First of all, I declare that the so-called programming mode in the title is a process control programming mode that I personally consider in the cluster environment of cross-node (jvm). It is conceived purely according to actual needs and has no theoretical support. In May, I shared some ideas about programming mode in cluster environment on scala meetup in Shenzhen. I provided the following schematic diagram:
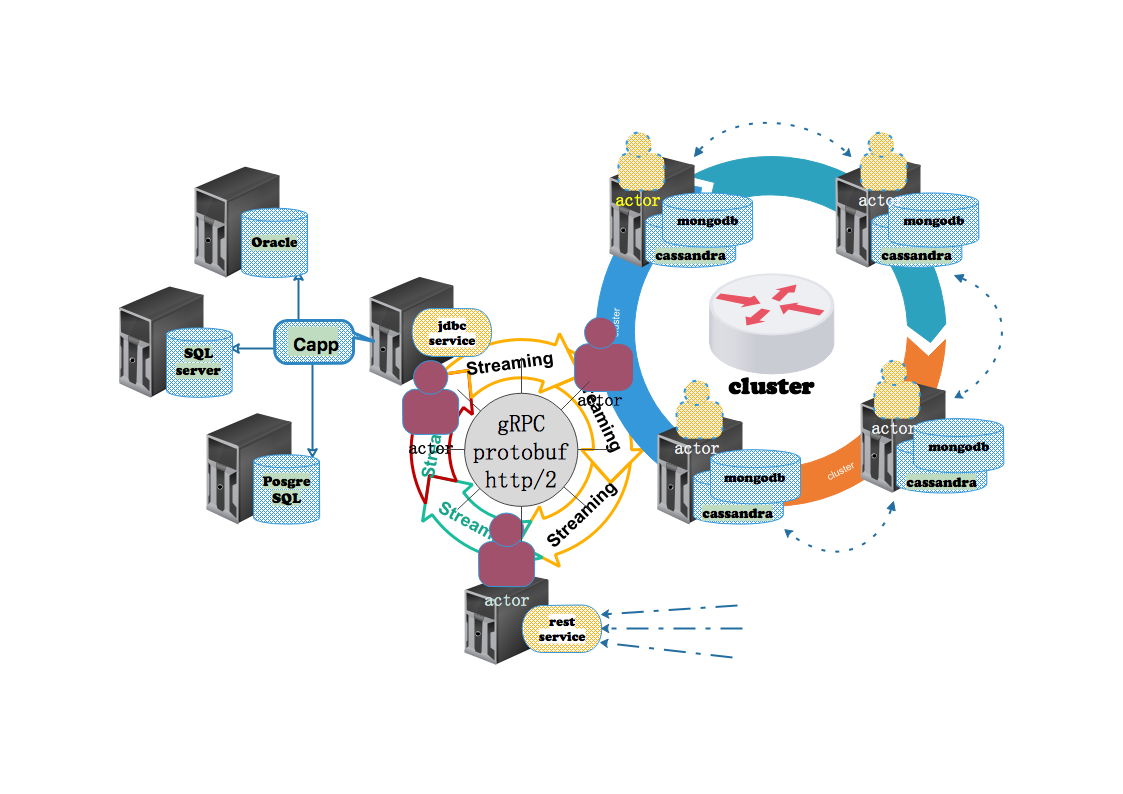
The figure above is the network structure of "Modern Enterprise I.T Integrated Data Platform" which I am discussing. Because the information system in the Internet economy must add large data elements, in addition to the traditional transaction type jdbc database, distributed database cassandra and mongodb are also added. Because jdbc database does not support distributed computing mode, it is separated from the cluster environment from the perspective of data exchange: jdbc data can not be obtained from any node in the cluster. So only one service based on HTTP can provide data to other nodes. I first considered akka-http, contacted gRPC in the preparation process, and found that gRPC is more suitable for program control across jvm, mainly because gRPC supports two-way flow control. I think that if we further extend the flow elements into program instructions, we should be able to control the flow of the program. In the previous chapters, we have implemented the integration of gRPC and akka-stream: so we can achieve an interactive data exchange through akka-stream. So streaming is the programming pattern mentioned above in the title. This idea can be understood from the sketch above.
