Preface
Part One Climb Himalayan FM Audio Finally, we mentioned that this time we crawled is Netease Cloud Music Review + Comment. I have used Netease Cloud for a long time, and I also like it very much.... Gossip is not much to say, follow my thinking to see how to crawl Netease Cloud's comment + comment _______~
target
The goal we are crawling for this time is to make popular reviews and general reviews of Netease Yun's music songs.
We know that Netease cloud music has many song lists, so our idea is to start with these song lists, traverse the song lists, traverse the song lists.
Here I choose the latest song list. I have a look at the last 100 pages of this song list, 35 song lists per page.
https://music.163.com/#/discover/playlist/?order=new
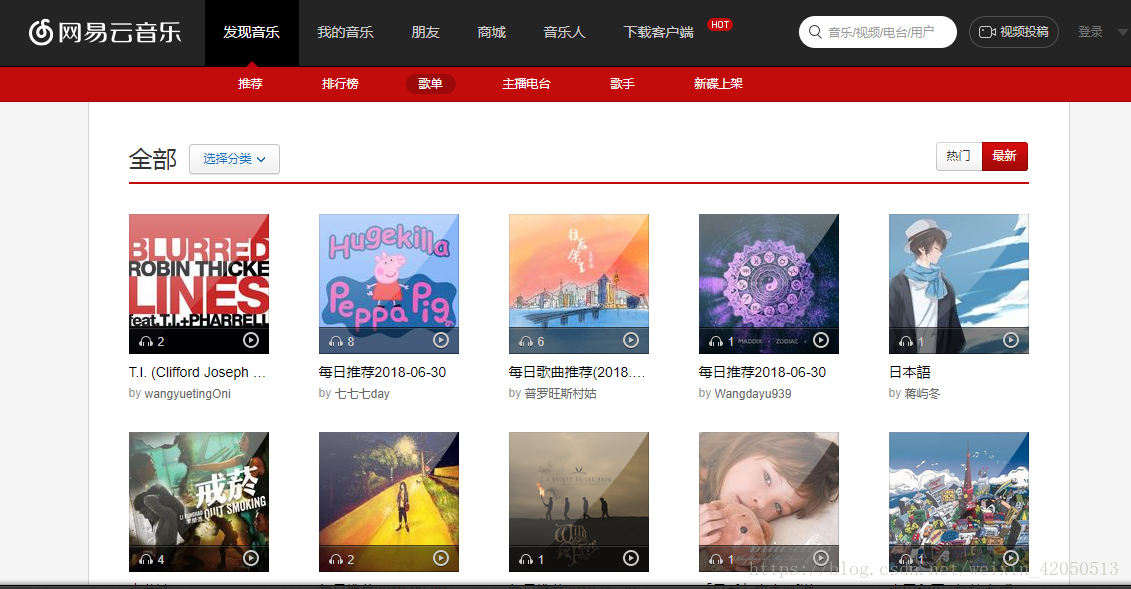
Next, let's analyze a song list.
