1 Principle
knn is a very basic algorithm in the field of machine learning, which can solve classification or regression problems. If it is just beginning to learn machine learning, knn is a very good entry choice. It has the characteristics of easy understanding and simple implementation. Let's start to introduce the principle of its algorithm.
Firstly, the basic rule of knn algorithm is that samples of the same category should be clustered together in the feature space.
As shown in the figure below, suppose that the points in red, green and blue are distributed in two-dimensional space, which corresponds to that the training sample points in the classification task contain three categories and the number of features is 2.
If we want to speculate that the point of the hollow circle in the figure belongs to that category, the knn algorithm will calculate the distance between the point to be speculated and all training samples, and select the K samples with the smallest distance (k=4 is set here), then the 4 points connected with the in the figure will be regarded as the reference basis for the category of speculated hollow points (points to be speculated). Obviously, since these four points are all red categories, the point to be speculated is speculated as a red category.
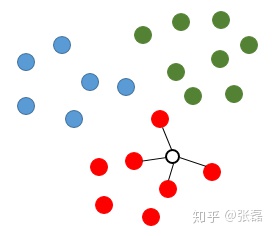
knn diagram 1
In another case, if the point to be speculated is in the middle (as shown in the figure below), the four nearest sample points are also calculated. At this time, the four sample points contain three categories (1 red, 1 blue and 2 green). In this case, knn algorithm usually uses voting method to speculate the category, That is, find out the category with the largest number of categories among the k sample points, so the type value of the point to be speculated is speculated as a green category.
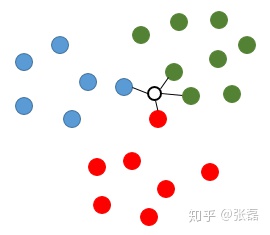
knn diagram 2
The principle of knn is so simple and simple. Some people will say that compared with other popular and more complex machine learning algorithms, such as neural network and random forest, what is the value of such a simple algorithm?
To answer this question, we may recall the famous no free lunch theorem in machine learning. For any problem (learning task), there is no best model. On the contrary, it just reminds us that for a specific learning task, we need to consider the most suitable learner for the problem, That is, the philosophical principle of specific analysis of specific problems.
Then, knn must have its value. For example, we need to choose a learner to solve the problem when we get a learning task, and there is no precedent for the study of the problem. So, where do we start?
Usually, we don't need to use a neural network model or a powerful integrated learning model to do it. Instead, we can use a simple model to "test". For example, knn is a good choice. What are the benefits of such "test"?
We know that knn is essentially a representative of lazy learning, that is, it does not use training data to fit a model at all, but directly uses top-k nearest neighbor sample points to vote to complete the classification task. Then, if such a lazy model can obtain a high accuracy in the current problem, Then we can think that the current learning task is relatively simple, the distribution of sample points of different categories in the feature space is relatively clear, and there is no need to use complex models,
On the contrary, if the accuracy obtained by knn is very low, the message conveyed to us is that the learning task is a little complex. The message is that the distribution of different types of sample points in the feature space is not clear, which is usually nonlinear and separable, so we need to call a more powerful learner. Thus, a simple knn machine learning algorithm can just help modelers have a general judgment on the complexity of the problem and help us how to carry out further work: continue to mine Feature Engineering, or replace complex models.
2 algorithm implementation
Next, use python to implement a knn classifier yourself.
Code link: https://github.com/zlxy9892/ml_code/tree/master/basic_algorithm/knn
First, create a file named knn.py to build the class implemented by KNN. The code is as follows.
# -*- coding: utf-8 -*-
import numpy as np
import operator
class KNN(object):
def __init__(self, k=3):
self.k = k
def fit(self, x, y):
self.x = x
self.y = y
def _square_distance(self, v1, v2):
return np.sum(np.square(v1-v2))
def _vote(self, ys):
ys_unique = np.unique(ys)
vote_dict = {}
for y in ys:
if y not in vote_dict.keys():
vote_dict[y] = 1
else:
vote_dict[y] += 1
sorted_vote_dict = sorted(vote_dict.items(), key=operator.itemgetter(1), reverse=True)
return sorted_vote_dict[0][0]
def predict(self, x):
y_pred = []
for i in range(len(x)):
dist_arr = [self._square_distance(x[i], self.x[j]) for j in range(len(self.x))]
sorted_index = np.argsort(dist_arr)
top_k_index = sorted_index[:self.k]
y_pred.append(self._vote(ys=self.y[top_k_index]))
return np.array(y_pred)
def score(self, y_true=None, y_pred=None):
if y_true is None and y_pred is None:
y_pred = self.predict(self.x)
y_true = self.y
score = 0.0
for i in range(len(y_true)):
if y_true[i] == y_pred[i]:
score += 1
score /= len(y_true)
return scoreNext, create a train.py file to generate random training sample data, call knn class to complete the classification task, and calculate the inference accuracy.
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from knn import *
# data generation
np.random.seed(314)
data_size_1 = 300
x1_1 = np.random.normal(loc=5.0, scale=1.0, size=data_size_1)
x2_1 = np.random.normal(loc=4.0, scale=1.0, size=data_size_1)
y_1 = [0 for _ in range(data_size_1)]
data_size_2 = 400
x1_2 = np.random.normal(loc=10.0, scale=2.0, size=data_size_2)
x2_2 = np.random.normal(loc=8.0, scale=2.0, size=data_size_2)
y_2 = [1 for _ in range(data_size_2)]
x1 = np.concatenate((x1_1, x1_2), axis=0)
x2 = np.concatenate((x2_1, x2_2), axis=0)
x = np.hstack((x1.reshape(-1,1), x2.reshape(-1,1)))
y = np.concatenate((y_1, y_2), axis=0)
data_size_all = data_size_1+data_size_2
shuffled_index = np.random.permutation(data_size_all)
x = x[shuffled_index]
y = y[shuffled_index]
split_index = int(data_size_all*0.7)
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
# visualize data
plt.scatter(x_train[:,0], x_train[:,1], c=y_train, marker='.')
plt.show()
plt.scatter(x_test[:,0], x_test[:,1], c=y_test, marker='.')
plt.show()
# data preprocessing
x_train = (x_train - np.min(x_train, axis=0)) / (np.max(x_train, axis=0) - np.min(x_train, axis=0))
x_test = (x_test - np.min(x_test, axis=0)) / (np.max(x_test, axis=0) - np.min(x_test, axis=0))
# knn classifier
clf = KNN(k=3)
clf.fit(x_train, y_train)
print('train accuracy: {:.3}'.format(clf.score()))
y_test_pred = clf.predict(x_test)
print('test accuracy: {:.3}'.format(clf.score(y_test, y_test_pred)))So far, the principle of knn algorithm and code implementation are introduced.