Note: some pictures in this article come from the Internet. If there is infringement, please inform us to delete them
1. What is a process?
Before we understand the concept of process, we need to know the concept of program.
Program refers to compiled binary files. These files are on disk and do not occupy system resources.
Process refers to the execution instance of a program. It is the unit that the operating system allocates system resources. The system resources here include CPU time, memory, etc. When the program runs, a process is generated.
In other words, compared with a program, a process is a dynamic concept.
2. What is used to describe the process?
Process information is placed in a data structure called process control block, which can be understood as a collection of process attributes. It is called PCB (process control block) in the textbook. There are different PCBs under different operating systems. The process control block under Linux is task_struct.
task_struct is a data structure of the Linux kernel. When a process is created, the system will first load the program into memory and at the same time load the task_struct is loaded into memory in task_struct contains process information.
task_ The contents of struct are mainly divided into the following categories:
-
Identifier (PID): the unique identifier describing this process, which is used to distinguish other processes. It is essentially a non negative integer.
-
Process status: task status, exit code, exit signal, etc.
-
Context data: data in the processor's registers when the process executes.
-
Program counter: the address of the next instruction to be executed in a program.
-
The file descriptor table contains many pointers to the file structure.
-
Priority: the priority relative to other processes.
-
Other information.
3. PID,PPID
In order to facilitate management, there is the concept of parent-child process in the operating system. The child process will inherit the properties and permissions of the parent process, and the parent process can also systematically manage the child process.
The identifier of the process is PID, which is the unique identifier of the process, while the identifier of the parent process is PPID.
To view the parent-child relationship of a process, use the command ps axj
We run a. / test executable in the background and use the following command to view the parent-child information of the process

You can see that the process PID of this process is 7711 and its parent process PPID is 29455
To get the process id and parent process id, you can use the getpid() and getppid() functions:
Get the current process ID pid_t getpid(void);
Get the parent process ID of the current process pid_t getppid (void);
For example, after running the following code, you can output the id of the process and the id of the parent process
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("pid: %d\n", getpid());
printf("ppid: %d\n", getppid());
return 0;
}
Output results:

4. fork function
After running man 2 fork, you can see pid_t fork(void);
Fork function is a function used to create a child process. When the parent process calls fork function, a child process will be created. The code of the parent and child processes will be shared, and the data will open up space respectively.
In general, fork ing is usually followed by shunting, such as code 1
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if(id < 0){
perror("fork fail");
return 1;
}
else if(id == 0) {
//child
printf("g_val = %d,child_pid = %d , &g_val = %p\n",g_val,getpid(),&g_val);
}
else {
//parent
printf("g_val = %d,parent_pid = %d , &g_val = %p\n",g_val,getpid(),&g_val);
}
return 0;
}
The results are as follows
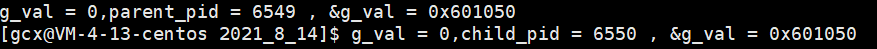
It can be seen that after shunting, the parent process executes the code with ID > 0, while the child process executes the code with id == 0, that is, fork has two return values. If the child process is created successfully, fork returns the PID of the child process to the parent process and 0 to the child process.
It should be noted that the subprocess executes the code after fork. Why?
After the parent process creates the child process, the parent-child process code is shared. The parent process will copy its own data to the child process, including the value of the parent process program counter. The program counter stores the address of the next instruction to be executed in the program. Because the parent process has executed the code before fork, the child process will execute the same as the parent process Code after fork.
5. Status of the process
When a process entity is loaded from disk to memory, the corresponding task_stuct will be created, and the processes have different states. In Linux, all processes running in the system exist in the kernel in the form of task_struct linked list. According to different states, you can
The process status is described in task_struct:
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};
R state: executable state. Only processes in this state can run on the processor. At the same time, multiple processes can be in R state at the same time. Except the processes on the processor, other processes in R state form a queue in the form of linked list and wait for the processor. The running state and ready state in the operating system textbook are unified as R state in Linux.
S state: an interruptible sleep state. A process is not running on the processor because it is waiting for some resources. This state is called s state. When it gets the waiting resources or receives some asynchronous signals, the process will wake up. Generally, use the ps command to view the process state. Most processes are in s state.
D state: deep sleep state. In this state, some asynchronous signals are not accepted. The reason for this state is that some operation requirements of the operating system are atomic operations, and the interference of other asynchronous signals can not be accepted. As long as the corresponding resources are not met, it will always be in D state. For example, kill -9 can not kill the process in D state. In practice, we use ps command It is almost impossible to capture processes in the D state, because atomic operations are often short-lived.
