1, Scene analysis
Today, let's climb my personal blog and summarize my article title and address into an Excel for easy viewing.

What bad thoughts can wshanshi have? She just... Wants to summarize her article and related address
2, Simple interface analysis:
Development all know, open debugging mode. Select Elements, and then find the box where the article is stored, as shown below.
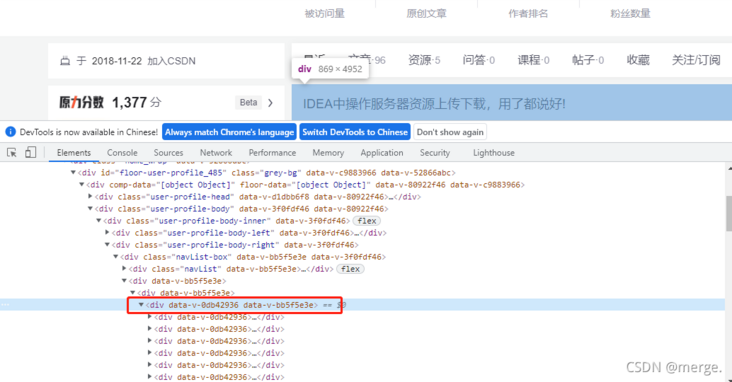
After analysis, it is found that each box stores information related to an article.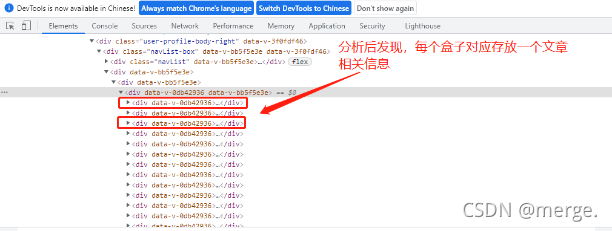
If you look carefully, you can find that the class of all article tags is the same.
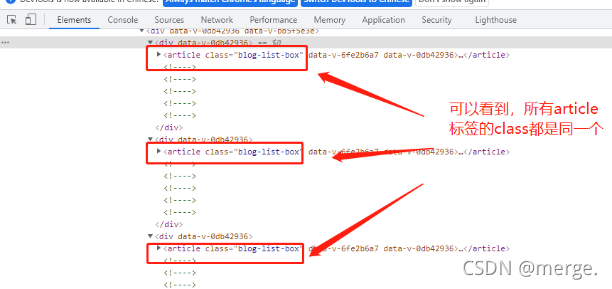
Oh, they all look the same. That's good. By combining the class selector with the tag, you can get it at once.
Click any article div and you will find that there are article hyperlinks, titles and descriptions.
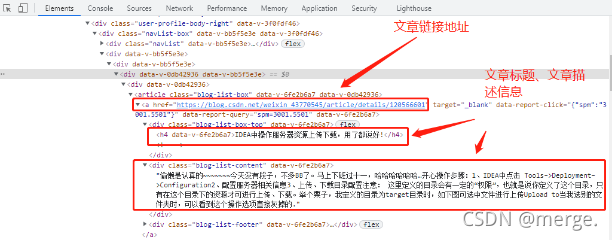
Combined with the ultimate goal of this operation, the following operation steps are obtained.

After analyzing the scene, we will start to make white.
The landlord will use two methods (Python and Java) to collect the data of personal articles. Just do it
3, Python implementation
Example version: Python 3.8
Installation package: requests, beatifulsoup4, pandas
Library package installation command (under windows)
pip install requests pip install beautifulsoup4 pip install pandas
3.1. Common library description
3.1.1,Requests
What are Requests? What are the advantages and disadvantages of Requests?
Chinese website address: https://docs.python-requests.org/zh_CN/latest/user/quickstart.html
3.1.2,Beautiful Soup 4.4.0
Description: it is a Python library that can extract data from HTML or XML files.
Chinese website address: https://beautifulsoup.readthedocs.io/zh_CN/latest/
3.1.3,Pandas
Description: powerful Python data analysis support library
Chinese website: https://www.pypandas.cn/docs/
See the official website happy for specific use details. There is no more introduction here!!!
