I. Write in front
In Last blog As mentioned in the article, Celery can be used to speed up the crawling of web crawlers, which contains a large number of network requests. So, this blog will specifically talk about how to use Celery to speed up our crawlers!
II. Knowledge Supplement
1.class celery.group
The group class represents the creation of a set of tasks to be executed in parallel, but a set of tasks is lazy, so you need to run and evaluate them. To understand this class, you can view the document, or directly Ctrl + left-click in Pycharm to view the source code, as follows:
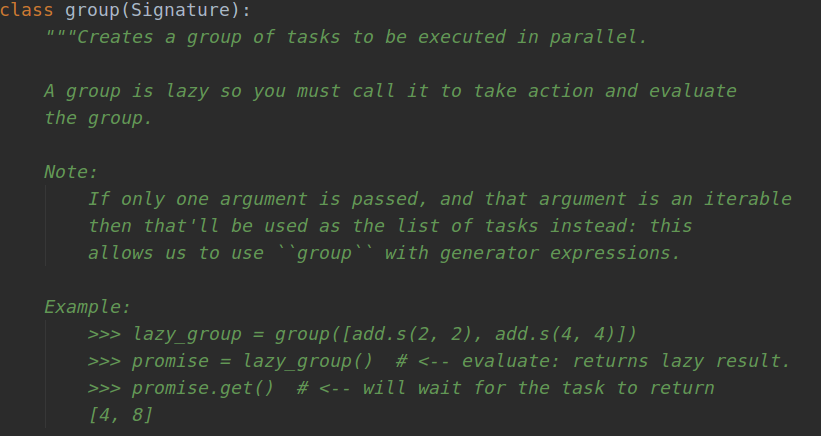
Of course, it's not enough to look at the source code directly, so it's better to start by yourself. So first create a test.py with the following code:
1 from celery import Celery 2 3 4 app = Celery("test", broker="redis://127.0.0.1:6379", backend="redis://127.0.0.1:6379") 5 6 7 @app.task 8 def add(x, y): 9 return x + y 10 11 12 if __name__ == '__main__': 13 app.start()
Then run the Celery server and create a test_run.py for testing under the directory where test.py resides, with the following code:
1 from celery import group 2 from .test import add 3 4 5 lazy_group = group(add.s(2, 2), add.s(4, 4)) 6 print(type(lazy_group)) 7 result = lazy_group() 8 print(result) 9 print(type(result)) 10 print(result.get())
Running test_run.py in Pycharm yields the following results:
<class 'celery.canvas.group'>
fe54f453-eb9c-4b24-87e3-a26fab75967f
<class 'celery.result.GroupResult'>
[4, 8]
By looking at the source code, you can see that an iterative object composed of tasks can be passed into the group, so this is a test to modify the above code a little:
1 from celery import group 2 from CelerySpider.test import add 3 4 5 lazy_group = group(add.s(x, y) for x, y in zip([1, 3, 5, 7, 9], [2, 4, 6, 8, 10])) 6 result = lazy_group() 7 print(result) 8 print(result.get())
After running, we got the desired results:
f03387f1-af00-400b-b58a-37901563251d
[3, 7, 11, 15, 19]
2.celer.result.collect()
In Celery, there is a class result, which contains the result and state of the task running, and in this class, there is a collect() method, which can collect the result when the result returns. For the same steps as before, first look at the source code:
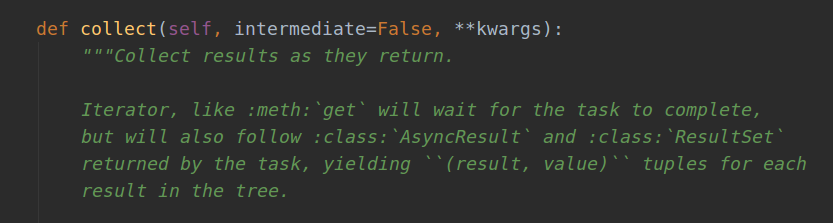
Seeing the source code here is also confusing, so it's better to try to write the code by hand. Create an app.py with the following code:
1 from celery import Celery, group, result 2 3 4 app = Celery("test", broker="redis://127.0.0.1:6379", backend="redis://127.0.0.1:6379") 5 6 7 @app.task(trail=True) 8 def A(how_many): 9 return group(B.s(i) for i in range(how_many))() 10 11 12 @app.task(trail=True) 13 def B(i): 14 return pow2.delay(i) 15 16 17 @app.task(trail=True) 18 def pow2(i): 19 return i ** 2 20 21 22 if __name__ == '__main__': 23 app.start()
You can see that the parameter trail=True has been added to set the task to store the results of the sub-task list run. Although it is the default setting, it is explicitly enabled here. In running the Celery server, enter the app.py peer directory, enter python, and then execute the following code:
>>> from app import A
>>> res = A.delay(10)
>>> [i[1] for i in res.collect() if isinstance(i[1], int)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
III. Specific steps
1. Project structure
The basic documents of this crawler project are as follows:
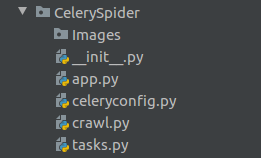
app.py is used to create Celery instances, celeryconfig.py is the configuration file Celery needs to use, tasks.py is the specific task, crawl.py is the crawler script, after opening the Celery server, run this file.
