container
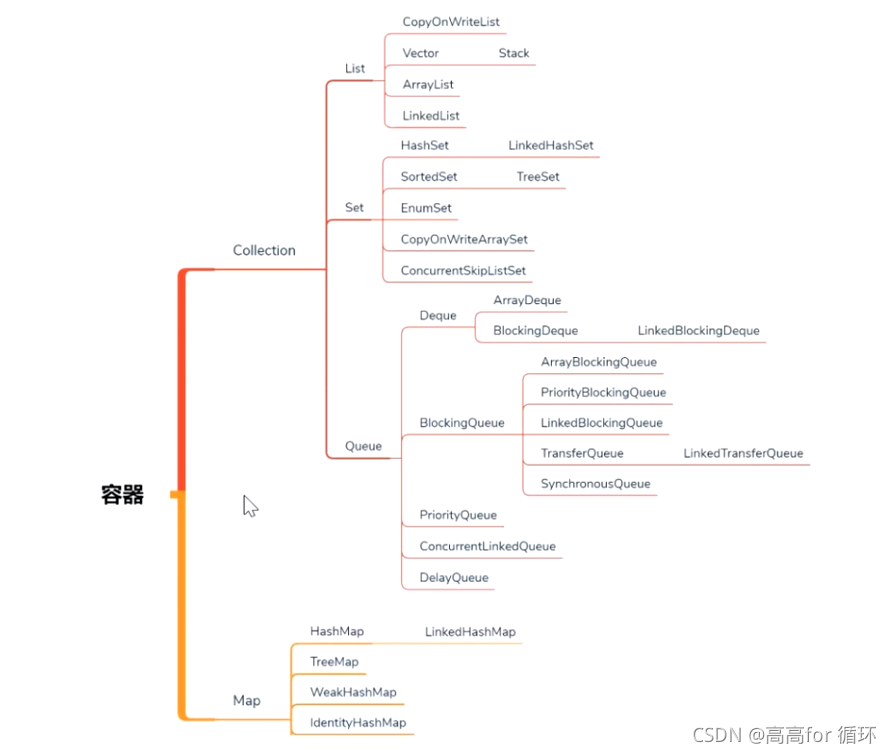
java containers fall into two categories
- The first category: Collection is called Collection
- The second category: Map
Collection collection
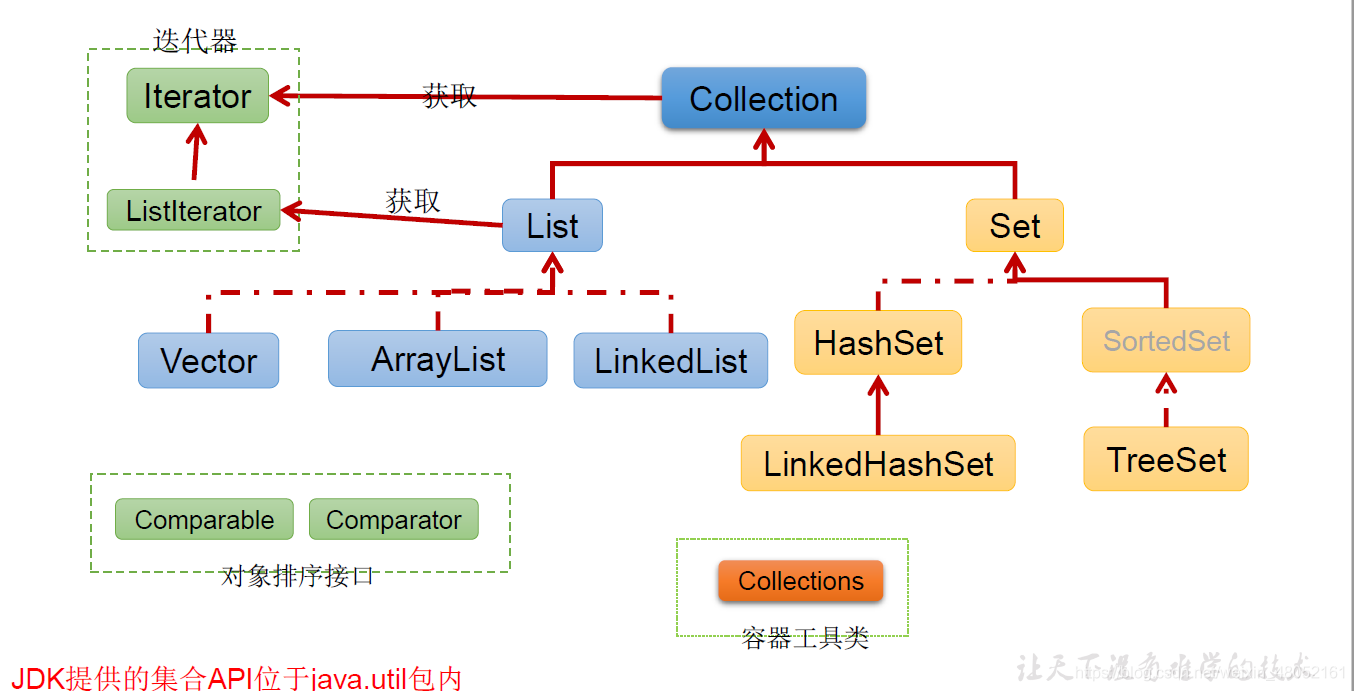
The first type of Collection is called Collection. Set means that no matter what the structure of your container is, you can throw one element into it one by one;
