The purpose of this crawler is to crawl the attention of a microblog user and the basic information of fans, including user nickname, id, gender, location and the number of fans. Then the crawler saves the data in the MongoDB database, and finally regenerates several graphs to analyze the data we get.
I. Specific steps:
The crawling site we selected here is https://m.weibo.cn This site is a micro-blog mobile site, we can directly view a user's micro-blog, such as https://m.weibo.cn/profile/5720474518.
Then look at the users they are interested in, open the developer's tools, switch to the XHR filter, and keep dropping down the list, and you'll see a lot of Ajax requests. The type of these requests is Get, and the result is in Json format. After expansion, you can see a lot of user information.
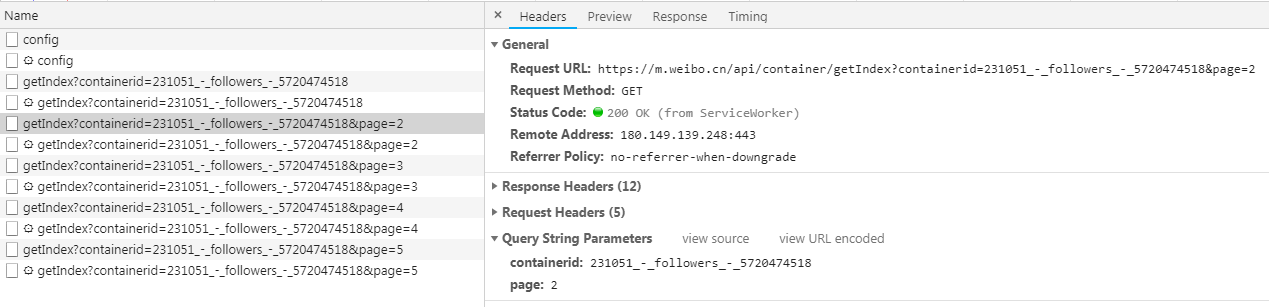
These requests have two parameters, containerid and page. By changing the number of pages, we can get more requests. The steps to get the user information of its fans are the same. In addition to the different links requested, the parameters are different. Just modify it.
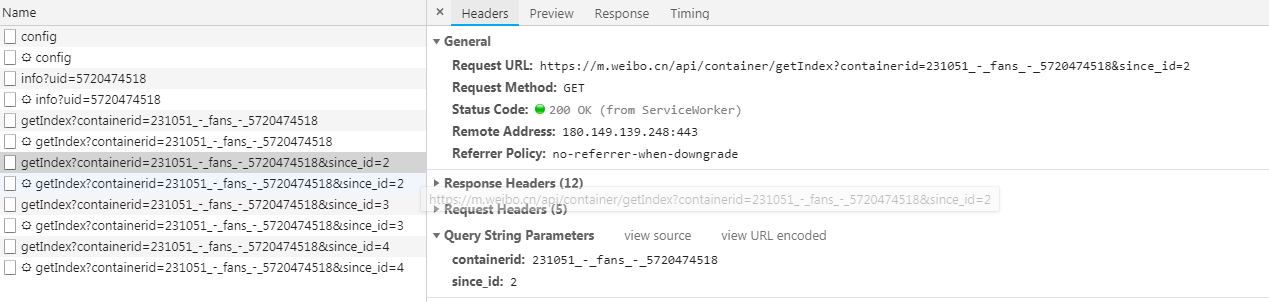
Since the results of these requests only contain the user's name and id, and do not contain the user's gender and other basic information, we click on someone's microblog, and then check their basic information, such as this Open the developer tool to find the following request:
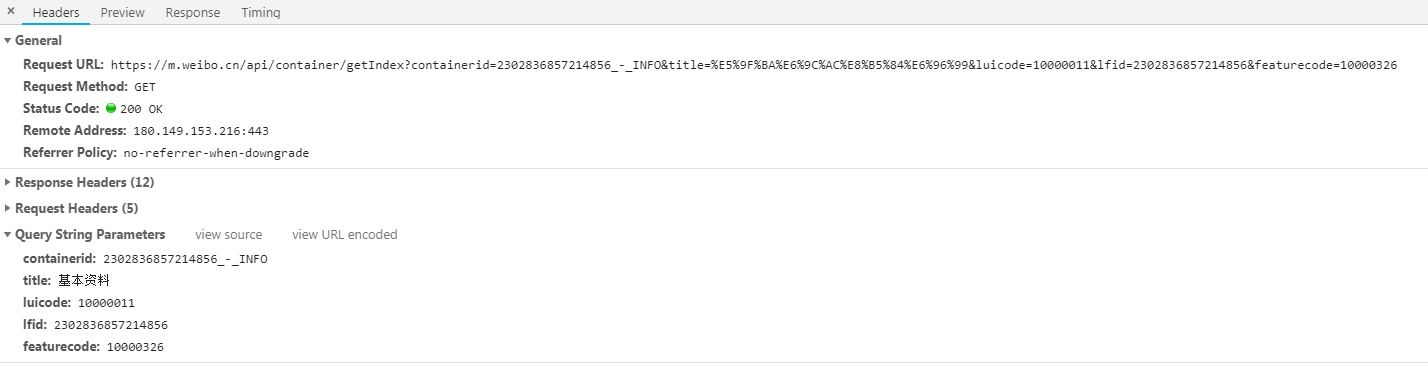
Since this person's ID is 6857214856, we can find that when we get a person's id, we can construct links and parameters to get basic information. The relevant code is as follows (uid is the user's id):
1 uid_str = "230283" + str(uid) 2 url = "https://m.weibo.cn/api/container/getIndex?containerid={}_-_INFO&title=%E5%9F%BA%E6%9C%AC%E8%B5%84%E6%96%99&luicode=10000011&lfid={}&featurecode=10000326".format(uid_str, uid_str) 3 data = { 4 "containerid": "{}_-_INFO".format(uid_str), 5 "title": "Basic data", 6 "luicode": 10000011, 7 "lfid": int(uid_str), 8 "featurecode": 10000326 9 }
Then the returned result is also in Json format, which is very convenient to extract, because many people's basic information is not complete, so I extracted user nicknames, gender, location and the number of fans. And because some accounts are not personal accounts, there is no gender information. For these accounts, I choose to set their gender as male. However, when crawling, I found a problem, that is, when the number of pages exceeds 250, the returned results have no content, that is to say, this method can only crawl 250 pages at most. All the user information is saved in the MongoDB database. After the crawl is finished, the information is read and several charts are drawn. The scalar sector diagram of men and women, the distribution map of user's location and the number of users'fans are drawn respectively.
