C language and python are often confused, especially I can't help adding a semicolon after Python... Just make a note for myself to save forgetting... (from the little turtle)
9, String
- Strings are widely used and extremely convenient:
'''Determine whether it is palindrome number''' >>> x = '123454321' >>> 'Is the palindrome number' if x == x[::-1] else 'Not palindromes' 'Is the palindrome number'
- Various methods of string:
2.1 case conversion

>>> x = 'I love FishC' >>> x.capitalize() #The first letter is uppercase, and the rest are lowercase 'I love fishc' #The returned string is not the source string. The string is immutable. It is just a newly generated string >>> x.casefold() #All lowercase 'i love fishc' >>> x.title() #The first letter of all words is uppercase, and the rest are lowercase 'I Love Fishc' >>> x.swapcase() #Flip Case 'i LOVE fISHc' >>> x.upper() #All caps 'I LOVE FISHC' >>> x.lower() #All lowercase 'i love fishc' '''casefold Can handle lowercase in other languages, lower Only English letters can be processed'''
2.2 left middle right alignment

First, specify the width. If the width is smaller than the total length of the source string, output according to the source string:
>>> x = 'Hello, world!' >>> x.center(10) #Center ' Hello, world! ' >>> x.ljust(10) #Align left 'Hello, world! ' >>> x.rjust(10) #Right align ' Hello, world!' >>> x.zfill(10) #Left fill 0 when specifying length '0000 Hello, world!'
You can also add to the blank:
>>> x = 'Hello, world!' >>> x.center(10, '0') '00 Hello, world! 00' >>> x.ljust(10, 'I') 'Hello, world! I, I, I, I'
2.3 search

>>> x = 'Shanghai tap water comes from the sea'
'''Search times'''
>>> x.count('sea')
2
>>> x.count('sea', 0, 5) #Find the number of times in the clip
1
'''Find index'''
>>> x.find('sea') #Look left to right
1
>>> x.rfind('sea') #Look right to left
7
>>> x.rfind('sea',0,5) #Look right to left from the position of subscript 5
1
>>> x.rfind('sea',4,9)
7
The difference between this search index and index() is that when the search content does not exist in the string, find() and rfind() return - 1, while index() reports an error
2.4 replacement

Replace all tabs with spaces:
>>> code = '''
My name is Buranny.
Your name is Aamy.''' #The previous line is indented with Tab and the next line is indented with 4 spaces
>>> new_code = code.expandtabs(4) #All tabs are represented by four spaces
>>> new_code
'\n My name is Buranny.\n Your name is Aamy.'
>>> print(new_code)
My name is Buranny.
Your name is Aamy.
Replace the old string with the new string. count indicates the number of replacement times. Generally, the default is - 1, indicating all replacement:
>>> 'I love my family'.replace('I', 'you', -1) #- 1 can also be omitted at this time
'You love your family'
>>> 'I love my family'.replace('I', 'you', 1)
