1. Collection container data type
The collections module contains container data types other than the built-in types list, dict, and tuple.
1.1 ChainMap searches multiple dictionaries
The ChainMap class manages a sequence of dictionaries and searches for values associated with keys in the order in which they appear. ChainMap provides a lot of "context" containers, because you can think of it as a stack, which changes when the stack grows and is discarded when the stack shrinks.
1.1.1 access values
ChainMap supports the same api as regular dictionaries to access existing values.
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print('Individual Values') print('a = {}'.format(m['a'])) print('b = {}'.format(m['b'])) print('c = {}'.format(m['c'])) print() print('Keys = {}'.format(list(m.keys()))) print('Values = {}'.format(list(m.values()))) print() print('Items:') for k, v in m.items(): print('{} = {}'.format(k, v)) print() print('"d" in m: {}'.format(('d' in m)))
The submaps are searched in the order they are passed to the constructor, so the values reported by the corresponding key 'c' come from the a dictionary.

1.1.2 rearrangement
ChainMap stores the list of maps to search in its maps attribute. The list is variable, so you can add new mappings directly, or change the order of elements to control the lookup and update behavior.
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print(m.maps) print('c = {}\n'.format(m['c'])) # reverse the list m.maps = list(reversed(m.maps)) print(m.maps) print('c = {}'.format(m['c']))
When you want to map a list reversal, the value associated with it changes' c '.
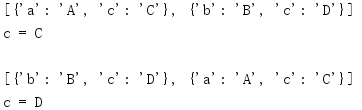
1.1.3 update values
ChainMap does not cache values in submaps. Therefore, if their contents are modified, they will be reflected in the results when accessing ChainMap.
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print('Before: {}'.format(m['c'])) a['c'] = 'E' print('After : {}'.format(m['c']))
Changing the value associated with an existing key is the same as adding a new element.

You can also set values directly through ChainMap, but only the first map in the chain will be modified.
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print('Before:', m) m['c'] = 'E' print('After :', m) print('a:', a)
When m is used to store new values, the a map is updated.

ChainMap provides a convenient way to create a new instance at the front of the maps list with an additional map, so that you can easily avoid modifying the existing underlying data structure.
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m1 = collections.ChainMap(a, b) m2 = m1.new_child() print('m1 before:', m1) print('m2 before:', m2) m2['c'] = 'E' print('m1 after:', m1) print('m2 after:', m2)
Based on this stack behavior, ChainMap instances can be easily used as templates or application contexts. Specifically, it's easy to add or update values in one iteration and then discard those changes in the next.
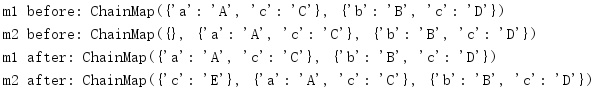
If the new context is known or built ahead of time, you can also pass a map to new_child().
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} c = {'c': 'E'} m1 = collections.ChainMap(a, b) m2 = m1.new_child(c) print('m1["c"] = {}'.format(m1['c'])) print('m2["c"] = {}'.format(m2['c']))
This is equivalent to:
m2 = collections.ChainMap(c, *m1.maps)
It also produces:
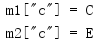
1.2 Counter statistics hash objects
Counter is a container that tracks the number of times an equivalent value increases. This class can be used to implement algorithms commonly used in other languages, such as bag or multiset data structures.
1.2.1 initialization
Counter supports three forms of initialization. When calling counter's constructor, you can provide a sequence of elements or a dictionary containing keys and counts, and you can use key parameters to map string names to counts.
import collections print(collections.Counter(['a', 'b', 'c', 'a', 'b', 'b'])) print(collections.Counter({'a': 2, 'b': 3, 'c': 1})) print(collections.Counter(a=2, b=3, c=1))
The initialization results of these three forms are the same.

