Process Threads Cooperate Those Things
Keywords:
Python
socket
less
Redis
I. Processes and Threads
1. Process
Our computer applications are all processes, assuming that the computer we use is single-core, and the CPU can only execute one process at the same time. When the program is blocked by I/O, it is too wasteful for the CPU to wait with the program. The CPU will execute other programs. At this time, it involves switching. Before switching, it is necessary to save the running state of the previous program in order to recover. So something is needed to record this thing, and the concept of process can be introduced.
A process is a dynamic execution process of a program on a data set. The process consists of three parts: program, data set and process control block. Programs are used to describe what functions of a process are and how they are accomplished; data sets are the resources used in the execution of a program; process control blocks are used to preserve the state of the program.
2. Threads
Many threads can be opened in a process. Why should there be a process instead of a thread? Because in a program, threads share a set of data. If they are all made into processes and each process has a single piece of memory, then the set of data should be copied several copies to each program, which is unreasonable, so there are threads.
Threads, also known as lightweight processes, are a basic unit of cpu execution and the smallest unit in the process of program execution. A process will have at least one main thread, in which threading module is used in sub-threading.
3. The relationship between process threads
(1) A thread can only belong to one process, and a process can have multiple threads, but at least one thread.
(2) Resources are allocated to the process, which is the main body of the program. All threads of the same process share all resources of the process.
(3) The cpu is allocated to threads, that is, threads are really running on the cpu.
(4) Thread is the smallest execution unit and process is the smallest resource management unit.
4. Parallelism and concurrency
Parallel processing is a computational method that can perform two or more tasks simultaneously in a computer system. Parallel processing can work in different aspects of the same program at the same time.
Concurrent processing is that several programs are running in a single cpu in the same period of time, but only one program runs on the cpu at any time.
The focus of concurrency is to have the ability to handle multiple tasks, not necessarily at the same time; while the focus of concurrency is to have the ability to handle multiple tasks at the same time. Parallelism is a subset of concurrency

What I said above is that Python has a GIL lock, which limits the use of cpu by only one thread of a process at the same time.
II. threading module
The function of this module is to create new threads. There are two ways to create threads:
1. Direct creation
import threading
import time
def foo(n):
print('>>>>>>>>>>>>>>>%s'%n)
time.sleep(3)
print('tread 1')
t1=threading.Thread(target=foo,args=(2,))
#arg The tuple must follow. t1 Is the created subthread object
t1.start()#Running subprocesses
print('ending')
The above code creates a sub-thread in the main thread
The result is: Print > > > > > > 2, print ending, and then wait 3 seconds to print thread 1.
2. Another way is to create threaded objects by inheriting classes
import threading
import time
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
print('ok')
time.sleep(2)
print('end')
t1=MyThread()#Creating Thread Objects
t1.start()#Activate Thread Objects
print('end again')
3.join () method
The function of this method is that the parent thread of the child thread will wait for the child thread to run until it has finished running.
import threading
import time
def foo(n):
print('>>>>>>>>>>>>>>>%s'%n)
time.sleep(n)
print('tread 1')
def bar(n):
print('>>>>>>>>>>>>>>>>%s'%n)
time.sleep(n)
print('thread 2')
s=time.time()
t1=threading.Thread(target=foo,args=(2,))
t1.start()#Running subprocesses
t2=threading.Thread(target=bar,args=(5,))
t2.start()
t1.join() #It just blocked the main thread from running. t2 No problem
t2.join()
print(time.time()-s)
print('ending')
'''
//Operation results:
>>>>>>>>>>>>>>>2
>>>>>>>>>>>>>>>>5
tread 1
thread 2
5.001286268234253
ending
'''
4.setDaemon() method
The purpose of this method is to declare a thread as a daemon thread, which must be set before the start() method calls.
By default, the main thread checks whether the sub-thread is completed after running, and if it is not, the main thread waits for the sub-thread to complete before exiting. But if the main thread exits after it has finished running without pipe, set Daemon (True)
import threading
import time
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
print('ok')
time.sleep(2)
print('end')
t1=MyThread()#Creating Thread Objects
t1.setDaemon(True)
t1.start()#Activate Thread Objects
print('end again')
#The result is printed immediately. ok and end again
#Then the program terminates and does not print. end
By default, the main thread is non-daemon thread, and the sub-threads are inherited main threads, so the default is non-daemon thread as well.