https://music.163.com/#/playlist?id=2294381226
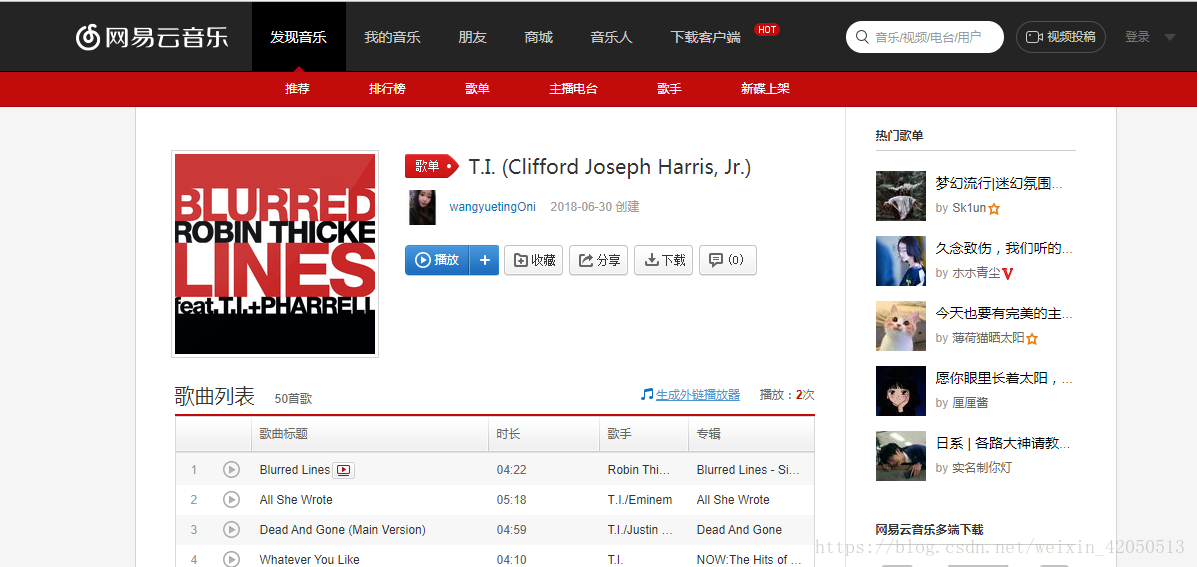
Let's click on one of the songs:
https://music.163.com/#/song?id=26075485
Now that we're going to get comments on songs, let's look at them through developer tools and see where they are.
Based on our experience, we found these comments on dynamic loading in XHR
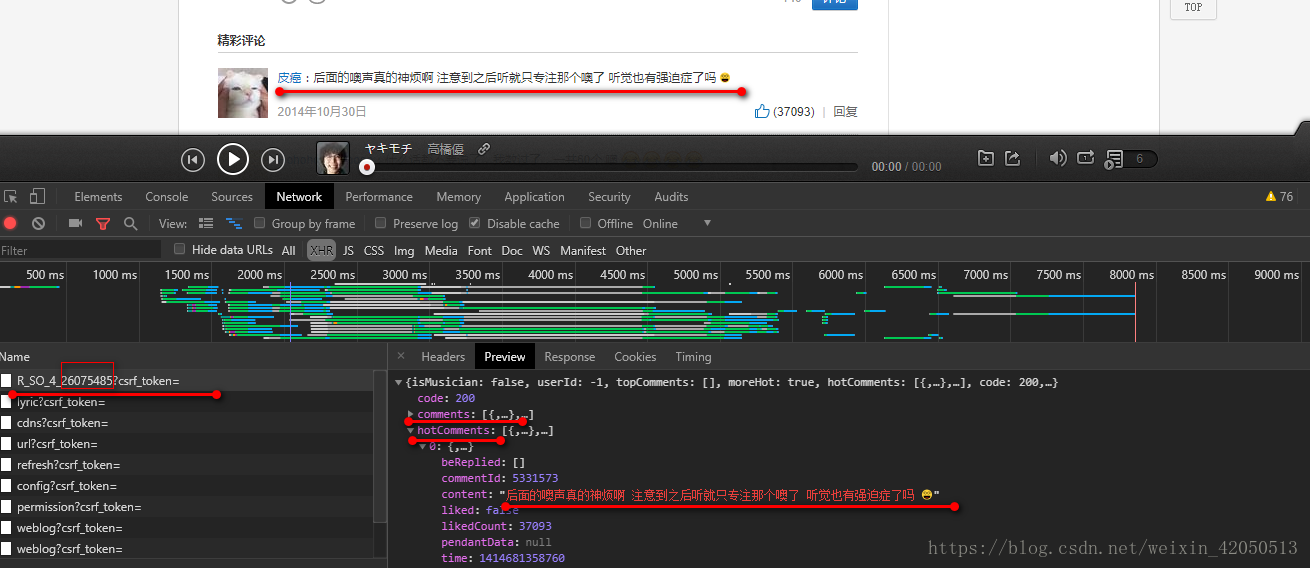
We can see that in R_SO_4_26075485?csrf_token = there are comments and hotComments, which correspond to the latest comments and popular comments respectively.
