This article is reproduced from the official account of "good future technology". The use of Flink CDC 2 is introduced in the case of Flink SQL, and the core design of CDC is interpreted. The main contents are as follows:
- case
- Core design
- Code explanation
GitHub address
https://github.com/apache/flink
Welcome to like Flink and send star~
In August, Flink CDC released version 2.0.0. Compared with version 1.0, it supports distributed reading and checkpoint in the full reading stage, and ensures data consistency without locking the table in the process of full + incremental reading. Detailed introduction reference Flink CDC 2.0 was officially released to explain the core improvements.
Flink CDC 2.0 data reading logic is not complex, but FLIP-27: Refactor Source Interface Design of and lack of understanding of Debezium Api. This paper focuses on the processing logic of Flink CDC, FLIP-27 The design of and the API call of Debezium will not be explained too much.
Using CDC version 2.0.0, this paper first introduces the use of Flink CDC 2.0 with the case of Flink SQL, then introduces the core design in CDC, including slice division, segmentation reading and incremental reading, and finally explains the call and implementation of Flink MySQL CDC interface in the process of data processing.
1, Case
Full read + incremental read Mysql table data, write kafka in changelog JSON format, and observe RowKind type and the number of data affected.
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings envSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
env.setParallelism(3);
// note: incremental synchronization needs to be enabled
env.enableCheckpointing(10000);
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env, envSettings);
tableEnvironment.executeSql(" CREATE TABLE demoOrders (\n" +
" `order_id` INTEGER ,\n" +
" `order_date` DATE ,\n" +
" `order_time` TIMESTAMP(3),\n" +
" `quantity` INT ,\n" +
" `product_id` INT ,\n" +
" `purchaser` STRING,\n" +
" primary key(order_id) NOT ENFORCED" +
" ) WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = 'localhost',\n" +
" 'port' = '3306',\n" +
" 'username' = 'cdc',\n" +
" 'password' = '123456',\n" +
" 'database-name' = 'test',\n" +
" 'table-name' = 'demo_orders'," +
// Full + incremental synchronization
" 'scan.startup.mode' = 'initial' " +
" )");
tableEnvironment.executeSql("CREATE TABLE sink (\n" +
" `order_id` INTEGER ,\n" +
" `order_date` DATE ,\n" +
" `order_time` TIMESTAMP(3),\n" +
" `quantity` INT ,\n" +
" `product_id` INT ,\n" +
" `purchaser` STRING,\n" +
" primary key (order_id) NOT ENFORCED " +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'properties.bootstrap.servers' = 'localhost:9092',\n" +
" 'topic' = 'mqTest02',\n" +
" 'format' = 'changelog-json' "+
")");
tableEnvironment.executeSql("insert into sink select * from demoOrders");}Full data output:
{"data":{"order_id":1010,"order_date":"2021-09-17","order_time":"2021-09-22 10:52:12.189","quantity":53,"product_id":502,"purchaser":"flink"},"op":"+I"}
{"data":{"order_id":1009,"order_date":"2021-09-17","order_time":"2021-09-22 10:52:09.709","quantity":31,"product_id":500,"purchaser":"flink"},"op":"+I"}
{"data":{"order_id":1008,"order_date":"2021-09-17","order_time":"2021-09-22 10:52:06.637","quantity":69,"product_id":503,"purchaser":"flink"},"op":"+I"}
{"data":{"order_id":1007,"order_date":"2021-09-17","order_time":"2021-09-22 10:52:03.535","quantity":52,"product_id":502,"purchaser":"flink"},"op":"+I"}
{"data":{"order_id":1002,"order_date":"2021-09-17","order_time":"2021-09-22 10:51:51.347","quantity":69,"product_id":503,"purchaser":"flink"},"op":"+I"}
{"data":{"order_id":1001,"order_date":"2021-09-17","order_time":"2021-09-22 10:51:48.783","quantity":50,"product_id":502,"purchaser":"flink"},"op":"+I"}
{"data":{"order_id":1000,"order_date":"2021-09-17","order_time":"2021-09-17 17:40:32.354","quantity":30,"product_id":500,"purchaser":"flink"},"op":"+I"}
{"data":{"order_id":1006,"order_date":"2021-09-17","order_time":"2021-09-22 10:52:01.249","quantity":31,"product_id":500,"purchaser":"flink"},"op":"+I"}
{"data":{"order_id":1005,"order_date":"2021-09-17","order_time":"2021-09-22 10:51:58.813","quantity":69,"product_id":503,"purchaser":"flink"},"op":"+I"}
{"data":{"order_id":1004,"order_date":"2021-09-17","order_time":"2021-09-22 10:51:56.153","quantity":50,"product_id":502,"purchaser":"flink"},"op":"+I"}
{"data":{"order_id":1003,"order_date":"2021-09-17","order_time":"2021-09-22 10:51:53.727","quantity":30,"product_id":500,"purchaser":"flink"},"op":"+I"}Modify table data to capture incrementally:
## Update the value of 1005
{"data":{"order_id":1005,"order_date":"2021-09-17","order_time":"2021-09-22 02:51:58.813","quantity":69,"product_id":503,"purchaser":"flink"},"op":"-U"}
{"data":{"order_id":1005,"order_date":"2021-09-17","order_time":"2021-09-22 02:55:43.627","quantity":80,"product_id":503,"purchaser":"flink"},"op":"+U"}
## Delete 1000
{"data":{"order_id":1000,"order_date":"2021-09-17","order_time":"2021-09-17 09:40:32.354","quantity":30,"product_id":500,"purchaser":"flink"},"op":"-D"}
2, Core design
1. Slice Division
The data reading method of the full volume stage is distributed reading. The current table data will be divided into multiple chunks according to the primary key, and the subsequent subtasks will read the data in the Chunk interval. According to whether the primary key column is a self increasing integer type, the table data is divided into evenly distributed chunks and non uniformly distributed chunks.