5. Other methods
isAlive(): Whether the return thread is active
getName(): Returns the thread name
setName(): Set the thread name
threading.currentThread(): Returns the current thread variable
threading.enumerate(): Returns a list of running threads
threading.activeCount(): Returns the number of threads running
III. All kinds of locks
1. Synchronization Lock (User Lock, Mutex Lock)
Let's start with an example:
The requirement is that we have a global variable with a value of 100. We have 100 threads. The operations performed by each thread are to subtract the global variable by one, and finally import threading.
import threading
import time
def sub():
global num
temp=num
num=temp-1
time.sleep(2)
num=100
l=[]for i in range(100):
t=threading.Thread(target=sub,args=())
t.start()
l.append(t)
for i in l:
i.join()
print(num)
It seems that everything is normal. Now let's change it. In the middle of temp=num and num=temp-1 of the sub function, add a time.sleep(0.1), and you will find something wrong. The result will be 99 printed in two seconds and changed to time.sleep(0.0001). The result is uncertain, but it's more than 90. What's the matter?
This is about the GIL lock in Python. Let's give it a stroke:
For the first time, a global variable num=100 is defined, and then 100 sub-threads are opened. But Python's GIL lock restricts only one thread to use the CPU at the same time, so the 100 threads are in the state of grabbing the lock. Whoever grabs it can run its own code. In the initial case, each thread grabs the CPU and immediately performs the operation of subtracting one global variable, so there will be no problem. But after the change, before the global variable is subtracted by one, let him sleep for 0.1 seconds, the program falls asleep, the CPU can not wait for this thread all the time. When this thread is blocked by I/O, other threads can grab the CPU again. So other threads grab it and start executing the code. We must know that 0.1 seconds has been a long time for the operation of the cpu, and this time is enough for the first time. Before one thread wakes up, the other threads grab the CPU once. They get 100 nums, and when they wake up, they perform 100-1 operations, so the final result is 99. The same reason, if the sleep time is shorter, it becomes 0.001, maybe when the 91 threads first grab the cpu, the first threads have waked up and changed the global variables. So the 91 threads get 99 global variables, and then the second and third threads wake up and modify the global variables respectively, so the final result is an unknown number. Understand the process with a picture
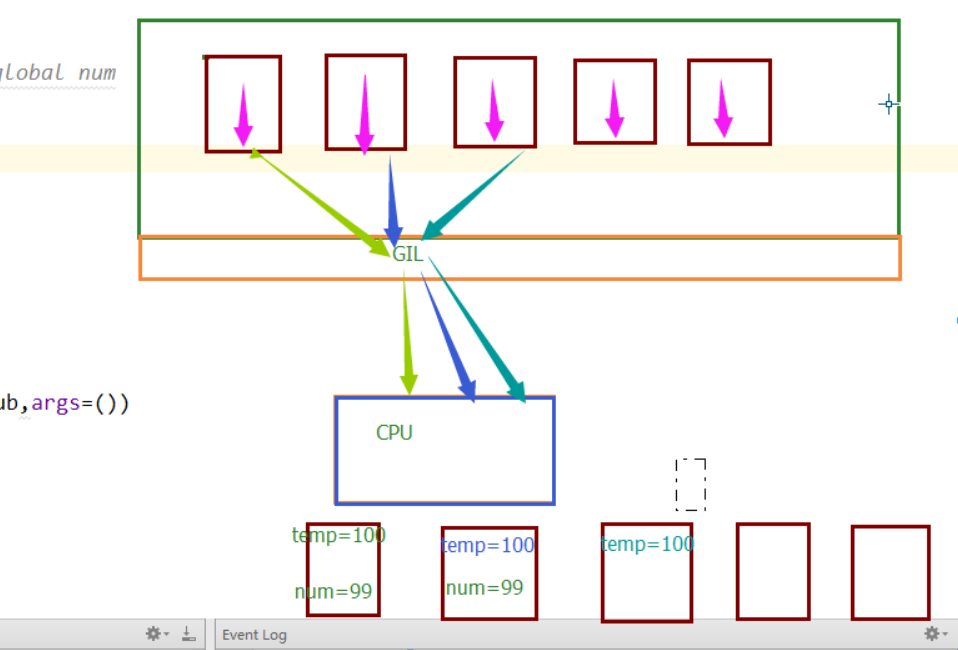
This is the thread security problem, as long as it involves threads, there will be this problem. The solution is to lock
We add a lock to the whole world, lock the operation involving data operation with the lock, and turn this code into serial code.
import threading
import time
def sub():
global num
lock.acquire()#Acquisition locks
temp=num
time.sleep(0.001)
num=temp-1
lock.release()#Release lock
time.sleep(2)
num=100
l=[]
lock=threading.Lock()
for i in range(100):
t=threading.Thread(target=sub,args=())
t.start()
l.append(t)
for i in l:
i.join()
print(num)
After acquiring the lock, it must be released before it can be retrieved again. This lock is called a user lock.
