1 HFDS core parameters
Parameters that must be referenced when building HFDS clusters
1.1 NameNode memory production configuration
Problem description
1) NameNode memory calculation
Each file block occupies about 150byte. Taking 128G memory of a server as an example, how many file blocks can be stored?
128 * 1024 * 1024 * 1024 / 150Byte ≈ 910 million
2) Hadoop 3. X series, configuring NameNode memory
/hadoop-env.sh in opt/module/hadoop-3.1.3/etc/hadoop path describes that Hadoop memory is dynamically allocated
# The maximum amount of heap to use (Java -Xmx). If no unit # is provided, it will be converted to MB. Daemons will # prefer any Xmx setting in their respective _OPT variable. # There is no default; the JVM will autoscale based upon machine / / if this parameter is not set, the value will be assigned according to the server memory # memory size. # export HADOOP_HEAPSIZE_MAX= # The minimum amount of heap to use (Java -Xms). If no unit # is provided, it will be converted to MB. Daemons will # prefer any Xms setting in their respective _OPT variable. # There is no default; the JVM will autoscale based upon machine # memory size. # export HADOOP_HEAPSIZE_MIN=
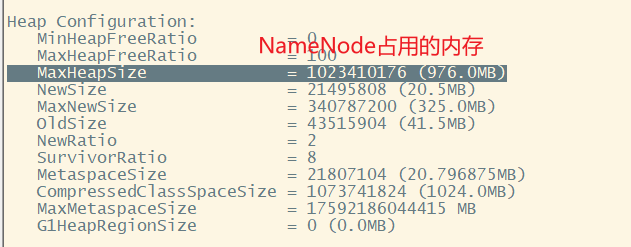
View memory occupied by NameNode
[ranan@hadoop102 hadoop]$ jpsall =============== hadoop102 =============== 15473 JobHistoryServer 15268 NodeManager 14933 DataNode 15560 Jps 14749 NameNode =============== hadoop103 =============== 13969 Jps 13218 DataNode 13717 NodeManager 13479 ResourceManager =============== hadoop104 =============== 13012 Jps 12869 NodeManager 12572 DataNode 12750 SecondaryNameNode [ranan@hadoop102 hadoop]$ jmap -heap 14749 Heap Configuration: MaxHeapSize = 1023410176 (976.0MB)
View the memory occupied by DataNode
[ranan@hadoop102 hadoop]$ jmap -heap 14749 MaxHeapSize = 1023410176 (976.0MB)
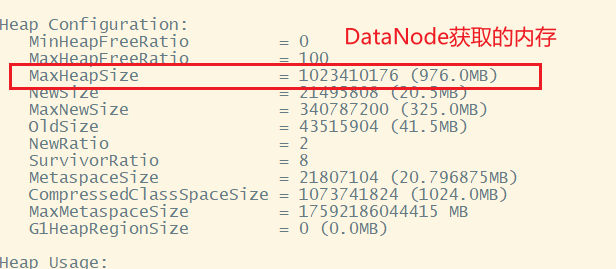
It is found that the memory occupied by NameNode and DataNode on Hadoop 102 is automatically allocated and equal. If both reach the upper limit at the same time (the system is 976M), it is obvious that there is insufficient memory, and it will seize the memory of the linux system, which is unreasonable. Therefore, manual configuration is required.