Map
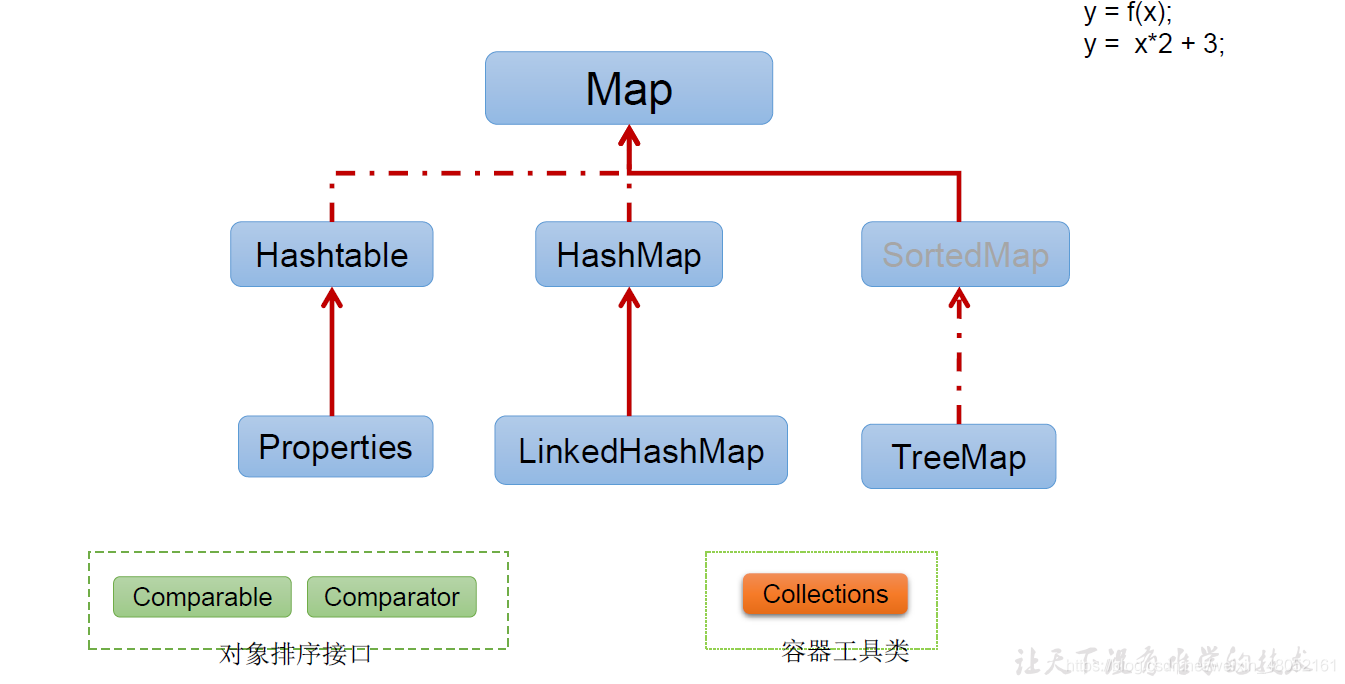
The second category is Map: Map is a one-to-one throwing in, kv structure. In fact, for Map, it can be seen that it is a special variant of Collection. You can regard a pair of objects as an entry object, so it is also an entire object. Containers are collections that hold objects one by one. Strictly speaking, arrays also belong to containers.