2. Deadlock and Recursive Lock
Deadlock is a phenomenon that two or more processes or threads wait for each other because of mutual restriction in the execution process. If there is no external force, they will be stuck there forever. For instance:
1 import threading,time
2
3 class MyThread(threading.Thread):
4 def __init(self):
5 threading.Thread.__init__(self)
6
7 def run(self):
8
9 self.foo()
10 self.bar()
11 def foo(self):
12 LockA.acquire()
13 print('i am %s GET LOCKA------%s'%(self.name,time.ctime()))
14 #Each thread has a default name. self.name Get the name.
15
16 LockB.acquire()
17 print('i am %s GET LOCKB-----%s'%(self.name,time.ctime()))
18
19 LockB.release()
20 time.sleep(1)
21 LockA.release()
22
23 def bar(self):#and
24 LockB.acquire()
25 print('i am %s GET LOCKB------%s'%(self.name,time.ctime()))
26 #Each thread has a default name. self.name Get the name.
27
28 LockA.acquire()
29 print('i am %s GET LOCKA-----%s'%(self.name,time.ctime()))
30
31 LockA.release()
32 LockB.release()
33
34 LockA=threading.Lock()
35 LockB=threading.Lock()
36
37 for i in range(10):
38 t=MyThread()
39 t.start()
40
41 #Operation results:
42 i am Thread-1 GET LOCKA------Sun Jul 23 11:25:48 2017
43 i am Thread-1 GET LOCKB-----Sun Jul 23 11:25:48 2017
44 i am Thread-1 GET LOCKB------Sun Jul 23 11:25:49 2017
45 i am Thread-2 GET LOCKA------Sun Jul 23 11:25:49 2017
46 And then it got stuck.
Deadlock example
In the example above, thread 2 is waiting for thread 1 to release the B lock and thread 1 is waiting for thread 2 to release the A lock, which restricts each other.
When we use mutexes, once we use more locks, it's easy to have this problem.
In Python, to solve this problem, Python provides a concept called Reusable Lock, which maintains a lock and a counter variable inside the lock. Counter records the number of acquisitions. Each acquisition, counter adds 1. Each release,counter decreases 1. Only when the value of counter is 0, other threads can get resources. Now replace Lo with RLock. Ck, it won't get stuck in operation:


1 import threading,time
2
3 class MyThread(threading.Thread):
4 def __init(self):
5 threading.Thread.__init__(self)
6
7 def run(self):
8
9 self.foo()
10 self.bar()
11 def foo(self):
12 RLock.acquire()
13 print('i am %s GET LOCKA------%s'%(self.name,time.ctime()))
14 #Each thread has a default name. self.name Get the name.
15
16 RLock.acquire()
17 print('i am %s GET LOCKB-----%s'%(self.name,time.ctime()))
18
19 RLock.release()
20 time.sleep(1)
21 RLock.release()
22
23 def bar(self):#and
24 RLock.acquire()
25 print('i am %s GET LOCKB------%s'%(self.name,time.ctime()))
26 #Each thread has a default name. self.name Get the name.
27
28 RLock.acquire()
29 print('i am %s GET LOCKA-----%s'%(self.name,time.ctime()))
30
31 RLock.release()
32 RLock.release()
33
34 LockA=threading.Lock()
35 LockB=threading.Lock()
36
37 RLock=threading.RLock()
38 for i in range(10):
39 t=MyThread()
40 t.start()
Examples of recursive locks
This lock is also called a recursive lock.
3. Semaphore (semaphore)
This is also a lock, you can specify how many threads can get the lock at the same time, up to five (the mutex mentioned above can only be obtained by one thread)
import threading
import time
semaphore=threading.Semaphore(5)
def foo():
semaphore.acquire()
time.sleep(2)
print('ok')
semaphore.release()
for i in range(10):
t=threading.Thread(target=foo,args=())
t.start()
The result is to print five ok every two seconds.
4.Event objects
Threads run independently. Event objects are needed if there is communication between threads, or if a thread needs to perform the next operation according to the state of a thread. Event object can be regarded as a flag bit, the default value is false. If a thread waits for an Event object and the flag bit in the Event object is false at this time, the thread will wait until the flag bit is true. After the flag bit is true, all threads waiting for the Event object will be awakened.
event.isSet(): Returns the status value of event;
event.wait(): If event.isSet()==False, the thread will be blocked.
event.set(): Set the state value of event to True, and all blocking pool threads are activated into ready state, waiting for the operating system to schedule; when setting objects, the default is False
event.clear(): Restore event's status value to False.