1.1 uniform distribution
The primary key column is self incremented and the type is integer (int,bigint,decimal). Query the minimum and maximum values of the primary key column, and divide the data evenly according to the chunkSize. Because the primary key is of integer type, the end position of the chunk is calculated directly according to the current chunk start position and chunkSize.
Note: the trigger condition of uniform distribution in the latest version no longer depends on whether the primary key column is self incremented. The primary key column is required to be of integer type, and the data distribution coefficient is calculated according to max(id) - min(id)/rowcount. The data will be evenly divided only if the distribution coefficient < = the configured distribution coefficient (even-distribution.factor is 1000.0d by defau lt).
// Calculate primary key column data range select min(`order_id`), max(`order_id`) from demo_orders; // Divide the data into chunkSize sized slices chunk-0: [min,start + chunkSize) chunk-1: [start + chunkSize, start + 2chunkSize) ....... chunk-last: [max,null)
1.2 non uniform distribution
The primary key column is not self incrementing or is of non integer type. The primary key is a non numeric type. The undivided data needs to be arranged in ascending order according to the primary key for each partition. The maximum value of the previous chunkSize is the end position of the current chunk.
Note: the trigger condition for non-uniform distribution in the latest version is that the primary key column is of non integer type, or the calculated distribution factor > the configured distribution factor (even-distribution. Factor).
// After sorting the undivided data, take chunkSize data and take the maximum value as the termination position of the slice.
chunkend = SELECT MAX(`order_id`) FROM (
SELECT `order_id` FROM `demo_orders`
WHERE `order_id` >= [Start position of previous slice]
ORDER BY `order_id` ASC
LIMIT [chunkSize]
) AS T2. Full slice data reading
Flink divides the table data into multiple chunks, and the subtasks read the Chunk data in parallel without locking. Because there is no lock in the whole process, other transactions may modify the data within the slice during the data slice reading process. At this time, the data consistency cannot be guaranteed. Therefore, in the full volume stage, Flink uses snapshot record reading + Binlog data correction to ensure data consistency.
2.1 snapshot reading
Execute SQL query on the data record of slice range through JDBC.
## Snapshot record data reading SQL SELECT * FROM `test`.`demo_orders` WHERE order_id >= [chunkStart] AND NOT (order_id = [chunkEnd]) AND order_id <= [chunkEnd]
2.2 data correction
Before and after the snapshot reading operation, execute SHOW MASTER STATUS to query the current offset of binlog file. After the snapshot is read, query the binlog data in the interval and correct the read snapshot records.
Data organization structure during snapshot reading + Binlog data reading:

BinlogEvents modifies the snapshot events rule.
- The binlog data is not read, that is, no other transactions are operated during the select phase, and all snapshot records are directly distributed.
- When binlog data is read and the changed data record does not belong to the current slice, issue a snapshot record.
- binlog data is read, and the change of data record belongs to the current slice. The delete operation removes the data from the snapshot memory, the insert operation adds new data to the snapshot memory, and the update operation adds change records to the snapshot memory. Finally, two records before and after the update will be output to the downstream.
Revised data organization structure:

Taking reading the data in the range of slice [1,11] as an example, the processing process of slice data is described. c. d and u represent the add, delete and update operations captured by Debezium.
Data and structure before correction:

Revised data and structure:

After a single slice data is processed, it will send the start position (ChunkStart, ChunkStartEnd) of the completed slice data and the maximum offset (High watermark) of Binlog to the SplitEnumerator to specify the start offset for incremental reading.
3. Incremental slice data reading
After reading the slice data in the full volume phase, the SplitEnumerator will issue a BinlogSplit for incremental data reading. The most important attribute of BinlogSplit reading is the start offset. If the offset is set too small, there may be duplicate data in the downstream. If the offset is set too large, there may be expired dirty data in the downstream. The initial offset read by Flink CDC increment is the Binlog offset with the smallest of all completed full slices, and only the data meeting the conditions will be distributed downstream. Data distribution conditions:
- The offset of the captured Binlog data > the maximum offset of the Binlog of the partition to which the data belongs.
For example, the completed slice information retained by SplitEnumerator is:
| Slice index | Chunk data range | Maximum Binlog read by slice |
|---|---|---|
| 0 | [1,100] | 1000 |
| 1 | [101,200] | 800 |
| 2 | [201,300] | 1500 |
During incremental reading, the Binlog data is read from the offset 800. When the data < data: 123, offset: 1500 > is captured, first find the snapshot fragment to which 123 belongs, and find the corresponding maximum Binlog offset 800. If the current offset is greater than the maximum offset of the snapshot read, the data will be distributed, otherwise it will be discarded directly.
3, Code explanation
about FLIP-27: Refactor Source Interface The design is not introduced in detail. This paper focuses on the call and implementation of the Flink MySQL CDC interface.