From the perspective of data structure:
From the perspective of data structure, there are only two kinds of physical data structures,
- One is the Array of continuous storage
- The other is a linked list of discontinuous storage pointing to another. In the logical structure, there are many.
Collection s fall into three categories
- list
- set
- Queue
Queue queue
A Queue is one-to-one. When fetching data from this Queue, it is different from the List and Set. As we all know, if the List is an Array, you can also get one of them. The main difference between Set and others is that the middle is unique and there will be no duplicate elements. This is its main difference. What logic does Queue implement? In fact, it is a Queue,
Queue has the concept of "in and out". On this basis, it implements many multi-threaded access methods (such as put blocking and take blocking). This is not available in other lists and sets. The main reason for queue is to load tasks. The most important one is called blocking queue. Its original purpose is to prepare for thread pool and high concurrency. The original containers are ordinary and prepared to hold things.
The difference between list, set and Queue
- Queue implements many multi-threaded access methods (such as put blocking and take blocking). This is not available in other lists and sets.
- Different original intention: the original intention of queue implementation is to prepare for thread pool and high concurrency. The original list and set containers are ordinary to prepare for loading.
JDK container development history
- java1.0-----Vector,Hashtable(synchronized)
- list, set, HashMap (no lock)
- Collections tool classes ------ SynchronizedList, synchronizedMap
- Queue, ConcurrentHashMap (high concurrency)
1. Vector,Hashtable
Vector and Hashtable have their own locks, which are basically unnecessary. Remember this conclusion.
- At first, there were only two Java 1.0 containers. The first one was called vector, which could be thrown into the container alone, and the other was Hashtable, which could be thrown into the container one by one. Vector implements the List interface, while Hashtable implements the Map interface. However, there was a slight problem in the design of these two containers in 1.0. These two containers are designed so that all methods are synchronized by default, which is the first unreasonable design. Most of the time, most of our programs have only one thread working, so in this case, you don't need to add synchronized, so the performance of the design is poor at the beginning,
2. list,set ,HashMap
- After the Hashtable, a HashMap is added. The HashMap is completely unlocked. One is to lock without saying a word, and the other is not locked at all. In addition to the lock difference, there are other source code differences between the two, so Sun added another one on the basis of the HashMap at that time, saying that the new HashMap you use is easier to use than the original Hashtable, but the HashMap does not have the things of those locks,
3. SynchronizedList,synchronizedMap
Map<> map = Collections.synchronizedMap(new HashMap<>());
- So how can this HashMap be used not only in environments that do not need locks, but also in environments that need locks? Therefore, it adds a method called Collections, which is equivalent to the tool class of the container. In this tool class, there is a method called synchronizedMap, which will turn it into a locked version. Therefore, HashMap has two versions.
4. ConcurrentHashMap
map container - efficiency comparison
The efficiency is high and the efficiency is low. Don't take it for granted. Be sure to write a program to test (pressure test)
Prepare data: 1 million UUID pairs, 100 threads
- The containers are filled with Key,Value pairs, one-to-one pairs. The Key is UUID, and the Value is also UUID, which is equal to a new Hashtable. How many UUIDs are there? I have defined two Constants. These two Constants are in a separate class. This class is called Constants: 1 million UUIDs. There will be 100 threads to load the contents into the container. In the future, there will be 100 threads to simulate when we visit.
public class Constants {
public static final int COUNT = 1000000;
public static final int THREAD_COUNT = 100;
}
Programming:
- Looking at the program, I first new out 1 million keys and 1 million values, and then put these things into the array, for loop (int i = 0; I < count; I + +). Why prepare these UUID pairs first instead of generating them on site when we install them? The reason is that when we write this test case, we use the same before and after. When you load it into the Hashtable, you have to use the 1 million pairs of the same content, but if you generate different content every time, in this case, there will be some interference factors in your test, so we are ready to throw it in first.
- Later, i wrote a Thread class called MyThread, which inherits from Thread. Start and gap are how many threads are responsible for loading into it. The Thread began to throw in. After looking at the main program code, record the start time, and new comes out with a Thread array. The Thread data has a total of 100 threads. Initialize it. Since you need to specify the start value, i times count when the MyThread starts (in a word, the starting value is different. The first Thread starts from 0 and the second starts from 100000). It doesn't matter if you don't use it. It's a good habit to record it when you use it. Then start each Thread, wait for each Thread to end, and finally calculate the Thread time.