An example is given to illustrate the use of Event objects:
import threading,time
event=threading.Event() #Create a event object
def foo():
print('wait.......')
event.wait()
#event.wait(1)#If the flag bit in the event object is Flase, then blocking
#wait()The parameter inside means: just wait for 1 second, if the flag has not been changed after 1 second, then wait, continue to execute the following code
print('connect to redis server')
print('attempt to start redis sever)')
time.sleep(3)
event.set()
for i in range(5):
t=threading.Thread(target=foo,args=())
t.start()
#3 Seconds later, the main thread ends, but the sub-thread is not the daemon thread, the sub-thread is not finished, so the program does not end, should be 3 seconds later, set the flag to true,Namely event.set()
5. Queues
Official documents say queues are very useful for data security in multithreading
Queues can be understood as a data structure that stores and reads and writes data. It's like adding a lock to the list.
5.1 get and put methods
import queue
#Only read and write data in the queue put and get Two methods, none of the list methods.
q=queue.Queue()#Create a queue object FIFO FIFO
#q=queue.Queue(20)
#There can be a parameter that sets the maximum amount of data stored, which can be understood as the maximum number of grids.
#If the parameter is set to 20, at the 21st put, the program will block until there is an empty location, that is, data is moved by get.
q.put(11)#Put value
q.put('hello')
q.put(3.14)
print(q.get())#Value 11
print(q.get())#Value hello
print(q.get())#Value 3.14
print(q.get())#Block, wait put A Data

There is a default parameter block=True in the get method. Change this parameter to False, and queue.Empty will be wrong if the value is not reached.
This is equivalent to q.get_nowait())
5.2 join and task_done methods
Join is used to block processes, and it makes sense to use it in conjunction with task_done. Event object can be used to understand, no times put(), join counter plus 1, no times task_done (), counter minus 1, counter is 0, before the next put()
Notice that task_done is added after each get().
import queue
import threading
#Only in the queue put and get Two methods, none of the list methods.
q=queue.Queue()#
def foo():#Storage of data
# while True:
q.put(111)
q.put(222)
q.put(333)
q.join()
print('ok')#There is join,This is where the program stops.
def bar():
print(q.get())
q.task_done()
print(q.get())
q.task_done()
print(q.get())
q.task_done()#In each get()After the statement, add
t1=threading.Thread(target=foo,args=())
t1.start()
t2=threading.Thread(target=bar,args=())
t2.start()
#t1,t2 It doesn't matter who comes first or who comes next, because it will block and wait for the signal.
5.3 Other methods
q.qsize() returns the size of the queue
q.empty() If the queue is empty, return True, and vice versa False
q.full() If the queue is full, return True, and vice versa False
q.full and maxsize size correspond
5.4 Other Models
The queues mentioned above are FIFO mode, and there are LIFO mode and priority queue.
Classqueue. LifoQueue (maxsize)
Priority queues are written as: class queue.Priorityueue(maxsize)
q=queue.PriorityQueue()
q.put([5,100]) This square bracket only represents a sequence type, and the tuple list is OK, but all must be the same.
q.put([7,200])
q.put([3,"hello"])
q.put([4,{"name":"alex"}])
The first place in brackets is priority.
5.5 Producer-Consumer Model
The producer is equivalent to the thread that generates the data, and the consumer is equivalent to the thread that fetches the data. When we write programs, we must consider whether the ability of production data matches the ability of consumption data. If it does not match, one party must wait, so the producer and consumer model is introduced.
This model solves the strong coupling problem between producer and consumer through a container. With this container, they do not need to communicate directly, but through this container, which is a blocking queue, equivalent to a buffer, balancing the capabilities of producers and consumers. Isn't the directory structure we use to write programs also for decoupling and reconciliation?
In addition to solving the strong coupling problem, the producer-consumer model can also achieve concurrency.
When the producer's and consumer's abilities do not match, the restriction should be considered, such as if Q. qsize ()< 20.
IV. Multiprocess
There's a global lock (GIL) in python that prevents multithreading from using multicores, but if it's a multiprocess, the lock won't be limited. How to open multiple processes, you need to import a multiprocessing module
import multiprocessing
import time
def foo():
print('ok')
time.sleep(2)
if __name__ == '__main__':#Must be in this format
p=multiprocessing.Process(target=foo,args=())
p.start()
print('ending')
Although multi-process can be opened, we must pay attention to not too much, because inter-process switching consumes system resources very much. If thousands of sub-processes are opened, the system will collapse, and inter-process communication is also a problem. Therefore, processes can be used or not, and processes can be used less or less.
