This section shares the Java thread pool. Next, let's dig up the thread pool step by step.
Introduction: old three withdraw money
There is a programmer whose name is Lao San.
The third man had no money in his pocket and hurried to do banking business.
This day got up early in the morning and the bank sister said good morning.
As soon as the third man saw that the counter was empty, he took all five cents from the card.

The old three got up late that day, and the business windows were full.
I had to enter the queue area and find out my mobile phone.
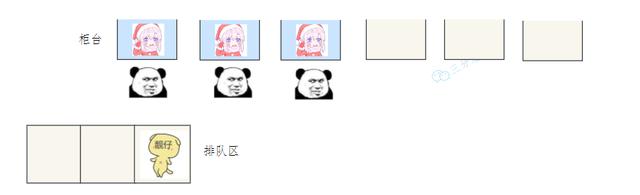
The old three slept to the last three shots, and the windows were full.
As soon as the manager opened a new mouth, the comrades in line hurried to do it.
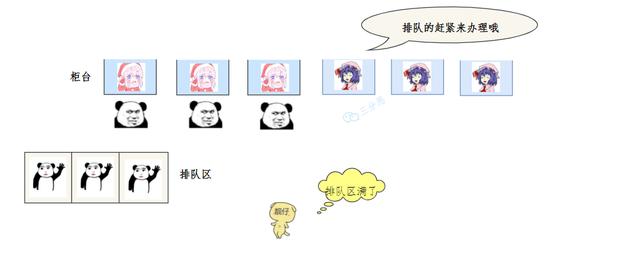
The business was so hot that the counter was used up.
The third one is angry. What do you say, manager.
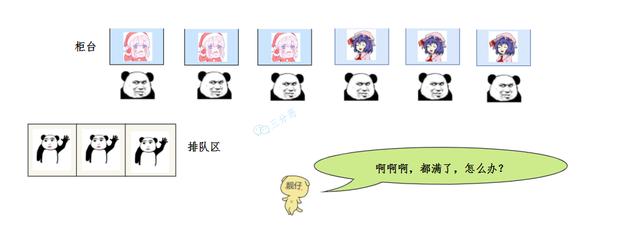
The manager waved and smiled. This kind of scene has been used to. Four ways to deal with it. Guess what I'll do.
- Small banks are overwhelmed and the old system has collapsed.
- Our temple is small. I'm sorry. Who asked you to do it.
- Your situation is very urgent. Come and put a plug in the team.
- I really can't help it today. You can't change it.
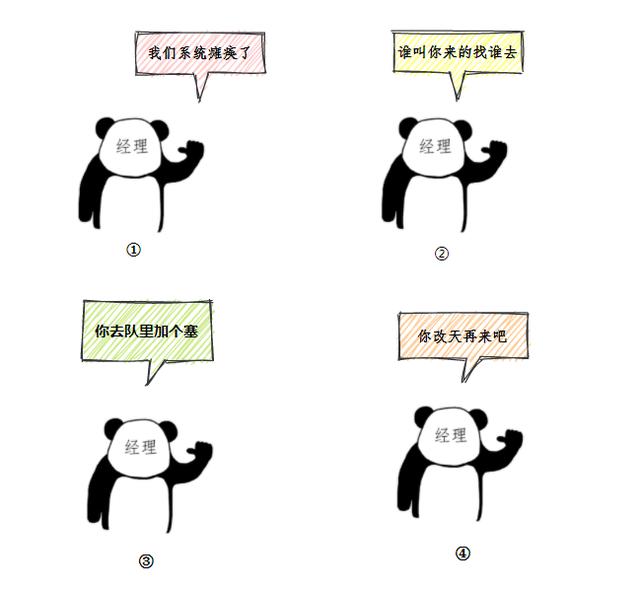
Yes, that's right. In fact, this process is similar to the workflow of the JDK thread pool ThreadPoolExecutor. Sell it first, and then combine it with the workflow of the thread pool to ensure that you will be suddenly enlightened.
Actual combat: thread pool management data processing thread
show you code, let's have a thread pool practice combined with business scenarios—— Many students are familiar with the principle of thread pool during the interview. When they ask how to use it in the project, they have a rest. After reading this example, quickly figure out where it can be applied in the project.
