1. itertools iterator function
itertools includes a set of functions for processing sequential datasets.The functions provided by this module are inspired by similar features in functional programming languages such as Clojure, Haskell, APL, and SML.The goal is to be able to process quickly, use memory efficiently, and join together to represent more complex iteration-based algorithms.
Iterator-based code provides better memory consumption characteristics than code that uses lists.Data is not generated from iterators until it is really needed; for this reason, it is not necessary to store all the data in memory at the same time.This "lazy" processing mode improves performance by reducing swapping and other side effects of large datasets.
In addition to the functions defined in itertools, the examples in this section use some built-in functions to complete the iteration.
1.1 Merge and Decomposition Iterator
The chain() function takes multiple iterators as parameters and returns an iterator, which generates the contents of all input iterators as if they were from one iterator.
from itertools import * for i in chain([1, 2, 3], ['a', 'b', 'c']): print(i, end=' ') print()
With chain(), multiple sequences can be easily processed without having to construct a large list.
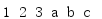
If you do not know in advance all the iterators to be combined (iterable objects), or if you need to compute using a lazy method, you can use chain.from_iterable() to construct this chain.(
from itertools import * def make_iterables_to_chain(): yield [1, 2, 3] yield ['a', 'b', 'c'] for i in chain.from_iterable(make_iterables_to_chain()): print(i, end=' ') print()
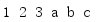
The built-in function zip() returns an iterator that combines elements of multiple iterators into a tuple.(
for i in zip([1, 2, 3], ['a', 'b', 'c']): print(i)
Like other functions in this module, the return value is an iterative object that generates one value at a time.
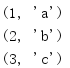
zip() stops when the first input iterator is processed.To process all inputs (even if the number of values generated by the iterator is different), use zip_longest().
from itertools import * r1 = range(3) r2 = range(2) print('zip stops early:') print(list(zip(r1, r2))) r1 = range(3) r2 = range(2) print('\nzip_longest processes all of the values:') print(list(zip_longest(r1, r2)))
By default, zip_longest() replaces all missing values with None.You can use a different replacement value with the fillvalue parameter.

The islice() function returns an iterator that returns selected elements from the input iterator by index.
from itertools import * print('Stop at 5:') for i in islice(range(100), 5): print(i, end=' ') print('\n') print('Start at 5, Stop at 10:') for i in islice(range(100), 5, 10): print(i, end=' ') print('\n') print('By tens to 100:') for i in islice(range(100), 0, 100, 10): print(i, end=' ') print('\n')
islice() has the same slice operator parameters as the list, including start, stop, and step.The start and step parameters are optional.

The tee() function returns multiple independent iterators (default is 2) based on an original input iterator.
from itertools import * r = islice(count(), 5) i1, i2 = tee(r) print('i1:', list(i1)) print('i2:', list(i2))
Tee() is semantically similar to UNIX tee tools in that it repeats values read from the input and writes them to a named file and to standard output.The iterator returned by tee() can be used to provide the same dataset for multiple algorithms that are processed in parallel.
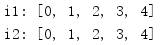
The new iterator created by tee() shares its input iterator, so once a new iterator is created, the original iterator should no longer be used.
from itertools import * r = islice(count(), 5) i1, i2 = tee(r) print('r:', end=' ') for i in r: print(i, end=' ') if i > 1: break print() print('i1:', list(i1)) print('i2:', list(i2))
If some values of the original input iterator are consumed, the new iterator will not regenerate them.

1.2 Convert Input
The built-in map() function returns an iterator that calls a function on the value in the input iterator and returns the result.The map() function stops when all the elements in any input iterator are consumed.
def times_two(x): return 2 * x def multiply(x, y): return (x, y, x * y) print('Doubles:') for i in map(times_two, range(5)): print(i) print('\nMultiples:') r1 = range(5) r2 = range(5, 10) for i in map(multiply, r1, r2): print('{:d} * {:d} = {:d}'.format(*i)) print('\nStopping:') r1 = range(5) r2 = range(2) for i in map(multiply, r1, r2): print(i)
In the first example, the lambda function multiplies the input value by two.In the second example, the lambda function multiplies two parameters from different iterators and returns a tuple containing the original parameter and the calculated value.The third example stops after generating two tuples because the second interval has been processed.

