1, On regular expression
1. Definition: it is a special character sequence, which can help to detect whether a string matches the character sequence we set.
2. Function: it can quickly retrieve text and replace text.
3. scenario:
1. Check whether a string of numbers is a telephone number
2. Check whether a string conforms to e-mail format
3. Replace the word specified in one text with another
4. example:
See if the incoming string still has Python
(1)
a = 'C|C++|Java|Python'
print(a.index('Python') > -1)
//perhaps
print('Python' in a)
(2)
Handle with regular expressions:
import re a = 'C|C++|Java|Python' r = re.findall('Python',a) if len(r) > 0: print('String contains Python') else: print('No')
5. grammar
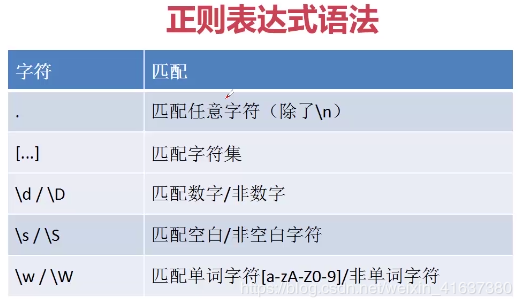


2, Metacharacters and common characters
1. 'Python' common character, '\ d' metacharacter. Regular expressions are composed of a series of common characters and metacharacters.
2. example:
Extract all numbers in the string: \ d: indicates all numbers
import re a = 'C2C++4Java7Python6' r = re.findall('\d',a) print(r) #Result: ['2', '4', '7', '6']
Extract all non numbers in the string:
import re a = 'C2C++4Java7Python6' r = re.findall('\D',a) #\D Non numeric print(r)
3, Character set
Example:
1. A word whose middle character is c or f: []: character set, or relation
Common character delimitation, to determine a small segment. In this example, a[cf]c, a and c outside the brackets are common character bounds
import re s = 'abc,acc,adc,aec,afc,ahc' r = re.findall('a[cf]c',s) print(r) #Result: ['acc', 'afc']
2. A word whose middle character is not c or f: ^: reverse operation
import re s = 'abc,acc,adc,aec,afc,ahc' r = re.findall('a[^cf]c',s) print(r) #Result: ['abc', 'adc', 'aec', 'ahc']
3. Use character order to omit characters, match c,d,e,f: -: omit intermediate characters
import re s = 'abc,acc,adc,aec,afc,ahc' r = re.findall('a[c-f]c',s) print(r) #Result: ['acc','adc','aec','afc']
4, General character set
1.\d can be represented by [0-9]:
import re a = 'python1111java678php' r = re.findall('[0-9]',a) print(r)
2.\w match all numbers and characters:
\w can only match word characters, i.e., [A-Za-z0-9]
\W only matches non word characters, such as spaces, &, \ n, r, t, etc
import re a = 'python1111&java___678php' r = re.findall('\w',a) print(r
Result:

3.\s for white space characters: space, n, r, etc
\ S for non white space characters
mport re a = 'python1111&_java678 \nph\rp' r = re.findall('\s',a) print(r) #[' ', ' ', '\n', '\r']
Common summary character set: \ d \D \w \W \s \S
. matches all characters except line breaks \ n
5, Quantifier
1. Match three letter words:
import re a = 'python1111 java678php' r = re.findall('[a-z]{3}',a) print(r) #['pyt', 'hon', 'jav', 'php']
2. Match complete words:
import re a = 'python1111 java678php' r = re.findall('[a-z]{3,6}',a) print(r) #['python', 'java', 'php']
Use the quantifier {quantity} to repeat many times
6, Greed and non greed
There are two kinds of quantifiers: greedy and non greedy. Generally speaking, Python tends to match greedily.
1. {quantity}? Become non greedy
2. example:
import re a = 'python1111 java678php' r = re.findall('[a-z]{3,6}?',a) print(r) #['pyt', 'hon', 'jav', 'php']
7, Match 0 times 1 times or infinite times
1. Use * to match the characters before it 0 times or infinite times:
import re a = 'pytho0python1pythonn2' r = re.findall('python*',a) print(r) #['pytho', 'python', 'pythonn']
2. Match once or infinite times with +:
import re a = 'pytho0python1pythonn2' r = re.findall('python+',a) print(r) #['python', 'pythonn']
3. use? Match 0 or once:
import re a = 'pytho0python1pythonn2' r = re.findall('python?',a) print(r) #['pytho', 'python', 'python']
Note: the extra n will be removed, because it will be satisfied when reading python
Use? To repeat the operation.
The {3,6} in greed and non greed? The usage of question mark is different from that of python.
