In this section, how to insert the crawled data into mysql database is discussed. The tools used are PyCharm and Navicat for MySQL or Navicat Premium
The crawled website is: http://books.toscrape.com/ , which is explained in many tutorials. Let's open navicat, create a new query, and create a table in the editor (using the database db_name): 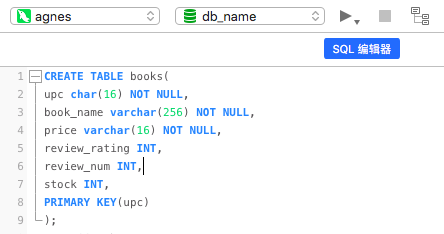
After success, books looks like this: 
Open PyCharm, and first create a crawler project named toscrape book. The code in items.py is as follows:
from scrapy import Item,Field
class BookItem(Item):
name = Field()
price =Field()
review_rating =Field() #Rating star
review_num =Field() #Evaluation quantity
upc =Field() #Product coding
stock =Field() # Storage volumebooks.py:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from toscrape_book.items import BookItem
class BooksSpider(scrapy.Spider):
name = 'books'
allowed_domains = ['books.toscrape.com']
start_urls = ['http://books.toscrape.com/']
cats={ #This is mainly to match the English version of the star rating into a number
'One':'1',
'Two':'2',
'Three':'3',
'Four':'4',
'Five':'5'
}
def parse(self, response):
le = LinkExtractor(restrict_css='article.product_pod h3')#Get links to detailed pages of each book
for link in le.extract_links(response):
yield scrapy.Request(link.url,callback=self.parse_book,dont_filter=True)
le = LinkExtractor(restrict_css='ul.pager li.next') #Get paged links
links = le.extract_links(response)
if links:
next_link = links[0].url
yield scrapy.Request(next_link,callback=self.parse,dont_filter=True)
def parse_book(self,response):
item=BookItem()
sel = response.css('div.product_main')
item['name']= sel.xpath('./h1/text()').extract_first()
item['price']= sel.css('p.price_color::text').extract_first()
rating = sel.css('p.star-rating::attr(class)').re_first('star-rating ([A-Za-z]+)')
item['review_rating'] = self.cats[rating] #Match the English of the star rating to a number
sel= response.css('table.table.table-striped')
item['review_num']=sel.xpath('.//tr[last()]/td/text()').extract_first()
item['upc']=sel.xpath('.//tr[1]/td/text()').extract_first()
item['stock']=sel.xpath('.//tr[last()-1]/td/text()').re_first('\((\d+) available\)') #Find the number before available with regular
yield itemsettings.py:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'toscrape_book.pipelines.MySQLPipeline': 100,
}
# Mysql database connection, here is my database information
MYSQL_HOST = 'localhost'
MYSQL_DB_NAME = 'db_name'
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'Your own database password'
MYSQL_PORT =3306pipelines.py:
# -*- coding: utf-8 -*-
import pymysql #Third party library files used to connect to the database
from scrapy.conf import settings
class MySQLPipeline(object):
def process_item(self,item,spider):
db= settings['MYSQL_DB_NAME'] #Call the corresponding data information in settings.py
host = settings['MYSQL_HOST']
port = settings['MYSQL_PORT']
user = settings['MYSQL_USER']
passwd =settings['MYSQL_PASSWORD']
db_conn = pymysql.connect(host = host,port = port, db= db,user=user,passwd=passwd,charset ='utf8')
db_cur = db_conn.cursor() #Create cursor object to execute SQL statement
print("Database connection successful")
values =( #This is the value we want to pass into the database
item['upc'],
item['name'],
item['price'],
item['review_rating'],
item['review_num'],
item['stock'],
)
try:
sql = 'INSERT INTO books VALUES (%s,%s,%s,%s,%s,%s)' #SQL statement
db_cur.execute(sql,values) #Execute with execute
print("Data inserted successfully")
except Exception as e:
print('Insert error:', e)
db_conn.rollback()
else:
db_conn.commit() #Every time you insert it, you commit it, and the data is saved
db_cur.close()
return itemOK. In this way, a simple connection and insertion are established. Run the crawler in terminal:
scrapy crawl books
Open to view navicat, and the result is as follows: 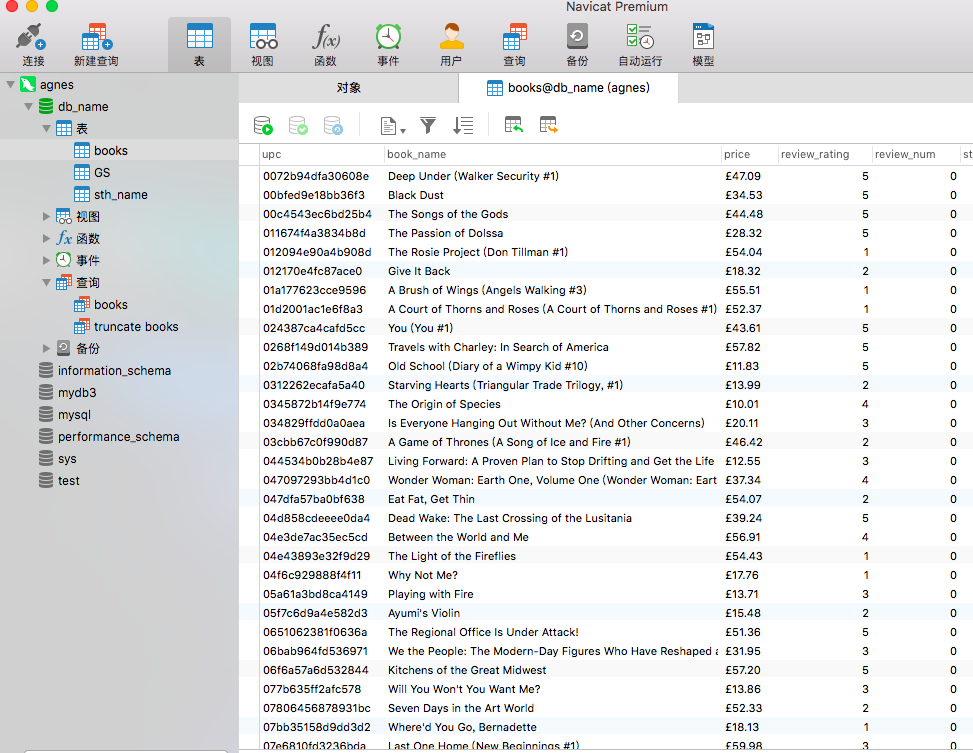
However, the insert connection established in this way is very inefficient. Each insert will commit once and connect to the database once. The solution is to realize the asynchronous network framework. By using the adbapi module in Twisted.enterprise, the efficiency of accessing the database can be significantly improved. This will be explained in case 5.