We can see that these comments are made by referring to
https://music.163.com/weapi/v1/resource/comments/R_SO_4_26075485?csrf_token=
When the post request is initiated, two parameters, params and encSecKey, are passed in.
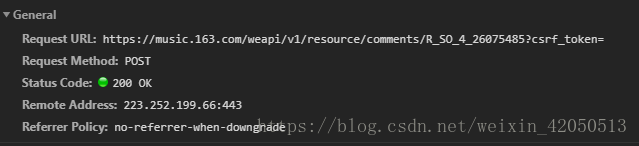

That is to say, we can get comments just by sending post requests to Netease cloud server through simulated browser!
Note also that the link to this post, R_SO_4, followed by a series of numbers is actually the corresponding id of the song; and here you need to pass in parameters, also have a good analysis (later)
So now the goal is to find all the latest song lists - > for each song list, traverse all the songs, get the ID of the song in the source code of the web page - > for each song through its id, request the server post (with parameters) to get the desired comments.
Start moving knife
First step
The code is as follows:
headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' } baseUrl = 'https://music.163.com' def getHtml(url): r = requests.get(url, headers=headers) html = r.text return html def getUrl(): #Start with the latest song list startUrl = 'https://music.163.com/discover/playlist/?order=new' html = getHtml(startUrl) pattern =re.compile('<li>.*?<p.*?class="dec">.*?<.*?title="(.*?)".*?href="(.*?)".*?>.*?span class="s-fc4".*?title="(.*?)".*?href="(.*?)".*?</li>',re.S) result = re.findall(pattern,html) #Get the total number of pages of the song list pageNum = re.findall(r'<span class="zdot".*?class="zpgi">(.*?)</a>',html,re.S)[0] info = [] #Get the information you want from the song list on page 1 for i in result: data = {} data['title'] = i[0] url = baseUrl+i[1] print url data['url'] = url data['author'] = i[2] data['authorUrl'] = baseUrl+i[3] info.append(data) #Call the method of getting songs from each song list getSongSheet(url) time.sleep(random.randint(1,10)) #Here is the first song list on page 1 for the time being, so use break break
It should be well understood here to get the information of the song list in the source code of the web page, but it should be noted that if you get it directly
https://music.163.com/#/discover/playlist/?order=new
It is impossible to get the song list information, which is also an interesting part of Netease Cloud. When we crawl, we need to delete the
https://music.163.com/discover/playlist/?order=new
So you can see it.

The second step
def getSongSheet(url): #Get the id of each song in each song list as the key to the next post html = getHtml(url) result = re.findall(r'<li><a.*?href="/song\?id=(.*?)">(.*?)</a></li>',html,re.S) result.pop() musicList = [] for i in result: data = {} headers1 = { 'Referer': 'https://music.163.com/song?id={}'.format(i[0]), 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' } musicUrl = baseUrl+'/song?id='+i[0] print musicUrl #Song url data['musicUrl'] = musicUrl #Song name data['title'] = i[1] musicList.append(data) postUrl = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_{}?csrf_token='.format(i[0]) param = { 'params': get_params(1), 'encSecKey': get_encSecKey() } r = requests.post(postUrl,data = param,headers = headers1) total = r.json() # Total comment total = int(total['total']) comment_TatalPage = total/20 # Base total pages print comment_TatalPage #Judging the number of comment pages, the remainder is one more page and the division is just right. if total%20 != 0: comment_TatalPage = comment_TatalPage+1 comment_data,hotComment_data = getMusicComments(comment_TatalPage, postUrl, headers1) #If ID duplication occurs when storing in the database, pay attention to whether there is only one data crawling down. saveToMongoDB(str(i[1]),comment_data,hotComment_data) print 'End!' else: comment_data, hotComment_data = getMusicComments(comment_TatalPage, postUrl, headers1) saveToMongoDB(str(i[1]),comment_data,hotComment_data) print 'End!' time.sleep(random.randint(1, 10)) break
The purpose of this step is to obtain the ID of the song in the song list, traverse each song (i.e. the corresponding id), and obtain the url and the title of the song.