- Now I have a Hashtable, which contains one-to-one contents. Now we have 100 threads. The 100 threads go to Key and Value to get data, and one thread takes 10000 data. A total of 1 million data, 100 threads, and each thread takes 10000 data to insert. The whole program simulates this situation
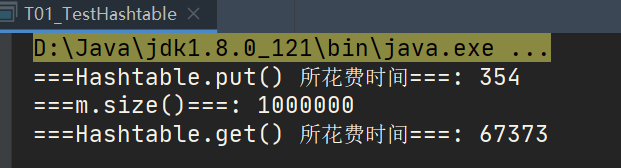
TestHashtable
package c_023_02_FromHashtableToCHM;
import java.util.Hashtable;
import java.util.UUID;
public class T01_TestHashtable {
static Hashtable<UUID, UUID> m = new Hashtable<>();
static int count = Constants.COUNT;
static UUID[] keys = new UUID[count];
static UUID[] values = new UUID[count];
static final int THREAD_COUNT = Constants.THREAD_COUNT;
static {
for (int i = 0; i < count; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
static class MyThread extends Thread {
int start;
int gap = count/THREAD_COUNT;
public MyThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i=start; i<start+gap; i++) {
m.put(keys[i], values[i]);
}
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i=0; i<threads.length; i++) {
threads[i] =
new MyThread(i * (count/THREAD_COUNT));
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println("===Hashtable.put() Time spent===: "+ (end - start));
System.out.println("===m.size()===: "+m.size());
//-----------------------------------
start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j = 0; j < 10000000; j++) {
m.get(keys[10]);
}
});
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
end = System.currentTimeMillis();
System.out.println("===Hashtable.get() Time spent===: "+(end - start));
}
}
HashMap
- Let's take a look at this HashMap. Students think about whether there is a problem inserting this HashMap into it. Because HashMap has no lock and the thread is not safe, this is meaningless. It is only for the integrity of the program. Although it is fast, there will be problems with the data and various exceptions. This is mainly because it will turn this into a TreeNode internally. We won't study it carefully first. In a word, when you throw HashMap into it, there will be problems when you access it through multiple threads because it has no internal lock. This has no practical meaning when you insert it.
package c_023_02_FromHashtableToCHM;
import java.util.HashMap;
import java.util.UUID;
public class T02_TestHashMap {
static HashMap<UUID, UUID> m = new HashMap<>();
static int count = Constants.COUNT;
static UUID[] keys = new UUID[count];
static UUID[] values = new UUID[count];
static final int THREAD_COUNT = Constants.THREAD_COUNT;
static {
for (int i = 0; i < count; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
static class MyThread extends Thread {