1. MySQL sourceenumerator initialization
As the implementation of the Source by the operator coordinator, the SourceCoordinator runs on the Master node. At startup, it creates a MySQL sourceenumerator by calling MySQL parallelsource#createenumerator and calls the start method to do some initialization work.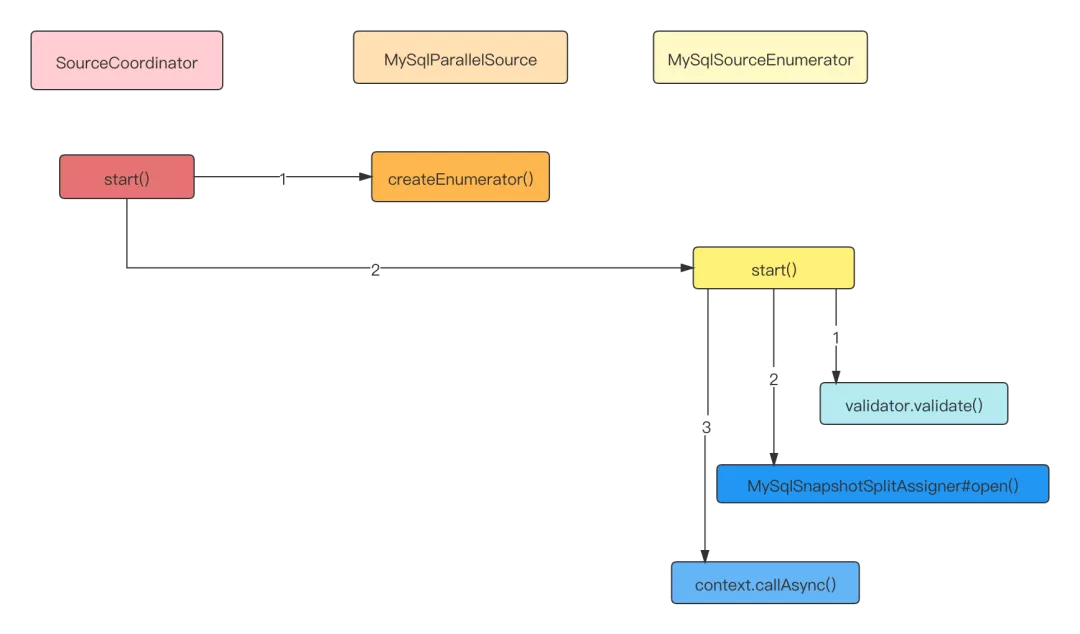
- Create a mysql sourceenumerator, slice the full + incremental data with mysql hybridsplitassignor, and verify the mysql version and configuration with mysql validator.
MySQL validator validation:
- mysql version must be greater than or equal to 5.7.
- binlog_format configuration must be ROW.
- binlog_row_image configuration must be FULL.
MySQL splitassigner initialization:
- Create a ChunkSplitter to divide slices.
- Filter out the table names to read.
- Start the cycle scheduling thread and ask SourceReader to send slice information of completed but not sent ACK events to SourceEnumerator.
private void syncWithReaders(int[] subtaskIds, Throwable t) {
if (t != null) {
throw new FlinkRuntimeException("Failed to list obtain registered readers due to:", t);
}
// when the SourceEnumerator restores or the communication failed between
// SourceEnumerator and SourceReader, it may missed some notification event.
// tell all SourceReader(s) to report there finished but unacked splits.
if (splitAssigner.waitingForFinishedSplits()) {
for (int subtaskId : subtaskIds) {
// note: send FinishedSnapshotSplitsRequestEvent
context.sendEventToSourceReader(
subtaskId, new FinishedSnapshotSplitsRequestEvent());
}
}
}2. MySQL sourcereader initialization
SourceOperator integrates SourceReader and interacts with SourceCoordinator through operator event gateway.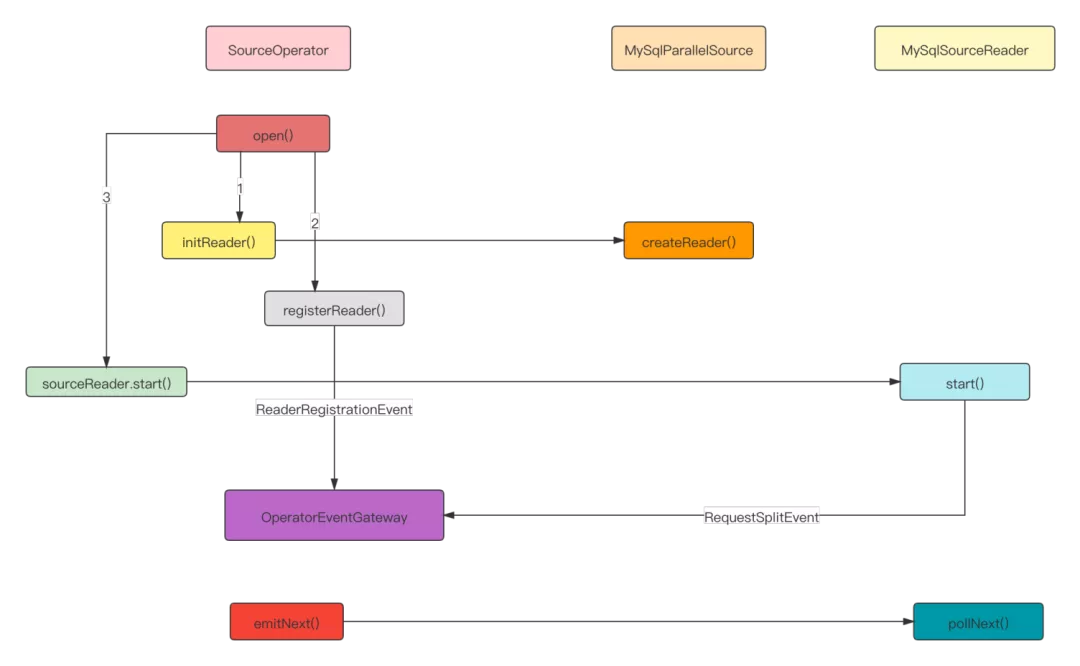
- When the SourceOperator initializes, it creates a MySQL sourcereader through MySQL parallelsource. MySQL sourcereader creates a Fetcher through SingleThreadFetcherManager to pull fragment data, and writes the data to elementsQueue in MySQL records format.