In this discussion, we will validate the implementation of gRPC services through JDBC Streaming. Refer to JDBC-Streaming for details on how to implement and use JDBC-Streaming. Previous blogs . Let's start then. First, we demonstrate a traditional Unary(request/response) mode implementation: a Query instruction is issued from the client to the server, and the server returns DataRows from the JDBC database according to the instruction. JDBC Streaming operates as follows:
val ctx = JDBCQueryContext[JDBCDataRow](
dbName = Symbol(q.dbName),
statement = q.statement,
parameters = params,
fetchSize = q.fetchSize.getOrElse(100),
autoCommit = q.autoCommit.getOrElse(false),
queryTimeout = q.queryTimeout
)
jdbcAkkaStream(ctx, toRow)
There are two types of data exchange across platforms: JDBC QueryContext and JDBC DataRow, which we need to convert to protobuf type to sequence/reverse order. The following is the corresponding IDL definition in the. proto file:
message JDBCDataRow {
string year = 1;
string state = 2;
string county = 3;
string value = 4;
}
message JDBCQuery {
string dbName = 1;
string statement = 2;
bytes parameters = 3;
google.protobuf.Int32Value fetchSize= 4;
google.protobuf.BoolValue autoCommit = 5;
google.protobuf.Int32Value queryTimeout = 6;
}
service JDBCServices {
rpc runQuery(JDBCQuery) returns (stream JDBCDataRow) {}
}
Note that we correspond the Seq[Any]] type to the bytes type. This avoids the complex operation of protobuf,Any type. scalaPB automatically maps the bytes type to ByteString as follows:
parameters: _root_.com.google.protobuf.ByteString = _root_.com.google.protobuf.ByteString.EMPTY,
Below is the sequence/deserialization operation function of ByteString:
package protobuf.bytes
import java.io.{ByteArrayInputStream,ByteArrayOutputStream,ObjectInputStream,ObjectOutputStream}
import com.google.protobuf.ByteString
object Converter {
def marshal(value: Any): ByteString = {
val stream: ByteArrayOutputStream = new ByteArrayOutputStream()
val oos = new ObjectOutputStream(stream)
oos.writeObject(value)
oos.close()
ByteString.copyFrom(stream.toByteArray())
}
def unmarshal[A](bytes: ByteString): A = {
val ois = new ObjectInputStream(new ByteArrayInputStream(bytes.toByteArray))
val value = ois.readObject()
ois.close()
value.asInstanceOf[A]
}
}
The gRPC-JDBC server reconstructs the JDBC Query Context according to the JDBC Query passed from the client, and then uses the Context to generate an akka-stream Flow [JDBC Query, JDBC Data Row, NotUsed]. The implementation of the whole runQuery service function is as follows:
class JDBCStreamingServices(implicit ec: ExecutionContextExecutor) extends JdbcGrpcAkkaStream.JDBCServices {
val logger = Logger.getLogger(classOf[JDBCStreamingServices].getName)
val toRow = (rs: WrappedResultSet) => JDBCDataRow(
year = rs.string("REPORTYEAR"),
state = rs.string("STATENAME"),
county = rs.string("COUNTYNAME"),
value = rs.string("VALUE")
)
override def runQuery: Flow[JDBCQuery, JDBCDataRow, NotUsed] = {
logger.info("**** runQuery called on service side ***")
Flow[JDBCQuery]
.flatMapConcat { q =>
//unpack JDBCQuery and construct the context
val params: Seq[Any] = unmarshal[Seq[Any]](q.parameters)
logger.info(s"**** query parameters: ${params} ****")
val ctx = JDBCQueryContext[JDBCDataRow](
dbName = Symbol(q.dbName),
statement = q.statement,
parameters = params,
fetchSize = q.fetchSize.getOrElse(100),
autoCommit = q.autoCommit.getOrElse(false),
queryTimeout = q.queryTimeout
)
jdbcAkkaStream(ctx, toRow)
}
}
}
The matching of JDBCDataRow type with JDBC data table field is also implemented. Clients need to build JDBCQuery types as follows:
val query = JDBCQuery (
dbName = "h2",
statement = "select * from AQMRPT where STATENAME = ? and VALUE = ?",
parameters = marshal(Seq("Arizona", 5))
)
Then via Flow is passed to the server for an akka-stream Source [JBC Data Row, NotUsed]:
def queryRows: Source[JDBCDataRow,NotUsed] = {
logger.info(s"running queryRows ...")
Source
.single(query)
.via(stub.runQuery)
}
Call this queryRows on the client:
object QueryRows extends App {
implicit val system = ActorSystem("QueryRows")
implicit val mat = ActorMaterializer.create(system)
val client = new JDBCStreamClient("localhost", 50051)
client.queryRows.runForeach(println)
scala.io.StdIn.readLine()
mat.shutdown()
system.terminate()
}
Here is the complete source code for this discussion:
project/scalapb.sbt
addSbtPlugin("com.thesamet" % "sbt-protoc" % "0.99.18")
resolvers += Resolver.bintrayRepo("beyondthelines", "maven")
libraryDependencies ++= Seq(
"com.thesamet.scalapb" %% "compilerplugin" % "0.7.4",
"beyondthelines" %% "grpcakkastreamgenerator" % "0.0.5"
)
build.sbt
import scalapb.compiler.Version.scalapbVersion
import scalapb.compiler.Version.grpcJavaVersion
name := "gRPCJDBCStreaming"
version := "0.11"
scalaVersion := "2.12.6"
resolvers += Resolver.bintrayRepo("beyondthelines", "maven")
libraryDependencies ++= Seq(
"com.thesamet.scalapb" %% "scalapb-runtime" % scalapbVersion % "protobuf",
"io.grpc" % "grpc-netty" % grpcJavaVersion,
"com.thesamet.scalapb" %% "scalapb-runtime-grpc" % scalapbVersion,
"io.monix" %% "monix" % "2.3.0",
// for GRPC Akkastream
"beyondthelines" %% "grpcakkastreamruntime" % "0.0.5",
// for scalikejdbc
"org.scalikejdbc" %% "scalikejdbc" % "3.2.1",
"org.scalikejdbc" %% "scalikejdbc-test" % "3.2.1" % "test",
"org.scalikejdbc" %% "scalikejdbc-config" % "3.2.1",
"org.scalikejdbc" %% "scalikejdbc-streams" % "3.2.1",
"org.scalikejdbc" %% "scalikejdbc-joda-time" % "3.2.1",
"com.h2database" % "h2" % "1.4.196",
"mysql" % "mysql-connector-java" % "6.0.6",
"org.postgresql" % "postgresql" % "42.2.0",
"commons-dbcp" % "commons-dbcp" % "1.4",
"org.apache.tomcat" % "tomcat-jdbc" % "9.0.2",
"com.zaxxer" % "HikariCP" % "2.7.4",
"com.jolbox" % "bonecp" % "0.8.0.RELEASE",
"com.typesafe.slick" %% "slick" % "3.2.1",
"ch.qos.logback" % "logback-classic" % "1.2.3",
"com.typesafe.akka" %% "akka-actor" % "2.5.4",
"com.typesafe.akka" %% "akka-stream" % "2.5.4"
)
PB.targets in Compile := Seq(
scalapb.gen() -> (sourceManaged in Compile).value,
// generate the akka stream files
grpc.akkastreams.generators.GrpcAkkaStreamGenerator() -> (sourceManaged in Compile).value
)
main/protobuf/jdbc.proto
syntax = "proto3";
import "google/protobuf/wrappers.proto";
import "google/protobuf/any.proto";
import "scalapb/scalapb.proto";
package grpc.jdbc.services;
option (scalapb.options) = {
// use a custom Scala package name
// package_name: "io.ontherocks.introgrpc.demo"
// don't append file name to package
flat_package: true
// generate one Scala file for all messages (services still get their own file)
single_file: true
// add imports to generated file
// useful when extending traits or using custom types
// import: "io.ontherocks.hellogrpc.RockingMessage"
// code to put at the top of generated file
// works only with `single_file: true`
//preamble: "sealed trait SomeSealedTrait"
};
/*
* Demoes various customization options provided by ScalaPBs.