1. Interprocess communication
There are two ways to communicate between processes, queue and pipeline.
1.1 Interprocess queues
Each process is a separate piece of space in memory. It can share data without threads, so the queue can only be passed from parent process to child process by parameter.
import multiprocessing
import threading
def foo(q):
q.put([12,'hello',True])
if __name__ =='__main__':
q=multiprocessing.Queue()#Create process queues
#Create a subthread
p=multiprocessing.Process(target=foo,args=(q,))
#Passing this queue object to the parent process by reference
p.start()
print(q.get())
1.2 Pipeline
The socket that I learned before is actually a pipe. The sock of the client and conn of the server are the two ends of the pipe. This is also the way to play in the process. There should also be two ends of the pipe.
from multiprocessing import Pipe,Process
def foo(sk):
sk.send('hello')#The main process sends messages
print(sk.recv())#The main process receives messages
sock,conn=Pipe()#Two ends of the pipe were created.
if __name__ == '__main__':
p=Process(target=foo,args=(sock,))
p.start()
print(conn.recv())#Subprocesses receive messages
conn.send('hi son')#Subprocesses send messages
2. Data Sharing between Processes
We have realized communication between processes through process queue and pipeline, but we have not realized data sharing yet.
Data sharing between processes needs to be implemented by referencing a manager object. All data types used are created by using manager points.
from multiprocessing import Process
from multiprocessing import Manager
def foo(l,i):
l.append(i*i)
if __name__ == '__main__':
manager = Manager()
Mlist = manager.list([11,22,33])#Create a shared list
l=[]
for i in range(5):
#Open up five sub-processes
p = Process(target=foo, args=(Mlist,i))
p.start()
l.append(p)
for i in l:
i.join()#join The method is to wait for the process to finish before executing the next one.
print(Mlist)
3. Process pool
The function of the process pool is to maintain a maximum amount of processes. If the maximum amount is exceeded, the program will block until the available processes are known.
from multiprocessing import Pool
import time
def foo(n):
print(n)
time.sleep(2)
if __name__ == '__main__':
pool_obj=Pool(5)#Create a process pool
#Creating processes through process pools
for i in range(5):
p=pool_obj.apply_async(func=foo,args=(i,))
#p Is the pool object created
# pool Use first close(),stay join(),Just remember.
pool_obj.close()
pool_obj.join()
print('ending')
There are several methods in the process pool:
1.apply: Take a process from the process pool and execute it
2.apply_async: asynchronous version of apply
3.terminate: Close the thread pool immediately
4.join: The main process waits for all subprocesses to finish executing, and must be after close or terminate
5.close: Wait for all processes to finish before closing the thread pool
V. COOPERATION
In hand, the world I have, say go away. Knowing the coroutines, the process threads mentioned above will be forgotten.
There is no upper limit and the consumption between handoffs can be neglected.
1.yield
Think back and forth about the word "yield". Familiar with it, no, that's the one used by the generator. Yield is an amazing thing, which is a feature of Python.
Normally, the function stops when it encounters return, and then returns the value after return. By default, None, yield and return are very similar, but when it encounters yield, it does not stop immediately, but pauses until it encounters next(), (the principle of for loop is also next()). You can also follow a variable in front of the field by sending () to the field to store the value in the variable in front of the field.
import time
def consumer():#There is yield, which is a generator.
r=""
while True:
n=yield r#Program pauses, waiting for next() signal
# if not n:
# return
print('consumer <--%s..'%n)
time.sleep(1)
r='200 ok'
def producer(c):
next(c)#Activation generator c
n=0
while n<5:
n=n+1
print('produer-->%s..'%n)
cr = c.send(n)#Send data to generator
print('consumer return :',cr)
c.close() #When the production process is over, turn off the generator
if __name__ == '__main__':
c=consumer()
producer(c)
Look at the above example, the whole process does not appear lock, but also to ensure data security, more importantly, can control the order, elegant realization of concurrency, throw off multi-threaded streets.
Threads are called micro-processes, and co-processes are called micro-threads. The coroutine has its own register context and stack, so it can retain the state of the last call.