T status: the (T) process can be stopped by sending SIGSTOP signal to the process. The suspended process can continue to run by sending SIGCONT signal.
X status: death status, which is a return status and cannot be seen in the task list.
Z state: zombie state, which is a special state. When the process exits, if the parent process does not read the return code of the child process exit, the zombie process will be generated. The zombie process will remain in the process table in Z state and wait for the parent process to read its exit state. Even the process in exit state needs to be maintained with PCB, that is, If the parent process does not read the exit information of the child process, the PCB of the child process will always be in memory, resulting in memory leakage.
In addition to the zombie process, there may be another process in the system - orphan process. When the parent process exits first, the child process becomes an orphan process. At this time, the orphan process will be adopted by init process 1, and its PPID will become 1.
6. Process address space
We will change the code when we explain the fork function in Section 4
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if(id < 0){
perror("fork fail");
return 1;
}
else if(id == 0) {
//child
g_val = 10000;
printf("g_val = %d,child_pid = %d , &g_val = %p\n",g_val,getpid(),&g_val);
}
else {
//parent
sleep(3);//This code allows the parent process to sleep for 3s, ensures that the code of the child process is executed first, and allows the child process to modify g_val
printf("g_val = %d,parent_pid = %d , &g_val = %p\n",g_val,getpid(),&g_val);
}
return 0;
}
The results are as follows

We are surprised to find that the &g_val of the parent process and the child process are the same, but the g_val is actually different!
We know that it is impossible to store two different numbers in the same physical memory unit, that is, the address here is not the actual physical address, but the virtual address. So, how does the operating system manage the address space of the process?
6.1 mm_struct
For the operating system, the management method is to describe the data structure first, and then organize the data structure. We know that when a process is created, the corresponding PCB will be created. In Linux, task_ There is a structure in struct - struct mm_struct, which is the structure used to describe the virtual address of the process.
mm_ The source code of struct is as follows
struct mm_struct {
//Chain header pointing to linear area object
struct vm_area_struct * mmap; /* list of VMAs */
//Red black tree pointing to linear area object
struct rb_root mm_rb;
//Points to the most recently found virtual interval
struct vm_area_struct * mmap_cache; /* last find_vma result */
//A function used to search for a valid process address space in the process address space
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
unsigned long (*get_unmapped_exec_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
//The method called when releasing the linear area,
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
//Identifies the linear address of the first allocated file memory map
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
/*
* RHEL6 special for bug 790921: this same variable can mean
* two different things. If sysctl_unmap_area_factor is zero,
* this means the largest hole below free_area_cache. If the
* sysctl is set to a positive value, this variable is used
* to count how much memory has been munmapped from this process
* since the last time free_area_cache was reset back to mmap_base.
* This is ugly, but necessary to preserve kABI.
*/
unsigned long cached_hole_size;
//The kernel process searches the linear address space in the process address space
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
//Directory to page table
pgd_t * pgd;
//Number of shared processes
atomic_t mm_users; /* How many users with user space? */
//The main usage counter of memory descriptor adopts the principle of reference counting. When it is 0, it means that no user uses it again
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
//Number of linear regions
int map_count; /* number of VMAs */
struct rw_semaphore mmap_sem;
//Locks that protect task page tables and reference counts
spinlock_t page_table_lock; /* Protects page tables and some counters */
//mm_struct structure, the first member is the initialized mm_struct structure,
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
/* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
mm_counter_t _file_rss;
mm_counter_t _anon_rss;
mm_counter_t _swap_usage;
//Maximum number of page tables owned by the process
unsigned long hiwater_rss; /* High-watermark of RSS usage */,
//The maximum number of page tables in the process linear area
unsigned long hiwater_vm; /* High-water virtual memory usage */
//The size of the process address space, the number of pages locked that cannot be changed, the number of pages mapped in shared file memory, and the number of pages in executable memory mapping
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
//The number of pages in the user state stack,
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
//Maintain code snippets and data snippets
unsigned long start_code, end_code, start_data, end_data;
//Maintain heap and stack
unsigned long start_brk, brk, start_stack;
//Maintain command line parameters, start address and last address of command line parameters, and start address and last address of environment variables
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
struct linux_binfmt *binfmt;
cpumask_t cpu_vm_mask;
/* Architecture-specific MM context */
mm_context_t context;
/* Swap token stuff */
/*
* Last value of global fault stamp as seen by this process.
* In other words, this value gives an indication of how long
* it has been since this task got the token.