Application scenario
The application scenario is very simple. Our project is an approval system. When it comes to accounting every year, we need to provide data to the third-party accounting system for accounting.
There is a problem here. Due to historical reasons, the interface provided by the accounting system only supports single push, but the actual amount of data is 300000. If you push one by one, it will take at least a week.
Therefore, consider using multithreading to push data. What is the thread management? Thread pool.
Why use thread pool to manage threads? For thread reuse, of course.
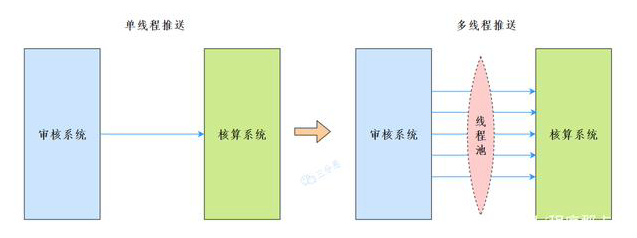
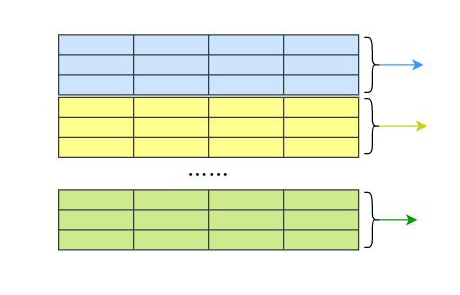
The idea is also very simple. Start several threads, and each thread reads the data not pushed in the start,count] interval from the database to push.
Specific code implementation
I extracted the scene. The main code is:
The code is quite long, so carbon is used for beautification. I can't see the code clearly. It doesn't matter. I uploaded all the runnable codes to the remote warehouse. The warehouse address is: https://gitee.com/fighter3/thread-demo.git , this example is relatively simple. Students who have not used thread pool can consider whether you have any data processing and cleaning scenarios to apply. You might as well learn from and deduce them.
The topic of this article is thread pool, so we focus on the code of thread pool:
Thread pool construction
//Number of core threads: set to the number of operating system CPU s multiplied by 2 private static final Integer CORE_POOL_SIZE = Runtime.getRuntime().availableProcessors() * 2; //Maximum number of threads: set to be the same as the number of core threads private static final Integer MAXIMUM_POOl_SIZE = CORE_POOL_SIZE; // Create thread pool ThreadPoolExecutor pool = new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIMUM_POOl_SIZE * 2, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100));
The thread pool is directly constructed by ThreadPoolExecutor:
- The number of core threads is set to the number of CPU s × two
- Because segmented data is required, the maximum number of threads is set to be the same as the number of core threads
- Blocking queues use LinkedBlockingQueue
- Reject policy use default
Thread pool submit task
//Submit the thread, and identify the thread with the data starting position Future<Integer> future = pool.submit(new PushDataTask(start, LIMIT, start));
- Because the return value is required, submit() is used to submit the task. If execute() is used to submit the task, there is no return value.
The code is not responsible. You can do it and run.
So, how does thread pool work? Let's move on.
Principle: implementation principle of thread pool
Thread pool workflow
Construction method
When constructing the thread pool, we used the construction method of ThreadPoolExecutor:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler);
}
Let's take a look at the meaning of several parameters:
-
corePoolSize: number of core threads
-
maximumPoolSize: maximum number of threads allowed (core threads + non core threads)
-
workQueue: thread pool task queue
A blocking queue used to save tasks waiting to be executed. Common blocking queues are:
-
- ArrayBlockingQueue: a bounded blocking queue based on array structure
- Linked blocking queue: blocking queue based on linked list structure
- SynchronousQueue: a blocking queue that does not store elements
- PriorityBlockingQueue: infinite blocking queue with priority
-
handler: thread pool saturation rejection policy
The JDK thread pool framework provides four strategies:
You can also implement the RejectedExecutionHandler interface to customize policies according to your own application scenarios.