'You love my family'
First, the conversion rules are given, and then translate is used for conversion:
>>> table = str.maketrans('ABCDEFG', '1234567')
>>> 'My Boy Lika Apple'.translate(table)
'My 2oy Lika 1pple'
>>> 'My Boy Lika Apple'.translate(str.maketrans('ABCDEFG', '1234567')) #The results are the same
'My 2oy Lika 1pple'
>>> 'My Boy Lika Apple'.translate(str.maketrans('ABCDEFG', '1234567', 'Myle'))
' 2o Lika 1pp' #The elements existing in the specified string are ignored, and all M, y, l and e are ignored
2.5 judgment

Judgment position:
>>> x = 'I love python'
>>> x.startswith('love') #Determine whether the string is at the starting position
False
>>> x.startswith('I')
True
>>> x.startswith('love', 1, 5)
True
>>> x.endswith('on') #Determines whether the string is at the end
True
>>> x.endswith('py',0 ,3)
False
>>> x.endswith('py',0 ,4)
True
>>> if x.startswith(('I', 'you', 'he')): #Tuple judgment can also be used
print('yes')
yes
Case determination:
>>> x = 'I love Python' >>> x.istitle() #Is only the first letter uppercase and the rest lowercase False >>> x = 'I Love Python' >>> x.istitle() True >>> x = 'I AM SINGER' >>> x.isupper() #Are all uppercase True >>> x.upper().isupper() #First convert upper() to uppercase, and then whether isupper() is uppercase True >>> x = 'I AM SINGER' >>> x.islower() #Are all lowercase False
Judgment type:
>>> x = 'I love Python' >>> x.isalpha() #Are they all letters False #There are spaces >>> ' \n'.isspace() #Single quotation marks contain indents, spaces and escape characters to judge whether it is a blank string True >>> 'I love Python'.isprintable() #Printable True >>> 'I love Python\n'.isprintable() #Escape characters are not printable False
Judge number type:
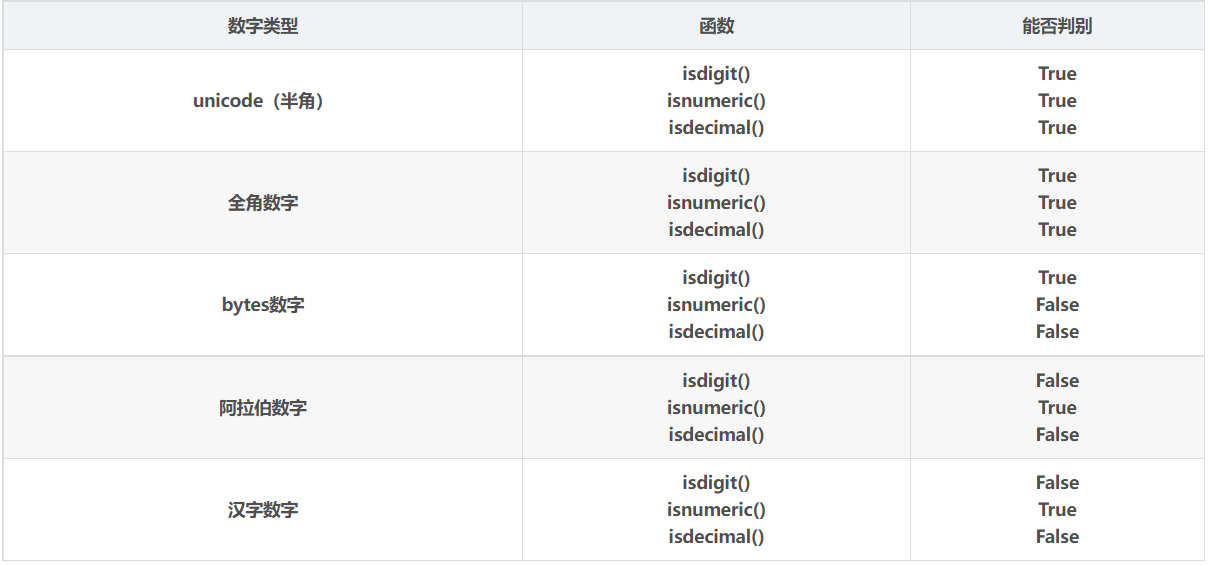
See for details The difference between isdigit(), isnumeric(), and isdecimal() . In isalpha(), isdigit(), isnumeric() and isdecimal(), any one returns True, and isalnum() returns True.
Judge whether it is a legal python identifier (variable name must be a legal python identifier):
>>> 'my god'.isidentifier() False >>> 'my_god'.isidentifier() True >>> 'my10'.isidentifier() True >>> '10my'.isidentifier() #Identifier cannot start with a number False
Determine whether it is a reserved identifier of python (such as if and for):
>>> import keyword
>>> keyword.iskeyword('if')
True
>>> keyword.iskeyword('py')
False
2.6 interception

>>> ' Remove the blank on the left'.lstrip() 'Remove the blank on the left' >>> 'Remove the blank on the right '.rstrip() 'Remove the blank on the right' >>> ' Remove the blank on both sides '.strip() 'Remove the blank on both sides'
Among them, chars=None means nothing, which means removing white space. You can pass in the string to be removed here:
>>> 'www.ilovefishc.com'.lstrip('wcom.')
