Association
A coroutine is also called a microthread. A coroutine is a user-mode lightweight thread.
The coroutine has its own registers and stacks. When the co-process scheduling switch, the register context and stack are saved elsewhere. When the switch comes back, it restores to the previously saved register context and stack. Therefore, the co-process can retain the state of the last call, and each process reentry is equivalent to the state of the last call.
Benefits of the consortium:
1. Overhead without thread context switching (or single thread)
2. The overhead of locking and synchronization without atomic operations (the process of changing a thread to a variable is called atomic operations)
3. Convenient switching of control flow and simplified programming model
4. High concurrency + High Extension + Low Cost: A cpu that supports tens of thousands of protocols is all right and suitable for high concurrency processing
Disadvantages:
1. Unable to utilize multi-core resources, the process itself is a single thread. It can not simultaneously use multi-core of a single cpu. The process needs to cooperate with the process in order to apply to multi-cpu (the process is running on the process)
2. Blocking operations block the entire program: for example, io
An example of using yield to implement a protocol:
import time import queue def consumer(name): print("---->start eating baozi......") while True: #yield By default, you can return data and go to yield The whole program returns, yield You can also receive data when awakened. #Enter Dead Cycle Encounters yield Suspend until awakened print new_baozi = yield print("[%s] is eating baozi %s" %(name,new_baozi)) #time.sleep(2) def producer(): #__next__()Calling on consumers next,consumer If called directly, it will not be executed for the first time and will become a generator. #Function if it has yield The first parenthesized call, which is a generator, has not yet been implemented.__next__()Will execute r = con.__next__() r = con2.__next__() n = 0 while n<5: n += 1 #send There are two functions: wake up the generator while transmitting a value, which is yield Received values new_baozi con.send(n) con2.send(n)
#time.sleep(1) print("\033[32;1m[producer]\033[0m is making baozi %s" %n) if __name__ == '__main__': con = consumer("c1") con2 = consumer("c2") p = producer()
The whole process is a simple protocol implemented by yield. In the process of running the program, it directly completes the operation and feels like a multi-concurrent effect.
Question: They seem to be able to achieve multiple concurrency because each producer does not have any sleep. If a time.sleep(1) is added to the producer, the speed will slow down.
When I encounter io operation, I switch. I operation is very time-consuming. The reason why I can handle large concurrency is that I remove the io operation, and then it becomes that only the cpu is switching in this program.
How to realize the automatic detection of io operation of the program?
greenlet
from greenlet import greenlet def tesst1(): print(12) gr2.switch() print(34) gr2.switch() def tesst2(): print(56) gr1.switch() print(78) gr1 = greenlet(tesst1)#Start a consortium gr2 = greenlet(tesst2) gr1.switch()#Manual switching
Operation results:

greenlet is still switching manually
gevent
Gevent is a third-party library, which can easily implement concurrent synchronous or asynchronous programming through gevent. The main mode used in gevent is Greenlet, which is a lightweight protocol that accesses python in the form of c extension module. Greenlet runs entirely within the main operating system process, but they are scheduled collaboratively
import gevent def foo(): print("Running in foo") gevent.sleep(2) print("Explicit context switch to foo again") def bar(): print("Explicit context to bar") gevent.sleep(1) print("Implicit context to switch back to bar") gevent.joinall( [ gevent.spawn(foo), gevent.spawn(bar), ] )
Operation results:

Running the whole system also runs for 2 seconds, simulating the io operation
Now let's make a simple little reptile:
from urllib.request import urlopen import gevent,time def f(url): print("GET: %s "%url) resp = urlopen(url) data = resp.read() print("%d bytes received from %s." %(len(data),url)) urls = [ 'https://www.python.org/', 'https://www.yahoo.com/', 'https://github.com/' ] time_start = time.time() for url in urls: f(url) print("synchronization cost",time.time()-time_start) async_time_start = time.time() gevent.joinall([ gevent.spawn(f,'https://www.python.org/'), gevent.spawn(f,'https://www.yahoo.com/'), gevent.spawn(f,'https://github.com/') ]) print("asynchronous cost",time.time()-time_start)
We use synchronous and asynchronous methods to crawl web pages, but the result is that synchronous time is shorter than asynchronous time. We used gevent.sleep (1) to simulate io operation, and completed the task by the way. The reason is: gevent call urllib is blocked by default, gevent can not detect the io operation of urllib, so it will not switch, so it is still running in serial.
So how can gevent know that urllib is an io operation, using a module monkey?
from urllib.request import urlopen import gevent,time from gevent import monkey monkey.patch_all()#Put all of the current program in place io Operate a separate sitting mark def f(url): print("GET: %s "%url) resp = urlopen(url) data = resp.read() print("%d bytes received from %s." %(len(data),url)) urls = [ 'https://www.python.org/', 'https://www.yahoo.com/', 'https://github.com/' ] time_start = time.time() for url in urls: f(url) print("synchronization cost",time.time()-time_start) async_time_start = time.time() gevent.joinall([ gevent.spawn(f,'https://www.python.org/'), gevent.spawn(f,'https://www.yahoo.com/'), gevent.spawn(f,'https://github.com/') ]) print("asynchronous cost",time.time()-async_time_start)
So the speed of asynchronous crawling is much faster in an instant.
Next we are writing a socket server and client using gevent:
Server side:
1 import sys,socket,time,gevent 2 3 from gevent import socket,monkey 4 monkey.patch_all() 5 6 def server(port): 7 s = socket.socket() 8 s.bind(('0.0.0.0',port)) 9 s.listen(500) 10 while True: 11 cli,addr = s.accept() 12 gevent.spawn(handle_request,cli) 13 def handle_request(conn): 14 try: 15 while True: 16 data = conn.recv(1024) 17 print("recv:",data) 18 conn.send(data) 19 if not data: 20 conn.shutdown(socket.SHUT_WR) 21 except Exception as e: 22 print(e) 23 finally: 24 conn.close() 25 26 if __name__ == '__main__': 27 server(8001)
Similar to socketserver, data is processed in handle_request function, and then a gevent is created in server.
Client:
1 import socket 2 HOST = 'localhost' 3 PORT = 8001 4 s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 5 s.connect((HOST,PORT)) 6 while True: 7 msg = bytes(input(">>>:"),encoding="utf-8") 8 s.sendall(msg) 9 data = s.recv(1024) 10 #repr Format output 11 print("Recv:",repr(data)) 12 s.close()
Operation results:
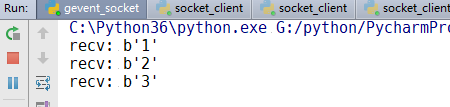
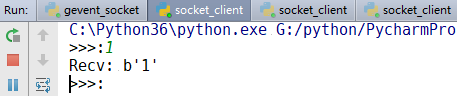

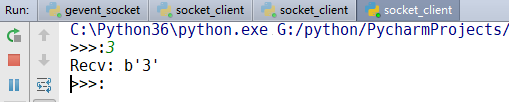
As can be seen from the above results, we have implemented concurrent operation, and do not need to use any multi-threading. We use a coordinator, and when we encounter io, we block it.
Now we have implemented the switch, but when do we switch back? How do we know when the thing of this function is finished and switch to the original function?
Event Driven and Asynchronous IO
Usually, when we write programs for server processing models, there are several models:
1. Every time a request is received, a new process is created to handle the change request, such as socketserver.
2. For each request received, create a new thread to process the request: for example, socketserver
3. Put a list of events into each request and let the main process process process process requests through non-blocking I/O mode, i.e. event-driven mode, which is adopted by most network servers.
In ui programming, we often have to respond to mouse clicks. How can we get mouse clicks?
Currently, most UI programming is event-driven. For example, many UI platforms provide onclick() events, which represent mouse-down events. The general idea of event-driven model is as follows:
1. There is an event queue
2. When the mouse is pressed, add a click event to the queue
3. There is a loop that constantly takes events out of the queue and calls different functions according to different events, such as onclick (), onkeydown(), etc.
4. Events (messages) generally have their own handler pointers, so that each message has its own handler.
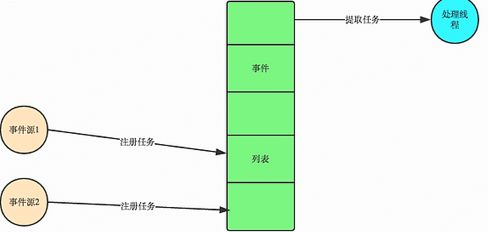
So let's go back to the above question, when do I switch back? We can register a callback function, which is to switch when your program encounters an io operation, and then wait for the io operation to end and switch back. The io operation is performed by the operating system. It's driven by this event.
Writing is not too good, I hope you will include QAQ more.