*/
message JDBCDataRow {
string year = 1;
string state = 2;
string county = 3;
string value = 4;
}
message JDBCQuery {
string dbName = 1;
string statement = 2;
bytes parameters = 3;
google.protobuf.Int32Value fetchSize= 4;
google.protobuf.BoolValue autoCommit = 5;
google.protobuf.Int32Value queryTimeout = 6;
}
service JDBCServices {
rpc runQuery(JDBCQuery) returns (stream JDBCDataRow) {}
}
main/resources/application.conf
# JDBC settings
test {
db {
h2 {
driver = "org.h2.Driver"
url = "jdbc:h2:tcp://localhost/~/slickdemo"
user = ""
password = ""
poolInitialSize = 5
poolMaxSize = 7
poolConnectionTimeoutMillis = 1000
poolValidationQuery = "select 1 as one"
poolFactoryName = "commons-dbcp2"
}
}
db.mysql.driver = "com.mysql.cj.jdbc.Driver"
db.mysql.url = "jdbc:mysql://localhost:3306/testdb"
db.mysql.user = "root"
db.mysql.password = "123"
db.mysql.poolInitialSize = 5
db.mysql.poolMaxSize = 7
db.mysql.poolConnectionTimeoutMillis = 1000
db.mysql.poolValidationQuery = "select 1 as one"
db.mysql.poolFactoryName = "bonecp"
# scallikejdbc Global settings
scalikejdbc.global.loggingSQLAndTime.enabled = true
scalikejdbc.global.loggingSQLAndTime.logLevel = info
scalikejdbc.global.loggingSQLAndTime.warningEnabled = true
scalikejdbc.global.loggingSQLAndTime.warningThresholdMillis = 1000
scalikejdbc.global.loggingSQLAndTime.warningLogLevel = warn
scalikejdbc.global.loggingSQLAndTime.singleLineMode = false
scalikejdbc.global.loggingSQLAndTime.printUnprocessedStackTrace = false
scalikejdbc.global.loggingSQLAndTime.stackTraceDepth = 10
}
dev {
db {
h2 {
driver = "org.h2.Driver"
url = "jdbc:h2:tcp://localhost/~/slickdemo"
user = ""
password = ""
poolFactoryName = "hikaricp"
numThreads = 10
maxConnections = 12
minConnections = 4
keepAliveConnection = true
}
mysql {
driver = "com.mysql.cj.jdbc.Driver"
url = "jdbc:mysql://localhost:3306/testdb"
user = "root"
password = "123"
poolInitialSize = 5
poolMaxSize = 7
poolConnectionTimeoutMillis = 1000
poolValidationQuery = "select 1 as one"
poolFactoryName = "bonecp"
}
postgres {
driver = "org.postgresql.Driver"
url = "jdbc:postgresql://localhost:5432/testdb"
user = "root"
password = "123"
poolFactoryName = "hikaricp"
numThreads = 10
maxConnections = 12
minConnections = 4
keepAliveConnection = true
}
}
# scallikejdbc Global settings
scalikejdbc.global.loggingSQLAndTime.enabled = true
scalikejdbc.global.loggingSQLAndTime.logLevel = info
scalikejdbc.global.loggingSQLAndTime.warningEnabled = true
scalikejdbc.global.loggingSQLAndTime.warningThresholdMillis = 1000
scalikejdbc.global.loggingSQLAndTime.warningLogLevel = warn
scalikejdbc.global.loggingSQLAndTime.singleLineMode = false
scalikejdbc.global.loggingSQLAndTime.printUnprocessedStackTrace = false
scalikejdbc.global.loggingSQLAndTime.stackTraceDepth = 10
}
jdbc/JDBCConfig.scala
package sdp.jdbc.config
import scala.collection.mutable
import scala.concurrent.duration.Duration
import scala.language.implicitConversions
import com.typesafe.config._
import java.util.concurrent.TimeUnit
import java.util.Properties
import scalikejdbc.config._
import com.typesafe.config.Config
import com.zaxxer.hikari._
import scalikejdbc.ConnectionPoolFactoryRepository
/** Extension methods to make Typesafe Config easier to use */
class ConfigExtensionMethods(val c: Config) extends AnyVal {
import scala.collection.JavaConverters._
def getBooleanOr(path: String, default: => Boolean = false) = if(c.hasPath(path)) c.getBoolean(path) else default
def getIntOr(path: String, default: => Int = 0) = if(c.hasPath(path)) c.getInt(path) else default
def getStringOr(path: String, default: => String = null) = if(c.hasPath(path)) c.getString(path) else default
def getConfigOr(path: String, default: => Config = ConfigFactory.empty()) = if(c.hasPath(path)) c.getConfig(path) else default
def getMillisecondsOr(path: String, default: => Long = 0L) = if(c.hasPath(path)) c.getDuration(path, TimeUnit.MILLISECONDS) else default
def getDurationOr(path: String, default: => Duration = Duration.Zero) =
if(c.hasPath(path)) Duration(c.getDuration(path, TimeUnit.MILLISECONDS), TimeUnit.MILLISECONDS) else default
def getPropertiesOr(path: String, default: => Properties = null): Properties =
if(c.hasPath(path)) new ConfigExtensionMethods(c.getConfig(path)).toProperties else default