-
- AbortPolicy: throw an exception directly. The default policy is.
- CallerRunsPolicy: run the task with the thread of the caller.
- Discard oldest policy: discards the oldest task in the task queue
- DiscardPolicy: discard the current task without processing
The above four parameters are closely related to the thread pool workflow. Let's take a look at the remaining three parameters.
- keepAliveTime: the maximum time a non core thread can survive idle
- unit: the time that non core threads in the thread pool remain alive
- threadFactory: the factory used when creating a new thread. It can be used to set the thread name, etc
Thread pool workflow
After knowing several parameters, how are these parameters applied?
Taking the task submitted by the execute() method as an example, let's look at the workflow of the thread pool:
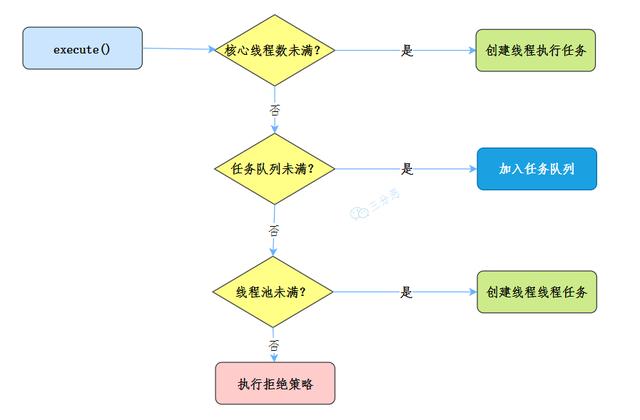
When submitting a task to the thread pool:
- If the number of currently running threads is less than corePoolSize, a new thread is created to execute the task
- If the number of running threads is equal to or more than the number of core threads corePoolSize, the task is added to the task queue workQueue
- If the task queue workQueue is full, create a new thread to process the task
- If a new thread is created so that the current number of bus processes exceeds the maximum number of threads, the task will be rejected and the thread pool will reject the execution of the policy handler
Combined with our life examples at the beginning, is it right:
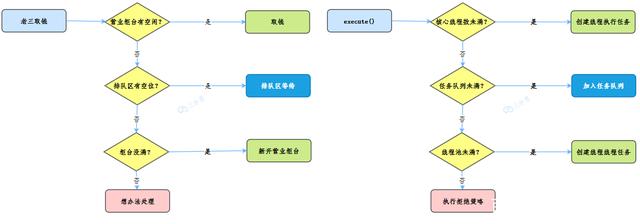
Analysis of working source code of thread pool
The above process analysis gives us an intuitive understanding of the working principle of thread pool. Let's look at the details through the source code.
Commit thread (execute)
The thread pool performs tasks as follows:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//Gets the combined value of the status of the current thread pool + the number of threads variable
int c = ctl.get();
// 1. If the number of running threads is less than the number of core threads
if (workerCountOf(c) < corePoolSize) {
// Start a new thread to run
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2. Judge whether the thread pool is running. If yes, add the task to the blocking queue
if (isRunning(c) && workQueue.offer(command)) {
// Secondary inspection
int recheck = ctl.get();
// If the current thread pool is not running, remove the task from the queue and execute the reject policy
if (!isRunning(recheck) && remove(command))
reject(command);
// If the current thread pool is empty, a new thread will be added
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// Finally, try to add a thread. If the addition fails, execute the reject policy
else if (!addWorker(command, false))
reject(command);
}
Let's take a look at the detailed flowchart of execute():
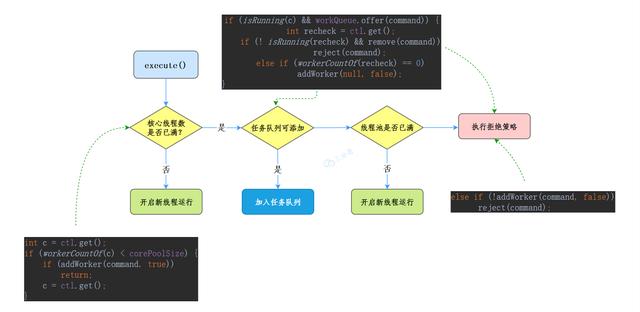
New thread (addWorker)
In the execute method code, there is a key method private boolean addWorker(Runnable firstTask, boolean core). This method mainly completes two parts: increasing the number of threads, adding tasks, and executing.
