NUS-WIDE is a multi label dataset, which contains 269648 samples and can be divided into 81 classes. Recently, I was doing a cross modal retrieval project and found that many papers used the NUS-WIDE-10K dataset, but I didn't find the relevant dataset download link or dataset creation code on the Internet, so I wrote a NUS-WIDE-10K dataset creation code myself.
1. Introduction
The earliest paper I found on the Internet on the description of NUS-WIDE-10K dataset is: cross modal retrieval with correlation autoencoder. The description is as follows: the author selects the 10 largest classes in the NUS-WIDE dataset: animal, clouds, owners, food, grass, person, sky, toy, water and window, and selects 1000 pictures (10000 in total) from each class as the NUS-WIDE-10K dataset. NUS-WIDE-10K is randomly divided into three subsets: training set, verification set and test set. The number of samples in each set is 8000, 1000 and 1000 respectively.

2. Data set analysis
Let's take a look at the main structure of the NUS-WIDE dataset
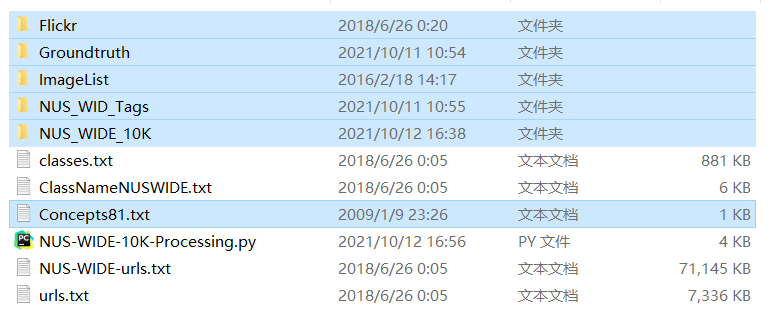
- Flickr folder: the Flickr folder contains all the pictures in the NUS-WIDE dataset. There are 704 folders, and each folder represents a kind of pictures (remember that NUS-WIDE is a multi label dataset? Yes, so each picture has two labels)
- Groundtruth folder: after decompression, there are AllLabels/ and TrainTestLabels/ Two directories, alllabels/ There are 81. txt files in total. Each file contains 269648 lines of 0 / 1 data, representing whether the data belongs to this category.
- ImageList folder: there are three files in this folder: Imagelist.txt, TestImagelist.txt and TrainImagelist.txt. We only use Imagelist.txt, which lists the storage addresses of all pictures of the dataset in order.
- NUS_WID_Tags folder: the folder has multiple files, but we only use All_Tags.txt, which stores the text descriptions of all pictures in order.
- Concepts81.txt: contains the class name of 81 categories.
3. Code
extract
- Extract the id value of each category sample of animal, clouds, owners, food, grass, person, sky, toy, water and window.
- 1000 samples were randomly selected from each category.
import os
import numpy as np
import random
from tqdm import tqdm
import shutil
import sys
N_SAMPLE = 269648
label_dir = "Groundtruth/AllLabels"
image_dir = 'ImageList/ImageList.txt'
txt_dir = 'NUS_WID_Tags/All_Tags.txt'
output_dir = 'NUS_WIDE_10K/NUS_WIDE_10k.list'
classes = ['animal', 'clouds', 'flowers', 'food', 'grass', 'person', 'sky', 'toy', 'water', 'window'] #10 categories of NUS-WIDE-10K dataset
print('loading all class names')
cls_id = {}
with open("Concepts81.txt", "r") as f:
for cid, line in enumerate(f):
cn = line.strip()
cls_id[cn] = cid
id_cls = {cls_id[k]: k for k in cls_id}
print('Finished, with {} classes.'.format(len(id_cls)))
print('Extract and sample id from label files')
data_list = {}
class_files = os.listdir(label_dir)
class_files.remove('Labels_waterfall.txt') #Remove labels manually_ Waterfall.txt this file prevents errors
for class_file in class_files:
for clas in classes:
if clas in class_file:
print('class_file:' + class_file)
with open(os.path.join(label_dir, class_file), "r") as f:
i = []
for sid, line in enumerate(f):
if int(line) > 0:
i.append(sid)
print('total samples of {}:'.format(clas) + str(len(i)))
data_list[clas] = random.sample(i, 1000) #Randomly select 1000 data for each category
print('sample number of ' + clas + ':{}\n'.format(len(data_list[clas])))Generate NUS_WIDE_10k.list file
- For ease of use, we created NUS_WIDE_10k.list file is used to store (picture address, text description, sample category).