def toProperties: Properties = {
def toProps(m: mutable.Map[String, ConfigValue]): Properties = {
val props = new Properties(null)
m.foreach { case (k, cv) =>
val v =
if(cv.valueType() == ConfigValueType.OBJECT) toProps(cv.asInstanceOf[ConfigObject].asScala)
else if(cv.unwrapped eq null) null
else cv.unwrapped.toString
if(v ne null) props.put(k, v)
}
props
}
toProps(c.root.asScala)
}
def getBooleanOpt(path: String): Option[Boolean] = if(c.hasPath(path)) Some(c.getBoolean(path)) else None
def getIntOpt(path: String): Option[Int] = if(c.hasPath(path)) Some(c.getInt(path)) else None
def getStringOpt(path: String) = Option(getStringOr(path))
def getPropertiesOpt(path: String) = Option(getPropertiesOr(path))
}
object ConfigExtensionMethods {
@inline implicit def configExtensionMethods(c: Config): ConfigExtensionMethods = new ConfigExtensionMethods(c)
}
trait HikariConfigReader extends TypesafeConfigReader {
self: TypesafeConfig => // with TypesafeConfigReader => //NoEnvPrefix =>
import ConfigExtensionMethods.configExtensionMethods
def getFactoryName(dbName: Symbol): String = {
val c: Config = config.getConfig(envPrefix + "db." + dbName.name)
c.getStringOr("poolFactoryName", ConnectionPoolFactoryRepository.COMMONS_DBCP)
}
def hikariCPConfig(dbName: Symbol): HikariConfig = {
val hconf = new HikariConfig()
val c: Config = config.getConfig(envPrefix + "db." + dbName.name)
// Connection settings
if (c.hasPath("dataSourceClass")) {
hconf.setDataSourceClassName(c.getString("dataSourceClass"))
} else {
Option(c.getStringOr("driverClassName", c.getStringOr("driver"))).map(hconf.setDriverClassName _)
}
hconf.setJdbcUrl(c.getStringOr("url", null))
c.getStringOpt("user").foreach(hconf.setUsername)
c.getStringOpt("password").foreach(hconf.setPassword)
c.getPropertiesOpt("properties").foreach(hconf.setDataSourceProperties)
// Pool configuration
hconf.setConnectionTimeout(c.getMillisecondsOr("connectionTimeout", 1000))
hconf.setValidationTimeout(c.getMillisecondsOr("validationTimeout", 1000))
hconf.setIdleTimeout(c.getMillisecondsOr("idleTimeout", 600000))
hconf.setMaxLifetime(c.getMillisecondsOr("maxLifetime", 1800000))
hconf.setLeakDetectionThreshold(c.getMillisecondsOr("leakDetectionThreshold", 0))
hconf.setInitializationFailFast(c.getBooleanOr("initializationFailFast", false))
c.getStringOpt("connectionTestQuery").foreach(hconf.setConnectionTestQuery)
c.getStringOpt("connectionInitSql").foreach(hconf.setConnectionInitSql)
val numThreads = c.getIntOr("numThreads", 20)
hconf.setMaximumPoolSize(c.getIntOr("maxConnections", numThreads * 5))
hconf.setMinimumIdle(c.getIntOr("minConnections", numThreads))
hconf.setPoolName(c.getStringOr("poolName", dbName.name))
hconf.setRegisterMbeans(c.getBooleanOr("registerMbeans", false))
// Equivalent of ConnectionPreparer
hconf.setReadOnly(c.getBooleanOr("readOnly", false))
c.getStringOpt("isolation").map("TRANSACTION_" + _).foreach(hconf.setTransactionIsolation)
hconf.setCatalog(c.getStringOr("catalog", null))
hconf
}
}
import scalikejdbc._
trait ConfigDBs {
self: TypesafeConfigReader with TypesafeConfig with HikariConfigReader =>
def setup(dbName: Symbol = ConnectionPool.DEFAULT_NAME): Unit = {
getFactoryName(dbName) match {
case "hikaricp" => {
val hconf = hikariCPConfig(dbName)
val hikariCPSource = new HikariDataSource(hconf)
case class HikariDataSourceCloser(src: HikariDataSource) extends DataSourceCloser {
var closed = false
override def close(): Unit = src.close()
}
if (hconf.getDriverClassName != null && hconf.getDriverClassName.trim.nonEmpty) {
Class.forName(hconf.getDriverClassName)
}
ConnectionPool.add(dbName, new DataSourceConnectionPool(dataSource = hikariCPSource,settings = DataSourceConnectionPoolSettings(),
closer = HikariDataSourceCloser(hikariCPSource)))
}
case _ => {
val JDBCSettings(url, user, password, driver) = readJDBCSettings(dbName)
val cpSettings = readConnectionPoolSettings(dbName)
if (driver != null && driver.trim.nonEmpty) {
Class.forName(driver)
}
ConnectionPool.add(dbName, url, user, password, cpSettings)
}
}
}
def setupAll(): Unit = {
loadGlobalSettings()
dbNames.foreach { dbName => setup(Symbol(dbName)) }
}
def close(dbName: Symbol = ConnectionPool.DEFAULT_NAME): Unit = {