The starmap() function is similar to map(), but does not consist of multiple iterators forming a tuple; it uses * syntax to decompose elements in an iterator as parameters to the mapping function.
from itertools import * values = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9)] for i in starmap(lambda x, y: (x, y, x * y), values): print('{} * {} = {}'.format(*i))
The map() mapping function is named f(i1,i2), and the mapping function passed in to starmap() is named f(*i).
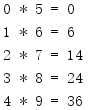
1.3 Generate new values
The count() function returns an iterator that generates an infinite number of consecutive integers.The first number can be passed in as a parameter (default is 0).There is no upper bound parameter here (see the built-in range(), which gives you more control over the result set).(
from itertools import * for i in zip(count(1), ['a', 'b', 'c']): print(i)
This example stops because the list parameters are fully consumed.
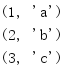
The start position and step parameters of count() can be any numeric value that can be added.(
import fractions from itertools import * start = fractions.Fraction(1, 3) step = fractions.Fraction(1, 3) for i in zip(count(start, step), ['a', 'b', 'c']): print('{}: {}'.format(*i))
In this example, the start point and step are Fraction objects from the fraction module.

The cycle() function returns an iterator that repeats the contents of a given parameter indefinitely.Since you must remember all the contents of the input iterator, if it is long, it may consume a lot of memory.(
from itertools import * for i in zip(range(7), cycle(['a', 'b', 'c'])): print(i)
This example uses a counter variable that aborts the loop after several cycles.
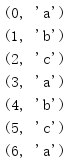
The repeat() function returns an iterator that generates the same value each time it is accessed.(
from itertools import * for i in repeat('over-and-over', 5): print(i)
The iterator returned by repeat() always returns data unless an optional time parameter is provided to limit the number of times.

If you want to include values from other iterators as well as invariant values, you can use a combination of repeat() and zip() or map().
from itertools import * for i, s in zip(count(), repeat('over-and-over', 5)): print(i, s)
This example combines a counter value with a constant returned by repeat().

The following example uses map() to multiply a number between 0 and 4 by 2.
from itertools import * for i in map(lambda x, y: (x, y, x * y), repeat(2), range(5)): print('{:d} * {:d} = {:d}'.format(*i))
The repeat() iterator does not need to be explicitly restricted because map() stops processing at the end of any input iterator and range() returns only five elements.
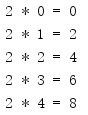
1.4 Filtration
The dropwhile() function returns an iterator that generates the elements of the input iterator after the condition first becomes false.(
from itertools import * def should_drop(x): print('Testing:', x) return x < 1 for i in dropwhile(should_drop, [-1, 0, 1, 2, -2]): print('Yielding:', i)
dropwhile() does not filter every element of input.After the first condition is false, all remaining elements of the input iterator are returned.

taskwhile() is the opposite of dropwhile().It also returns an iterator that returns elements in the input iterator that guarantee the test condition is true.(
from itertools import * def should_take(x): print('Testing:', x) return x < 2 for i in takewhile(should_take, [-1, 0, 1, 2, -2]): print('Yielding:', i)
Once should_take() returns false, takewhile() stops processing the input.

The built-in function filter() returns an iterator that contains only the elements for which the test condition returns true.
from itertools import * def check_item(x): print('Testing:', x) return x < 1 for i in filter(check_item, [-1, 0, 1, 2, -2]): print('Yielding:', i)
Unlike dropwhile() and takewhile(), filter() tests each element before returning.

filterfalse() returns an iterator that contains only the elements that correspond when the test condition returns false.
from itertools import * def check_item(x): print('Testing:', x) return x < 1 for i in filterfalse(check_item, [-1, 0, 1, 2, -2]): print('Yielding:', i)
The test expression in check_item() is the same as before, so in this example using filterfalse(), the result is the opposite of the previous one.

compress() provides another way to filter iterative object content.Instead of calling a function, use the values in another Iterable object to indicate when a value is accepted and when a value is abused.(
from itertools import * every_third = cycle([False, False, True]) data = range(1, 10) for i in compress(data, every_third): print(i, end=' ') print()
The first parameter is the data iterator to process.The second parameter is a selector iterator that generates a Boolean value indicating which elements are taken from the data input (the true value indicates that this value will be generated; the false value indicates that this value will be ignored).
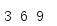
1.5 Data Grouping
The groupby() function returns an iterator that generates a set of values organized by a common key.The following example shows how to group related values based on an attribute.
import functools from itertools import * import operator import pprint @functools.total_ordering class Point: def __init__(self, x, y): self.x = x self.y = y def __repr__(self): return '({}, {})'.format(self.x, self.y) def __eq__(self, other): return (self.x, self.y) == (other.x, other.y) def __gt__(self, other): return (self.x, self.y) > (other.x, other.y) # Create a dataset of Point instances data = list(map(Point, cycle(islice(count(), 3)), islice(count(), 7))) print('Data:') pprint.pprint(data, width=35) print() # Try to group the unsorted data based on X values print('Grouped, unsorted:') for k, g in groupby(data, operator.attrgetter('x')): print(k, list(g)) print() # Sort the data data.sort() print('Sorted:') pprint.pprint(data, width=35) print() # Group the sorted data based on X values print('Grouped, sorted:') for k, g in groupby(data, operator.attrgetter('x')): print(k, list(g)) print()
The input sequence is sorted by key values to ensure the expected grouping.

