instead, after the producer produces the message, it will jump to the consumer to start execution directly through yield. After the consumer completes execution, it will switch back to the producer to continue production, with high efficiency:
Producer consumer model of CO process implementation
def consumer(): r = '' while True: n = yield r #n is the parameter sent if not n: return print('[CONSUMER] Consuming %s...' % n) r = '200 OK' def produce(c): c.send(None) #Transfer parameters, and q n = 0 while n < 5: n = n + 1 print('[PRODUCER] Producing %s...' % n) r = c.send(n) print('[PRODUCER] Consumer return: %s' % r) c.close() if __name__ == '__main__': c = consumer() produce(c) //Operation result: [PRODUCER] Producing 1... [CONSUMER] Consuming 1... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 2... [CONSUMER] Consuming 2... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 3... [CONSUMER] Consuming 3... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 4... [CONSUMER] Consuming 4... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 5... [CONSUMER] Consuming 5... [PRODUCER] Consumer return: 200 OK
Notice that the consumer function is a generator. After passing a consumer into produce:
- First call c.send(None) to start the generator;
- Then, once something is produced, switch to consumer for execution through c.send(n);
- consumer gets the message through yield, processes it, and returns the result through yield;
- Produce takes the result of consumer processing and continues to produce the next message;
- Produce decides not to produce. Close the consumer through c.close(). The whole process is over.
The whole process is unlocked and executed by one thread. produce and consumer cooperate to complete the task, so it is called "collaboration", rather than thread preemptive multitask.
Python 3.5 asyncio
Asyncio is a standard library introduced in Python version 3.4, which has built-in support for asynchronous io. Using @ asyncio.coroutine provided by asyncio, you can mark a generator as coroutine type, and then use yield from to call another coroutine inside coroutine to implement asynchronous operation. In order to simplify and better identify asynchronous IO, new syntax async and await are introduced from Python 3.5, which can make the code of coroutine more concise and readable.
Synchronously executed process
import asyncio import time # Use the await of the main function to launch two Ctrip programs. At this time, the code is still synchronized, # When the first await is finished, the second one will be started. This is that their operation is consistent with the function async def say_after(delay, what): await asyncio.sleep(delay) print('--->:{}'.format(what)) async def main(): print(f"started at {time.strftime('%X')}") await say_after(1, 'hello') await say_after(2, 'world') print(f"finished at {time.strftime('%X')}") if __name__ == '__main__': asyncio.run(main()) //Execution result: 2019-12-15 18:03:52,719 - asyncio - DEBUG - Using proactor: IocpProactor started at 18:03:52 hello world finished at 18:03:55
Concurrent processes
import asyncio import time # What's different from the previous example is that the way to start the cooperation process here is to start the task task, which is considered to be a waiting object, so they can run concurrently. This example will save one second compared with the previous example async def say_after(delay, what): # Why use this approach to simulate waiting? Because time.sleep(delay) is not considered as a wait object by asyncio, the expected time.sleep() will not appear when it is replaced with time.sleep() await asyncio.sleep(delay) print('--->:{}'.format(what)) async def main(): print(f"started at {time.strftime('%X')}") # Used to create a collaboration task task1 = asyncio.create_task(say_after(1,'hello')) task2 = asyncio.create_task(say_after(2,'world')) # Although the concurrent start task is executed concurrently, in Python, the program will wait for the most time-consuming process to run and then exit, so it takes 2 seconds here await task1 await task2 print(f"finished at {time.strftime('%X')}") if __name__ == '__main__': asyncio.run(main()) //Execution result: 2019-12-15 18:18:50,374 - asyncio - DEBUG - Using proactor: IocpProactor started at 18:18:50 --->:hello --->:world finished at 18:18:52
Common usage
Co processes on a single core
Tasks = [asyncio. Create [task (test (1)) for proxy in range (10000)] created tasks
[await t for t in tasks] to the execution queue
There are 10000 tasks here, taking 1.2640011310577393 seconds
import asyncio import time async def test(time): await asyncio.sleep(time) async def main(): start_time = time.time() tasks = [asyncio.create_task(test(1)) for proxy in range(10000)] [await t for t in tasks] print(time.time() - start_time) if __name__ == "__main__": asyncio.run(main()) //Execution result: 2019-12-15 18:15:17,668 - asyncio - DEBUG - Using proactor: IocpProactor 1.1492626667022705
Co processes on multicore
For multi-core applications, of course, multi process + CO process is used
from multiprocessing import Pool import asyncio import time async def test(time): await asyncio.sleep(time) async def main(num): start_time = time.time() tasks = [asyncio.create_task(test(1)) for proxy in range(num)] [await t for t in tasks] print(time.time() - start_time) def run(num): asyncio.run(main(num)) if __name__ == "__main__": p = Pool() for i in range(4): p.apply_async(run, args=(2500,)) p.close() p.join() //Execution result: 1.0610532760620117 1.065042495727539 1.0760507583618164 1.077049970626831