int start;
int gap = count/THREAD_COUNT;
public MyThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i=start; i<start+gap; i++) {
m.put(keys[i], values[i]);
}
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i=0; i<threads.length; i++) {
threads[i] =
new MyThread(i * (count/THREAD_COUNT));
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println(m.size());
}
}
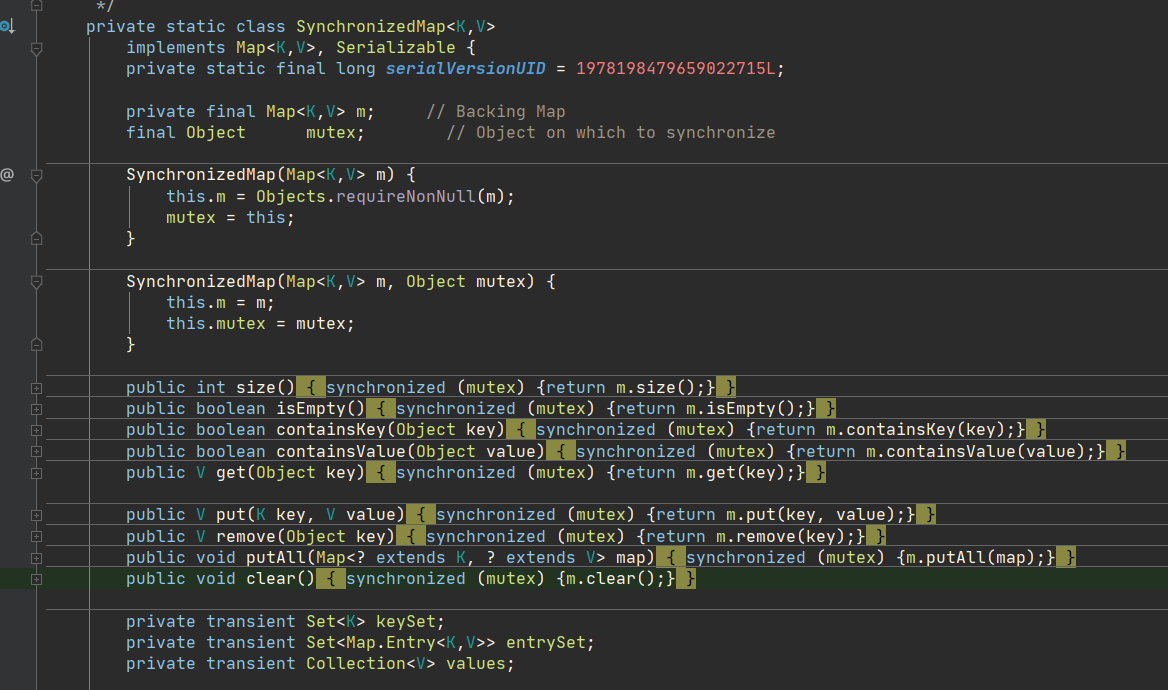
SynchronizedHashMap
- We are looking at the third one. We use the synchronized map method to manually lock the HashMap. Its source code makes an Object itself, and then it is synchronized Object every time. Strictly speaking, it is not different from that Hashtable in efficiency.
package c_023_02_FromHashtableToCHM;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
public class T03_TestSynchronizedHashMap {
static Map<UUID, UUID> m = Collections.synchronizedMap(new HashMap<UUID, UUID>());
static int count = Constants.COUNT;
static UUID[] keys = new UUID[count];
static UUID[] values = new UUID[count];
static final int THREAD_COUNT = Constants.THREAD_COUNT;
static {
for (int i = 0; i < count; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
static class MyThread extends Thread {
int start;
int gap = count/THREAD_COUNT;
public MyThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i=start; i<start+gap; i++) {
m.put(keys[i], values[i]);
}
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i=0; i<threads.length; i++) {
threads[i] =
new MyThread(i * (count/THREAD_COUNT));
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println("===SynchronizedHashMap.put() Time spent===: "+ (end - start));
System.out.println("===m.size()===: "+m.size());
//-----------------------------------
start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j = 0; j < 10000000; j++) {
m.get(keys[10]);
}
});
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
end = System.currentTimeMillis();
System.out.println("===SynchronizedHashMap.get() Time spent===: "+(end - start));
}
}
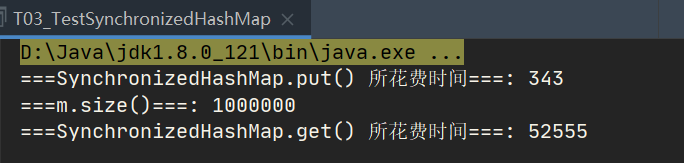
Look at the results. Strictly speaking, the synchronized HashMap has little difference in efficiency from the Hashtable.
ConcurrentHashMap
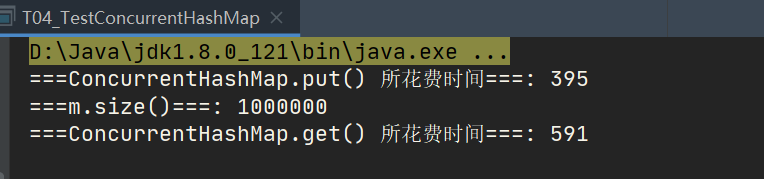
- The fourth ConcurrentHashMap is really used in multithreading. In the future, it is basically used by multithreading. When using Map. Concurrent.
- The efficiency of this ConcurrentHashMap is mainly improved by reading it. When it is inserted, it makes various internal judgments. It was originally a linked list, but after 8, it becomes a red black tree, and then it makes various cas judgments. Therefore, the data it inserts is lower.