If you don't provide any parameters, you can construct an empty Counter and then populate it with the update() method.
import collections c = collections.Counter() print('Initial :', c) c.update('abcdaab') print('Sequence:', c) c.update({'a': 1, 'd': 5}) print('Dict :', c)
The count value will only increase according to the new data, and the replacement data will not change the count. In the following example, the count of a will increase from 3 to 4.
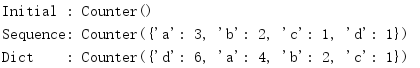
1.2.2 access count
Once Counter is populated, you can use the dictionary API to get its value.
import collections c = collections.Counter('abcdaab') for letter in 'abcde': print('{} : {}'.format(letter, c[letter]))
Counter does not generate KeyError for unknown elements. If a value (E in this cas e) is not found in the input, its count is 0

The elements() method returns an iterator that will generate all elements known to Counter.
import collections c = collections.Counter('extremely') c['z'] = 0 print(c) print(list(c.elements()))
The order of the elements cannot be guaranteed to be the same. In addition, elements whose count is less than or equal to 0 are not included.
With most_common(), you can generate a sequence of n most commonly encountered input values and their corresponding counts.
import collections c = collections.Counter() with open('test.txt', 'rt') as f: for line in f: c.update(line.rstrip().lower()) print('Most common:') for letter, count in c.most_common(3): print('{}: {:>7}'.format(letter, count))
This example counts the letters in all the words in the system dictionary to generate a frequency distribution, and then prints the three most common letters. If you do not supply parameters to most_common(), a list of all elements is generated, sorted by frequency.
1.2.3 arithmetic operation
Counter instance supports arithmetic and collection operations to complete the aggregation of results. The following ex amp le shows the standard operators for creating a new counter instance, but also supports in place operators such as + =, - =, & =, and| =.
import collections c1 = collections.Counter(['a', 'b', 'c', 'a', 'b', 'b']) c2 = collections.Counter('alphabet') print('C1:', c1) print('C2:', c2) print('\nCombined counts:') print(c1 + c2) print('\nSubtraction:') print(c1 - c2) print('\nIntersection (taking positive minimums):') print(c1 & c2) print('\nUnion (taking maximums):') print(c1 | c2)
Every time a new Counter is generated by an operation, elements with a count of 0 or negative are deleted. The count of a is the same in c1 and c2, so its count is 0 after subtraction.

1.3 defaultdict missing key returns a default value
The standard dictionary includes a setdefault() method, which is used to get a value. If the value does not exist, a default value is established. In contrast, when initializing a container, defaultdict causes the caller to specify a default value in advance.
import collections def default_factory(): return 'default value' d = collections.defaultdict(default_factory, foo='bar') print('d:', d) print('foo =>', d['foo']) print('bar =>', d['bar'])
As long as all keys have the same default value, this method can be used well. This method is particularly useful if the default value is a type used to aggregate or accumulate values, such as list, set, or int. The standard library documentation provides many examples of using defaultdict in this way.

1.4 deque two terminal queue
Double ended queues or deque support adding and removing elements from either end. Two more commonly used structures (stack and queue) are the degenerate form of two terminal queue, whose input and output are limited to one end.
import collections d = collections.deque('abcdefg') print('Deque:', d) print('Length:', len(d)) print('Left end:', d[0]) print('Right end:', d[-1]) d.remove('c') print('remove(c):', d)
Since deque is a sequence container, it also supports some operations of list, such as checking the contents with \\\\\\\\\\.
1.4.1 fill
deque can be populated from any end, which is known in Python implementations as the "left" and "right".
import collections # Add to the right d1 = collections.deque() d1.extend('abcdefg') print('extend :', d1) d1.append('h') print('append :', d1) # Add to the left d2 = collections.deque() d2.extendleft(range(6)) print('extendleft:', d2) d2.appendleft(6) print('appendleft:', d2)
The extendleft() function iterates over its input, doing the same for each element as appendleft(). The end result is that deque will contain the input sequence in reverse order.
1.4.2 elimination
Similarly, deque elements can be eliminated from either or both ends, depending on the algorithm applied.
import collections print('From the right:') d = collections.deque('abcdefg') while True: try: print(d.pop(), end='') except IndexError: break print() print('\nFrom the left:') d = collections.deque(range(6)) while True: try: print(d.popleft(), end='') except IndexError: break print()
Use pop() to remove an element from the right end of deque, and use pop left () to take an element from the left end.

Because the two terminal queue is thread safe, it can even eliminate the contents of the queue from both ends in different threads at the same time.
import collections import threading import time candle = collections.deque(range(5)) def burn(direction, nextSource): while True: try: next = nextSource() except IndexError: break else: print('{:>8}: {}'.format(direction, next)) time.sleep(0.1) print('{:>8} done'.format(direction)) return left = threading.Thread(target=burn, args=('Left', candle.popleft)) right = threading.Thread(target=burn, args=('Right', candle.pop)) left.start() right.start() left.join() right.join()
The thread in this example alternates between the two ends, removing the element until the deque is empty.

