PyQuery is a powerful and flexible web parsing library in python. If you find regular writing too cumbersome and Beautiful Soup grammar too difficult to remember, if you are familiar with jQuery grammar, PyQuery is your best choice.
Installation: pip3 install pyquery
I. Initialization
Here are three ways to initialize PyQuery.
1. String initialization
html = ''' <div> <ul> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> ''' from pyquery import PyQuery as pq#Habitual writing, replacing the PyQuery class with the letter pq doc = pq(html)#Declare the PyQuery object doc and pass in the parameter html (string) print(doc('li'))#use css Selector to implement, if you want to select id Front plus#If class is selected, add., if label name is selected, add nothing.

As shown in the figure, the content of the li tag is selected and printed out.
2. URL initialization
from pyquery import PyQuery as pq doc=pq(url='http://www.baidu.com')#Directly requesting the incoming url print(doc('head'))

The head tag was selected.
3. File initialization
from pyquery import PyQuery as pq doc=pq(filename='demo.html')#Specify the file name, which is in the runtime directory print(doc('head'))
Basic CSS selector
html = ''' <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> ''' from pyquery import PyQuery as pq doc = pq(html) print(doc('#container .list li')) #It looks for objects with id container class as list and label li as hierarchical relationships. The latter is not necessarily a child of the former. #Pay attention to space separation

3. Finding Elements
Find child elements
html = ''' <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> ''' from pyquery import PyQuery as pq doc = pq(html) items = doc('.list')#Get items and select the list class. print(type(items)) print(items) lis = items.find('li')#Using the find method to find the li tag in items, the obtained lis can also continue to call the find method to look down and peel off layer by layer. print(type(lis)) print(lis)
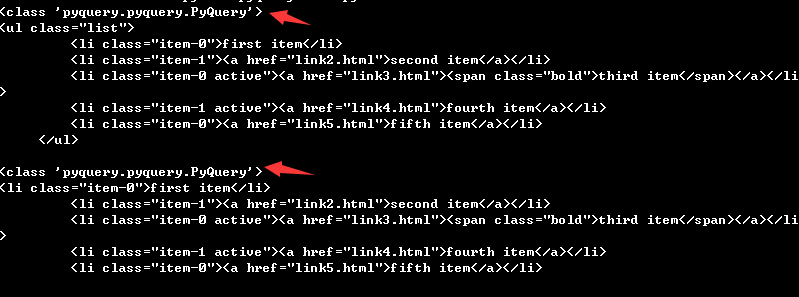
The printed content is shown in the figure above, with all the contents in the list class above and all the contents of the li tags in the class below.
You can also use **. children()** to find direct child elements:
items = doc('.list') lis = items.children() print(type(lis)) print(lis) lis = items.children('.active') print(lis)
Find the parent element
html = ''' <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> ''' from pyquery import PyQuery as pq doc = pq(html) items = doc('.list') container = items.parent()#parent() finds the parent element of the object print(type(container)) print(container)
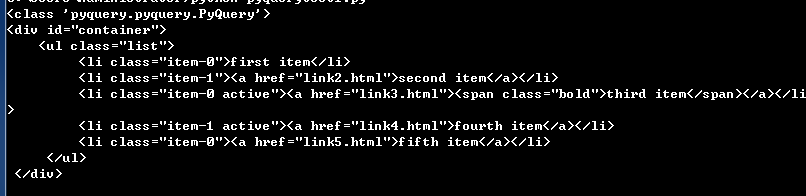
The parent node of the list class is container, which is printed out.
Ancestral node
html = ''' <div class="wrap"> <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> </div> ''' from pyquery import PyQuery as pq doc = pq(html) items = doc('.list') #parents = items.parents()#parents () Find all ancestor nodes parent = items.parents('.wrap')#You can pass in parameters and filter them again. print(parent)
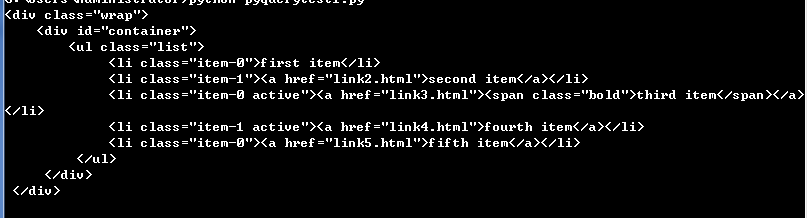
Find out all ancestor nodes, wrap-like nodes.
Brotherhood
html = ''' <div class="wrap"> <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> </div> ''' from pyquery import PyQuery as pq doc = pq(html) li = doc('.list .item-0.active')#Spaces denote the next level, and no spaces denote juxtaposition print(li.siblings())#siblings() siblings () siblings() siblings () siblings() siblings () siblings() siblings () siblings() siblings () siblings() sibling