According to id, construct postUrl to get the total number of comments and the total number of pages by post on the first page (about how to get the desired information about post, which will be discussed later);
And call the method of getting song reviews;
There's also a judgment here, based on dividing the total number of comments by 20 comments per page, to determine whether there is a surplus, to get the total number of pages of final comments, and we can also find that hot comments are only on the first page.
The third step
def getMusicComments(comment_TatalPage ,postUrl, headers1): commentinfo = [] hotcommentinfo = [] # Comments on each page for j in range(1, comment_TatalPage + 1): # Hot reviews are available only on the first page if j == 1: #Get comments r = getPostApi(j , postUrl, headers1) comment_info = r.json()['comments'] for i in comment_info: com_info = {} com_info['content'] = i['content'] com_info['author'] = i['user']['nickname'] com_info['likedCount'] = i['likedCount'] commentinfo.append(com_info) hotcomment_info = r.json()['hotComments'] for i in hotcomment_info: hot_info = {} hot_info['content'] = i['content'] hot_info['author'] = i['user']['nickname'] hot_info['likedCount'] = i['likedCount'] hotcommentinfo.append(hot_info) else: r = getPostApi(j, postUrl, headers1) comment_info = r.json()['comments'] for i in comment_info: com_info = {} com_info['content'] = i['content'] com_info['author'] = i['user']['nickname'] com_info['likedCount'] = i['likedCount'] commentinfo.append(com_info) print u'The first'+str(j)+u'Page crawl finished...' time.sleep(random.randint(1,10)) print commentinfo print '\n-----------------------------------------------------------\n' print hotcommentinfo return commentinfo,hotcommentinfo
Three parameters are passed in, comment_TatalPage, postUrl, headers 1, corresponding to the total number of comments pages, postUrl is postUrl... and the request header.
Get reviews and comments on the first page, general comments on other pages, and other data to add to the list
The fourth step
Now let's take a look at the painful post section! ...
# The offset value is (comment page number - 1) * 20, the first page of total is true, and the remaining pages are false. # first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}' # First parameter # Second parameter second_param = "010001" # Third parameter third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7" # Fourth parameter forth_param = "0CoJUm6Qyw8W8jud" # Get parameters def get_params(page): # page is the number of incoming pages iv = "0102030405060708" first_key = forth_param second_key = 16 * 'F' if(page == 1): # If it's page one first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}' h_encText = AES_encrypt(first_param, first_key, iv) else: offset = str((page-1)*20) first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset,'false') h_encText = AES_encrypt(first_param, first_key, iv) h_encText = AES_encrypt(h_encText, second_key, iv) return h_encText # Get encSecKey def get_encSecKey(): encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c" return encSecKey # Encryption process def AES_encrypt(text, key, iv): pad = 16 - len(text) % 16 text = text + pad * chr(pad) encryptor = AES.new(key, AES.MODE_CBC, iv) encrypt_text = encryptor.encrypt(text) encrypt_text = base64.b64encode(encrypt_text) return encrypt_text #Get the Json from post def getPostApi(j ,postUrl, headers1): param = { # Get the number of pages corresponding to params 'params': get_params(j), 'encSecKey': get_encSecKey() } r = requests.post(postUrl, data=param, headers=headers1) return r
Here, the getPostApi function passes in three parameters, namely, the number of pages (because the params attached to each page's post are different), the postURL, and the request header.