- Although HashMap and Hashtable say that the reading efficiency will be slightly lower, they check very few things when inserting them, so they add a lock and insert them. So, about efficiency, it depends on your actual needs. With a few simple small programs to give you a list of these different differences.
package c_023_02_FromHashtableToCHM;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.ConcurrentHashMap;
public class T04_TestConcurrentHashMap {
static Map<UUID, UUID> m = new ConcurrentHashMap<>();
static int count = Constants.COUNT;
static UUID[] keys = new UUID[count];
static UUID[] values = new UUID[count];
static final int THREAD_COUNT = Constants.THREAD_COUNT;
static {
for (int i = 0; i < count; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
static class MyThread extends Thread {
int start;
int gap = count/THREAD_COUNT;
public MyThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i=start; i<start+gap; i++) {
m.put(keys[i], values[i]);
}
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i=0; i<threads.length; i++) {
threads[i] =
new MyThread(i * (count/THREAD_COUNT));
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println("===ConcurrentHashMap.put() Time spent===: "+(end - start));
System.out.println("===m.size()===: "+m.size());
//-----------------------------------
start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j = 0; j < 10000000; j++) {
m.get(keys[10]);
}
});
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
end = System.currentTimeMillis();
System.out.println("===ConcurrentHashMap.get() Time spent===: "+(end - start));
}
}
Collection container - efficiency comparison
Ticket buying cases
- There are N train tickets, each with a number
- At the same time, there are 10 windows for ticket sales
ArrayList
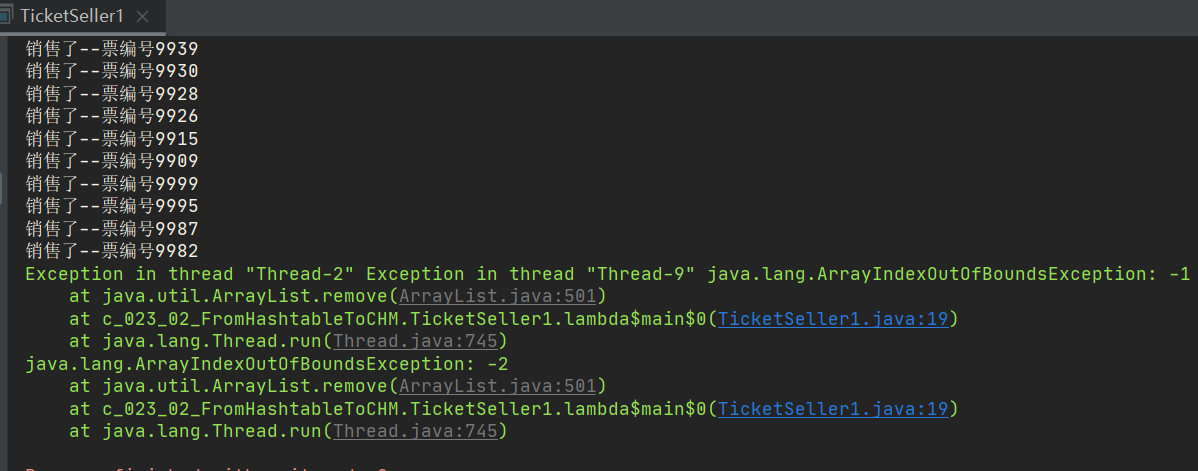
- The writing method is relatively simple. First, we use a List to load all these tickets, and then load 10000 tickets into it. Then, 10 threads, that is, 10 windows, are sold to the outside. As long as the size is greater than zero, as long as there are remaining tickets, I will go to take out and take one to remove.
- Imagine that when the last ticket arrives, several threads execute here, so all threads find that the size is greater than zero, and all threads buy a ticket. What happens? Only one thread gets the ticket, and others get null value, which is oversold. Without locking, the thread is not safe.
import java.util.ArrayList;
import java.util.List;
public class TicketSeller1 {
static List<String> tickets = new ArrayList<>();
static {
for(int i=0; i<10000; i++) tickets.add("Ticket No" + i);
}
public static void main(String[] args) {
for(int i=0; i<10; i++) {
new Thread(()->{
while(tickets.size() > 0) {
System.out.println("Sold--" + tickets.remove(0));
}
}).start();
}
}
}
Vector
- Let's take a look at the earliest container Vector, which has its own lock. When you read it, you will see many methods synchronized. Lock it first without saying a word, so when you use Vector, please rest assured that it must be thread safe. With 100 tickets and 10 windows, there is still a problem reading this program, which is still wrong.