'ilovefishc.com'
>>> 'www.ilovefishc.com'.rstrip('wcom.')
'www.ilovefish'
>>> 'www.ilovefishc.com'.strip('wcom.')
'ilovefish'
'''
Here, the first example is right'www.ilovefishc.com'This string is searched by character from left to right until it is no longer deleted'wcom.':
First, three'w'All in'wcom.'In, delete;
next,'.'stay'wcom.'In, delete;
then,'i'be not in'wcom.'In, stop finding.
It is not deleted as a whole'wcom.'I mean.
'''
Delete string as a whole:
>>> 'www.ilovefishc.com'.removeprefix('www.') #Deletes the specified prefix
'ilovefishc.com'
>>> 'www.ilovefishc.com'.removesuffix('.com') #Delete specified suffix
'www.ilovefishc'
2.7 disassembly and splicing
Split:
>>> 'www.ilovefishc.com'.partition('.') #Find the separator from left to right, split it with '.' as the flag, and split it only once
('www', '.', 'ilovefishc.com')
>>> 'www.ilovefishc.com'.rpartition('.') #Find the separator from right to left, split it with '.' as the flag, and split it only once
('www.ilovefishc', '.', 'com')
>>> 'www.ilovefishc.com'.split('.') #Find the separator from left to right, split with '.' as the flag, and split all
['www', 'ilovefishc', 'com']
>>> 'www.ilovefishc.com'.split('.',1)
['www', 'ilovefishc.com']
>>> 'www.ilovefishc.com'.rsplit('.',1) #Find the separator from right to left, split it with '.' as the flag, and split it only once
['www.ilovefishc', 'com']
>>> 'you\n I\r he\n\r she'.splitlines() #Split with newline character. The default is False, which means that the result does not contain newline character
['you', 'I', 'he', '', 'she']
>>> 'you\n I\r he\n\r she'.splitlines(True) #Change to False to indicate that the result contains a newline character
['you\n', 'I\r', 'he\n', '\r', 'she']
Splicing:
>>> '.'.join(['www', 'ilovefishc', 'com']) #Here, the substrings to be spliced are wrapped in a list, and tuples can also be used
'www.ilovefishc.com'
#You can also splice with a plus sign, but join is faster:
>>> x = 'fishc'
>>> x += x
>>> x
'fishcfishc'
>>> ''.join(('fishc', 'fishc'))
'fishcfishc'
- format() syntax format string:
>>> '1+2={}, 2^2={}, 3^3={}'.format(1+2, 2*2, 3*3*3)
'1+2=3, 2^2=4, 3^3=27'
#Numbers can be written in curly braces to indicate which content (location index):
>>> '{}notice{}I'm very excited'.format('I', 'you')
'I'm excited to see you'
>>> '{1}notice{0}I'm very excited'.format('I', 'you')
'You're excited to see me'
#The string in the parameter is treated as a tuple element, so the subscript starts from 0 and the index value is in curly braces
#The same index value can be referenced multiple times:
>>> '{0}{0}{1}{1}'.format('yes', 'wrong')
'right and wrong'
#You can also use keyword parameters:
>>> 'My name is{name},I love{fav}. '.format(fav='Python', name='Three ears 01') #At this time, the order in tuples is not important
'My name is three ears 01, I love you Python. '
#Location index and keyword index can be combined:
>>> 'My name is{name},I love{0},{0}Very fun.'.format('Python', name='Three ears 01')
'My name is three ears 01, I love you Python,Python Very fun.'