1.4.3 rotation
Another useful aspect of deque is the ability to rotate in any direction, skipping elements.
import collections d = collections.deque(range(10)) print('Normal :', d) d = collections.deque(range(10)) d.rotate(2) print('Right rotation:', d) d = collections.deque(range(10)) d.rotate(-2) print('Left rotation :', d)
Rotating deque to the right (using a positive rotation value) takes elements from the right and moves them to the left. Rotate left (with a negative value) moves the element from the left to the right. You can visualize the elements in deque as engraved on the dial, which is very helpful for understanding the two terminal queue.

1.4.4 limit queue size
When configuring a deque instance, you can specify a maximum length so that it does not exceed this size. When the queue reaches the specified length, the existing elements are deleted as the new elements increase. This behavior is useful if you are looking for the last n elements in a stream of uncertain length.
import collections import random # Set the random seed so we see the same output each time # the script is run. random.seed(1) d1 = collections.deque(maxlen=3) d2 = collections.deque(maxlen=3) for i in range(5): n = random.randint(0, 100) print('n =', n) d1.append(n) d2.appendleft(n) print('D1:', d1) print('D2:', d2)
The queue length remains the same regardless of which end the element is added to.

1.5 named tuple subclass with named field
The standard tuple uses a numeric index to access its members.
bob = ('Bob', 30, 'male') print('Representation:', bob) jane = ('Jane', 29, 'female') print('\nField by index:', jane[0]) print('\nFields by index:') for p in [bob, jane]: print('{} is a {} year old {}'.format(*p))
For simple use, tuple is a convenient container.

On the other hand, when using tuple, you need to remember which index to use for each value, which may lead to errors, especially when tuple has a large number of fields, and the constructor is far away from the place where tuple is used. namedtuple specifies a name for each member in addition to a numeric index.
1.5.1 definition
As with regular tuples, namedtuple instances are equally efficient in memory usage because they do not have a dictionary for each instance.
Each namedtuple is represented by its own class, which is created using the number of namedtuple() factories. The parameter is the new class name and a string containing the element name.
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print('\nRepresentation:', bob) jane = Person(name='Jane', age=29) print('\nField by name:', jane.name) print('\nFields by index:') for p in [bob, jane]: print('{} is {} years old'.format(*p))
As shown in this example, in addition to using the location index of a standard tuple, you can also use obj. Attr to access the fields of namedtuple by name.

Like a regular tuple, a named tuple is also immutable. This restriction allows tuple instances to have consistent hash values, which allows them to be used as keys in dictionaries and included in collections.
import collections Person = collections.namedtuple('Person', 'name age') pat = Person(name='Pat', age=12) print('\nRepresentation:', pat) pat.age = 21
If you try to change a value by naming an attribute, this results in an AttributeError.

1.5.2 illegal field name
If the field name is duplicate or conflicts with the Python keyword, it is an illegal field name.
import collections try: collections.namedtuple('Person', 'name class age') except ValueError as err: print(err) try: collections.namedtuple('Person', 'name age age') except ValueError as err: print(err)
When resolving field names, illegal values cause ValueError exceptions.

If you want to create a namedtuple based on a value outside of program control (for example, to represent a record row returned by a database query without knowing the database mode in advance), in this case, you should set the rename option to True to rename the illegal field.
import collections with_class = collections.namedtuple( 'Person', 'name class age', rename=True) print(with_class._fields) two_ages = collections.namedtuple( 'Person', 'name age age', rename=True) print(two_ages._fields)
The new name of the renamed field depends on its index in the tuple, so the field named class changes to_1, and the duplicate age field changes to_2.
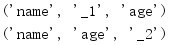
1.5.3 specifying attributes
Namedtuple provides many useful properties and methods to handle subclasses and instances. All of these built-in property names have an underscore prefix, which, by convention, indicates a private property in most Python programs. However, for namedtuple, the prefix is used to prevent the name from colliding with the property name provided by the user.
The field name passed in to define the new class is saved in the fields property.
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print('Representation:', bob) print('Fields:', bob._fields)
Although the parameter is a space delimited string, the stored value is a sequence of names.
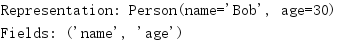
The namedtuple instance can be converted to an OrderedDict instance using \.
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print('Representation:', bob) print('As Dictionary:', bob._asdict())
The key of OrderedDict is in the same order as the field of the corresponding namedtuple.
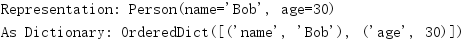
_The replace() method builds a new instance in which the values of some fields are replaced.
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print('\nBefore:', bob) bob2 = bob._replace(name='Robert') print('After:', bob2) print('Same?:', bob is bob2)
Although it seems that the existing object will be modified by name, since the namedtuple instance is immutable, in fact, this method will return a new object.

