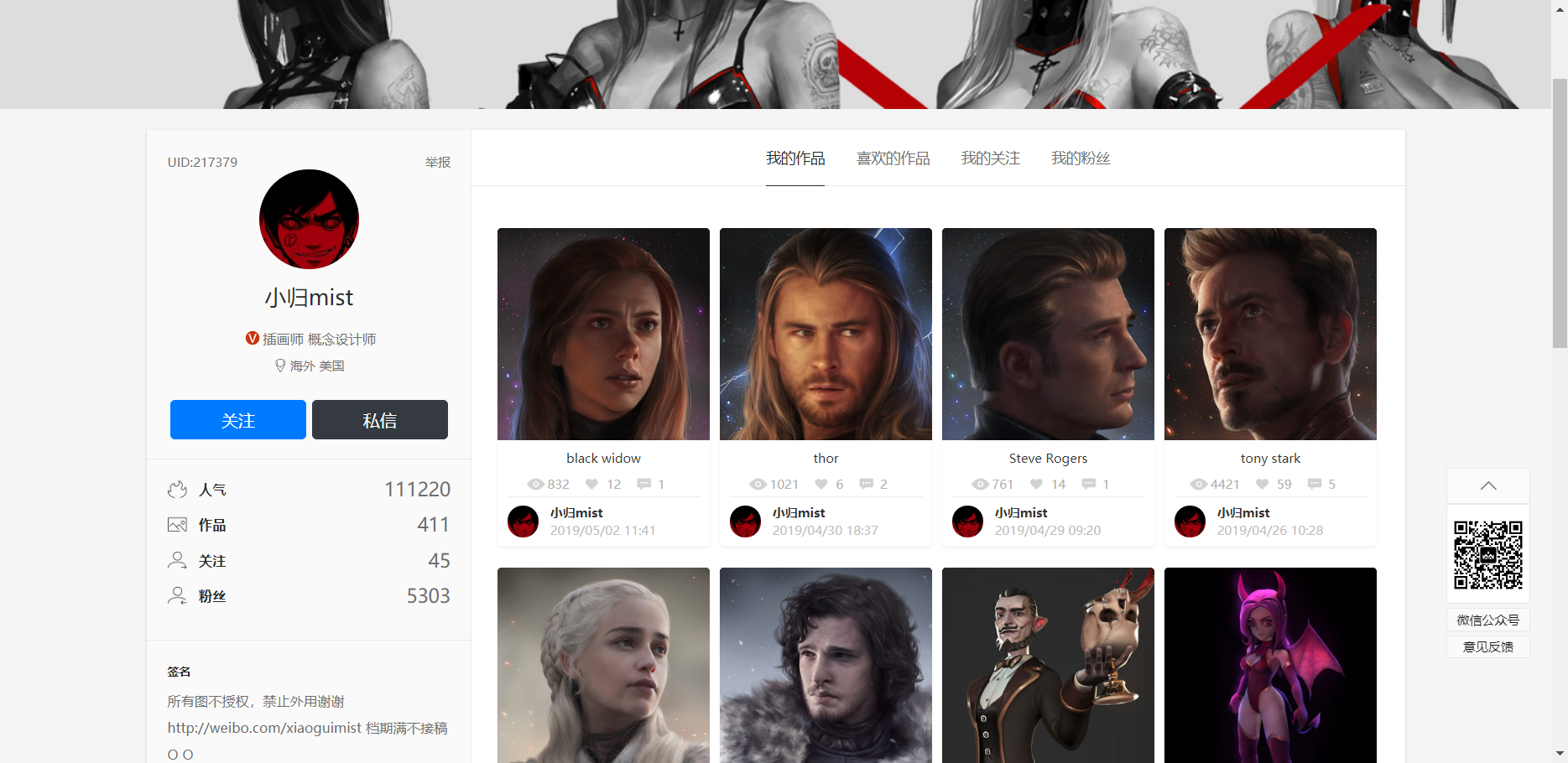
Open the first link for details
The key point is
The previous. jpg is the original image, which can be rewritten to get the original link by manipulating the string
Pictures published earlier are linked in different ways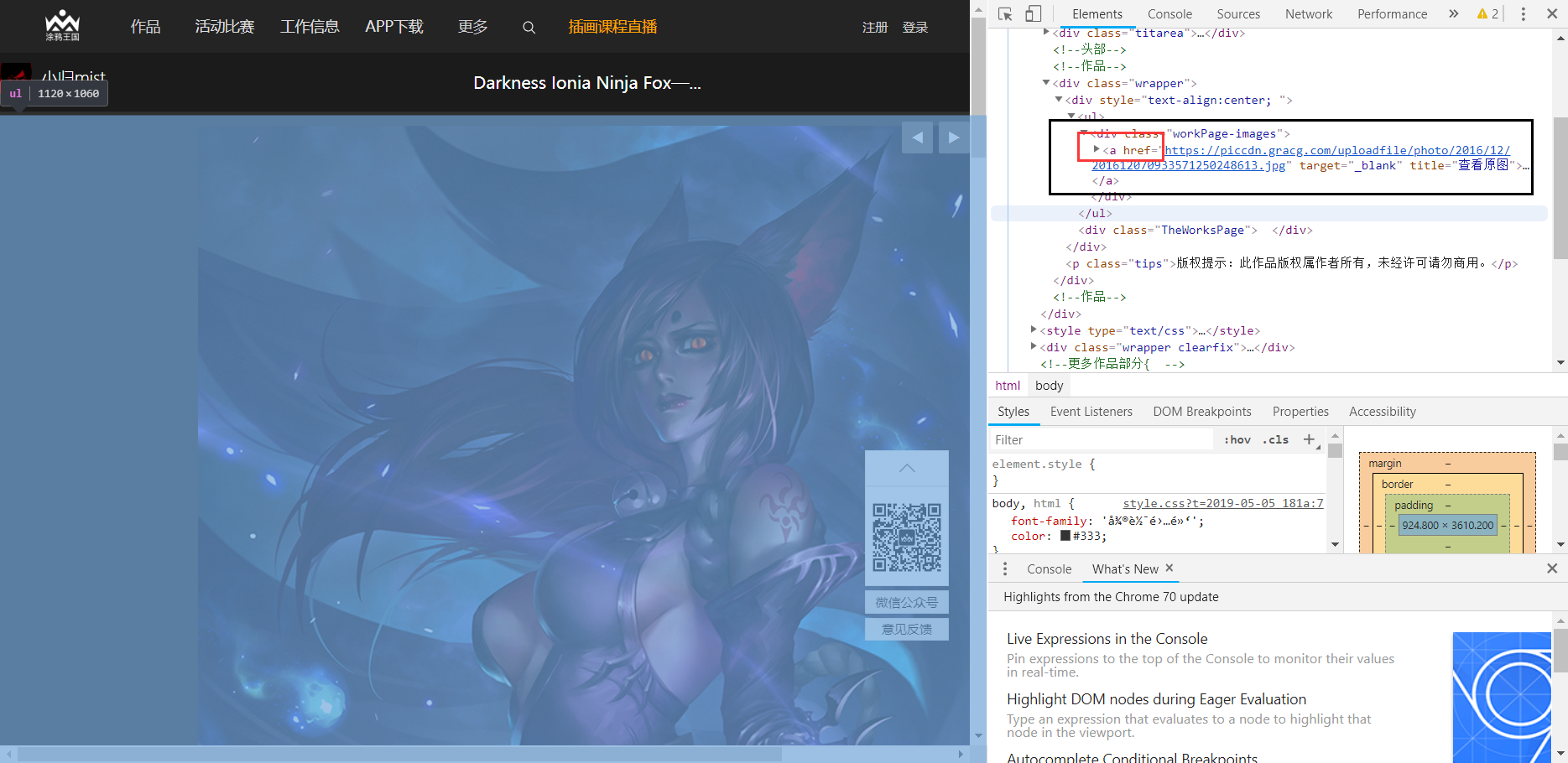
Here write a judgment to determine whether the obtained src is empty
Solve the key problems and sort out the ideas
1.https://www.gracg.com/p599367964217379?page=1
Change "page=x" to get the directory list of all pictures ------ format can be operated
2.xpath gets a separate link to the image that each thumbnail points to
def get_infos(url):
res=requests.get(url,headers=headers)
selector=etree.HTML(res.text)
pic_urls=selector.xpath('//div[@class="imgbox"]/a/@href')
for pic_url in pic_urls:
print(pic_url)
get_pictures(pic_url)
time.sleep(1)
3. After getting a single picture link, distinguish the code of the old and new web pages, and construct the download link.
def get_pictures(url):
res=requests.get(url,headers=headers)
selector=etree.HTML(res.text)
#Get the name of the picture
pic_name=selector.xpath('/html/body/div[1]/div[2]/div[1]/div/div[2]/text()')
name=pic_name[0].strip().replace('\n','')#Get rid of the spaces, get back in the mess
print(name)
#Get download links for pictures
pic_url=selector.xpath('//div[@class="workPage-images"]/img/@src')