ConnectionPool.close(dbName)
}
def closeAll(): Unit = {
ConnectionPool.closeAll
}
}
object ConfigDBs extends ConfigDBs
with TypesafeConfigReader
with StandardTypesafeConfig
with HikariConfigReader
case class ConfigDBsWithEnv(envValue: String) extends ConfigDBs
with TypesafeConfigReader
with StandardTypesafeConfig
with HikariConfigReader
with EnvPrefix {
override val env = Option(envValue)
}
jdbc/JDBCEngine.scala
package sdp.jdbc.engine
import java.sql.PreparedStatement
import scala.collection.generic.CanBuildFrom
import akka.stream.scaladsl._
import scalikejdbc._
import scalikejdbc.streams._
import akka.NotUsed
import akka.stream._
import scala.util._
import java.time._
import scala.concurrent.duration._
import sdp.jdbc.FileStreaming._
import scalikejdbc.TxBoundary.Try._
import scala.concurrent.ExecutionContextExecutor
import java.io.InputStream
object JDBCContext {
type SQLTYPE = Int
val SQL_EXEDDL= 1
val SQL_UPDATE = 2
val RETURN_GENERATED_KEYVALUE = true
val RETURN_UPDATED_COUNT = false
}
case class JDBCQueryContext[M](
dbName: Symbol,
statement: String,
parameters: Seq[Any] = Nil,
fetchSize: Int = 100,
autoCommit: Boolean = false,
queryTimeout: Option[Int] = None)
// extractor: WrappedResultSet => M)
case class JDBCContext(
dbName: Symbol,
statements: Seq[String] = Nil,
parameters: Seq[Seq[Any]] = Nil,
fetchSize: Int = 100,
queryTimeout: Option[Int] = None,
queryTags: Seq[String] = Nil,
sqlType: JDBCContext.SQLTYPE = JDBCContext.SQL_UPDATE,
batch: Boolean = false,
returnGeneratedKey: Seq[Option[Any]] = Nil,
// no return: None, return by index: Some(1), by name: Some("id")
preAction: Option[PreparedStatement => Unit] = None,
postAction: Option[PreparedStatement => Unit] = None) {
ctx =>
//helper functions
def appendTag(tag: String): JDBCContext = ctx.copy(queryTags = ctx.queryTags :+ tag)
def appendTags(tags: Seq[String]): JDBCContext = ctx.copy(queryTags = ctx.queryTags ++ tags)
def setFetchSize(size: Int): JDBCContext = ctx.copy(fetchSize = size)
def setQueryTimeout(time: Option[Int]): JDBCContext = ctx.copy(queryTimeout = time)
def setPreAction(action: Option[PreparedStatement => Unit]): JDBCContext = {
if (ctx.sqlType == JDBCContext.SQL_UPDATE &&
!ctx.batch && ctx.statements.size == 1)
ctx.copy(preAction = action)
else
throw new IllegalStateException("JDBCContex setting error: preAction not supported!")
}
def setPostAction(action: Option[PreparedStatement => Unit]): JDBCContext = {
if (ctx.sqlType == JDBCContext.SQL_UPDATE &&
!ctx.batch && ctx.statements.size == 1)
ctx.copy(postAction = action)
else
throw new IllegalStateException("JDBCContex setting error: preAction not supported!")
}
def appendDDLCommand(_statement: String, _parameters: Any*): JDBCContext = {
if (ctx.sqlType == JDBCContext.SQL_EXEDDL) {
ctx.copy(
statements = ctx.statements ++ Seq(_statement),
parameters = ctx.parameters ++ Seq(Seq(_parameters))
)
} else
throw new IllegalStateException("JDBCContex setting error: option not supported!")
}
def appendUpdateCommand(_returnGeneratedKey: Boolean, _statement: String, _parameters: Any*): JDBCContext = {
if (ctx.sqlType == JDBCContext.SQL_UPDATE && !ctx.batch) {
ctx.copy(
statements = ctx.statements ++ Seq(_statement),
parameters = ctx.parameters ++ Seq(_parameters),
returnGeneratedKey = ctx.returnGeneratedKey ++ (if (_returnGeneratedKey) Seq(Some(1)) else Seq(None))
)
} else
throw new IllegalStateException("JDBCContex setting error: option not supported!")
}
def appendBatchParameters(_parameters: Any*): JDBCContext = {
if (ctx.sqlType != JDBCContext.SQL_UPDATE || !ctx.batch)
throw new IllegalStateException("JDBCContex setting error: batch parameters only supported for SQL_UPDATE and batch = true!")
var matchParams = true
if (ctx.parameters != Nil)
if (ctx.parameters.head.size != _parameters.size)
matchParams = false
if (matchParams) {
ctx.copy(
parameters = ctx.parameters ++ Seq(_parameters)
)
} else
throw new IllegalStateException("JDBCContex setting error: batch command parameters not match!")
}
def setBatchReturnGeneratedKeyOption(returnKey: Boolean): JDBCContext = {
if (ctx.sqlType != JDBCContext.SQL_UPDATE || !ctx.batch)
throw new IllegalStateException("JDBCContex setting error: only supported in batch update commands!")