2.greenlet module
This module encapsulates yield, which makes program switching very convenient, but it can not achieve the function of value transfer.
from greenlet import greenlet
def foo():
print('ok1')
gr2.switch()
print('ok3')
gr2.switch()
def bar():
print('ok2')
gr1.switch()
print('ok4')
gr1=greenlet(foo)
gr2=greenlet(bar)
gr1.switch()#start-up
3.gevent module
On the basis of greenlet module, a better module gevent is developed.
gevent provides better collaboration support for Python. Its basic principles are:
When a Greenlet encounters an IO operation, it will automatically switch to another greenlet, wait for the IO operation to complete, and then switch back, so as to ensure that there is always Greenlet running, not waiting.
import requests
import gevent
import time
def foo(url):
response=requests.get(url)
response_str=response.text
print('get data %s'%len(response_str))
s=time.time()
gevent.joinall([gevent.spawn(foo,"https://itk.org/"),
gevent.spawn(foo, "https://www.github.com/"),
gevent.spawn(foo, "https://zhihu.com/"),])
# foo("https://itk.org/")
# foo("https://www.github.com/")
# foo("https://zhihu.com/")
print(time.time()-s)
4. Advantages and disadvantages of the protocol:
Advantage:
Context switching consumes less
Convenient switching of control flow and simplified programming model
High concurrency, high scalability and low cost
Disadvantages:
Multicore is unavailable
Blocking operations block the entire program
VI. IO Model
Let's compare four IO models
1.blocking IO
2.nonblocking IO
3.IO multiplexing
4.asynchronous IO
We take IO for example. It involves two system objects, one is the thread or process that calls the IO, the other is the system kernel. When reading data, it will go through two stages:
Waiting for data preparation
The process of copying data from the kernel state to the user state (because the data transmission of the network is realized by the physical device, which is hardware and can only be processed by the kernel state of the operating system, but the reading data is used by the program, so the switch of this step is needed).
1.blocking IO (Blocking IO)
The typical read operation is shown below.
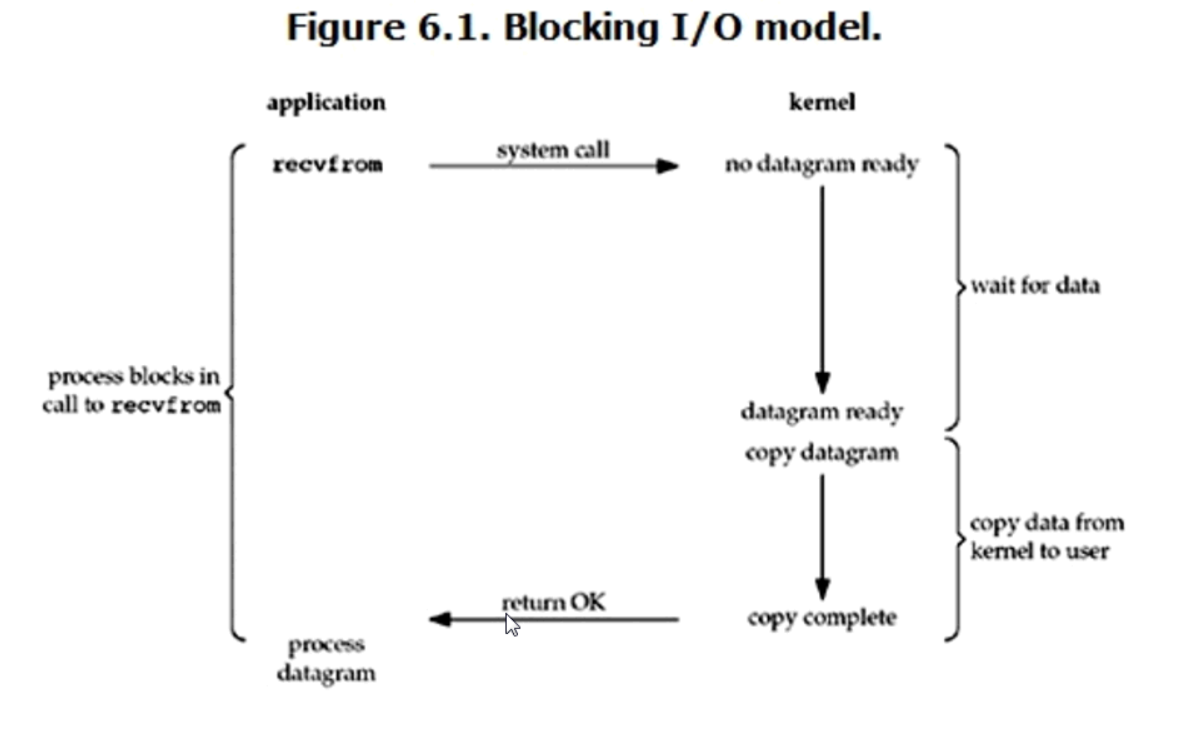
Under linux, the default sockets are blocking. Looking back on the sockets we used before, sock and conn are two connections. The server can only monitor one connection at the same time, so if the server is waiting for the client to send messages, other connections can not connect to the server.