#Enter curly braces
>>> '{}, {}, {}'.format(1, '{}', 2) #Think of curly braces as strings
'1, {}, 2'
>>> '{}, {{}}, {}'.format(1, 2) #Annotate the curly braces with curly braces, and there is only one left in the tuple
'1, {}, 2'
More usage:
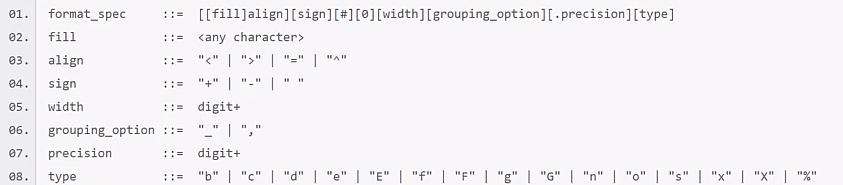
[[fill]align][sign][#][0][width][grouping_option][.precision][type]
3.1 [align]
>>> '{:^10}'.format('apple') #The width is 10, ^ indicates the center
' apple '
>>> '{1:<6}{0:>6}'.format('boy', 'cat') #When the width is 6, 1 indicates that the index is 1, i.e. 'cat', < indicates left, and > indicates right
'cat boy'
#It's the same with changing location index to keyword index
>>> '{c:<6}{b:>6}'.format(b='boy', c='cat')
'cat boy'
#Perceptual sign padding 0 (valid for numbers only):
>>> '{:09}'.format(55) #Width 9
'000000055'
>>> '{:09}'.format(-55)
'-00000055'
#You can specify the character to be filled in (at this time, you need to indicate the position instead of sensing the sign to fill in 0):
>>> '{:%^9}'.format(55)
'%%%55%%%%'
>>> '{:%>9}'.format(-55)
'%%%%%%-55' #There is no sense sign here. If you want to sense the sign, replace it with the equal sign:
>>> '{:%=9}'.format(-55)
'-%%%%%%55' #Similarly, when 0 is filled in front, it can also be:
>>> '{:0=9}'.format(-55)
'-00000055'
3.2 [sign]

>>> '{:+} {:+}'.format(1, -1)
'+1 -1'
>>> '{:-} {:-}'.format(1, -1)
'1 -1'
>>> '{: } {: }'.format(1, -1)
' 1 -1'
Set the separator for the thousands:
>>> '{:,}'.format(1234567)
'1,234,567'
>>> '{:_}'.format(1234567)
'1_234_567'
Precision (not allowed on integers):
>>> '{:.2f}'.format(3.1415) #Limit the number of decimal places
'3.14'
>>> '{:.2g}'.format(3.1415) #Limit the number of decimal places
'3.1'
>>> '{:.6}'.format('I love Python') #Limit the size of the maximum field of a non numeric type