- Let's take a look at the first part to increase the number of threads:
retry:
for (; ; ) {
int c = ctl.get();
int rs = runStateOf(c);
// 1. Check whether the queue is empty only when necessary (judge the thread status, and the queue is not empty)
if (rs >= SHUTDOWN && !(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty())) return false;
// 2. Increase the number of threads in the cyclic CAS
for (; ; ) {
int wc = workerCountOf(c);
// 2.1 if the number of threads exceeds the limit, false is returned
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false;
// 2.2 increase the number of threads in CAS mode, and only one thread successfully jumps out of the loop
if (compareAndIncrementWorkerCount(c)) break retry;
// 2.3 CAS fails. Check whether the thread pool state changes. If it changes, jump to the outer layer and try to get the thread pool state again. Otherwise, the inner layer will CAS again
c = ctl.get(); // Re-read ctl if (runStateOf(c) != rs) continue retry; } }
// 3. This shows that CAS is successful
boolean workerStarted = false;
boolean workerAdded = false;
}
}
- Next, let's look at the second part, adding tasks and executing them
Worker w = null;
try {
//4. Create worker
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// 4.1. Add an exclusive lock. In order to synchronize workers, multiple threads may call the excute method of the thread pool
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 4.2, recheck the thread pool state to avoid calling the shutdown interface before getting the lock.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// 4.3 adding tasks
workers.add(w);
int s = workers.size();
if (s > largestPoolSize) largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 4.4. Start the task after adding successfully
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (!workerStarted) addWorkerFailed(w);
}
return workerStarted;
Let's take a look at the overall process:
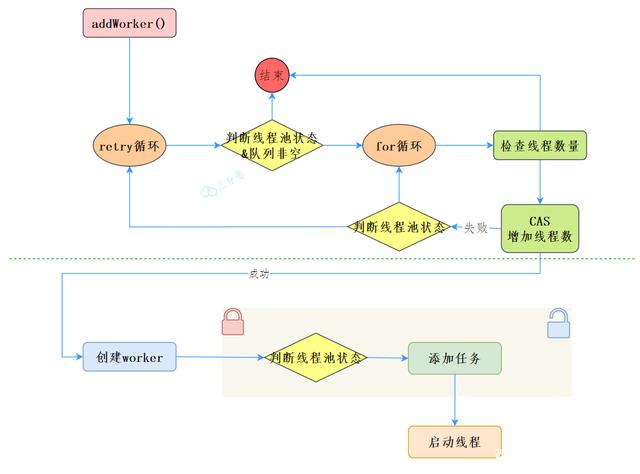
Execution thread (runWorker)
After the user thread is submitted to the thread pool, it is executed by the Worker. The Worker is a custom class within the thread pool that inherits AQS and implements the Runnable interface. It is an object that specifically carries tasks.