In this mode, waiting for data and replicating data all need to wait, so the whole process is blocked.
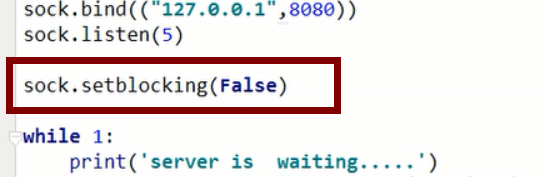
2.nonlocking IO (non-blocking IO)
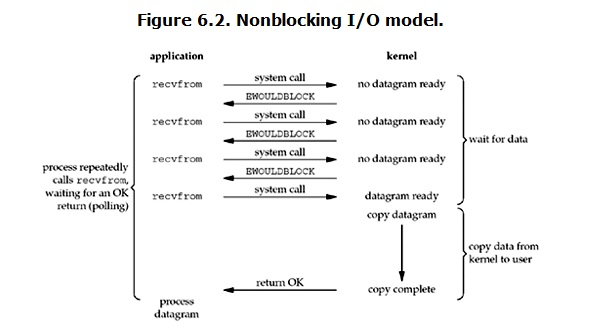
After the server establishes the connection, with this command, it becomes a non-blocking IO mode.
In this mode, if there is data, it will fetch it, and if there is no error, it can add an exception capture. It is not blocked while waiting for data, but it is blocked when copy ing data.
The advantage is that the waiting time can be used, but the disadvantage is also obvious: there are many system calls, which consume a lot; and when the program does something else, the data arrives, although it will not be lost, but the data received by the program is not real-time.
3.IO multiplexing (IO multiplexing)
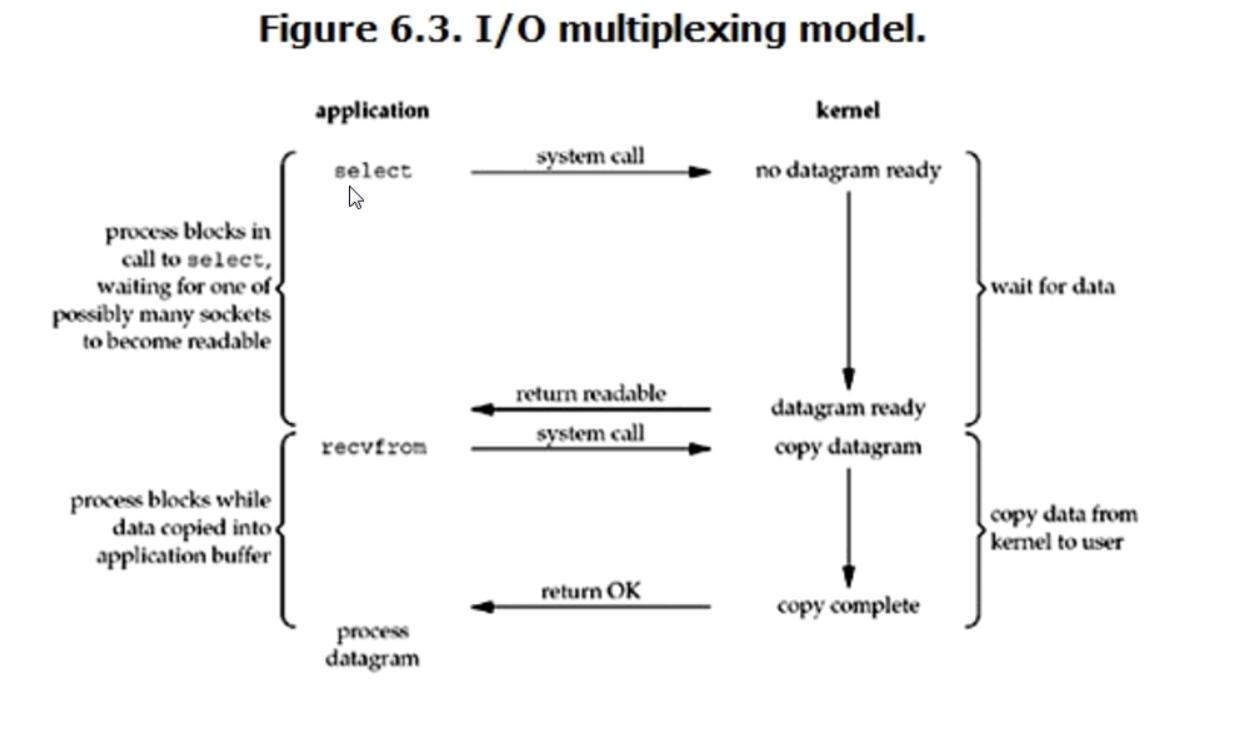
This is commonly used. The accept() we used before has two functions:
1. Monitor, Wait for Connection
2. Connecting
Now let's replace the first role of accept with select. The advantage of select is that it can listen to many objects, no matter which object activity is, it can react and collect the active objects into a list.