Here data=param is the required parameter

It's obviously encrypted. Here's a brief introduction.
First of all, I thought about using fiddler to grab bags. The results were no different. Then I referred to it.
http://www.cnblogs.com/lyrichu/p/6635798.html
The author mentioned this.........................................................
https://www.zhihu.com/question/36081767/answer/140287795
as well as
https://www.zhihu.com/question/21471960
Sharing of Big Brother A in the Middle Road
Download core.js locally and analyze it with notepad+. Here we recommend a notepad++ plug-in that can format JavaScript. https://blog.csdn.net/u011037869/article/details/47170653
Then find the two parameters we need.

Then redirect core.js in fiddler, modify the content of local core.js, and print the above parameters. The results can be seen in the console for the first time, and then always report errors.
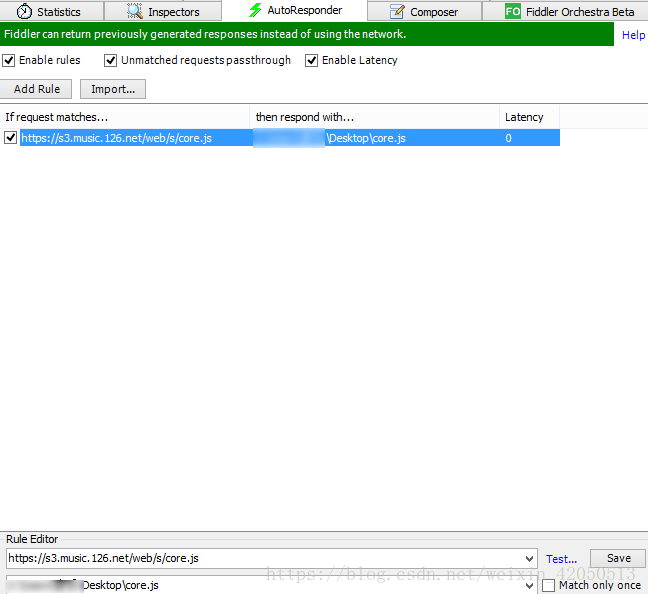
Then I'll analyze the JavaScript code, and here I'm going to use the method of generating parameters directly. (Sure enough, I'll have to learn js well.)
AND
Don't think that's all right! Then I had the worst problem: when you import
Error reporting from Crypto.Cipher import AES!
ImportError: No module named Crypto.Cipher
Then I tried pip install Crypto successfully, but this time it appeared.
ImportError: No module named Cipher!!...
Finally, I found a lot of information to sum up for you, how to solve this problem
Normally, after pip install Crypto, you just need to change crypto to Crypto under C: Python 27 Lib site-packages (but I'm useless)
-
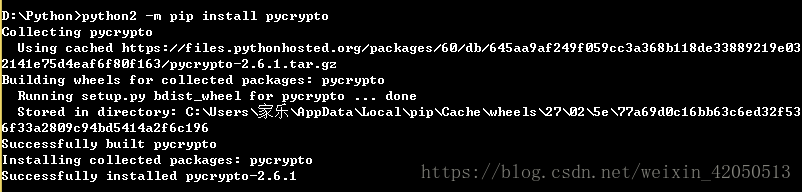
My final solution is to refer to the following. Note that in my words, pycrypto is installed.
https://blog.csdn.net/teloy1989/article/details/72862108
Install pycrypto by itself
Microsoft Visual C++ 9.0 was not installed at first Here's a picture description.
Here's a picture description.
There was an error, then downloaded Microsoft Visual C++ 9.0 and installed pycrypto again.
It's a success! After that, I import from Crypto.Cipher import AES and it will run properly.~
The fifth step
def saveToMongoDB(musicName,comment_data,hotComment_data): client = pymongo.MongoClient(host='localhost',port=27017) db = client['Music163'] test = db[musicName] test.insert(hotComment_data) test.insert(comment_data) print musicName+u'Stored in database...'