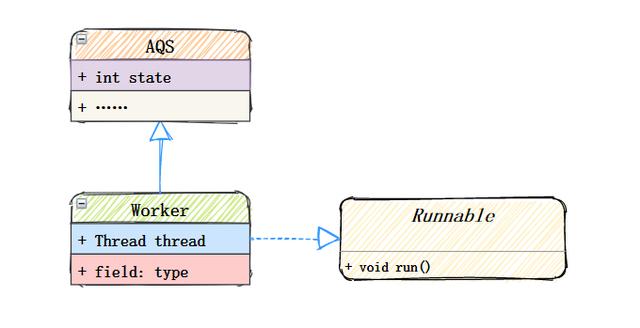
Let's take a look at its construction method:
Worker(Runnable firstTask) {
setState(-1);
// Disable interrupts before calling runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //Create a thread
}
- First, set state=-1 in the constructor, and a simple non reentrant exclusive lock is present. state=0 indicates that the lock has not been acquired, state=1 indicates that the lock has been acquired, and the state size is - 1 to prevent the thread from being interrupted before running the runWorker() method
- firstTask records the first task of the worker thread
- Thread is the thread that executes the task
Its run method directly calls runWorker, and the real thread execution is in our runWorker method:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock();
// Allow interrupt
boolean completedAbruptly = true;
try {
// Get the current task and get the task from the queue
while (task != null || (task = getTask()) != null) {
w.lock(); ............try {
// Do something like statistics before performing the task
beforeExecute(wt, task);
Throwable thrown = null;
try {
// Perform tasks
task.run();
} catch (RuntimeException x) {
thrown = x;
throw x;
} catch (Error x) {
thrown = x;
throw x;
} catch (Throwable x) {
thrown = x;
throw new Error(x);
} finally {
// Do something after the task
afterExecute(task, thrown);
}
} finally {
task = null;
// Count how many tasks the current Worker has completed
w.completedTasks++;
w.unlock();
}
} completedAbruptly = false;
} finally {
// Perform cleaning work
processWorkerExit(w, completedAbruptly);
}
}
The code looks too much. In fact, the core point is that task.run() makes the thread run.
Get task (getTask)
We can see from the above execution task runWorker that when (task! = null | (task = getTask())! = null), the execution task is either the currently passed in firstTask or can be obtained through getTask(). The core purpose of this getTask is to obtain tasks from the queue.
private Runnable getTask() {
//Whether the poll() method timed out
boolean timedOut = false;
// Cyclic acquisition
for (; ; ) {
int c = ctl.get();
int rs = runStateOf(c);
// 1. If the thread pool is not terminated and the queue is empty, null is returned
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
// Number of worker threads
int wc = workerCountOf(c);
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 2. Judge whether the number of worker threads exceeds the maximum number of threads & & timeout Judgment & & the number of worker threads is greater than 0 or the queue is empty
if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c)) return null;
continue;
}
try {
// Get thread from task queue
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
// Get success
if (r != null) return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
To sum up, the task execution model of Worker is as follows [8]:
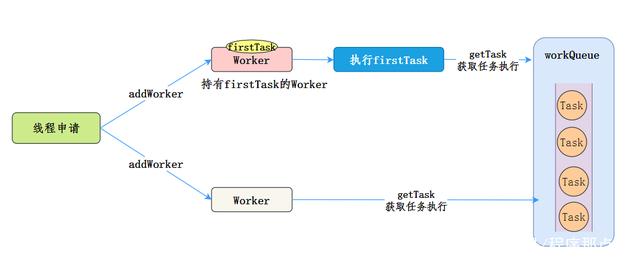
Summary
After understanding some processes of execute and worker, it can be said that the implementation of ThreadPoolExecutor is a production and consumption model.
When a user adds a task to the thread pool, it is equivalent to a producer production element. When a thread in the workers thread working set directly executes a task or obtains a task from the task queue, it is equivalent to a consumer consumption element.
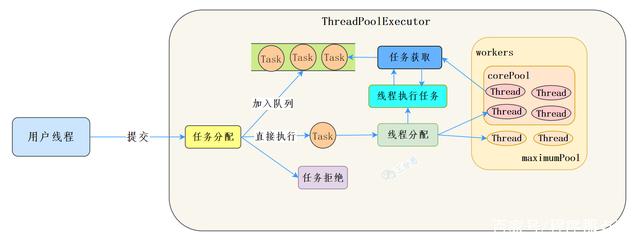
Thread pool lifecycle
Thread pool status representation
Some states are defined in the ThreadPoolExecutor. At the same time, the ctl parameter can save the state and the number of threads by using the high and low methods. It is very clever! [6]
//Record thread pool status and number of threads private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); // 29 private static final int COUNT_BITS = Integer.SIZE - 3; private static final int CAPACITY = (1 << COUNT_BITS) - 1; // Thread pool status private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;