In the figure, four sibling elements are selected.
Of course, it can be screened again from the results:
print(li.siblings('.active'))#

Four, traversal
If the result of the search has multiple elements and you want to operate on each one, then traversal is needed. The key to traversal is items.
html = ''' <div class="wrap"> <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> </div> ''' from pyquery import PyQuery as pq doc = pq(html) lis = doc('li').items()#items will be a generator that can be used to traverse print(type(lis)) for li in lis: print(li)
V. Access to Information
get attribute
html = ''' <div class="wrap"> <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> </div> ''' from pyquery import PyQuery as pq doc = pq(html) a = doc('.item-0.active a')#Select the tag space with both item-0 and activity information to represent the inner tag of the tag. print(a) print(a.attr('href'))#The content of the href attribute of a tag, which is a hyperlink print(a.attr.href)#Another way of writing
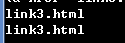
Get text
from pyquery import PyQuery as pq doc = pq(html) a = doc('.item-0.active a')#Select the tag space with both item-0 and activity information to represent the inner tag of the tag. print(a) print(a.text())#Get the content in the tag
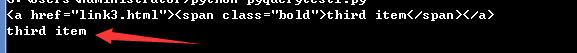
Get HTML
from pyquery import PyQuery as pq doc = pq(html) li = doc('.item-0.active')#Select a li tag print(li) print(li.html())#Get the html content in the tag

6. DOM Operation
Do some operations on the nodes. There are many API s in this section. Here are some examples.
addClass,removeClass
html = ''' <div class="wrap"> <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> </div> ''' from pyquery import PyQuery as pq doc = pq(html) li = doc('.item-0.active') print(li) li.removeClass('active')#Delete the class attribute of activity print(li) li.addClass('active')#increase print(li)

attr,css
from pyquery import PyQuery as pq doc = pq(html) li = doc('.item-0.active') print(li) li.attr('name','link')#If it does not exist, a name attribute with link content is added to the tag. If it does exist, change it. print(li) li.css('font-size','14px')#Add a css print(li)

remove
Looking at the following html paragraph, we want to get "Hello World" content separately, but there's something else beside him. If we select the wrap tag and then. text directly, we will get two pieces of content. At this time, you can delete the unnecessary parallel content by remove method first.
html = ''' <div class="wrap"> Hello, World <p>This is a paragraph.</p> </div> ''' from pyquery import PyQuery as pq doc = pq(html) wrap = doc('.wrap') print(wrap.text()) wrap.find('p').remove()#Find the p tag and delete it print(wrap.text())
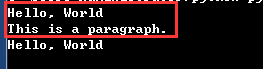
In the red box, delete the previous content. After deletion, you can get the ancestor of the code alone: "Hello World!"
Other DOM methods
Other DOM methods
http://pyquery.readthedocs.io/en/latest/api.html
The above website lists all the API s, which can be viewed when needed.
#7. Pseudo-class selector
Select the specified label according to your needs (order, etc.).
html = ''' <div class="wrap"> <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> </div> ''' from pyquery import PyQuery as pq doc = pq(html) li = doc('li:first-child')#Select the first in the li tag print(li) li = doc('li:last-child') print(li) li = doc('li:nth-child(2)')#Get the second li tag print(li) li = doc('li:gt(2)')#Get the li tag after two indexes. Be careful! Index starts at 0. print(li) li = doc('li:nth-child(2n)')#Get the even number of li Tags print(li) li = doc('li:contains(second)')#Find the li tag containing the "second" text print(li)
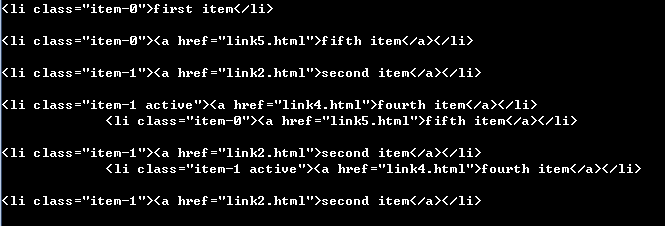
More CSS selectors can be viewed http://www.w3school.com.cn/css/index.asp
Official documents
http://pyquery.readthedocs.io/