3.2 code example
Direct post code: the obtained article title and article link are integrated and exported to a. csv file.
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import pandas as pd
import openpyxl
import re
import os
def is_in(full_str, sub_str):
return full_str.count(sub_str) > 0
def blogOutput(df,url):
# if file does not exist write header
if not os.path.isfile(url):
df.to_csv(url, index = False)
else: # else it exists so append without writing the header
df.to_csv(url, mode = 'a', index = False, header = False)
if __name__ == '__main__':
target = 'https://blog.csdn.net/weixin_43770545'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
res = requests.get(target,headers=headers)
#div_bf = BeautifulSoup(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
#Define output array
result=[]
for item in soup.find_all("article",{"class":"blog-list-box"}):
#Extract article title
#print(item.find("h4").text.strip())
#Extract article address links
#print(item.find("a").get('href'))
data = []
data.append(item.find("h4").text.strip())
data.append(item.find("a").get('href'))
result.append(data)
df = pd.DataFrame(result,columns=['Article title', 'Article address'])
# Call the function to write data to the table
blogOutput(df, 'F:/blog_result.csv')
print('Output complete')After coding, Run. As shown in the figure below, Run (shortcut key F5).
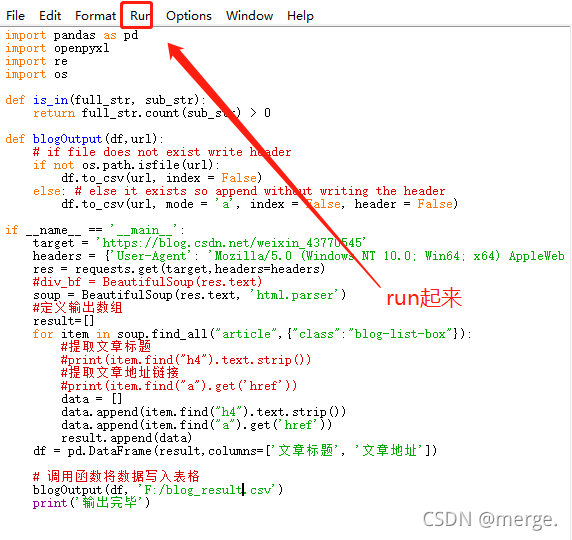
After the prompt is output, you can view the exported file.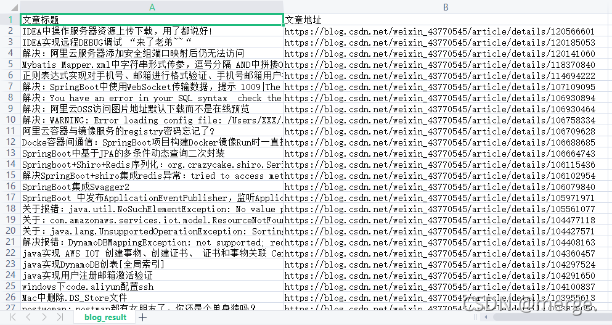
Yes, I got the data!!! There are so many Python methods to demonstrate (after all, I'm not good at it). Let's look at brother Java.
4, Java implementation
The Java operation uses the jsup library, which essentially operates Dom.