MySqlParallelSource#createReader
public SourceReader<T, MySqlSplit> createReader(SourceReaderContext readerContext) throws Exception {
// note: data storage queue
FutureCompletingBlockingQueue<RecordsWithSplitIds<SourceRecord>> elementsQueue =
new FutureCompletingBlockingQueue<>();
final Configuration readerConfiguration = getReaderConfig(readerContext);
// note: Split Reader factory class
Supplier<MySqlSplitReader> splitReaderSupplier =
() -> new MySqlSplitReader(readerConfiguration, readerContext.getIndexOfSubtask());
return new MySqlSourceReader<>(
elementsQueue,
splitReaderSupplier,
new MySqlRecordEmitter<>(deserializationSchema),
readerConfiguration,
readerContext);
}- Pass the created MySQL sourcereader as an event to the SourceCoordinator for registration. After receiving the registration event, the SourceCoordinator saves the reader address and index.
SourceCoordinator#handleReaderRegistrationEvent
// note: SourceCoordinator handles Reader registration events
private void handleReaderRegistrationEvent(ReaderRegistrationEvent event) {
context.registerSourceReader(new ReaderInfo(event.subtaskId(), event.location()));
enumerator.addReader(event.subtaskId());
}- After MySQL sourcereader is started, it will send a request fragment event to MySQL sourceenumerator to collect the allocated slice data.
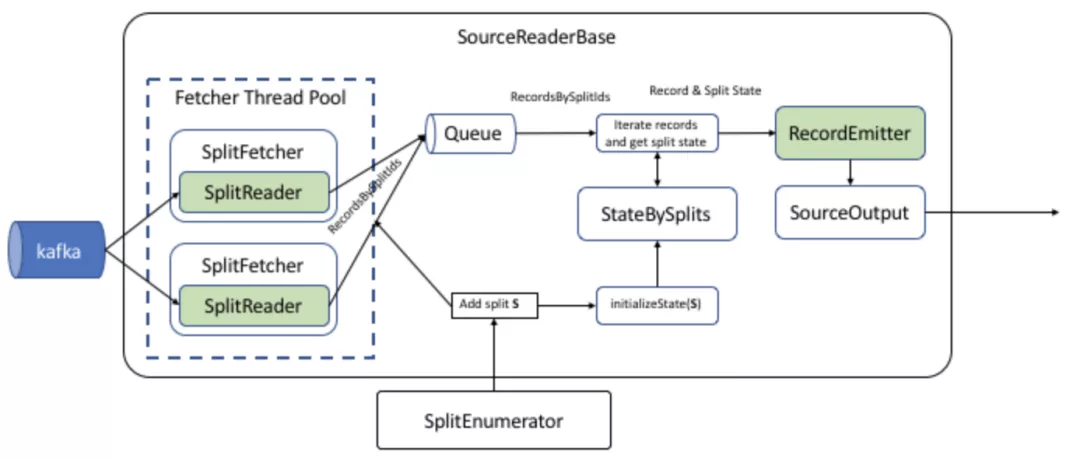
- After SourceOperator is initialized, the emitNext is called by SourceReaderBase to get the data set from elementsQueue and send it to MySqlRecordEmitter. Interface call diagram:
3. MySQL sourceenumerator handles fragmentation requests
When MySQL sourcereader is started, it will send a RequestSplitEvent event to MySQL sourceenumerator to read interval data according to the returned slice range. The MySQL sourceenumerator uses the fragment request processing logic in the full read phase, and finally returns a MySQL snapshot split. 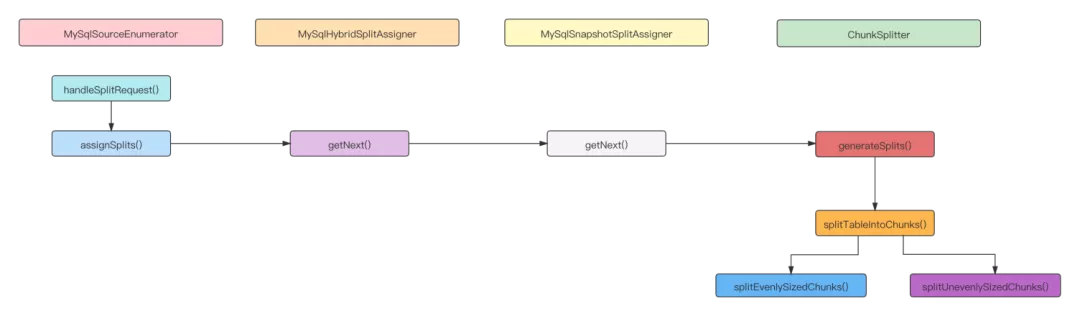
- Process slice request events, allocate slices for the requested Reader, and transfer MySQL split (full volume stage MySQL snapshot split, incremental stage MySQL binlogsplit) by sending AddSplitEvent time.
MySqlSourceEnumerator#handleSplitRequest
public void handleSplitRequest(int subtaskId, @Nullable String requesterHostname) {
if (!context.registeredReaders().containsKey(subtaskId)) {
// reader failed between sending the request and now. skip this request.
return;
}
// note: store the subtask ID to which the reader belongs in TreeSet, and give priority to task-0 when processing binlog split
readersAwaitingSplit.add(subtaskId);
assignSplits();
}
// note: assign slices
private void assignSplits() {
final Iterator<Integer> awaitingReader = readersAwaitingSplit.iterator();
while (awaitingReader.hasNext()) {
int nextAwaiting = awaitingReader.next();
// if the reader that requested another split has failed in the meantime, remove
// it from the list of waiting readers
if (!context.registeredReaders().containsKey(nextAwaiting)) {
awaitingReader.remove();
continue;
}
//note: assign slices by MySQL splitassigner
Optional<MySqlSplit> split = splitAssigner.getNext();
if (split.isPresent()) {
final MySqlSplit mySqlSplit = split.get();
// note: send AddSplitEvent and return slice information for Reader
context.assignSplit(mySqlSplit, nextAwaiting);
awaitingReader.remove();
LOG.info("Assign split {} to subtask {}", mySqlSplit, nextAwaiting);
} else {
// there is no available splits by now, skip assigning
break;
}
}
}MySQL hybridsplitassigner handles the logic of full slice and incremental slice.