1.6 OrderedDict remember the order in which keys are added to the dictionary
OrderedDict is a dictionary subclass that remembers the order in which its contents increase.
import collections print('Regular dictionary:') d = {} d['a'] = 'A' d['b'] = 'B' d['c'] = 'C' for k, v in d.items(): print(k, v) print('\nOrderedDict:') d = collections.OrderedDict() d['a'] = 'A' d['b'] = 'B' d['c'] = 'C' for k, v in d.items(): print(k, v)
Conventional dict does not track the insertion order. During iterative processing, values will be generated in order according to how to store keys in the hash table, while the storage of keys in the hash table will be affected by a random value to reduce conflicts. In OrderedDict, instead, it remembers the order in which elements are inserted and uses that order when creating iterators.

1.6.1 equality
A regular dict looks at its contents when it checks for equality. OrderedDict also considers the order in which elements are added.
import collections print('dict :', end=' ') d1 = {} d1['a'] = 'A' d1['b'] = 'B' d1['c'] = 'C' d2 = {} d2['c'] = 'C' d2['b'] = 'B' d2['a'] = 'A' print(d1 == d2) print('OrderedDict:', end=' ') d1 = collections.OrderedDict() d1['a'] = 'A' d1['b'] = 'B' d1['c'] = 'C' d2 = collections.OrderedDict() d2['c'] = 'C' d2['b'] = 'B' d2['a'] = 'A' print(d1 == d2)
In this case, because two ordered dictionaries are created by values in different order, the two ordered dictionaries are considered different.

1.6.2 rearrangement
In OrderedDict, you can change the order of keys by moving them to the beginning or end of the sequence.
import collections d = collections.OrderedDict( [('a', 'A'), ('b', 'B'), ('c', 'C')] ) print('Before:') for k, v in d.items(): print(k, v) d.move_to_end('b') print('\nmove_to_end():') for k, v in d.items(): print(k, v) d.move_to_end('b', last=False) print('\nmove_to_end(last=False):') for k, v in d.items(): print(k, v)
The last parameter tells move_to_end() to move the element to the last (True) or first (false) element of the key sequence.

1.7 abstract base class of collections.abc container
The collections.abc module contains abstract base classes that define API s for Python's built-in container data structures and the container data structures defined by the collections module.
| class | Base class | API uses |
|---|---|---|
| Container | Basic container properties, such as the in operator | |
| Hashable | Added hash support to provide hash value for container instance | |
| Iterable | You can create an iterator on the contents of the container | |
| Iterator | Iterable | This is an iterator on the contents of the container |
| Generator | Iterator | Extended Generator Protocol for iterators |
| Sized | How to add containers of your own size | |
| Callable | Containers that can be called as functions | |
| Sequence | Sized, Iterable, Container | Support for getting individual elements and iterating and changing element order |
| MutableSequence | Sequence | Support adding and deleting elements after creating an instance |
| ByteString | Sequence | API for merging bytes and byte array |
| Set | Sized, Iterable, Container | Supports collection operations such as intersection and union |
| MutableSet | Set | Added method of managing collection content after creating collection |
| Mapping | Sized, Iterable, Container | Define the read-only API used by dict |
| MutableMapping | Mapping | Define how to manage the content of a map after it is created |
| MappingView | Sized | Define how to access mapped content from iterators |
| ItemsView | MappingView, Set | Part of the view API |
| KeysView | MappingView, Set | Part of the view API |
| ValuesView | MappingView | Part of the view API |
| Awaitable | API for objects available in await expressions, such as coroutines | |
| Coroutine | Awaitable | The API of classes implementing the protocol |
| AsyncIterable | API of iterable compatible with async for | |
| AsyncIterator | AsyncIterable | API of asynchronous iterator |
In addition to clearly defining APIs for different containers, these abstract base classes can also test whether an object supports an API with isinstance() before calling an object. Some classes also provide method implementations that can be used as "min in" to construct custom container types without having to implement each method from scratch.