ctx.copy(
returnGeneratedKey = if (returnKey) Seq(Some(1)) else Nil
)
}
def setDDLCommand(_statement: String, _parameters: Any*): JDBCContext = {
ctx.copy(
statements = Seq(_statement),
parameters = Seq(_parameters),
sqlType = JDBCContext.SQL_EXEDDL,
batch = false
)
}
def setUpdateCommand(_returnGeneratedKey: Boolean, _statement: String, _parameters: Any*): JDBCContext = {
ctx.copy(
statements = Seq(_statement),
parameters = Seq(_parameters),
returnGeneratedKey = if (_returnGeneratedKey) Seq(Some(1)) else Seq(None),
sqlType = JDBCContext.SQL_UPDATE,
batch = false
)
}
def setBatchCommand(_statement: String): JDBCContext = {
ctx.copy (
statements = Seq(_statement),
sqlType = JDBCContext.SQL_UPDATE,
batch = true
)
}
type JDBCDate = LocalDate
type JDBCDateTime = LocalDateTime
def jdbcSetDate(yyyy: Int, mm: Int, dd: Int) = LocalDate.of(yyyy,mm,dd)
def jdbcSetNow = LocalDateTime.now()
type JDBCBlob = InputStream
def fileToJDBCBlob(fileName: String, timeOut: FiniteDuration = 60 seconds)(
implicit mat: Materializer) = FileToInputStream(fileName,timeOut)
def jdbcBlobToFile(blob: JDBCBlob, fileName: String)(
implicit mat: Materializer) = InputStreamToFile(blob,fileName)
}
object JDBCEngine {
import JDBCContext._
private def noExtractor(message: String): WrappedResultSet => Nothing = { (rs: WrappedResultSet) =>
throw new IllegalStateException(message)
}
def jdbcAkkaStream[A](ctx: JDBCQueryContext[A],extractor: WrappedResultSet => A)
(implicit ec: ExecutionContextExecutor): Source[A,NotUsed] = {
val publisher: DatabasePublisher[A] = NamedDB('h2) readOnlyStream {
val rawSql = new SQLToCollectionImpl[A, NoExtractor](ctx.statement, ctx.parameters)(noExtractor(""))
ctx.queryTimeout.foreach(rawSql.queryTimeout(_))
val sql: SQL[A, HasExtractor] = rawSql.map(extractor)
sql.iterator
.withDBSessionForceAdjuster(session => {
session.connection.setAutoCommit(ctx.autoCommit)
session.fetchSize(ctx.fetchSize)
})
}
Source.fromPublisher[A](publisher)
}
def jdbcQueryResult[C[_] <: TraversableOnce[_], A](ctx: JDBCQueryContext[A],
extractor: WrappedResultSet => A)(
implicit cbf: CanBuildFrom[Nothing, A, C[A]]): C[A] = {
val rawSql = new SQLToCollectionImpl[A, NoExtractor](ctx.statement, ctx.parameters)(noExtractor(""))
ctx.queryTimeout.foreach(rawSql.queryTimeout(_))
rawSql.fetchSize(ctx.fetchSize)
implicit val session = NamedAutoSession(ctx.dbName)
val sql: SQL[A, HasExtractor] = rawSql.map(extractor)
sql.collection.apply[C]()
}
def jdbcExcuteDDL(ctx: JDBCContext): Try[String] = {
if (ctx.sqlType != SQL_EXEDDL) {
Failure(new IllegalStateException("JDBCContex setting error: sqlType must be 'SQL_EXEDDL'!"))
}
else {
NamedDB(ctx.dbName) localTx { implicit session =>
Try {
ctx.statements.foreach { stm =>
val ddl = new SQLExecution(statement = stm, parameters = Nil)(
before = WrappedResultSet => {})(
after = WrappedResultSet => {})
ddl.apply()
}
"SQL_EXEDDL executed succesfully."
}
}
}
}
def jdbcBatchUpdate[C[_] <: TraversableOnce[_]](ctx: JDBCContext)(
implicit cbf: CanBuildFrom[Nothing, Long, C[Long]]): Try[C[Long]] = {
if (ctx.statements == Nil)
throw new IllegalStateException("JDBCContex setting error: statements empty!")
if (ctx.sqlType != SQL_UPDATE) {
Failure(new IllegalStateException("JDBCContex setting error: sqlType must be 'SQL_UPDATE'!"))
}
else {
if (ctx.batch) {
if (noReturnKey(ctx)) {
val usql = SQL(ctx.statements.head)
.tags(ctx.queryTags: _*)
.batch(ctx.parameters: _*)
Try {
NamedDB(ctx.dbName) localTx { implicit session =>
ctx.queryTimeout.foreach(session.queryTimeout(_))
usql.apply[Seq]()
Seq.empty[Long].to[C]
}
}
} else {
val usql = new SQLBatchWithGeneratedKey(ctx.statements.head, ctx.parameters, ctx.queryTags)(None)
Try {
NamedDB(ctx.dbName) localTx { implicit session =>
ctx.queryTimeout.foreach(session.queryTimeout(_))
usql.apply[C]()
}
}
}
} else {
Failure(new IllegalStateException("JDBCContex setting error: must set batch = true !"))