- When the task is just started, remainingTables is not empty, the return value of nomoreplits is false, and a snapshot split is created.
- After the full volume phase fragment reading is completed, the return value of nomoreplits is true and BinlogSplit is created.
MySqlHybridSplitAssigner#getNext
@Override
public Optional<MySqlSplit> getNext() {
if (snapshotSplitAssigner.noMoreSplits()) {
// binlog split assigning
if (isBinlogSplitAssigned) {
// no more splits for the assigner
return Optional.empty();
} else if (snapshotSplitAssigner.isFinished()) {
// we need to wait snapshot-assigner to be finished before
// assigning the binlog split. Otherwise, records emitted from binlog split
// might be out-of-order in terms of same primary key with snapshot splits.
isBinlogSplitAssigned = true;
//Note: after the snapshot split slice is completed, create a BinlogSplit.
return Optional.of(createBinlogSplit());
} else {
// binlog split is not ready by now
return Optional.empty();
}
} else {
// note: SnapshotSplit created by MySQL snapshotsplitassigner
// snapshot assigner still have remaining splits, assign split from it
return snapshotSplitAssigner.getNext();
}
}
- MySQL snapshot splitassigner handles the full amount of slicing logic, generates slices through ChunkSplitter and stores them in the Iterator.
@Override
public Optional<MySqlSplit> getNext() {
if (!remainingSplits.isEmpty()) {
// return remaining splits firstly
Iterator<MySqlSnapshotSplit> iterator = remainingSplits.iterator();
MySqlSnapshotSplit split = iterator.next();
iterator.remove();
//note: the allocated tiles are stored in the assignedSplits collection
assignedSplits.put(split.splitId(), split);
return Optional.of(split);
} else {
// note: in the initialization phase, remainingTables stores the table names to be read
TableId nextTable = remainingTables.pollFirst();
if (nextTable != null) {
// split the given table into chunks (snapshot splits)
// note: ChunkSplitter is created in the initialization phase, and generateSplits is called for slicing
Collection<MySqlSnapshotSplit> splits = chunkSplitter.generateSplits(nextTable);
// note: keep all slice information
remainingSplits.addAll(splits);
// note: the fragmented Table has been completed
alreadyProcessedTables.add(nextTable);
// note: call the method recursively
return getNext();
} else {
return Optional.empty();
}
}
}- ChunkSplitter is the logic that divides the table into evenly distributed or unevenly distributed slices. The read table must contain a physical primary key.
public Collection<MySqlSnapshotSplit> generateSplits(TableId tableId) {
Table schema = mySqlSchema.getTableSchema(tableId).getTable();
List<Column> primaryKeys = schema.primaryKeyColumns();
// note: there must be a primary key
if (primaryKeys.isEmpty()) {
throw new ValidationException(
String.format(
"Incremental snapshot for tables requires primary key,"
+ " but table %s doesn't have primary key.",
tableId));
}
// use first field in primary key as the split key
Column splitColumn = primaryKeys.get(0);
final List<ChunkRange> chunks;
try {
// note: divide data into multiple slices by primary key column
chunks = splitTableIntoChunks(tableId, splitColumn);
} catch (SQLException e) {
throw new FlinkRuntimeException("Failed to split chunks for table " + tableId, e);
}
//note: convert the primary key data type and wrap the ChunkRange into MySQL snapshot split.
// convert chunks into splits
List<MySqlSnapshotSplit> splits = new ArrayList<>();
RowType splitType = splitType(splitColumn);
for (int i = 0; i < chunks.size(); i++) {
ChunkRange chunk = chunks.get(i);
MySqlSnapshotSplit split =
createSnapshotSplit(
tableId, i, splitType, chunk.getChunkStart(), chunk.getChunkEnd());
splits.add(split);
}
return splits;
}- splitTableIntoChunks divides slices based on physical primary keys.
private List<ChunkRange> splitTableIntoChunks(TableId tableId, Column splitColumn)
throws SQLException {
final String splitColumnName = splitColumn.name();
// select min, max
final Object[] minMaxOfSplitColumn = queryMinMax(jdbc, tableId, splitColumnName);
final Object min = minMaxOfSplitColumn[0];
final Object max = minMaxOfSplitColumn[1];
if (min == null || max == null || min.equals(max)) {
// empty table, or only one row, return full table scan as a chunk
return Collections.singletonList(ChunkRange.all());
}
final List<ChunkRange> chunks;
if (splitColumnEvenlyDistributed(splitColumn)) {
// use evenly-sized chunks which is much efficient
// note: evenly divided by primary key
chunks = splitEvenlySizedChunks(min, max);
} else {
// note: non uniform division by primary key
// use unevenly-sized chunks which will request many queries and is not efficient.
chunks = splitUnevenlySizedChunks(tableId, splitColumnName, min, max);
}
return chunks;
}
/** Checks whether split column is evenly distributed across its range. */
private static boolean splitColumnEvenlyDistributed(Column splitColumn) {
// only column is auto-incremental are recognized as evenly distributed.
// TODO: we may use MAX,MIN,COUNT to calculate the distribution in the future.
if (splitColumn.isAutoIncremented()) {
DataType flinkType = MySqlTypeUtils.fromDbzColumn(splitColumn);
LogicalTypeRoot typeRoot = flinkType.getLogicalType().getTypeRoot();
// currently, we only support split column with type BIGINT, INT, DECIMAL
return typeRoot == LogicalTypeRoot.BIGINT
|| typeRoot == LogicalTypeRoot.INTEGER
|| typeRoot == LogicalTypeRoot.DECIMAL;
} else {
return false;
}
}
/**
* Split the table into evenly sized blocks according to the minimum and maximum values of the split column, and scroll the blocks in {@ link #chunkSize} steps.