2. Main Code
The first is app.py, which is coded as follows, where the config_from_object() method is used to configure Celery, and the incoming parameter is a module that can be imported:
1 from celery import Celery 2 3 4 app = Celery("spiders", include=["CelerySpider.tasks"]) 5 # Import configuration files 6 app.config_from_object("CelerySpider.celeryconfig") 7 8 9 if __name__ == '__main__': 10 app.start()
The following is the code in tasks.py, which contains the code for sending requests and parsing web pages:
1 import requests 2 from lxml import etree 3 from celery import group 4 from CelerySpider.app import app 5 6 7 headers = { 8 "Cookie": "__cfduid=d5d815918f19b7370d14f80fc93f1f27e1566719058; UM_distinctid=16cc7bba92f7b6-0aac860ea9b9a7-7373e61-144000-16cc7bba930727; CNZZDATA1256911977=1379501843-1566718872-https%253A%252F%252Fwww.baidu.com%252F%7C1566718872; XSRF-TOKEN=eyJpdiI6InJvNVdZM0krZ1wvXC9BQjg3YUk5aGM1Zz09IiwidmFsdWUiOiI5WkI4QU42a0VTQUxKU2ZZelVxK1dFdVFydlVxb3g0NVpicEdkSGtyN0Uya3VkXC9pUkhTd2plVUtUTE5FNWR1aCIsIm1hYyI6Ijg4NjViZTQzNGRhZDcxNTdhMDZlMWM5MzI4NmVkOGZhNmRlNTBlYWM0MzUyODIyOWQ4ZmFhOTUxYjBjMTRmNDMifQ%3D%3D; doutula_session=eyJpdiI6IjFoK25pTG50azEwOXlZbmpWZGtacnc9PSIsInZhbHVlIjoiVGY2MU5Ob2pocnJsNVBLZUNMTWw5OVpjT0J6REJmOGVpSkZwNFlUZVwvd0tsMnZsaiszWEpTbEdyZFZ6cW9UR1QiLCJtYWMiOiIxZGQzNTJlNzBmYWE0MmQzMzQ0YzUzYmYwYmMyOWY3YzkxZjJlZTllNDdiZTlkODA2YmQ3YWRjNGRmZDgzYzNmIn0%3D", 9 "Referer": "https://www.doutula.com/article/list/?page=1", 10 "UserAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36" 11 } 12 13 14 @app.task(trail=True) 15 def main(urls): 16 # Principal function 17 return group(call.s(url) for url in urls)() 18 19 20 @app.task(trail=True) 21 def call(url): 22 # Send requests 23 try: 24 res = requests.get(url, headers=headers) 25 parse.delay(res.text) 26 except Exception as e: 27 print(e) 28 29 30 @app.task(trail=True) 31 def parse(html): 32 # Analysis of Web Pages 33 et = etree.HTML(html) 34 href_list = et.xpath('//*[@id="home"]/div/div[2]/a/@href') 35 result = [] 36 for href in href_list: 37 href_res = requests.get(href, headers=headers) 38 href_et = etree.HTML(href_res.text) 39 src_list = href_et.xpath('//*[@class="artile_des"]/table/tbody/tr/td/a/img/@src') 40 result.extend(src_list) 41 return result
Finally, the code in crawl.py:
1 import time 2 from CelerySpider.tasks import main 3 4 5 start_time = time.time() 6 7 8 url_list = ["https://www.doutula.com/article/list/?page={}".format(i) for i in range(1, 31)] 9 res = main.delay(url_list) 10 all_src = [] 11 for i in res.collect(): 12 if isinstance(i[1], list) and isinstance(i[1][0], str): 13 all_src.extend(i[1]) 14 15 print("Src count: ", len(all_src)) 16 17 18 end_time = time.time() 19 print("Cost time: ", end_time - start_time)
The crawled website is a Emotional Pack Website url_list means the url to crawl. Here I choose to crawl 30 pages to test. all_src is used to store the resource links of the emoticons. The links to be crawled are extracted by the collect() method, and then the emoticons are downloaded. Finally, the number of downloaded pictures and the time consumed by the whole program are printed out.
IV. Operational results
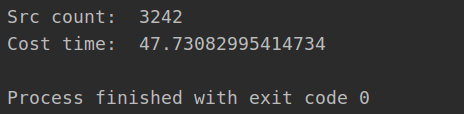
When you run the Celery service and then run the crawl.py file, you will see the following information printed out:
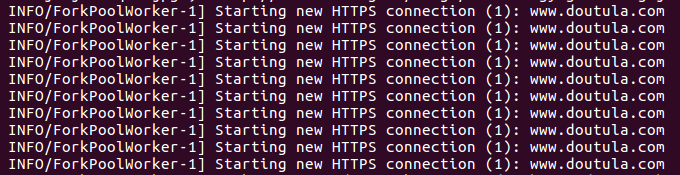
When the whole crawler runs out, it prints out the time spent:
Complete code has been uploaded to GitHub!