'I love'
type:
Integer:
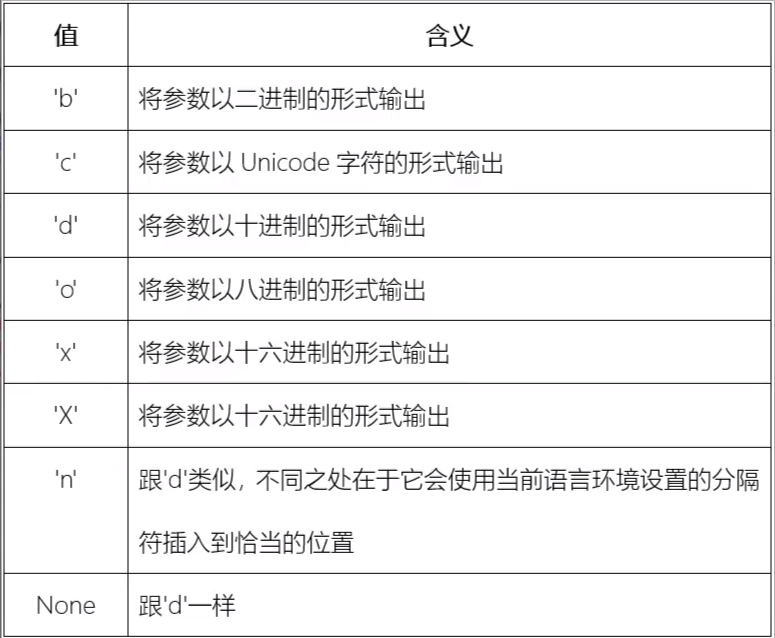
>>> '{:b}'.format(80)
'1010000'
>>> '{:c}'.format(80)
'P'
>>> '{:d}'.format(80)
'80'
>>> '{:o}'.format(80)
'120'
>>> '{:x}'.format(80)
'50'
>>> '{:#b}'.format(80) #Add one#The prefix will be added to the result
'0b1010000' #A 0b is added to indicate that it is binary
Decimal:
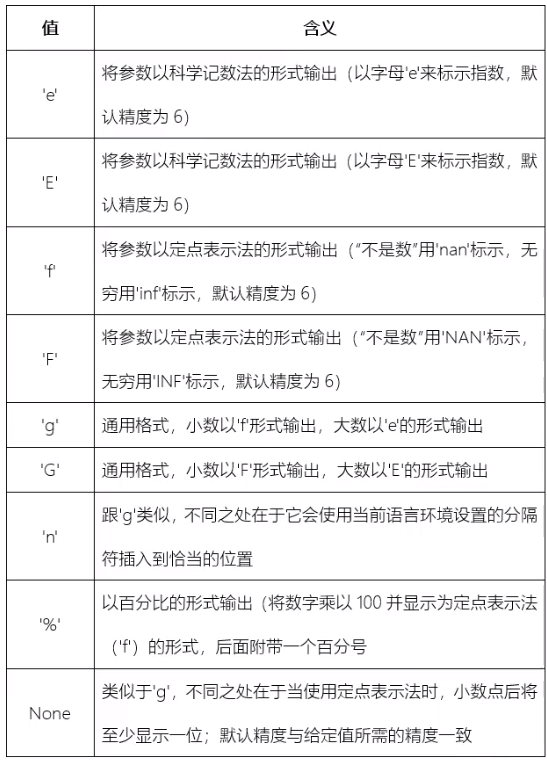
>>> '{:e}'.format(30)
'3.000000e+01' #The decimal of scientific counting here is 6 digits
>>> '{:f}'.format(3.1415)
'3.141500' #6 decimal places
>>> '{:g}'.format(123456789) #g general, large
'1.23457e+08'
>>> '{:g}'.format(1234.56789) #g general, decimal
'1234.57'
>>> '{:%}'.format(0.98)
'98.000000%'
>>> '{:.2%}'.format(0.98) #Change precision
'98.00%'
>>> '{:.{prec}%}'.format(3.1415, prec=2) #Change precision with keywords
'314.15%'
>>> '{:{fill}{align}{width}.{prec}{ty}}'.format(3.1415, fill='+', align='^', width=10, prec=3, ty='g')
'+++3.14+++'
>>> '{:.4g}'.format(3.1415) #rounding
'3.142'
>>> '{:.3%}'.format(3.1415) #%Different from the precision expressed by g, g limits the number of decimal places before and after the decimal point, as mentioned earlier
'314.150%'
f/F-string: it can be regarded as a syntax sugar of format(), which further simplifies the operation and improves the function (as a product of Python 3.6, format() is more compatible, so it is more extensive):
>>> '1+2={}, 2^2={}, 3^3={}'.format(1+2, 2*2, 3*3*3)
'1+2=3, 2^2=4, 3^3=27' #You can become:
>>> f'1+2={1+2}, 2^2={2*2}, 3^3={3*3*3}' #format() is not needed
'1+2=3, 2^2=4, 3^3=27'
#The same is true for formatting strings
>>> '{:010}'.format(-55)
'-000000055'
>>> f'{-55:010}'
'-000000055'
>>> '{:,}'.format(1234567)
'1,234,567'
>>> F'{1234567:,}'
'1,234,567'