# print(pic_url)
if len(pic_url):
# If there is not only one picture, add numbers after the picture name
if len(pic_url)==1:
downloadurl = pic_url[0].split('!')[0]
data = requests.get(downloadurl, headers=headers)
fp = open(downloadpath + name + '.jpg', 'wb')
fp.write(data.content)
fp.close()
else:
num=1
for pic_u in pic_url:
downloadurl=pic_u.split('!')[0]
data=requests.get(downloadurl,headers=headers)
fp=open(downloadpath+name+'__'+num.__str__()+'.jpg','wb')
num+=1
fp.write(data.content)
fp.close()
# print(downloadurl)
else:
pic_url=selector.xpath('//div[@class="workPage-images"]/a/@href')
#If there is not only one picture, add numbers after the picture name
if len(pic_url)==1:
downloadurl=pic_url[0]
data = requests.get(downloadurl, headers=headers)
fp = open(downloadpath + name + '.jpg', 'wb')
fp.write(data.content)
fp.close()
else:
num = 1
for pic_u in pic_url:
downloadurl = pic_u.split('!')[0]
data = requests.get(downloadurl, headers=headers)
fp = open(downloadpath + name + '__' + num.__str__() + '.jpg', 'wb')
num += 1
fp.write(data.content)
fp.close()
4. Finally write a main program to enter, and then fill in the access header of the imported package
if __name__=='__main__':
downloadpath='E:/spider_pictures/Xiao Gui mist_20190505/'
urls=['https://www.gracg.com/p599367964217379?page={}'.format(num) for num in range(7,27)]
for url in urls:
get_infos(url)