This article mainly introduces the common function set of string operation based on Python. Please refer to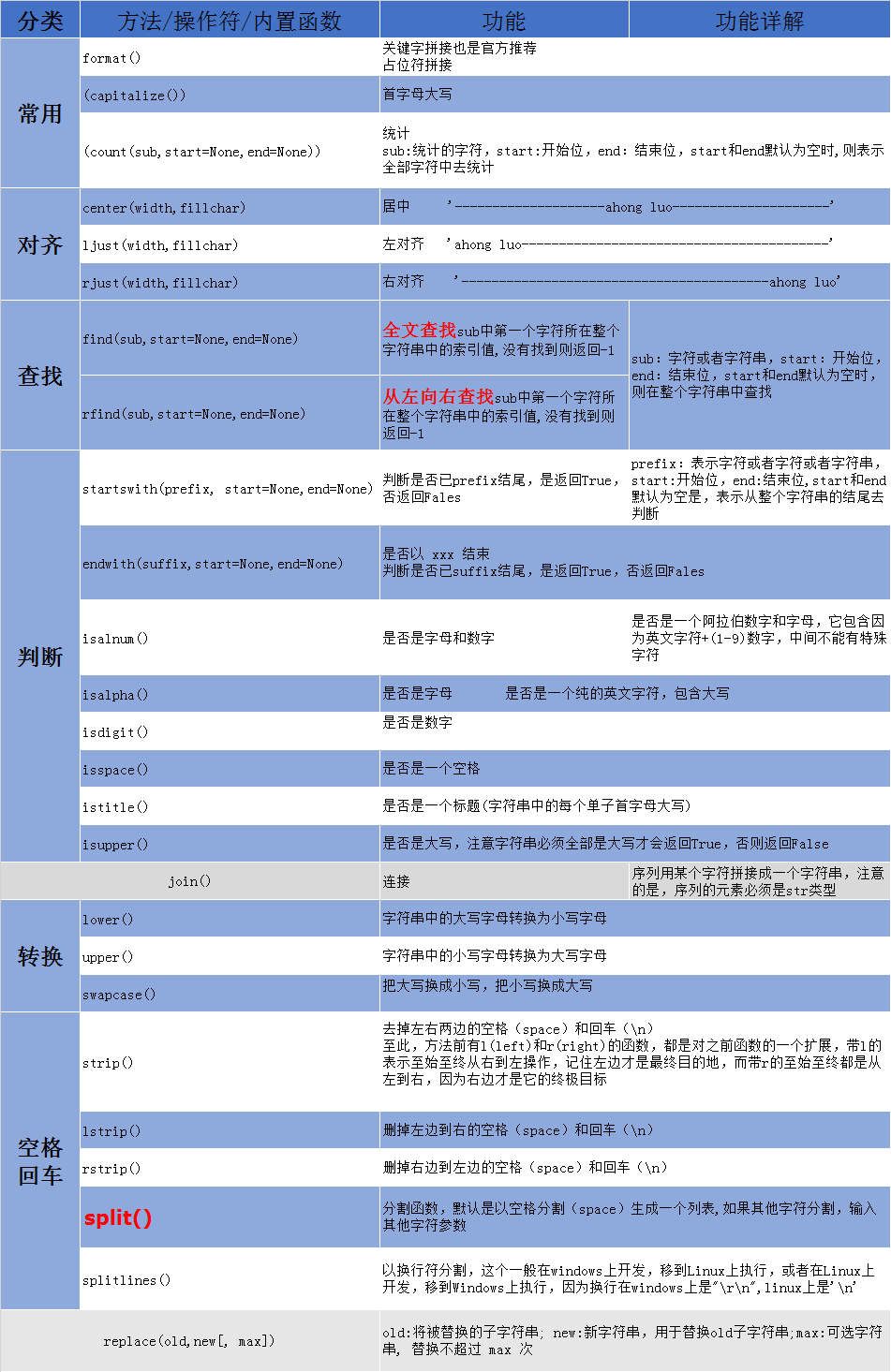
Article directory
- 1. Definition of string
- 2, slice
- 3. Capitalize (capitalize())
- 4. Count (sub, start = none, end = none)
- 5,center(width,fillchar)
- 6,ljust(width,fillchar)
- 7.rjust(width,fillchar)
- 8. Encode
- 9,endwith(suffix,start=None,end=None)
- 10,find(sub,start=None,end=None)
- 11,rfind(sub,start=None,end=None)
- 12,format()
- 14,isalnum()
- 15,isalpha()
- 16,isdigit()
- 17,isspace()
- 18,istitle()
- 19,isupper()
- 21,lower()
1. Definition of string
#Define empty string<br>>>> name=''<br>#Define non empty string >>> name="luoahong"<br>#Access by subscript >>> name[1] 'u'<br>#The value of string cannot be modified, otherwise an error will be reported >>> name[2] = "3" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Special note: if the string is modified, the memory address of the string will also change, so it cannot be modified. But for the list, it can be modified because the memory of the list is unchanged, and it can be modified directly on the list
2, slice
Special note: strings, like lists and tuples, can be sliced
>>> name="ahong luo" >>> name[1:4] #Take characters between 1 and 4, including 1, excluding 4 'hon' >>> name[1:-1] #Take characters between 1 and - 1, including 1, excluding - 1 'hong lu' >>> name[0:3] 'aho' >>> name[:3] #Select from the beginning, 0 can be omitted, the effect is the same as name[0:3] 'aho' >>> name[3:] #To get the last value, you must not write - 1, only this 'ng luo' >>> name[0::2] #The next two represent: every other character takes one 'aoglo' >>> name[::2] #Zero can be omitted from the beginning, the effect is the same as the last sentence 'aoglo'
3. Capitalize (capitalize())
>>> name="ahong luo" >>> name.capitalize() 'Ahong luo' >>>
4. Count (sub, start = none, end = none)
sub: statistical character, start: start bit, end: end bit, when start and end are empty by default, it means that all characters are de counted
>>> name="ahong luo"
#There are start and end characters
<br>
>>> name.count("o",1,5)
1<br>#Count characters from the entire string
>>> name.count("o")<br>2
>>>
5,center(width,fillchar)
If the width is less than or equal to the len gt h of (< =) string, the original string will be returned. If the width is greater than or equal to (>) string, the fillchar will be used to fill in. The processing resu lt is equal to width, and the string is in the middle of fillchar
>>> name="ahong luo" >>> len(name) 9<br>#10 less than or equal to string width >>> name.center(12,'-') '-ahong luo--'<br>#50 is greater than the string length and the string is in the middle of the fill character >>> name.center(50,'-') '--------------------ahong luo---------------------' >>> len(name.center(50,'-')) 50
6,ljust(width,fillchar)
If the length of the string is greater than width, the original string will be returned. If it is less than width, it will be filled with fillchar (fill character). The processing result is equal to width, and fillchar is on the far right side of the string
>>> name="ahong luo" >>> len(name) 9<br>#Less than or equal to the length of the string >>> name.ljust(8,'-') 'ahong luo'<br>#Greater than the length of the string >>> name.ljust(50,'-') 'ahong luo-----------------------------------------'
Special note: l in ljust means left, right to left
7.rjust(width,fillchar)
