Functional introduction
Objective: To obtain the names and trading information of all stocks on the Shanghai Stock Exchange and Shenzhen Stock Exchange.
Output: Save to file.
Technical route: requests--bs4--re
Language: Python 3.5
Explain
Site Selection Principle: Stock information exists in html pages statically, is not generated by js code, and is not restricted by Robbts protocol.
Selection method: Open the web page, view the source code, search the web page for stock price data exists in the source code.
If you open the web address of Sina Stock: Link Description As shown in the following figure:
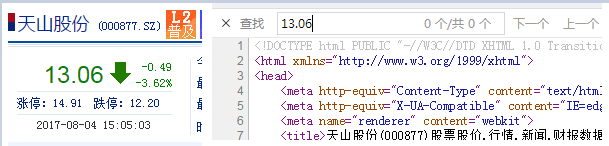
In the image above, on the left is the interface of the web page, which shows that the stock price of Tianshan shares is 13.06.On the right is the source code of the page. Query 13.06 in the source code and find it not found.Therefore, judging that the data of this web page was generated using js is not suitable for this project.So switch to a different page.
Then open the website of Baidu Stock: Link Description As shown in the following figure:
From the above figure, we can see that the data of Baidu stock is generated by html code, which meets the requirements of this project, so we choose the website of Baidu stock in this project.
Since Baidu stock only has information about individual stocks, we also need a list of all the stocks in the current stock market. Here we choose Oriental Fortune. com at: Link Description And the interface is as follows:
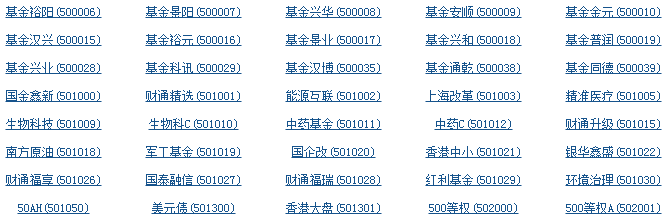
Principle analysis
Looking at the web address of each stock in Baidu stock: https://gupiao.baidu.com/stock/sz300023.html, you can see that there is a number 300023 in the web address that exactly corresponds to the number of this stock, which is the Shenzhen Stock Exchange represented by sz.So we constructed the following program structure:
- Step 1: Get a list of stocks from Eastern Fortune.
- Step 2: Get the stock codes one by one, and add them to the links of Baidu stock. Finally, access these links one by one to get the stock information;
- Step 3: Store the results in a file.
Next, look at the source code of Baidu stock information web page, and find that the information of each stock is stored in the html code as follows:

Therefore, when we store information about each stock, we can refer to how the html code in the figure above is stored.Each information source corresponds to an information value, which is stored as a key-value pair.In python, key-value pairs can be of type dictionary.Therefore, in this project, use a dictionary to store the information for each stock, then use the dictionary to record all stock information, and finally output the data in the dictionary to a file.
Coding
The first is the program to get html web page data, which is not described here much. The code is as follows:
#Get html text def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ""
Next comes the html code parser, where the first thing you need to parse is the Oriental Wealth web page: Link Description , we open its source code, as shown in the following figure:

As you can see from the above image, the web address link in the href attribute of tag a has the corresponding number for each stock, so we just need to parse out the number of the corresponding stock in the web address.The parsing steps are as follows:
Step one, get a page:
html = getHTMLText(stockURL)
Step 2, parse the page and find all the a tags:
soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a')
The third step is to iterate through each tag a for related processing.The process is as follows:
1. Find the href attribute in the a tag and determine the link in the middle of the attribute. Remove the number after the link, where you can use regular expressions to match.Since the code for the Shenzhen Stock Exchange starts with sz and the code for the Shanghai Stock Exchange starts with sh and the number of shares is composed of six digits, the regular expression can be written as [s][hz]\d{6}.That is, construct a regular expression, find the string that satisfies the regular expression in the link, and extract it.The code is as follows:
for i in a: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
2. Because there are many a tags in html, but some a tags do not have href attribute, so the above programs run with exceptions, all of the above programs have to try...except to handle the program exception, the code is as follows:
for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue
As you can see from the code above, we use the continue statement for exceptions, skip it and continue with the following statement.With the above program, we can save all the code information of the stock on Oriental Wealth Online.
Encapsulate the above code as a function, and the complete code for the Oriental Wealth Web page parsing is as follows:
def getStockList(lst, stockURL): html = getHTMLText(stockURL) soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue
Next is to get Baidu Stock Network Link Description Information about individual stocks.Let's first look at the source code for this page, as shown in the following figure:

The information for the stock exists in the html code shown above, so we need to parse this html code.The process is as follows:
1. The web address of Baidu Stock Net is: https://gupiao.baidu.com/stock/
A stock info is available at https://gupiao.baidu.com/stock/sz300023.html
So as long as the website address of Baidu Stock Net + the code of each stock, and the code of each stock has been parsed out by the previous program getStockList from Eastern Wealth Net, so we can traverse the list returned by the getStockList function, the code is as follows:
for stock in lst: url = stockURL + stock + ".html"
2. After you get the web address, you need to visit the web page to get the html code of the web page. The program is as follows:
html = getHTMLText(url)
3. Once you get the html code, you need to parse the html code. From the figure above, we can see that the information of a single stock is stored in the html code labeled div and attributed stock-bets, so we can parse it:
soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div',attrs={'class':'stock-bets'})
4. We also found that the stock name is in the bets-name tag, continue to parse, and put it in the dictionary:
infoDict = {} name = stockInfo.find_all(attrs={'class':'bets-name'})[0] infoDict.update({'Stock Name': name.text.split()[0]})
split() means that the part after the space in the stock name is not needed.
5. We can also see from the html code that other information about the stock is stored in the dt and dd tags, where dt represents the key domain of the stock information, and dd tags are the value domain.Get all keys and values:
keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd')
And put the way the key and value key value pairs are obtained into the dictionary:
for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val
6. Finally, store the data in the dictionary in an external file:
with open(fpath, 'a', encoding='utf-8') as f: f.write( str(infoDict) + '\n' )
Encapsulate the above process as a completed function with the following code:
def getStockInfo(lst, stockURL, fpath): for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html=="": continue infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div',attrs={'class':'stock-bets'}) name = stockInfo.find_all(attrs={'class':'bets-name'})[0] infoDict.update({'Stock Name': name.text.split()[0]}) keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f: f.write( str(infoDict) + '\n' ) except: continue
Where try...except is used for exception handling.
Next, write the main function and call the above function:
def main(): stock_list_url = 'http://quote.eastmoney.com/stocklist.html' stock_info_url = 'https://gupiao.baidu.com/stock/' output_file = 'D:/BaiduStockInfo.txt' slist=[] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file)
Project Complete Program
# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockURL): html = getHTMLText(stockURL) soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue def getStockInfo(lst, stockURL, fpath): count = 0 for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html=="": continue infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div',attrs={'class':'stock-bets'}) name = stockInfo.find_all(attrs={'class':'bets-name'})[0] infoDict.update({'Stock Name': name.text.split()[0]}) keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f: f.write( str(infoDict) + '\n' ) count = count + 1 print("\r Current Progress: {:.2f}%".format(count*100/len(lst)),end="") except: count = count + 1 print("\r Current Progress: {:.2f}%".format(count*100/len(lst)),end="") continue def main(): stock_list_url = 'http://quote.eastmoney.com/stocklist.html' stock_info_url = 'https://gupiao.baidu.com/stock/' output_file = 'D:/BaiduStockInfo.txt' slist=[] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file) main()
The print statement in the code above is used to print the progress of the crawl.After executing the above code, the BaiduStockInfo.txt file appears on the D disk, which stores the information of the stock.