1.6 Merge Inputs
The accumulate() function handles the input iterator, passes the nth and n+1 elements to a function, and generates a return value instead of an input.The default function of merging two values adds the two values, so accumulate() can be used to generate the sum of a sequence of numeric inputs.
from itertools import * print(list(accumulate(range(5)))) print(list(accumulate('abcde')))
When used for a sequence of non-integer values, the result depends on what the two elements "add up" means.The second example in this script shows that when accumulate() receives a string input, each corresponding will be a prefix to the string and will grow in length.
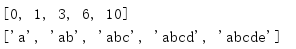
accumulate() can be combined with any function that takes two input values to produce different results.
from itertools import * def f(a, b): print(a, b) return b + a + b print(list(accumulate('abcde', f)))
This example combines string values in a special way and produces a series of (meaningless) palindromes.Each time f() is called, it prints the input value passed in by accumulate().

Nested for loops that iterate over multiple sequences can often be replaced with product(), which generates an iterator whose value is the Cartesian product of the set of input values.(
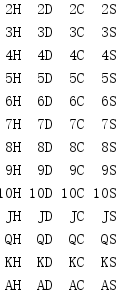
from itertools import * import pprint FACE_CARDS = ('J', 'Q', 'K', 'A') SUITS = ('H', 'D', 'C', 'S') DECK = list( product( chain(range(2, 11), FACE_CARDS), SUITS, ) ) for card in DECK: print('{:>2}{}'.format(*card), end=' ') if card[1] == SUITS[-1]: print()
The value generated by product() is a tuple with members taken from each iterator passed in as a parameter in the order in which it was passed in.The first tuple returned contains the first value of each iterator.The last iterator passed into product() is processed first, then the second to last iterator, and so on.The result is a return value in the order of the first iterator, the next iterator, and so on.
In this example, poker cards are first sorted by face size and then by suit.
To change the order of these poker cards, you need to change the order of the parameters passed into product().
from itertools import * FACE_CARDS = ('J', 'Q', 'K', 'A') SUITS = ('H', 'D', 'C', 'S') DECK = list( product( SUITS, chain(range(2, 11), FACE_CARDS), ) ) for card in DECK: print('{:>2}{}'.format(card[1], card[0]), end=' ') if card[1] == FACE_CARDS[-1]: print()
The print cycle in this example looks for an A instead of a spade, and then adds a line break output line display.

To calculate the product of a sequence to itself, open source specifies how many times the input is repeated.(
from itertools import * def show(iterable): for i, item in enumerate(iterable, 1): print(item, end=' ') if (i % 3) == 0: print() print() print('Repeat 2:\n') show(list(product(range(3), repeat=2))) print('Repeat 3:\n') show(list(product(range(3), repeat=3)))
Since repeating an iterator is like passing the same iterator in multiple times, each tuple produced by product() contains as many elements as the repeating counter.

The permutations() function generates elements from the input iterator that are grouped in an arrangement of a given length.By default, it generates a complete set of all permutations.
from itertools import * def show(iterable): first = None for i, item in enumerate(iterable, 1): if first != item[0]: if first is not None: print() first = item[0] print(''.join(item), end=' ') print() print('All permutations:\n') show(permutations('abcd')) print('\nPairs:\n') show(permutations('abcd', r=2))
The r parameter can be used to limit the length and number of each permutation returned.

To limit values to unique combinations rather than permutations, combinations() can be used.As long as the input members are unique, the output will not contain any duplicate values.
from itertools import * def show(iterable): first = None for i, item in enumerate(iterable, 1): if first != item[0]: if first is not None: print() first = item[0] print(''.join(item), end=' ') print() print('Unique pairs:\n') show(combinations('abcd', r=2))
Unlike permutations, the r parameter of combinations() is required.

Although combinations() do not repeat a single input element, there may be times when you need to consider including duplicate combinations of elements.In this case, you can use combinations_with_replacement().
from itertools import * def show(iterable): first = None for i, item in enumerate(iterable, 1): if first != item[0]: if first is not None: print() first = item[0] print(''.join(item), end=' ') print() print('Unique pairs:\n') show(combinations_with_replacement('abcd', r=2))
In this output, each input element is paired with itself and all other members of the input sequence.