}
}
}
private def singleTxUpdateWithReturnKey[C[_] <: TraversableOnce[_]](ctx: JDBCContext)(
implicit cbf: CanBuildFrom[Nothing, Long, C[Long]]): Try[C[Long]] = {
val Some(key) :: xs = ctx.returnGeneratedKey
val params: Seq[Any] = ctx.parameters match {
case Nil => Nil
case p@_ => p.head
}
val usql = new SQLUpdateWithGeneratedKey(ctx.statements.head, params, ctx.queryTags)(key)
Try {
NamedDB(ctx.dbName) localTx { implicit session =>
session.fetchSize(ctx.fetchSize)
ctx.queryTimeout.foreach(session.queryTimeout(_))
val result = usql.apply()
Seq(result).to[C]
}
}
}
private def singleTxUpdateNoReturnKey[C[_] <: TraversableOnce[_]](ctx: JDBCContext)(
implicit cbf: CanBuildFrom[Nothing, Long, C[Long]]): Try[C[Long]] = {
val params: Seq[Any] = ctx.parameters match {
case Nil => Nil
case p@_ => p.head
}
val before = ctx.preAction match {
case None => pstm: PreparedStatement => {}
case Some(f) => f
}
val after = ctx.postAction match {
case None => pstm: PreparedStatement => {}
case Some(f) => f
}
val usql = new SQLUpdate(ctx.statements.head,params,ctx.queryTags)(before)(after)
Try {
NamedDB(ctx.dbName) localTx {implicit session =>
session.fetchSize(ctx.fetchSize)
ctx.queryTimeout.foreach(session.queryTimeout(_))
val result = usql.apply()
Seq(result.toLong).to[C]
}
}
}
private def singleTxUpdate[C[_] <: TraversableOnce[_]](ctx: JDBCContext)(
implicit cbf: CanBuildFrom[Nothing, Long, C[Long]]): Try[C[Long]] = {
if (noReturnKey(ctx))
singleTxUpdateNoReturnKey(ctx)
else
singleTxUpdateWithReturnKey(ctx)
}
private def noReturnKey(ctx: JDBCContext): Boolean = {
if (ctx.returnGeneratedKey != Nil) {
val k :: xs = ctx.returnGeneratedKey
k match {
case None => true
case Some(k) => false
}
} else true
}
def noActon: PreparedStatement=>Unit = pstm => {}
def multiTxUpdates[C[_] <: TraversableOnce[_]](ctx: JDBCContext)(
implicit cbf: CanBuildFrom[Nothing, Long, C[Long]]): Try[C[Long]] = {
Try {
NamedDB(ctx.dbName) localTx { implicit session =>
session.fetchSize(ctx.fetchSize)
ctx.queryTimeout.foreach(session.queryTimeout(_))
val keys: Seq[Option[Any]] = ctx.returnGeneratedKey match {
case Nil => Seq.fill(ctx.statements.size)(None)
case k@_ => k
}
val sqlcmd = ctx.statements zip ctx.parameters zip keys
val results = sqlcmd.map { case ((stm, param), key) =>
key match {
case None =>
new SQLUpdate(stm, param, Nil)(noActon)(noActon).apply().toLong
case Some(k) =>
new SQLUpdateWithGeneratedKey(stm, param, Nil)(k).apply().toLong
}
}
results.to[C]
}
}
}
def jdbcTxUpdates[C[_] <: TraversableOnce[_]](ctx: JDBCContext)(
implicit cbf: CanBuildFrom[Nothing, Long, C[Long]]): Try[C[Long]] = {
if (ctx.statements == Nil)
throw new IllegalStateException("JDBCContex setting error: statements empty!")
if (ctx.sqlType != SQL_UPDATE) {
Failure(new IllegalStateException("JDBCContex setting error: sqlType must be 'SQL_UPDATE'!"))
}
else {
if (!ctx.batch) {
if (ctx.statements.size == 1)
singleTxUpdate(ctx)
else
multiTxUpdates(ctx)
} else
Failure(new IllegalStateException("JDBCContex setting error: must set batch = false !"))
}
}
case class JDBCActionStream[R](dbName: Symbol, parallelism: Int = 1, processInOrder: Boolean = true,
statement: String, prepareParams: R => Seq[Any]) {
jas =>
def setDBName(db: Symbol): JDBCActionStream[R] = jas.copy(dbName = db)
def setParallelism(parLevel: Int): JDBCActionStream[R] = jas.copy(parallelism = parLevel)
def setProcessOrder(ordered: Boolean): JDBCActionStream[R] = jas.copy(processInOrder = ordered)
private def perform(r: R) = {
import scala.concurrent._
val params = prepareParams(r)
NamedDB(dbName) autoCommit { session =>
session.execute(statement,params: _*)
}
Future.successful(r)
}
def performOnRow(implicit session: DBSession): Flow[R, R, NotUsed] =
if (processInOrder)
Flow[R].mapAsync(parallelism)(perform)
else
Flow[R].mapAsyncUnordered(parallelism)(perform)
}
object JDBCActionStream {
def apply[R](_dbName: Symbol, _statement: String, params: R => Seq[Any]): JDBCActionStream[R] =
new JDBCActionStream[R](dbName = _dbName, statement=_statement, prepareParams = params)
}
}
jdbc/JDBCFileStreaming.scala
package sdp.jdbc
import java.io.{InputStream, ByteArrayInputStream}
import java.nio.ByteBuffer
import java.nio.file.Paths
import akka.stream.{Materializer}
import akka.stream.scaladsl.{FileIO, StreamConverters}
import scala.concurrent.{Await}
import akka.util._
import scala.concurrent.duration._
object FileStreaming {
def FileToByteBuffer(fileName: String, timeOut: FiniteDuration = 60 seconds)(
implicit mat: Materializer):ByteBuffer = {
val fut = FileIO.fromPath(Paths.get(fileName)).runFold(ByteString()) { case (hd, bs) =>
hd ++ bs
}
(Await.result(fut, timeOut)).toByteBuffer
}
def FileToByteArray(fileName: String, timeOut: FiniteDuration = 60 seconds)(
implicit mat: Materializer): Array[Byte] = {
val fut = FileIO.fromPath(Paths.get(fileName)).runFold(ByteString()) { case (hd, bs) =>
hd ++ bs
}
(Await.result(fut, timeOut)).toArray
}
def FileToInputStream(fileName: String, timeOut: FiniteDuration = 60 seconds)(
implicit mat: Materializer): InputStream = {
val fut = FileIO.fromPath(Paths.get(fileName)).runFold(ByteString()) { case (hd, bs) =>
hd ++ bs
}
val buf = (Await.result(fut, timeOut)).toArray
new ByteArrayInputStream(buf)
}
def ByteBufferToFile(byteBuf: ByteBuffer, fileName: String)(