If the length of the string is greater than width, the original string will be returned. If it is less than width, it will be filled with fillchar (fill character). The processing result is equal to width, and fillchar is on the leftmost side of the string
>>> name="ahong luo"<br>>>> len(name) 9 >>> name.rjust(8,'-') 'ahong luo' >>> name.rjust(50,'-') '-----------------------------------------ahong luo'
Special note: l in ljust means left, from left to right
8. Encode
The encoding and decoding of strings. Needless to say, I wrote a blog specifically. Detailed address: click here
9,endwith(suffix,start=None,end=None)
Judge whether it has ended with suffix, return True if yes, return false if no
suffix: indicates character, start: start bit, end: end bit, start and end are empty by default, indicating judging from the end of the whole string > > > name = "ahong luo"
<em id="__mceDel">>>> name.endswith('0',1,4) False<br> >>> name.endswith('o') True >>> name.endswith('o',1,4) False</em>
10,find(sub,start=None,end=None)
Full text search for the index value of the whole string where the first character in sub is located. If not found, return - 1
sub: character or string, start: start bit, end: end bit. When start and end are empty by default, they are searched in the whole string
>>> name="ahong luo"<br><br>#If not found, return to - 1
>>> name.find("lu",1,4)
-1
>>> name.find("a",2)
-1
>>> name.find("lu")
6
>>> name.find("lu",1,6)
-1
>>> name.find("lu",1,10)
6
>>>
Recommend our Python learning button qun: 913066266, and see how the seniors learn! From the basic Python script to web development, crawler, django, data mining and so on [PDF, actual source], the data from zero base to project actual combat have been sorted out. To everyone in Python! Every day, Daniel regularly explains Python technology, shares some learning methods and small details that need attention, and click to join our python learners' gathering place
11,rfind(sub,start=None,end=None)
Find the index value in the whole string of the first character in sub from left to right, and return - 1 if not found
>>> name="ahong luo"<br>#find
>>> name.rfind("a")
0<br>#not found
>>> name.rfind("a",2)
-1
12,format()
①Keyword splicing is also an official recommendation
1
2
3
4
5
6
7
8
9
name = "alex"
age = 18
info = '''----info-----
name:{_name}
age:{_age}
'''.format(_name=name,_age=age)
print(info)
②Placeholder splicing
1
2
3
4
5
6
8
7
9
name = "alex"
age = 18
info = '''----info-----
name:{0}
age:{1}
'''.format(name,age)
print(info)
## 13,format_map()
Data format, passed in as a dictionary
>>> name="name:{name},age:{age}"
>>> name.format_map({"name":"luoahong",'age':23})<br>#Output result
'name:luoahong,age:23'
14,isalnum()
Whether it is an Arabic numeral and letter. It contains English characters + (1-9) numbers. No special characters are allowed in the middle
>>> age='23' >>> age.isalnum() True<br>#Having special characters >>> age='ab23' >>> age='ab' >>> age.isalnum() True >>> age='ab' >>> age.isalpha() True >>>
15,isalpha()
Whether it is a pure English character, including uppercase
>>> age = 'ab' >>> age.isalpha() True #With numbers >>> age = 'ab23' >>> age.isalpha() False #Capitalization >>> age = 'Ab' >>> age.isalpha() True
16,isdigit()
Judge whether it is an integer
17,isspace()
Judge whether it is a space
#Not spaces >>> age = ' age' >>> age.isspace() False #It's a blank space. >>> age = ' ' >>> age.isspace() True
18,istitle()
Whether it is a title (each single initial in the string is capitalized)