- For thread safety, the lock is added when we call the size method, and it is also locked when we call remove. Unfortunately, it is not locked between you. Then, many threads will judge that the size is still greater than 0, and the big guy is oversold again.
import java.util.Vector;
import java.util.concurrent.TimeUnit;
public class TicketSeller2 {
static Vector<String> tickets = new Vector<>();
static {
for(int i=0; i<10000; i++) tickets.add("Ticket No" + i);
}
public static void main(String[] args) {
for(int i=0; i<10; i++) {
new Thread(()->{
while(tickets.size() > 0) {
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Sold--" + tickets.remove(0));
}
}).start();
}
}
}

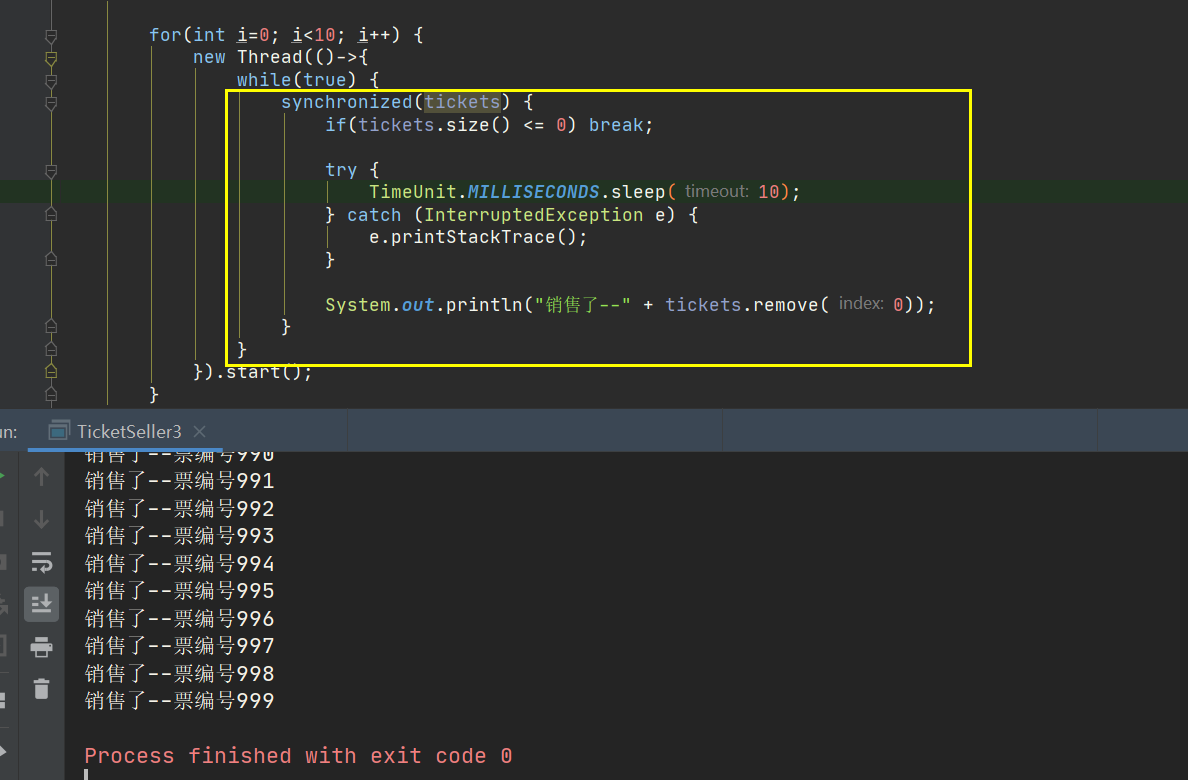
Correct writing
- Although you have used the locked container, you have called two atomic methods when you call the concurrent container, so you have to add a lock synchronized(tickets) in the outer layer, continue to judge the size, and continue to remove after selling. This is no problem. It will be sold out steadily, but it is not the most efficient solution
package c_023_02_FromHashtableToCHM;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.TimeUnit;
public class TicketSeller3 {
static List<String> tickets = new LinkedList<>();
static {
for(int i=0; i<1000; i++) tickets.add("Ticket No" + i);
}
public static void main(String[] args) {
for(int i=0; i<10; i++) {
new Thread(()->{
while(true) {
synchronized(tickets) {
if(tickets.size() <= 0) break;
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Sold--" + tickets.remove(0));
}
}
}).start();
}
}
}
Queue
In the case of high concurrency and multithreading, Queue should be considered when a single element operates.