* Split table into evenly sized chunks based on the numeric min and max value of split column,
* and tumble chunks in {@link #chunkSize} step size.
*/
private List<ChunkRange> splitEvenlySizedChunks(Object min, Object max) {
if (ObjectUtils.compare(ObjectUtils.plus(min, chunkSize), max) > 0) {
// there is no more than one chunk, return full table as a chunk
return Collections.singletonList(ChunkRange.all());
}
final List<ChunkRange> splits = new ArrayList<>();
Object chunkStart = null;
Object chunkEnd = ObjectUtils.plus(min, chunkSize);
// chunkEnd <= max
while (ObjectUtils.compare(chunkEnd, max) <= 0) {
splits.add(ChunkRange.of(chunkStart, chunkEnd));
chunkStart = chunkEnd;
chunkEnd = ObjectUtils.plus(chunkEnd, chunkSize);
}
// add the ending split
splits.add(ChunkRange.of(chunkStart, null));
return splits;
}
/** Split the table into blocks with uneven size by continuously calculating the maximum value of the next block.
* Split table into unevenly sized chunks by continuously calculating next chunk max value. */
private List<ChunkRange> splitUnevenlySizedChunks(
TableId tableId, String splitColumnName, Object min, Object max) throws SQLException {
final List<ChunkRange> splits = new ArrayList<>();
Object chunkStart = null;
Object chunkEnd = nextChunkEnd(min, tableId, splitColumnName, max);
int count = 0;
while (chunkEnd != null && ObjectUtils.compare(chunkEnd, max) <= 0) {
// we start from [null, min + chunk_size) and avoid [null, min)
splits.add(ChunkRange.of(chunkStart, chunkEnd));
// may sleep a while to avoid DDOS on MySQL server
maySleep(count++);
chunkStart = chunkEnd;
chunkEnd = nextChunkEnd(chunkEnd, tableId, splitColumnName, max);
}
// add the ending split
splits.add(ChunkRange.of(chunkStart, null));
return splits;
}
private Object nextChunkEnd(
Object previousChunkEnd, TableId tableId, String splitColumnName, Object max)
throws SQLException {
// chunk end might be null when max values are removed
Object chunkEnd =
queryNextChunkMax(jdbc, tableId, splitColumnName, chunkSize, previousChunkEnd);
if (Objects.equals(previousChunkEnd, chunkEnd)) {
// we don't allow equal chunk start and end,
// should query the next one larger than chunkEnd
chunkEnd = queryMin(jdbc, tableId, splitColumnName, chunkEnd);
}
if (ObjectUtils.compare(chunkEnd, max) >= 0) {
return null;
} else {
return chunkEnd;
}
}4. MySQL sourcereader handles slice allocation requests
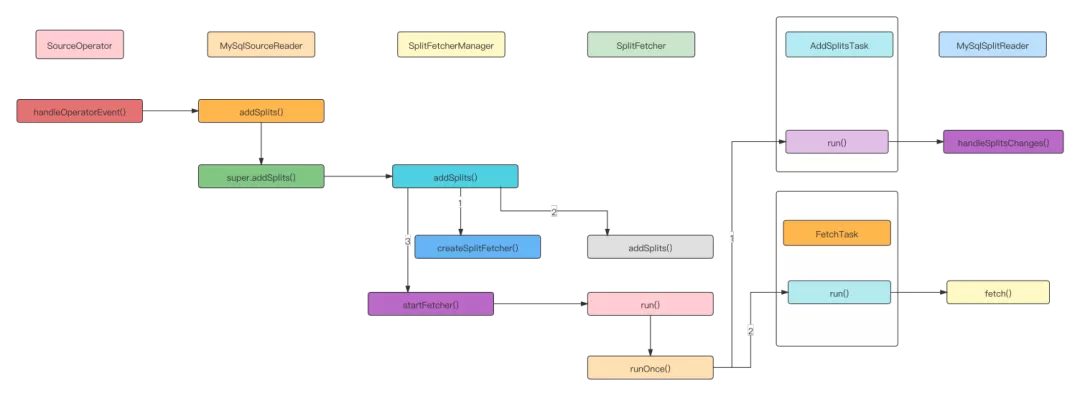
After receiving the slice allocation request, MySQL sourcereader will first create a SplitFetcher thread, add and execute the addsplittask task task to the taskQueue to handle the adding slice task, then execute the FetchTask, use the Debezium API to read the data, store the read data in the elementsQueue, and SourceReaderBase will get the data from the queue, And send it to MySQL recordemitter.
- When processing slice allocation events, create a SplitFetcher and add addsplittaskto the taskQueue.
SingleThreadFetcherManager#addSplits
public void addSplits(List<SplitT> splitsToAdd) {
SplitFetcher<E, SplitT> fetcher = getRunningFetcher();
if (fetcher == null) {
fetcher = createSplitFetcher();
// Add the splits to the fetchers.
fetcher.addSplits(splitsToAdd);
startFetcher(fetcher);
} else {
fetcher.addSplits(splitsToAdd);
}
}
// Create SplitFetcher
protected synchronized SplitFetcher<E, SplitT> createSplitFetcher() {
if (closed) {
throw new IllegalStateException("The split fetcher manager has closed.");
}
// Create SplitReader.