* Look at mm/thrash.c
*/
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
//Default access flag for linear area
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct hlist_head ioctx_list;
#endif
#ifdef CONFIG_MM_OWNER
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct *owner;
#endif
#ifdef CONFIG_PROC_FS
/* store ref to file /proc/<pid>/exe symlink points to */
struct file *exe_file;
unsigned long num_exe_file_vmas;
#endif
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
/* reserved for Red Hat */
#ifdef __GENKSYMS__
unsigned long rh_reserved[2];
#else
/* How many tasks sharing this mm are OOM_DISABLE */
union {
unsigned long rh_reserved_aux;
atomic_t oom_disable_count;
};
/* base of lib map area (ASCII armour) */
unsigned long shlib_base;
#endif
};
Therefore, the process address space is actually the structure mm_ In the virtual space described by struct, each process has its own virtual address space. The virtual address of each process is shown in the figure below.
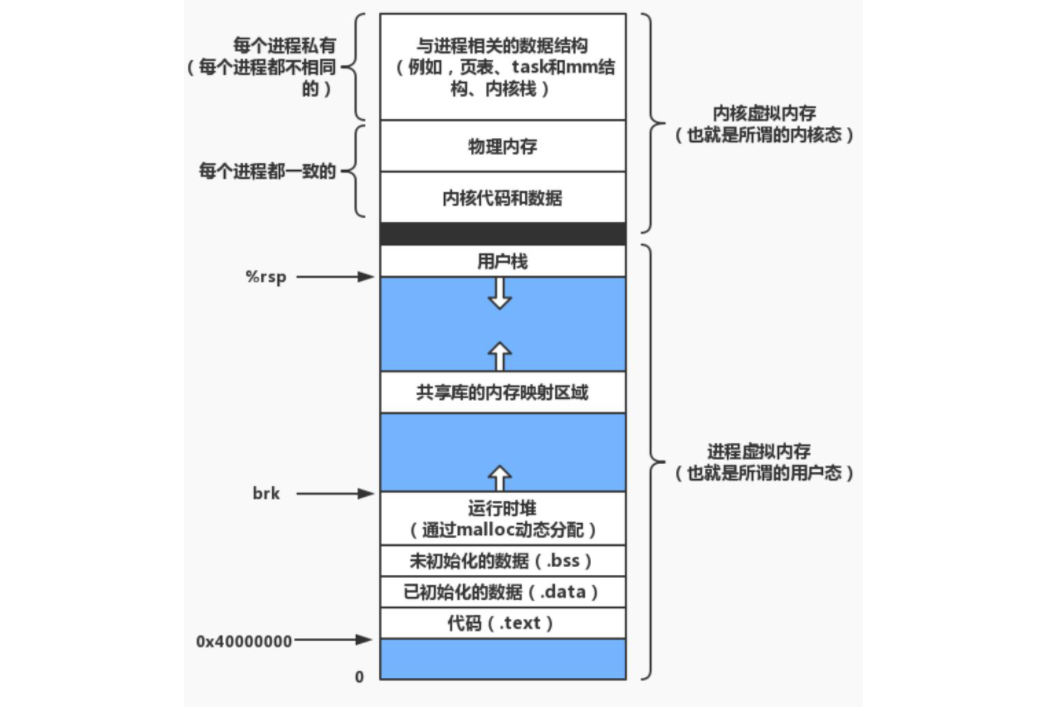
In Linux, the memory is managed by paging storage. Since the address we usually see is not the actual physical address, the operating system needs to map the virtual address to the physical address. The operating system realizes the mapping of virtual address and physical address with the help of page table. The essence of page table is also a data structure. The two main items are the mapping relationship between process virtual address and actual physical address.
6.2 copy on write
In our code, when fork creates a child process, it will change the mm of the parent process_ Struct is also copied to the child process. At first, there is only one g in memory_ Val, when the child process modifies g_val, because the data of the parent and child processes are private and the execution between processes should be independent, the child processes modify g_val should not affect the parent process. At this time, copy on write occurs, that is, the sub process opens up a new space in memory, fills the modified value into the space, and modifies the actual physical address of the virtual address mapping in the sub process page table.
Therefore, we see a scenario where the values stored in the same virtual address are different.
6.3 why is there a process address space?
This is because the introduction of process address space can ensure that the space used by each process is independent and continuous 3. The cross-border operation of one process will not affect another process, so memory protection is realized. At the same time, the address space of each process is much larger than the actual memory space, so the memory expansion can also be realized in a virtual way. When a process exits, we only need to clear the mm of the process_ Struct and page table, which is conducive to memory allocation and recycling.