Configuration in hadoop-env.sh
Experience:

Specific modification: hadoop-env.sh
[ranan@hadoop102 hadoop]$ vim hadoop-env.sh [ranan@hadoop102 hadoop]$ vim hadoop-env.sh //Select splice without modifying the default configuration information- Xmx1024m for splicing export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m" export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m" [ranan@hadoop102 hadoop]$ xsync hadoop-env.sh

Restart cluster
[ranan@hadoop102 hadoop]$ myhadoop.sh stop [ranan@hadoop102 hadoop]$ myhadoop.sh start
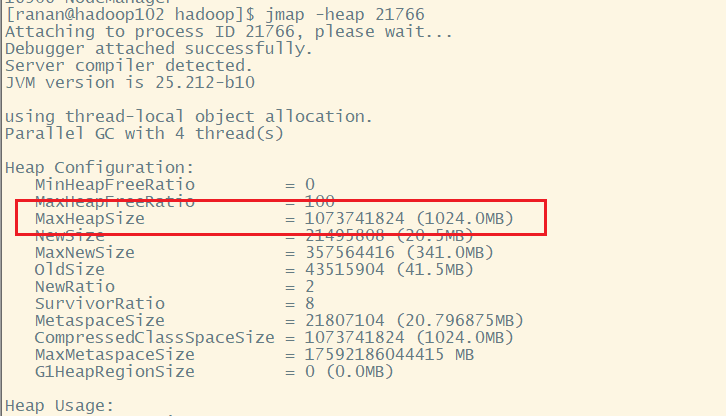
View NameNode memory
[ranan@hadoop103 hadoop]$ jpsall =============== hadoop102 =============== 22292 NodeManager 22500 JobHistoryServer 21957 DataNode 21766 NameNode 22598 Jps =============== hadoop103 =============== 19041 Jps 18531 ResourceManager 18824 NodeManager 18314 DataNode =============== hadoop104 =============== 16787 SecondaryNameNode 16602 DataNode 16906 NodeManager 17069 Jps [ranan@hadoop102 hadoop]$ jmap -heap 21766
View DataNode memory
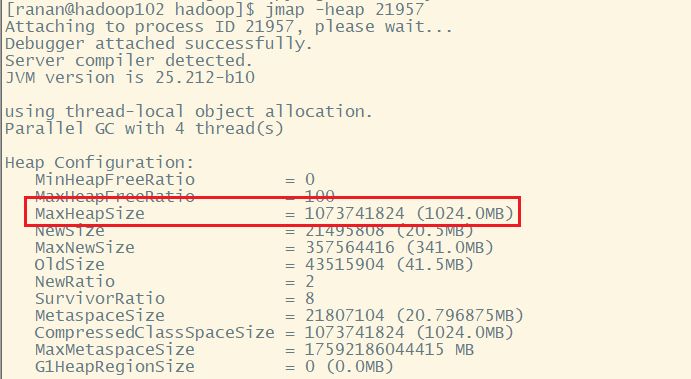
[ranan@hadoop102 hadoop]$ jmap -heap 21957
1.2 NameNode heartbeat concurrency configuration
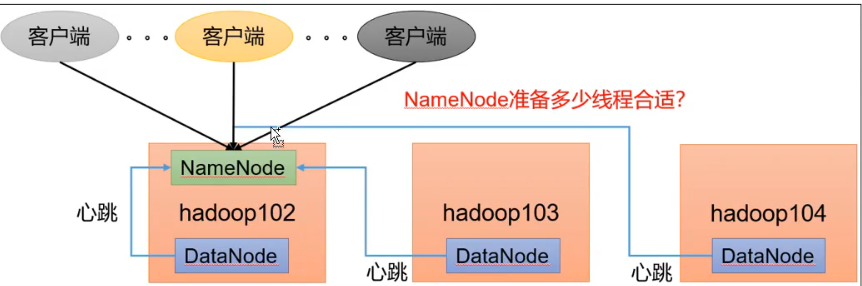
After the DataNode is started, it tells the NameNode the local block information (whether the block is intact) and periodically (6 hours by default) reports all block messages (whether the block is intact).
If there are a large number of datanodes, the NameNode will prepare a thread to handle the report, and the client may also request from the NameNode.
Question: how many threads are appropriate for NameNode?
Modify hdfs-site.xml configuration
NameNode has a worker thread pool, which is used to handle concurrent heartbeats of different datanodes and concurrent metadata operations of clients.
Parameter dfs.namenode.hakdler.count. The default value is 10
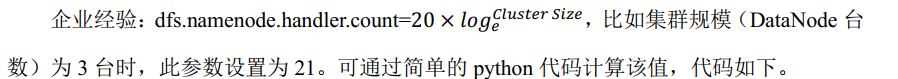
[ranan@hadoop102 ~]$ sudo yum install -y python [ranan@hadoop102 ~]$ python Python 2.7.5 (default, Apr 11 2018, 07:36:10) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import math >>> print int(20*math.log(3)) 21 >>> quit()
hdfs-site.xml NEW
[ranan@hadoop102 hadoop]$ vim hdfs-site.xml <!-- newly added --> <property> <name>dfs.namenode.handler.count</name> <value>21</value> </property>
1.3 enable recycle bin configuration
When the recycle bin function is enabled, the deleted files can be restored to the original data without timeout, so as to prevent accidental deletion and backup. It is disabled by default.