Yibai tutorial website (friendly link): https://www.yiibai.com/jsoup/jsoup-quick-start.html
4.1 environment, warehouse and package
Jsoup Maven:
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency>4.2 code example
Define BlogVo class
public class BlogVo implements Serializable {
/**
* Article title
*/
private String title;
/**
* Article address
*/
private String url;
@Excel(colName = "Article title", sort = 1)
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
@Excel(colName = "Article title", sort = 2)
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}service interface
/** * Get extracted blog information * * @return */ List<BlogVo> getBlogList(); /** * Export csv file * * @param httpServletResponse * @throws Exception */ void export(HttpServletResponse httpServletResponse) throws Exception;
serviceImpl implementation class
@Override
public List<BlogVo> getBlogList() {
List<BlogVo> list = new ArrayList<>();
try {
Document document = Jsoup.connect("https://blog.csdn.net/weixin_43770545").timeout(20000).get();
Elements e = document.getElementsByClass("blog-list-box");
Elements h4 = e.select(".blog-list-box-top").select("h4");
Elements a = e.select(".blog-list-box").select("a");
List<String> h4List = new ArrayList<>();
List<String> aList = new ArrayList<>();
h4.forEach(item -> {
h4List.add(item.text());
});
a.forEach(item -> {
String href = item.attr("href");
aList.add(href);
});
for (int i = 0; i < h4List.size(); i++) {
BlogVo blogVo = new BlogVo();
blogVo.setTitle(h4List.get(i));
blogVo.setUrl(aList.get(i));
list.add(blogVo);
}
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
@Override
public void export(HttpServletResponse httpServletResponse) throws Exception {
new ExcelExportUtils().export(BlogVo.class, getBlogList(), httpServletResponse, "blog");
}controller control layer
/**
* Export csv file
*
* @param response
* @throws Exception
*/
@GetMapping("/getExport")
public void getExport(HttpServletResponse response) throws Exception {
demoService.export(response);
}Custom annotation class (Excel)
package com.wshanshi.test.entity;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Excel {
public String colName(); //Listing
public int sort(); //order
}Tool class (export)
package com.wshanshi.test.util;
import com.wshanshi.test.entity.Excel;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.formula.functions.T;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedOutputStream;
import java.lang.reflect.Method;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
/**
* Export tool class
*/
public class ExcelExportUtils {
public void ResponseInit(HttpServletResponse response, String fileName) {
response.reset();
//Set the content disposition response header to control the browser to open the file in the form of download
response.setHeader("Content-Disposition", "attachment;filename=" + fileName + ".csv");
//Let the server tell the browser that the data it sends belongs to excel file type
response.setContentType("application/vnd.ms-excel;charset=UTF-8");
response.setHeader("Prama", "no-cache");
response.setHeader("Cache-Control", "no-cache");
response.setDateHeader("Expires", 0);
}
public void POIOutPutStream(HttpServletResponse response, HSSFWorkbook wb) {
try {
BufferedOutputStream out = new BufferedOutputStream(response.getOutputStream());
wb.write(out);
out.flush();
out.close();
} catch (Exception e) {
e.printStackTrace();
}
}
@SuppressWarnings({"unchecked", "rawtypes"})
public void export(Class<?> objClass, List<?> dataList, HttpServletResponse response, String fileName) throws Exception {
ResponseInit(response, fileName);
Class excelClass = Class.forName(objClass.toString().substring(6));
Method[] methods = excelClass.getMethods();
Map<Integer, String> mapCol = new TreeMap<>();
Map<Integer, String> mapMethod = new TreeMap<>();
for (Method method : methods) {
Excel excel = method.getAnnotation(Excel.class);
if (excel != null) {
mapCol.put(excel.sort(), excel.colName());
mapMethod.put(excel.sort(), method.getName());
}
}
HSSFWorkbook wb = new HSSFWorkbook();
POIBuildBody(POIBuildHead(wb, "sheet1", mapCol), excelClass, mapMethod, (List<T>) dataList);
POIOutPutStream(response, wb);
}
public HSSFSheet POIBuildHead(HSSFWorkbook wb, String sheetName, Map<Integer, String> mapCol) {
HSSFSheet sheet01 = wb.createSheet(sheetName);
HSSFRow row = sheet01.createRow(0);
HSSFCell cell;
int i = 0;
for (Map.Entry<Integer, String> entry : mapCol.entrySet()) {
cell = row.createCell(i++);
cell.setCellValue(entry.getValue());
}
return sheet01;
}
public void POIBuildBody(HSSFSheet sheet01, Class<T> excelClass, Map<Integer, String> mapMethod, List<T> dataList) throws Exception {
HSSFRow r = null;
HSSFCell c = null;
if (dataList != null && dataList.size() > 0) {
for (int i = 0; i < dataList.size(); i++) {
r = sheet01.createRow(i + 1);
int j = 0;
for (Map.Entry<Integer, String> entry : mapMethod.entrySet()) {
c = r.createCell(j++);
Object obj = excelClass.getDeclaredMethod(entry.getValue()).invoke(dataList.get(i));
c.setCellValue(obj == null ? "" : obj + "");
}
}
}
}
}PostMan test export, the effect is as follows.