The last thing is to put the data in MongoDB, or try to put it in MySQL if you are interested.
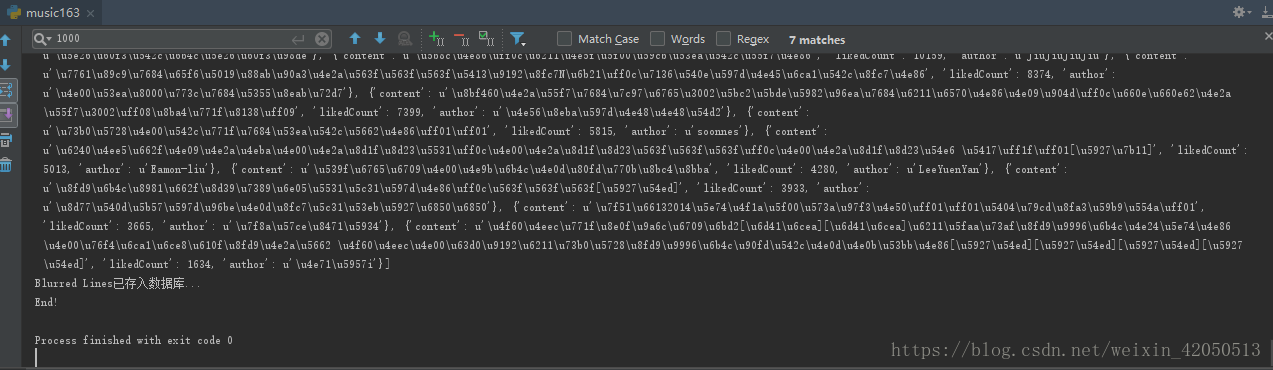
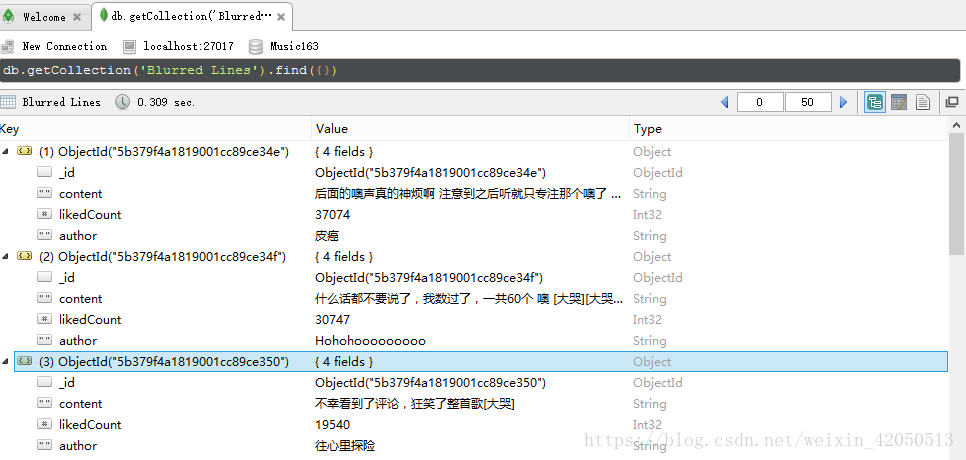
if __name__ == '__main__': getUrl()
Here I'm putting the data into MongoDB once I've crawled it. It may be a bit too burdensome. Or can I try to crawl a page and put it into a page?
If you have questions or better ways, welcome to exchange!
The next article is about crawling APP, or maybe crawling videos..... Alas, it's going to be a holiday...
The complete code can be downloaded from my GitHub~
https://github.com/joelYing/Music163
print('Wechat Public Number Search "Singles'Daily Life" ,Java Technological upgrading and pest master training, we are all together!') print('Can also sweep down the two-dimensional code Oh~')