#The first letter of each word is lowercase < br > > > name = "luahong" >>> name.istitle() False >>> name="luo a hong" >>> name.istitle() False<br>#Capitalize each word >>> name="Luo A Hong" >>> name.istitle() True >>> name="Luoahong" >>> name.istitle() True
19,isupper()
If it is uppercase, note that the string must be all uppercase to return True, otherwise it returns False
#All uppercase < br > > > name = "Luo" >>> name.isupper() True < br > ා lowercase >>> name="Luo" >>> name.isupper() False >>> ## ```20,join() The sequence is spliced into a string with a certain character. Note that the elements of the sequence must be str class
a = ['1','2','3']
'+'.join(a)
'1+2+3'
21,lower()
Conversion of uppercase letters to lowercase letters in strings
name="LuoAHong"
name.lower()
'luoahong'
## 22,upper() Conversion of lowercase letters to uppercase letters in strings
name="LuoAHong"
name.upper()
'LUOAHONG'
## 23,strip() Remove space s and carriage returns on the left and right
name= " \n luoahong \n"
name.strip()
'luoahong'
## 24,lstrip() Delete left to right space s and carriage returns (\ n)
name= " \n luoahong \n"
name.lstrip()
'luoahong \n
## 25,rstrip() Delete right to left space s and carriage returns (\ n)
name= " \n luoahong \n"
name.rstrip()
' \n luoahong'
So far, there are l(left) and r(right) functions in front of the method, both of which are an extension of the previous functions. The representation with L is operated from right to left from the beginning to the end. Remember that the left is the final destination, while the one with r is from left to the end, because the right is its ultimate goal ## 26,split() Split function. By default, a list is generated by space splitting. If other characters are split, enter other character parameters
name="ahong luo"
#Blank by default, split by space
name.split()
['ahong', 'luo']
name="ahong+luo"
#Split by "+" character
>>> name.split("+")
['ahong', 'luo']
#Split by '\ n'
name="ahong\nluo"
name.split("\n")
['ahong', 'luo']
## 27,splitlines() This is usually developed on windows, moved to Linux for execution, or developed on Linux, moved to windows for execution, because line breaking is "\ R \ n" on windows, and "\ n" on Linux
name="ahong\nluo"
name.splitlines()
['ahong', 'luo']
## 28,swapcase() Change upper case to lower case and lower case to upper case
name="Luo"
name.swapcase()
'lUO'
## 29,startswith(prefix, start=None,end=None) Judge whether to start with prefix, return True if yes, return false if no prefix: indicates character or character or string, start: start bit, end: end bit, start and end are empty by default, indicating judging from the end of the whole string
name="ahong luo"
name.startswith("luo") #Find the "luo" string at the beginning
False
name.startswith("h",3,5) #No beginning of character 'h' found between index 3 and index 5
False
## 30,replace(old,new[, max]) Old: substring to be replaced; new: new string, used to replace old substring; Max: optional string, replaced no more than max times
name="wo shi luo a hong"
name.replace("shi","bushi")
'wo bushi luo a hong'
#The original string does not change
name.replace("shi","bushi",0)
'wo shi luo a hong'
name.replace("shi","bushi",1)
'wo bushi luo a hong
## 31,zfill(width) Whether the len gt h of the character is greater than or equal to (> =) with. If it is smaller than width, it will be filled with 0 in the string money. If > = width, it will return the original string
name="luoahong"
len(name)
8
#width greater than string length
name.zfill(11)
'000luoahong'
#width is less than or equal to string length
name.zfill(8)
'luoahong'