Recycle bin mechanism
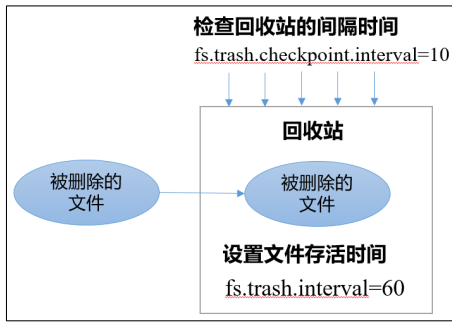
Assuming that the file survival time is set to fs.trash,interval = 6060min, check the file survival time in the recycle bin every 10min, fs.trash,checkpoint.interval=10. If it is not set, it is consistent with the file survival time interval, and check it every 60min
Description of function parameters for opening recycle bin
(1) The default value is fs.trash.interval = 0. 0 means the recycle bin is disabled; Other values indicate the lifetime of the setup file.
(2) The default value is fs.trash.checkpoint.interval = 0, which is the interval between checking the recycle bin. If the value is 0, the value setting is equal to the parameter value of fs.trash.interval.
(3) Fs.trash.checkpoint.interval < = fs.trash.interval is required.
Start Recycle Bin - modify core-site.xml
Modify the core-site.xml and configure the garbage collection time to be 1 minute.
<!--newly added--> <property> <name>fs.trash.interval</name> <value>1</value> </property>
View recycle bin
Path of recycle bin directory in HDFS cluster: / user/ranan/.Trash /
Note: deleting directly on the web page does not go to the recycle bin
The files deleted through the program will not go through the recycle bin. You need to call moveToTrash() to enter the recycle bin
Trash trash = New Trash(conf); trash.moveToTrash(path); //Add to recycle bin after deletion
Only files deleted on the command line with the hadoop fs -rm command will go to the recycle bin.
[ranan@hadoop102 hadoop]$ hadoop fs -rm /test.txt 2021-11-04 16:25:53,705 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop102:8020/test.txt' to trash at: hdfs://hadoop102:8020/user/ranan/.Trash/Current/test.txt
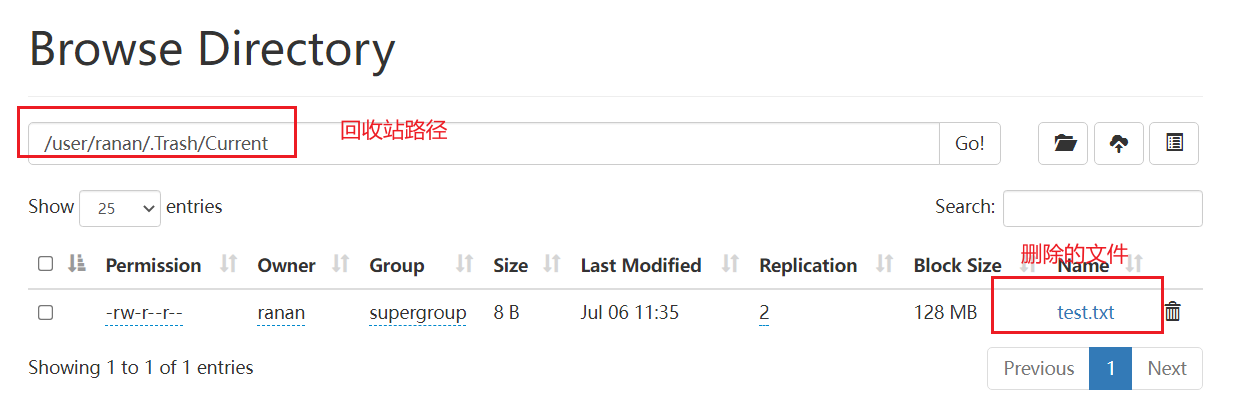
Recover recycle bin data
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /user/ranan/.Trash/Current/test.txt /