2. Main codes:
Because the results returned on the first page are different from those returned on other pages, they need to be parsed separately, and because some of the results have different json formats, they may report errors, so try...except... Is used to print out the cause of the error.
Click the first page and parse the code as follows:
1 def get_and_parse1(url): 2 res = requests.get(url) 3 cards = res.json()['data']['cards'] 4 info_list = [] 5 try: 6 for i in cards: 7 if "title" not in i: 8 for j in i['card_group'][1]['users']: 9 user_name = j['screen_name'] # User name 10 user_id = j['id'] # user id 11 fans_count = j['followers_count'] # Number of fans 12 sex, add = get_user_info(user_id) 13 info = { 14 "User name": user_name, 15 "Gender": sex, 16 "Location": add, 17 "Number of fans": fans_count, 18 } 19 info_list.append(info) 20 else: 21 for j in i['card_group']: 22 user_name = j['user']['screen_name'] # User name 23 user_id = j['user']['id'] # user id 24 fans_count = j['user']['followers_count'] # Number of fans 25 sex, add = get_user_info(user_id) 26 info = { 27 "User name": user_name, 28 "Gender": sex, 29 "Location": add, 30 "Number of fans": fans_count, 31 } 32 info_list.append(info) 33 if "followers" in url: 34 print("Page 1 Focus on information crawling...") 35 else: 36 print("Page 1 Fan information crawled through...") 37 save_info(info_list) 38 except Exception as e: 39 print(e)
The code for crawling other pages and parsing is as follows:
1 def get_and_parse2(url, data): 2 res = requests.get(url, headers=get_random_ua(), data=data) 3 sleep(3) 4 info_list = [] 5 try: 6 if 'cards' in res.json()['data']: 7 card_group = res.json()['data']['cards'][0]['card_group'] 8 else: 9 card_group = res.json()['data']['cardlistInfo']['cards'][0]['card_group'] 10 for card in card_group: 11 user_name = card['user']['screen_name'] # User name 12 user_id = card['user']['id'] # user id 13 fans_count = card['user']['followers_count'] # Number of fans 14 sex, add = get_user_info(user_id) 15 info = { 16 "User name": user_name, 17 "Gender": sex, 18 "Location": add, 19 "Number of fans": fans_count, 20 } 21 info_list.append(info) 22 if "page" in data: 23 print("The first{}Page attention information crawled...".format(data['page'])) 24 else: 25 print("The first{}Page fans information crawl through...".format(data['since_id'])) 26 save_info(info_list) 27 except Exception as e: 28 print(e)
3. Operation results:
There may be a variety of errors in operation, sometimes the result is empty, sometimes the parsing error, but still can successfully crawl most of the data, let's put the last three pictures here.