The upper 3 bits indicate the status, and the lower 29 bits record the number of threads:
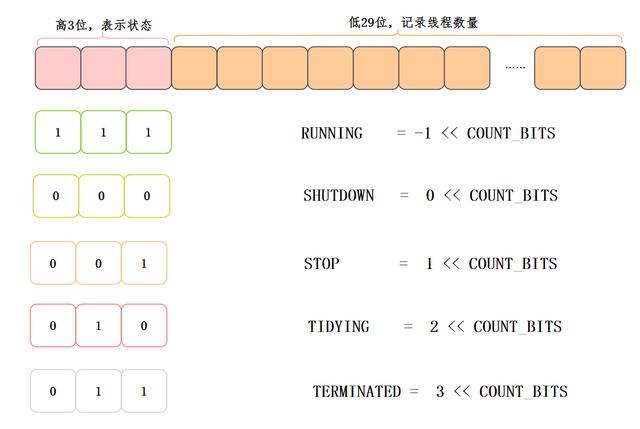
Thread pool state flow
There are five states defined in the thread pool. Let's see how these states flow [6]:
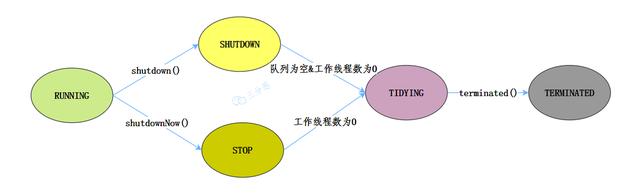
- RUNNING: RUNNING status, accepting new tasks and processing tasks in the queue.
- shutdown: shutdown state (shutdown method called). Do not accept new tasks, but process tasks in the queue.
- STOP: STOP status (the shutdown now method is called). Do not accept new tasks, do not process tasks in the queue, and interrupt the task being processed.
- TIDYING: all tasks have been TERMINATED. The workerCount is 0. After the thread pool enters this state, it will call the terminated() method to enter the TERMINATED state.
- TERMINATED: the TERMINATED state, which is the state after the terminated() method call ends.
Application: build a robust thread pool
Reasonably configure thread pool
About the construction of thread pool, we need to pay attention to two configurations, the size of thread pool and task queue.
Thread pool size
As for the size of thread pool, there is no "golden rule" that needs to be strictly observed. According to the nature of tasks, it can be divided into CPU intensive tasks, IO intensive tasks and hybrid tasks.
- CPU intensive tasks: CPU intensive tasks should be configured with as few threads as possible, such as the thread pool of Ncpu+1 thread.
- IO intensive tasks: if IO intensive task threads are not always executing tasks, configure as many threads as possible, such as 2*Ncpu.
- Hybrid tasks: hybrid tasks can be split into CPU intensive tasks and IO intensive tasks as needed.
Of course, this is just a suggestion. In fact, how to configure it should be combined with prior evaluation, testing and in-process monitoring to determine the approximate thread pool size. The thread pool size can also be adjusted by using dynamic configuration without writing dead.
Task queue
It is generally recommended to use bounded queues for task queues. Unbounded queues may cause unlimited accumulation of tasks in the queue, resulting in memory overflow exceptions.
Thread pool monitoring
[1] If the thread pool is widely used in the system, it is necessary to monitor the thread pool to quickly locate the problem according to the usage of the thread pool.
You can monitor the thread pool through the parameters and methods provided by the thread pool:
- getActiveCount(): the number of threads executing tasks in the thread pool
- getCompletedTaskCount(): the number of tasks completed by the thread pool, which is less than or equal to taskCount
- getCorePoolSize(): the number of core threads in the thread pool
- getLargestPoolSize(): the maximum number of threads that the thread pool has ever created. Through this data, you can know whether the thread pool is full, that is, it reaches the maximum poolsize
- getMaximumPoolSize(): the maximum number of threads in the thread pool
- getPoolSize(): the current number of threads in the thread pool
- getTaskCount(): the total number of executed and unexecuted tasks in the thread pool
You can also monitor by extending the thread pool:
- Customize the thread pool by inheriting the thread pool, and override the beforeExecute, afterExecute and terminated methods of the thread pool,
- You can also execute some code to monitor before, after, and before the thread pool is closed. For example, the average execution time, maximum execution time and minimum execution time of monitoring tasks.
End
This article starts with a life scene, step by step from actual combat to principle to deeply understand thread pool.