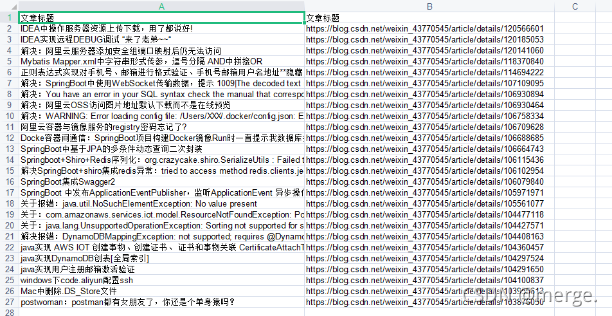
Oh, yes.
Although the data was exported, a problem was found. Less data? The data previously obtained in python is clearly more than 90. Why did you only request more than 20 this time? It's a little strange.

After a closer look at the next interface, it turns out that the page is loaded slowly. Request paging when you slide to the bottom.
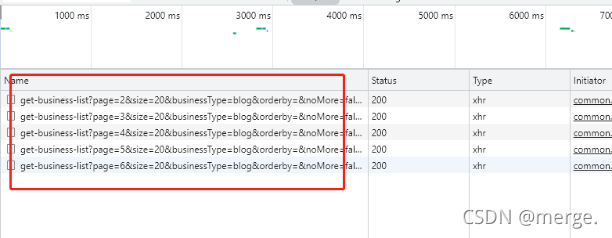
Oh, so it is. However, now that you see the interface, use postMan to adjust the white.
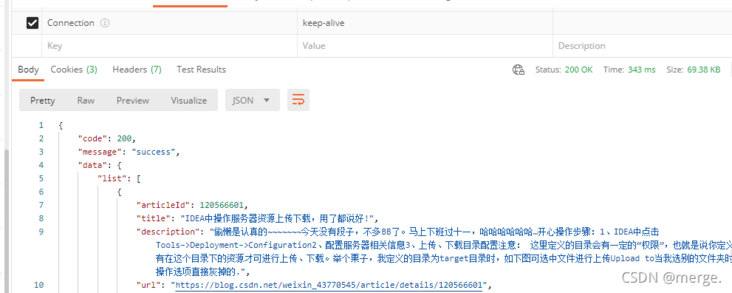
I got the data right away

So, there's another way. It is to directly request the Http interface. Just set the number of pages a little larger.
The example code is as follows:
public List<BlogVo> blogHttp() {
List<BlogVo> list = new ArrayList<>();
String s = HttpClientUtils.doGetRequest("https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=300&businessType=blog&orderby=&noMore=false&username=weixin_43770545", null, null, null);
RespDTO blogDTO = JSON.parseObject(s, RespDTO.class);
DataEntity data = blogDTO.getData();
data.getList().forEach(item -> {
BlogVo blogVo = new BlogVo();
blogVo.setUrl(item.getUrl());
blogVo.setTitle(item.getTitle());
list.add(blogVo);
});
return list;
}The effect is as follows. Try it yourself. You know
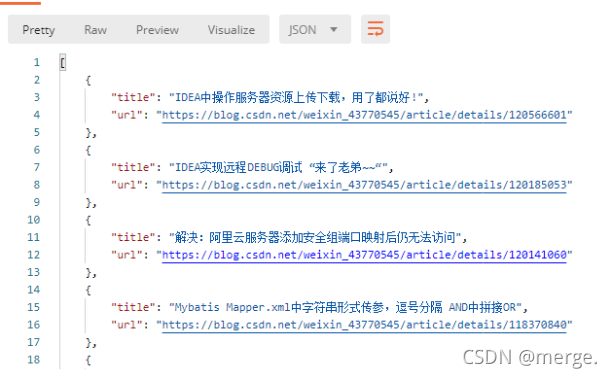
Harm, let's do it first! Don't learn bad