import socket
import select
sock=socket.socket()
sock.bind(('127.0.0.1',8080))
sock.listen(5)
inp=[sock,]
while True:
r=select.select(inp,[],[])
print('r',r[0])
for obj in r[0]:
if obj == sock:
conn,addr=obj.accept()
But the function of establishing connection is accept. With this, we can realize tcp chat in a concurrent way.
1 # Server
2 import socket
3 import time
4 import select
5
6 sock=socket.socket()
7 sock.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
8 sock.bind(('127.0.0.1',8080))
9 sock.listen(5)
10
11 inp=[sock,]#List of listening socket objects
12
13 while True:
14 r=select.select(inp,[],[])
15 print('r',r[0])
16 for obj in r[0]:
17 if obj == sock:
18 conn,addr=obj.accept()
19 inp.append(conn)
20 else:
21 data=obj.recv(1024)
22 print(data.decode('utf8'))
23 response=input('>>>>:')
24 obj.send(response.encode('utf8'))
Only when a connection is established, the sock is active, and the list will have this object. If after the connection is established, the active object is not sock, but conn in the process of sending and receiving messages. So in practice, it is necessary to judge whether the object in the list is sock.
In this model, the process of waiting for data and copy ing data is blocked, so it is also called full blocking. Compared with blocking IO model, the advantage of this model is to handle multiple connections.
In addition to select, IO multiplexing has two ways, poll and epoll.
Only select is supported under windows, but in linux, all three are supported. Epoll is the best, the only advantage of select is that it can be used on many platforms, but the disadvantage is also obvious, that is, the efficiency is very poor. poll is the intermediate transition between epoll and select. Compared with select, there is no limit to the number of polls that can be monitored. There is no maximum connection limit for epoll, and the monitoring mechanism is completely changed. The selection mechanism is polling (every data is checked once, even if it finds a change, it will continue to check). The epoll mechanism is a callback function, which calls the callback function if any object changes.
4. Asynchronous IO (Asynchronous IO)

This mode is non-blocking in the whole process, only non-blocking in the whole process can be called asynchronism. Although this mode looks good, but in practice, if the request volume is large, the efficiency will be very low, and the task of the operating system is very heavy.
Seventh, selectors module
If you learn this module, you don't need to use select, poll, or epoll. Their interfaces are all this module. We just need to know how to use this interface and what it encapsulates, without considering it.
In this module, the binding of sockets and functions uses a regesier() method. The usage of the module is very fixed. The example of the server side is as follows:
1 import selectors,socket
2
3 sel=selectors.DefaultSelector()
4
5 sock=socket.socket()
6 sock.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
7 sock.bind(('127.0.0.1',8080))
8 sock.listen(5)
9 sock.setblocking(False)
10
11 def read(conn,mask):
12 data=conn.recv(1024)
13 print(data.decode('utf8'))
14 res=input('>>>>>>:')
15 conn.send(res.encode('utf8'))
16
17 def accept(sock,mask):
18 conn,addr=sock.accept()
19 sel.register(conn,selectors.EVENT_READ,read)#conn and read Function binding
20 #Binding socket objects and functions
21 #Binding( register)Meaning, socket objects conn When a change occurs, the bound function can be executed
22 sel.register(sock,selectors.EVENT_READ,accept)#The middle one is fixed.
23 while True:
24 events=sel.select() #Listen for socket objects (the one registered)
25 #The following lines of code are basically fixed.
26 # print('events',events)
27 for key,mask in events:
28 callback = key.data#Binding functions,
29 # key.fileobj Is the active socket object
30 # print('callback',callable)
31 #mask It's fixed.
32 callback(key.fileobj,mask)#callback Is a callback function
33 # print('key.fileobj',key.fileobj)
Next article, database