Preface
Requirements: search and save 360 Gallery pictures
Gallery address: 360 Gallery
Basic thinking
After a simple analysis, it is found that the 360 picture library uses dynamic rendering, and uses pull-down reverse loading of pictures, so there are three common methods to solve the problem, namely, operating js, simulation browser, Ajax. If you use the simulation of the trans code is high, slow (of course, more stable), but after a simple analysis found that the image is loaded using Ajax. Then use ajax directly.
Analyze the request
View the response of the request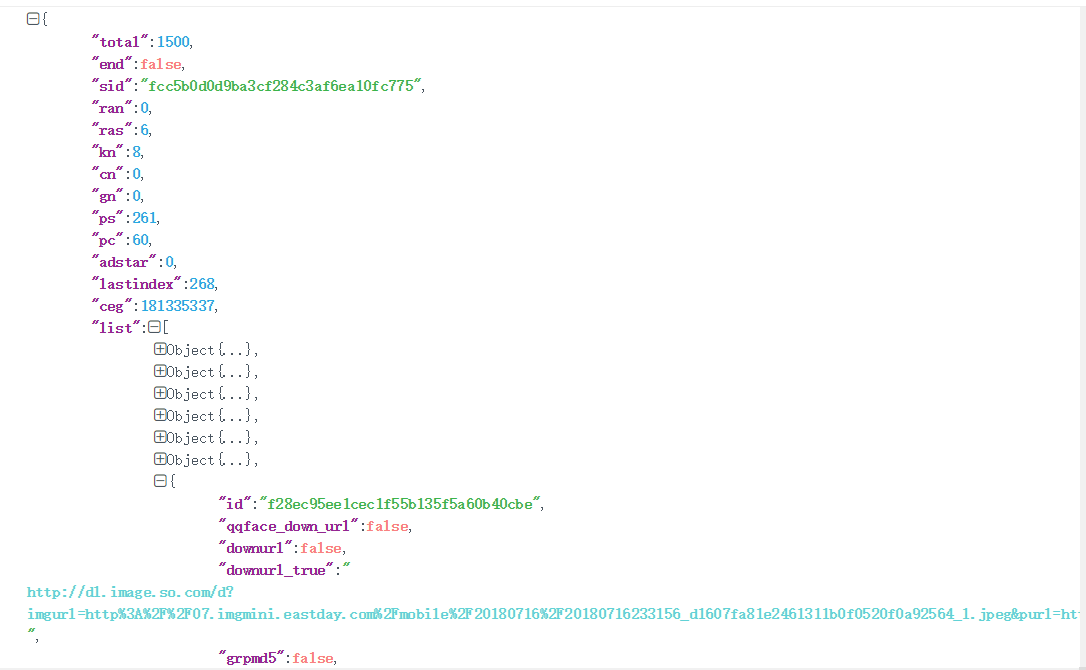
The result of the discovery request is a json string, and "img" is found in the string:“ http://image2.sina.com.cn/ty/k/2007-02-28/U1830P6T12D2772429F44DT20070228124853.jpg ”, such a field, this is the image address to be crawled.
Then the problem is simple. After simulating the request through requses, we can directly parse json to extract the image address and save it.
Our analysis request header has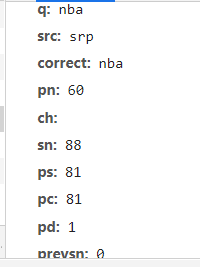
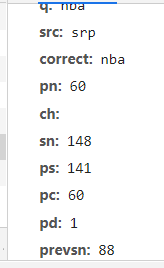
These important fields
q: search keywords
PS SN: tag for crawling pictures (increase by 60 each time)
pn: number of pages to crawl pictures
Write code after simple analysis
import requests from urllib.request import urlretrieve import time def image_spider(key_q, key_ps, key_sn): # Request function url = "http://image.so.com/j?q=nba&src=srp&correct=nba&pn=60&ch=&sn=208&ps=201&pc=60&pd=1&prevsn=148" \ "&sid=39b8dabeae51031efce5a8d8b1fc6957&ran=0&ras=6&cn=0&gn=0&kn=8&comm=1" headers = { 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 " "(KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36", 'Referer': "http://image.so.com/i?q=nba&src=srp" } params = { 'q': key_q, 'src': 'srp', 'pn': '60', 'ch': '', 'sn': key_sn, 'ps': key_ps, 'pc': '60', 'pd': '1', 'prevsn': '0', 'sid': 'd34ad660320d853f00ea2d476ba2eaa5', 'ran': '0', 'ras': '6', 'cn': '0', 'gn': '0', 'kn': '8', 'comm': '1' } response = requests.get(url, headers=headers, params=params).json() # Turn json lists = response.get('list') # Extract list pieces with a value of a list for lis in lists: open_image(lis.get('img')) # Traverse the list and extract img string (picture url) time.sleep(2) def open_image(image_url): image_name = hash(image_url) # Picture name (url value of picture address) path = 'image/%s.jpg' % str(image_name) # Picture address urlretrieve(image_url, path) # Save pictures print(image_url, 'Download successful') time.sleep(1) def main(): key_q = input("Enter the image keywords to crawl") ps = 81 sn = 88 for i in range(0, 10): # How many pictures to crawl key_ps = ps+i*60 key_sn = sn+i*60 image_spider(key_q, key_ps, key_sn) if __name__ == '__main__': main()
summary
The 360 Gallery crawler is not difficult, in fact, as long as you carefully analyze ajax and the returned json, you can find the results.