images = []
txts = []
with open(image_dir, "r") as f:
for line in f:
line = line.strip()
images.append(line)
with open(txt_dir, "r", encoding='utf-8') as f:
for line in f:
line = line.strip().split(' ')
txts.append(line[-1])
print('images:{} text:{}'.format(len(images), len(txts)))
print('Write the list')
with open(output_dir, "w", encoding='utf-8') as f:
for clas in classes:
for i in data_list[clas]:
f.write('{} {} {}\n'.format(images[i].split('\\')[0] + '/' + images[i].split('\\')[1], txts[i], clas))Divide image training set and test set
- For each category, there are 800, 100, 100 images for training, validation and testing.
def split_train_val_nus_wide_10k(): #Divide the training set and test set of pictures
count = 0
print('Split training and test set for images')
with open(output_dir, 'r', encoding='utf-8') as f:
for i, line in enumerate(f):
print("\r", end="")
print("Download progress: {}%: ".format(i/100), "▋" * (i // 100), end="")
sys.stdout.flush()
count += 1
line = line.strip().split(' ')
img = line[0]
doc = line[-1]
if count % 1000 < 900:
new_path = 'NUS_WIDE_10K/image_split/train/'
else:
new_path = 'NUS_WIDE_10K/image_split/val/'
if not os.path.exists(new_path + doc):
os.mkdir(new_path + doc)
image_path = 'Flickr/' + img
shutil.copyfile(image_path, new_path + doc + '/' + img.split('/')[-1])Complete code
import os
import numpy as np
import random
from tqdm import tqdm
import shutil
import sys
N_SAMPLE = 269648
label_dir = "Groundtruth/AllLabels"
image_dir = 'ImageList/ImageList.txt'
txt_dir = 'NUS_WID_Tags/All_Tags.txt'
output_dir = 'NUS_WIDE_10K/NUS_WIDE_10k.list'
classes = ['animal', 'clouds', 'flowers', 'food', 'grass', 'person', 'sky', 'toy', 'water', 'window'] #10 categories of NUS-WIDE-10K dataset
print('loading all class names')
cls_id = {}
with open("Concepts81.txt", "r") as f:
for cid, line in enumerate(f):
cn = line.strip()
cls_id[cn] = cid
id_cls = {cls_id[k]: k for k in cls_id}
print('Finished, with {} classes.'.format(len(id_cls)))
print('Extract and sample id from label files')
data_list = {}
class_files = os.listdir(label_dir)
class_files.remove('Labels_waterfall.txt') #Remove labels manually_ Waterfall.txt this file prevents errors
for class_file in class_files:
for clas in classes:
if clas in class_file:
print('class_file:' + class_file)
with open(os.path.join(label_dir, class_file), "r") as f:
i = []
for sid, line in enumerate(f):
if int(line) > 0:
i.append(sid)
print('total samples of {}:'.format(clas) + str(len(i)))
data_list[clas] = random.sample(i, 1000) #Randomly select 1000 data for each category
print('sample number of ' + clas + ':{}\n'.format(len(data_list[clas])))
print('Extract all images and text')
images = []
txts = []
with open(image_dir, "r") as f:
for line in f:
line = line.strip()
images.append(line)
with open(txt_dir, "r", encoding='utf-8') as f:
for line in f:
line = line.strip().split(' ')
txts.append(line[-1])
print('images:{} text:{}'.format(len(images), len(txts)))
print('Write the list')
with open(output_dir, "w", encoding='utf-8') as f:
for clas in classes:
for i in data_list[clas]:
f.write('{} {} {}\n'.format(images[i].split('\\')[0] + '/' + images[i].split('\\')[1], txts[i], clas))
print('Finished!')
def split_train_val_nus_wide_10k(): #Divide the training set and test set of pictures
count = 0
print('Split training and test set for images')
with open(output_dir, 'r', encoding='utf-8') as f:
for i, line in enumerate(f):
print("\r", end="")
print("Download progress: {}%: ".format(i/100), "▋" * (i // 100), end="")
sys.stdout.flush()
count += 1
line = line.strip().split(' ')
img = line[0]
doc = line[-1]
if count % 1000 < 900:
new_path = 'NUS_WIDE_10K/image_split/train/'
else:
new_path = 'NUS_WIDE_10K/image_split/val/'
if not os.path.exists(new_path + doc):
os.mkdir(new_path + doc)
image_path = 'Flickr/' + img
shutil.copyfile(image_path, new_path + doc + '/' + img.split('/')[-1])
split_train_val_nus_wide_10k()