SplitReader<E, SplitT> splitReader = splitReaderFactory.get();
int fetcherId = fetcherIdGenerator.getAndIncrement();
SplitFetcher<E, SplitT> splitFetcher =
new SplitFetcher<>(
fetcherId,
elementsQueue,
splitReader,
errorHandler,
() -> {
fetchers.remove(fetcherId);
elementsQueue.notifyAvailable();
});
fetchers.put(fetcherId, splitFetcher);
return splitFetcher;
}
public void addSplits(List<SplitT> splitsToAdd) {
enqueueTask(new AddSplitsTask<>(splitReader, splitsToAdd, assignedSplits));
wakeUp(true);
}
- Execute the SplitFetcher thread. For the first time, execute the addsplittask thread to add fragments, and then execute the FetchTask thread to pull data.
SplitFetcher#runOnce
void runOnce() {
try {
if (shouldRunFetchTask()) {
runningTask = fetchTask;
} else {
runningTask = taskQueue.take();
}
if (!wakeUp.get() && runningTask.run()) {
LOG.debug("Finished running task {}", runningTask);
runningTask = null;
checkAndSetIdle();
}
} catch (Exception e) {
throw new RuntimeException(
String.format(
"SplitFetcher thread %d received unexpected exception while polling the records",
id),
e);
}
maybeEnqueueTask(runningTask);
synchronized (wakeUp) {
// Set the running task to null. It is necessary for the shutdown method to avoid
// unnecessarily interrupt the running task.
runningTask = null;
// Set the wakeUp flag to false.
wakeUp.set(false);
LOG.debug("Cleaned wakeup flag.");
}
}- Addsplittask calls the handleSplitsChanges method of MySQL splitreader to add the allocated slice information to the slice queue. On the next fetch() call, the slice is fetched from the queue and the slice data is read.
AddSplitsTask#run
public boolean run() {
for (SplitT s : splitsToAdd) {
assignedSplits.put(s.splitId(), s);
}
splitReader.handleSplitsChanges(new SplitsAddition<>(splitsToAdd));
return true;
}
MySqlSplitReader#handleSplitsChanges
public void handleSplitsChanges(SplitsChange<MySqlSplit> splitsChanges) {
if (!(splitsChanges instanceof SplitsAddition)) {
throw new UnsupportedOperationException(
String.format(
"The SplitChange type of %s is not supported.",
splitsChanges.getClass()));
}
//note: add slice to queue.
splits.addAll(splitsChanges.splits());
}- MySQL splitreader executes fetch(), and DebeziumReader reads the data to the event queue. After correcting the data, it returns in MySQL records format.
MySqlSplitReader#fetch
@Override
public RecordsWithSplitIds<SourceRecord> fetch() throws IOException {
// note: create Reader and read data
checkSplitOrStartNext();
Iterator<SourceRecord> dataIt = null;
try {
// note: correct the read data
dataIt = currentReader.pollSplitRecords();
} catch (InterruptedException e) {
LOG.warn("fetch data failed.", e);
throw new IOException(e);
}
// note: the returned data is encapsulated as MySQL records for transmission
return dataIt == null
? finishedSnapshotSplit()
: MySqlRecords.forRecords(currentSplitId, dataIt);
}
private void checkSplitOrStartNext() throws IOException {
// the binlog reader should keep alive
if (currentReader instanceof BinlogSplitReader) {
return;
}
if (canAssignNextSplit()) {
// note: read MySQL split from slice queue
final MySqlSplit nextSplit = splits.poll();
if (nextSplit == null) {
throw new IOException("Cannot fetch from another split - no split remaining");
}
currentSplitId = nextSplit.splitId();
// note: distinguish between full slice reading and incremental slice reading
if (nextSplit.isSnapshotSplit()) {
if (currentReader == null) {
final MySqlConnection jdbcConnection = getConnection(config);
final BinaryLogClient binaryLogClient = getBinaryClient(config);
final StatefulTaskContext statefulTaskContext =
new StatefulTaskContext(config, binaryLogClient, jdbcConnection);
// note: create a snapshot splitreader, and use the Debezium Api to read the allocation data and interval Binlog values
currentReader = new SnapshotSplitReader(statefulTaskContext, subtaskId);
}
} else {
// point from snapshot split to binlog split
if (currentReader != null) {
LOG.info("It's turn to read binlog split, close current snapshot reader");
currentReader.close();
}
final MySqlConnection jdbcConnection = getConnection(config);
final BinaryLogClient binaryLogClient = getBinaryClient(config);
final StatefulTaskContext statefulTaskContext =
new StatefulTaskContext(config, binaryLogClient, jdbcConnection);
LOG.info("Create binlog reader");
// note: create a BinlogSplitReader and use the Debezium API for incremental reading
currentReader = new BinlogSplitReader(statefulTaskContext, subtaskId);
}
// note: execute Reader to read data
currentReader.submitSplit(nextSplit);
}
}5. DebeziumReader data processing
DebeziumReader includes two stages: full slice reading and incremental slice reading. After reading, the data is stored in ChangeEventQueue and corrected when pollSplitRecords is executed.
- Snapshot splitreader full slice read. For data reading in the full volume stage, query the table data within the slice range by executing the Select statement, and write the current offset when executing SHOW MASTER STATUS before and after writing to the queue.
public void submitSplit(MySqlSplit mySqlSplit) {
......
executor.submit(
() -> {
try {
currentTaskRunning = true;
// note: for data reading, insert the current offset of Binlog before and after the data
// 1. execute snapshot read task.