implicit mat: Materializer) = {
val ba = new Array[Byte](byteBuf.remaining())
byteBuf.get(ba,0,ba.length)
val baInput = new ByteArrayInputStream(ba)
val source = StreamConverters.fromInputStream(() => baInput) //ByteBufferInputStream(bytes))
source.runWith(FileIO.toPath(Paths.get(fileName)))
}
def ByteArrayToFile(bytes: Array[Byte], fileName: String)(
implicit mat: Materializer) = {
val bb = ByteBuffer.wrap(bytes)
val baInput = new ByteArrayInputStream(bytes)
val source = StreamConverters.fromInputStream(() => baInput) //ByteBufferInputStream(bytes))
source.runWith(FileIO.toPath(Paths.get(fileName)))
}
def InputStreamToFile(is: InputStream, fileName: String)(
implicit mat: Materializer) = {
val source = StreamConverters.fromInputStream(() => is)
source.runWith(FileIO.toPath(Paths.get(fileName)))
}
}
BytesConverter.scala
package protobuf.bytes
import java.io.{ByteArrayInputStream,ByteArrayOutputStream,ObjectInputStream,ObjectOutputStream}
import com.google.protobuf.ByteString
object Converter {
def marshal(value: Any): ByteString = {
val stream: ByteArrayOutputStream = new ByteArrayOutputStream()
val oos = new ObjectOutputStream(stream)
oos.writeObject(value)
oos.close()
ByteString.copyFrom(stream.toByteArray())
}
def unmarshal[A](bytes: ByteString): A = {
val ois = new ObjectInputStream(new ByteArrayInputStream(bytes.toByteArray))
val value = ois.readObject()
ois.close()
value.asInstanceOf[A]
}
}
JDBCService.scala
package demo.grpc.jdbc.services
import akka.NotUsed
import akka.stream.scaladsl.Flow
import grpc.jdbc.services._
import java.util.logging.Logger
import protobuf.bytes.Converter._
import sdp.jdbc.engine._
import JDBCEngine._
import scalikejdbc.WrappedResultSet
import scala.concurrent.ExecutionContextExecutor
class JDBCStreamingServices(implicit ec: ExecutionContextExecutor) extends JdbcGrpcAkkaStream.JDBCServices {
val logger = Logger.getLogger(classOf[JDBCStreamingServices].getName)
val toRow = (rs: WrappedResultSet) => JDBCDataRow(
year = rs.string("REPORTYEAR"),
state = rs.string("STATENAME"),
county = rs.string("COUNTYNAME"),
value = rs.string("VALUE")
)
override def runQuery: Flow[JDBCQuery, JDBCDataRow, NotUsed] = {
logger.info("**** runQuery called on service side ***")
Flow[JDBCQuery]
.flatMapConcat { q =>
//unpack JDBCQuery and construct the context
val params: Seq[Any] = unmarshal[Seq[Any]](q.parameters)
logger.info(s"**** query parameters: ${params} ****")
val ctx = JDBCQueryContext[JDBCDataRow](
dbName = Symbol(q.dbName),
statement = q.statement,
parameters = params,
fetchSize = q.fetchSize.getOrElse(100),
autoCommit = q.autoCommit.getOrElse(false),
queryTimeout = q.queryTimeout
)
jdbcAkkaStream(ctx, toRow)
}
}
}
JDBCServer.scala
package demo.grpc.jdbc.server
import java.util.logging.Logger
import akka.actor.ActorSystem
import akka.stream.ActorMaterializer
import io.grpc.Server
import demo.grpc.jdbc.services._
import io.grpc.ServerBuilder
import grpc.jdbc.services._
class gRPCServer(server: Server) {
val logger: Logger = Logger.getLogger(classOf[gRPCServer].getName)
def start(): Unit = {
server.start()
logger.info(s"Server started, listening on ${server.getPort}")
sys.addShutdownHook {
// Use stderr here since the logger may has been reset by its JVM shutdown hook.
System.err.println("*** shutting down gRPC server since JVM is shutting down")
stop()
System.err.println("*** server shut down")
}
()
}
def stop(): Unit = {
server.shutdown()
}
/**
* Await termination on the main thread since the grpc library uses daemon threads.
*/
def blockUntilShutdown(): Unit = {
server.awaitTermination()
}
}
object JDBCServer extends App {
import sdp.jdbc.config._
implicit val system = ActorSystem("JDBCServer")
implicit val mat = ActorMaterializer.create(system)
implicit val ec = system.dispatcher
ConfigDBsWithEnv("dev").setup('h2)
ConfigDBsWithEnv("dev").loadGlobalSettings()
val server = new gRPCServer(
ServerBuilder
.forPort(50051)
.addService(
JdbcGrpcAkkaStream.bindService(
new JDBCStreamingServices
)
).build()
)
server.start()
// server.blockUntilShutdown()
scala.io.StdIn.readLine()
ConfigDBsWithEnv("dev").close('h2)
mat.shutdown()
system.terminate()
}
JDBCClient.scala
package demo.grpc.jdbc.client
import grpc.jdbc.services._
import java.util.logging.Logger
import protobuf.bytes.Converter._
import akka.stream.scaladsl._
import akka.NotUsed
import akka.actor.ActorSystem
import akka.stream.{ActorMaterializer, ThrottleMode}
import io.grpc._
class JDBCStreamClient(host: String, port: Int) {
val logger: Logger = Logger.getLogger(classOf[JDBCStreamClient].getName)
val channel = ManagedChannelBuilder
.forAddress(host,port)
.usePlaintext(true)
.build()
val stub = JdbcGrpcAkkaStream.stub(channel)
val query = JDBCQuery (
dbName = "h2",
statement = "select * from AQMRPT where STATENAME = ? and VALUE = ?",
parameters = marshal(Seq("Arizona", 5))
)
def queryRows: Source[JDBCDataRow,NotUsed] = {
logger.info(s"running queryRows ...")
Source
.single(query)
.via(stub.runQuery)
}
}
object QueryRows extends App {
implicit val system = ActorSystem("QueryRows")
implicit val mat = ActorMaterializer.create(system)
val client = new JDBCStreamClient("localhost", 50051)
client.queryRows.runForeach(println)
scala.io.StdIn.readLine()
mat.shutdown()
system.terminate()
}