8, Boundary matching
Example:
Whether the digits of QQ number conform to 4-8 digits:
import re qq = '10000004531' r = re.findall('^\d{4,8}$',qq) print(r) #[]
^$composition boundary match
^Match from beginning of string
$matches from end of string
000 $the last three digits are 000
^000, the first three are 000
Nine. Group
1. example:
Whether the python string repeats three times:
import re a = 'pythonpythonpythonpythonpython' r = re.findall('(python){3}',a) print(r)
2.
A bracket corresponds to a group.
Character yes or relation in []
The characters in () are and related
10, Match pattern parameters
1. example:
Ignore case:
import re a = 'pythonC#\nJavaPHP' r = re.findall('c#.{1}',a,re.I|re.S) print(r) #['c#\n']
2.
re.I: ignore case, use | between multiple modes, where | is and
re.S: match any character including \ n
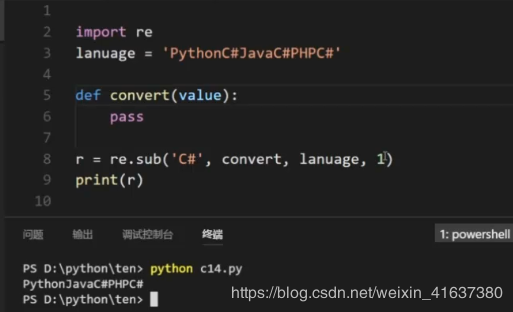
11, re.sub regular replacement

0: replace all matched ones, 1: only the first matched ones are replaced
1. example:
(1) Find and replace:
import re a = 'PythonC#JavaPHP' r = re.sub('C#','GO',a) print(r) #PythonGOJavaPHP
import re a = 'PythonC#\nJavaPHP' r = re.sub('C#','GO',a,0) #0: Take all C#Replace with GO, 1: only the first matched one is replaced with GO print(r) #PythonGO #JavaPHP
(2) A general replacement can use the replace function:
import re a = 'PythonC#\nJavaPHP' a = a.replace('C#','GO') #yes sub Simplified version print(a)
(3) The powerful thing about sub is that its second parameter can be a function:
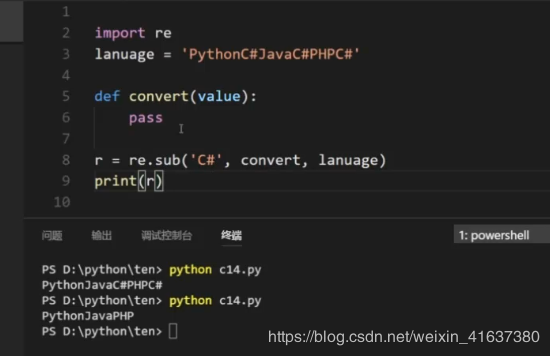
import re def convert(value): matched = value.group() #Extract strings from objects return '!!' + matched + '!!' a = 'PythonC#JavaPHP' r = re.sub('C#',convert,a) print(r) #Python!!C#!!JavaPHP
sub matching to the first result will be passed to the convert function. The returned result is a new string to replace the matched word.
12, Passing functions as parameters
Example:
Find the number, replace the number greater than or equal to 6 with 9, and replace the number less than 6 with 0:
import re def convert(value): matched = value.group() if int(matched) >= 6: return '9' else: return '0' s = 'A8C3721D86' r = re.sub('\d',convert,s) print(r) #A9C0900D99
13, search and match function
1.
match: starts at the beginning of the string (initial).
search: searches the entire string until the first satisfied result is found and returned.
Match and search return objects and only match once, not all like findall.
2
import re s = 'A8C3721D86' r = re.match('\d',s) print(r) r1 = re.search('\d',s) print(r1) #None #<re.Match object; span=(1, 2), match='8'>
3.