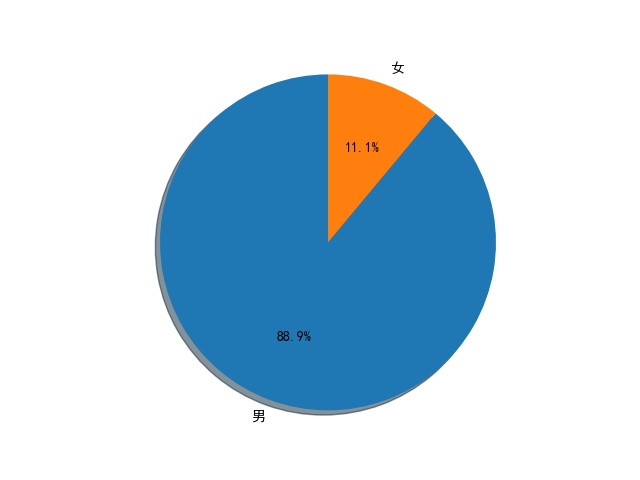
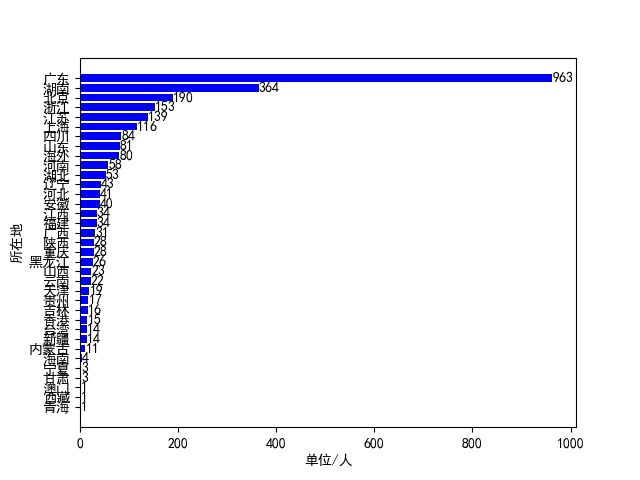
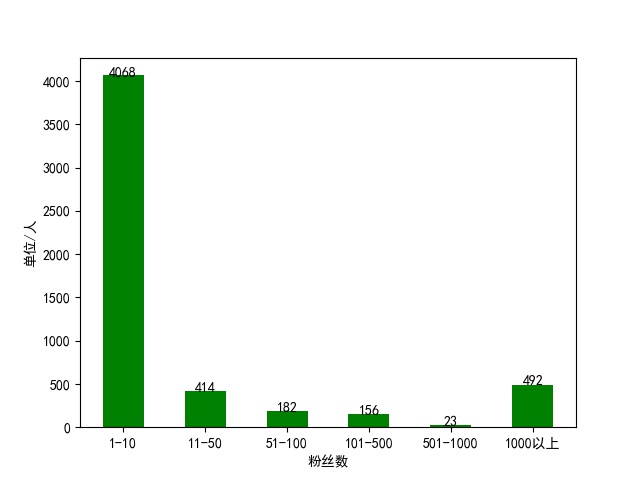
The complete code has been uploaded to GitHub: https://github.com/QAQ112233/WeiBoUsers