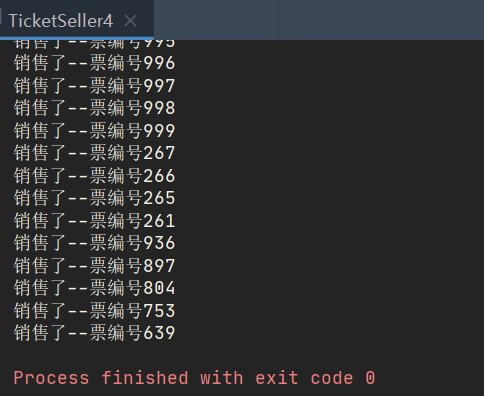
- The most efficient is the Queue, which is the latest interface. Its main goal is to use it for high concurrency and multithreading. Therefore, in the future, when considering a single element such as multithreading, think more about Queue.
- Let's look at the initialization in the program. This uses ConcurrentLinkedQueue, and then there is no lock in it. I directly call a method called poll, which means I get the value from tickets. When this value is empty, it means that the value in it has disappeared, so this while(true) is constantly sold out, Until he suddenly found that there was nothing in it when he reached for the ticket, so I could close the window without buying a ticket.
poll()
- poll means that it adds many methods that are more friendly to multithreading access. Its source code, take it down to get the header on our queue and the element on our head, and get and remove the value in it,
- If this is already empty, I return a null value.
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
public class TicketSeller4 {
static Queue<String> tickets = new ConcurrentLinkedQueue<>();
static {
for(int i=0; i<1000; i++) tickets.add("Ticket No" + i);
}
public static void main(String[] args) {
for(int i=0; i<10; i++) {
new Thread(()->{
while(true) {
String s = tickets.poll();
if(s == null) break;
else System.out.println("Sold--" + s);
}
}).start();
}
}
}
Summary:
Therefore, the eight small programs just mentioned are mainly to explain to you what the overall evolution process looks like. From the perspective of Map, the earliest is from Hashtable, not to mention adding locks to HashMap, removing locks, and then adding a locked version to synchronized HashMap, which is dedicated to concurrent HashMap multithreading.
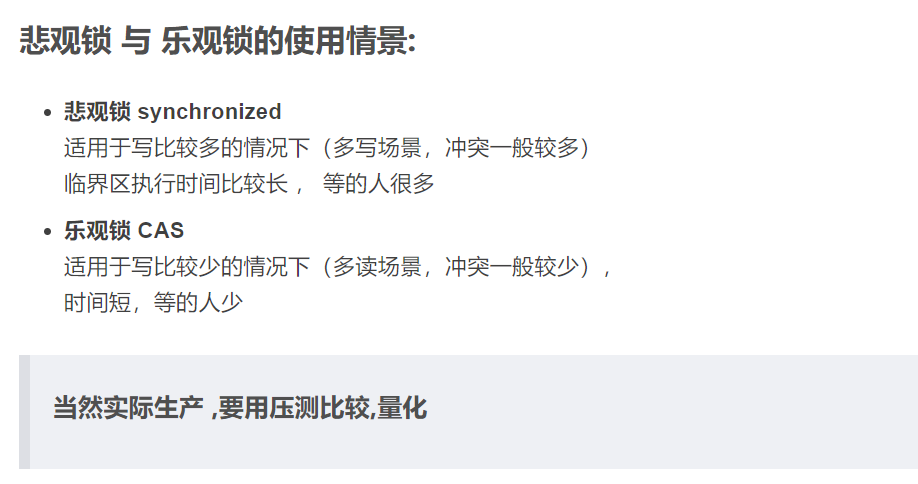
At any time, in your actual situation, you need to determine which container to use through test and pressure test.
- Note that it is not a substitution relationship. In the final analysis, this will come down to whether cas operation must be more efficient than synchronized. Not necessarily, it depends on your concurrency and the code execution time after you lock. You need to decide which container to use through testing and pressure testing at any time.
Interface oriented programming
- Why interface oriented programming? If you design a program in your work, you should design an interface. This interface only includes business logic. Take out the student list and put it. But is the specific implementation of the list put in Hashtable, HashMap or ConcurrentHashMap, You can write several different implementations and use different implementations in different concurrent situations. Your program will be more flexible. Can you understand the subtlety of this interface oriented programming and interface oriented design.