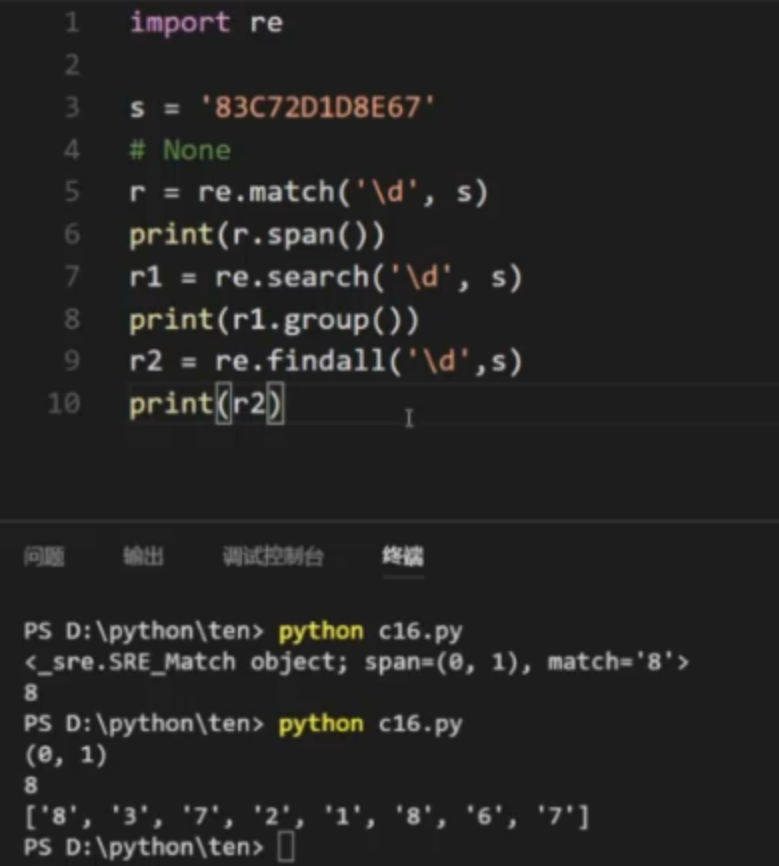
Summary:
r.span() return position, (the first number represents the previous position of the number found, and the second number represents the position of the number found)
r.group() returns a string
14, Group group
1. Extract the characters between life and python:
import re s = 'life is short,i use python' r = re.search('life(.*)python',s) print(r.group(1)) #is short,i use
group(0) is the complete match result
group(1) is an internal group of complete matching results
(2)
Using findall:
import re s = 'life is short,i use python' r = re.findall('life(.*)python',s) print(r) #['is short,i use']
2.group(1) is the first group and group(2) is the second group:
import re s = 'life is short,i use python,i love python' r = re.search('life(.*)python(.*)python',s) print(r.group(0)) print(r.group(1)) print(r.group(2)) #life is short,i use python,i love python #is short,i use #,i love
3.r.groups() returns results other than complete:
import re s = 'life is short,i use python,i love python' r = re.search('life(.*)python(.*)python',s) print(r.groups()) #(' is short,i use ', ',i love ')
Conclusion:
Some suggestions on learning regularity
python is mostly used in crawlers, and regular expressions are needed
Search for 'common regular expressions' and analyze them
1, Understand JSON
1.JavaScript Object Notation is a lightweight (compared with XML) data exchange format.
2. String is the representation of JSON. The string conforming to JSON format is JSON string.
3. advantage:
- Easy to read
- Easy to analyze
- High network transmission efficiency
Suitable for cross language data exchange
4.
2, Deserialization: the process of string to language data structure
Double quotation marks inside json, single quotation marks outside string
1. Use JSON in python to parse JSON data:
import json json_str = '{"name":"tai","age":23}' #json Double quotes inside, single quotes outside str student = json.loads(json_str) print(type(student)) print(student) print(student['name']) print(student['age']) #<class 'dict'> #It's a dictionary #{'name': 'tai', 'age': 23} #tai #23
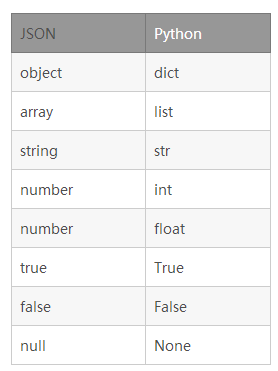
For the same JSON string, different languages will replace it with different types. Where corresponds to the dictionary type in Python.
2. Parse JSON array:
import json json_str = '[{"name":"tai","age":23,"flag":false},{"name":"tai","age":23}]' student=json.loads(json_str) print(type(student)) print(student) #<class 'list'> #Array converted to list #[{'name': 'tai', 'age': 23, 'flag': False}, {'name': 'tai', 'age': 23}] #Two elements in the list, each of which is a dictionary
The process of a data structure in string - > Language: deserialization
Summary: the corresponding data conversion types from json to Python
3, Serialization
1. Serialization: dictionary to string
import json student = [ {"name":"tai","age":23,"flag":False}, {"name":"tai","age":23} ] json_str = json.dumps(student) print(type(json_str)) print(json_str) #<class 'str'> #[{"name": "tai", "age": 23, "flag": false}, {"name": "tai", "age": 23}]
4, On JSON, JSON object and JSON string
JSON is to some extent a Javascript level language.
JSON object, JSON, JSON string.
A language data type - JSON (intermediate data type) - > b language data type
JSON has its own data types, though similar to Javascript.
Standard format for REST services, using JSON.