Background needs
At the same time of finishing the task, practice the crawler, and use the Xpath to match the content to be crawled;
News interface to be crawled
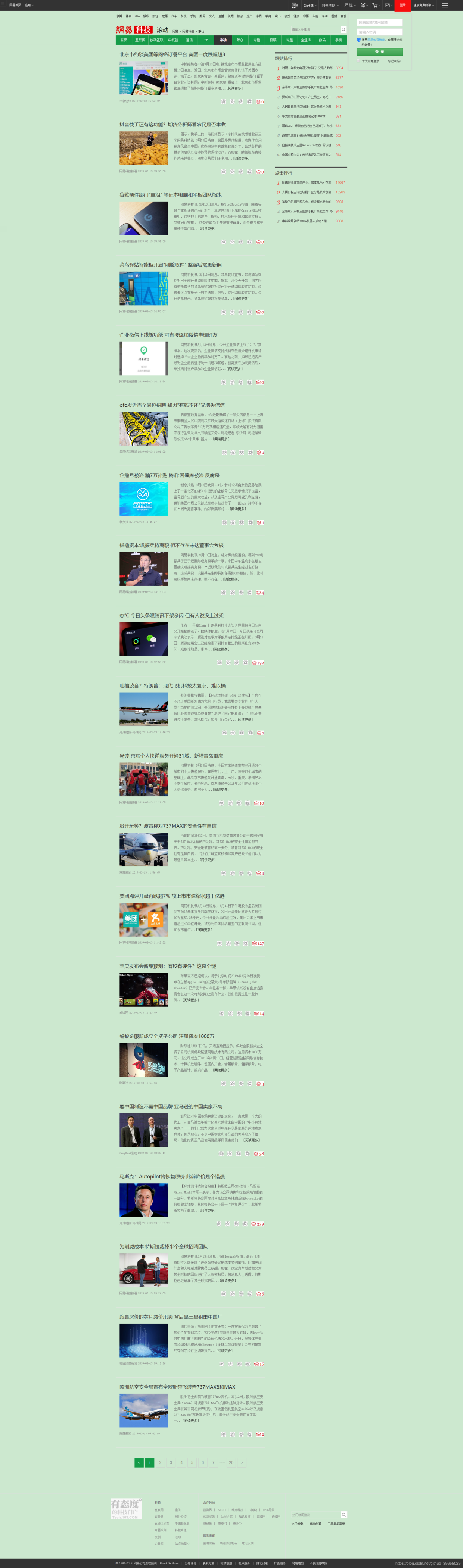
Information to be crawled

Implementation code
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2019/3/13 13:08 # @Author : cunyu # @Site : cunyu1943.github.io # @File : NetaseNewsSpider.py # @Software: PyCharm import requests from lxml import etree import xlwt headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36" } # Get the url list of the news details page in the new page according to the url def getNewsDetailUrlList(url): """ :param url: Per page URL :return newDetailList:News details per page URL """ response = requests.get(url, headers=headers) html = response.content.decode('gbk') selector = etree.HTML(html) newsDetailList = selector.xpath('//ul[@id="news-flow-content"]//li//div[@class="titleBar clearfix"]//h3//a/@href') return newsDetailList # Get news headlines def getNewsTitle(detailUrl): """ :param detailUrl:News detail url :return newsTitle:News headlines """ response = requests.get(detailUrl, headers=headers) html = response.content.decode('gbk') selector = etree.HTML(html) newsTitle = selector.xpath('//div[@class="post_content_main"]//h1/text()') return newsTitle # Get news details def getNewsContent(detailUrl): """ :param detailUrl: News detail url :return newsContent: News details """ response = requests.get(detailUrl, headers=headers) html = response.content.decode('gbk') selector = etree.HTML(html) newsContent = selector.xpath('//div[@class="post_text"]//p/text()') return newsContent # Write news headlines and content to a file TODO # Get page turning URL list def getUrlList(baseUrl, num): """ :param baseUrl:Basic website :param num: Turn to page :return urlList: Page turning URL list """ urlList = [] urlList.append(baseUrl) for i in range(2, num+1): urlList.append(baseUrl + "_" + str(i).zfill(2)) return urlList if __name__ == '__main__': baseUrl = "http://tech.163.com/special/gd2016" num = int(input('Enter the number of pages you want to crawl: ')) urlList = getUrlList(baseUrl, num) print(urlList) detailUrl = [] for url in urlList: for i in getNewsDetailUrlList(url): detailUrl.append(i) print(detailUrl) print(getNewsTitle(detailUrl[0])) print(getNewsContent(detailUrl[0])) # Save crawled text to text file # with open('news.txt', 'w', encoding='utf-8') as f: # for i in detailUrl: # f.write(''.join(getNewsTitle(i))) # f.write('\n') # f.write(''.join(getNewsContent(i))) # f.write('\n') # print('File written successfully ') # Save crawled text to excel file # Create an Excel file workbook = xlwt.Workbook(encoding='utf-8') news_sheet = workbook.add_sheet('news') news_sheet.write(0, 0, 'Title') news_sheet.write(0, 1, 'Content') for i in range(len(detailUrl)): # print(detailUrl[i]) news_sheet.write(i + 1, 0, getNewsTitle(detailUrl[i])) news_sheet.write(i + 1, 1, getNewsContent(detailUrl[i])) # Save the write operation to the specified Excel file workbook.save('NetEase News.xls') print('File written successfully')
Result
-
Code run results

-
Saved files

summary
Generally speaking, the code is relatively simple, and there are also areas that need to be improved. In the future, it will be improved and updated, and people with other ideas can also communicate with each other!