final SnapshotSplitChangeEventSourceContextImpl sourceContext =
new SnapshotSplitChangeEventSourceContextImpl();
SnapshotResult snapshotResult =
splitSnapshotReadTask.execute(sourceContext);
// note: prepare for incremental reading, including the starting offset
final MySqlBinlogSplit appendBinlogSplit = createBinlogSplit(sourceContext);
final MySqlOffsetContext mySqlOffsetContext =
statefulTaskContext.getOffsetContext();
mySqlOffsetContext.setBinlogStartPoint(
appendBinlogSplit.getStartingOffset().getFilename(),
appendBinlogSplit.getStartingOffset().getPosition());
// note: read from start offset
// 2. execute binlog read task
if (snapshotResult.isCompletedOrSkipped()) {
// we should only capture events for the current table,
Configuration dezConf =
statefulTaskContext
.getDezConf()
.edit()
.with(
"table.whitelist",
currentSnapshotSplit.getTableId())
.build();
// task to read binlog for current split
MySqlBinlogSplitReadTask splitBinlogReadTask =
new MySqlBinlogSplitReadTask(
new MySqlConnectorConfig(dezConf),
mySqlOffsetContext,
statefulTaskContext.getConnection(),
statefulTaskContext.getDispatcher(),
statefulTaskContext.getErrorHandler(),
StatefulTaskContext.getClock(),
statefulTaskContext.getTaskContext(),
(MySqlStreamingChangeEventSourceMetrics)
statefulTaskContext
.getStreamingChangeEventSourceMetrics(),
statefulTaskContext
.getTopicSelector()
.getPrimaryTopic(),
appendBinlogSplit);
splitBinlogReadTask.execute(
new SnapshotBinlogSplitChangeEventSourceContextImpl());
} else {
readException =
new IllegalStateException(
String.format(
"Read snapshot for mysql split %s fail",
currentSnapshotSplit));
}
} catch (Exception e) {
currentTaskRunning = false;
LOG.error(
String.format(
"Execute snapshot read task for mysql split %s fail",
currentSnapshotSplit),
e);
readException = e;
}
});
}- SnapshotSplitReader incremental slice read. The focus of slice reading in the incremental phase is to judge when BinlogSplitReadTask stops, and the offset when reading to the end of the slice phase is terminated.
MySqlBinlogSplitReadTask#handleEvent
protected void handleEvent(Event event) {
// note: event distribution queue
super.handleEvent(event);
// note: the Binlog reading needs to be terminated in the full reading phase
// check do we need to stop for read binlog for snapshot split.
if (isBoundedRead()) {
final BinlogOffset currentBinlogOffset =
new BinlogOffset(
offsetContext.getOffset().get(BINLOG_FILENAME_OFFSET_KEY).toString(),
Long.parseLong(
offsetContext
.getOffset()
.get(BINLOG_POSITION_OFFSET_KEY)
.toString()));
// Note: currentbinlogoffset > HW stop reading
// reach the high watermark, the binlog reader should finished
if (currentBinlogOffset.isAtOrBefore(binlogSplit.getEndingOffset())) {
// send binlog end event
try {
signalEventDispatcher.dispatchWatermarkEvent(
binlogSplit,
currentBinlogOffset,
SignalEventDispatcher.WatermarkKind.BINLOG_END);
} catch (InterruptedException e) {
logger.error("Send signal event error.", e);
errorHandler.setProducerThrowable(
new DebeziumException("Error processing binlog signal event", e));
}
// Terminate binlog read
// tell reader the binlog task finished
((SnapshotBinlogSplitChangeEventSourceContextImpl) context).finished();
}
}
}- When the snapshot splitreader executes pollSplitRecords, it corrects the original data in the queue. See RecordUtils#normalizedSplitRecords for specific processing logic.
public Iterator<SourceRecord> pollSplitRecords() throws InterruptedException {
if (hasNextElement.get()) {
// data input: [low watermark event][snapshot events][high watermark event][binlogevents][binlog-end event]
// data output: [low watermark event][normalized events][high watermark event]
boolean reachBinlogEnd = false;
final List<SourceRecord> sourceRecords = new ArrayList<>();
while (!reachBinlogEnd) {
// note: handles the DataChangeEvent event written in the queue
List<DataChangeEvent> batch = queue.poll();
for (DataChangeEvent event : batch) {
sourceRecords.add(event.getRecord());
if (RecordUtils.isEndWatermarkEvent(event.getRecord())) {
reachBinlogEnd = true;
break;
}
}
}
// snapshot split return its data once
hasNextElement.set(false);
// ************Correction data***********
return normalizedSplitRecords(currentSnapshotSplit, sourceRecords, nameAdjuster)
.iterator();
}
// the data has been polled, no more data
reachEnd.compareAndSet(false, true);
return null;
}- BinlogSplitReader data read. The reading logic is relatively simple, focusing on the setting of the starting offset, which is the HW of all slices.
- When BinlogSplitReader executes pollSplitRecords, it modifies the original data in the queue to ensure data consistency. The Binlog reading in the incremental phase is unbounded, and all data will be distributed to the event queue. The BinlogSplitReader judges whether the data is distributed through shouldEmit().
BinlogSplitReader#pollSplitRecords
public Iterator<SourceRecord> pollSplitRecords() throws InterruptedException {
checkReadException();
final List<SourceRecord> sourceRecords = new ArrayList<>();
if (currentTaskRunning) {
List<DataChangeEvent> batch = queue.poll();
for (DataChangeEvent event : batch) {
if (shouldEmit(event.getRecord())) {
sourceRecords.add(event.getRecord());
}
}
}
return sourceRecords.iterator();
}Event issuing conditions:
- The newly received event post is greater than maxwm;
- The current data value belongs to a snapshot, the spike & offset is greater than HWM, and the data is distributed.
/**
*
* Returns the record should emit or not.
*
* <p>The watermark signal algorithm is the binlog split reader only sends the binlog event that
* belongs to its finished snapshot splits. For each snapshot split, the binlog event is valid
* since the offset is after its high watermark.
*
* <pre> E.g: the data input is :
* snapshot-split-0 info : [0, 1024) highWatermark0
* snapshot-split-1 info : [1024, 2048) highWatermark1
* the data output is:
* only the binlog event belong to [0, 1024) and offset is after highWatermark0 should send,
* only the binlog event belong to [1024, 2048) and offset is after highWatermark1 should send.
* </pre>
*/
private boolean shouldEmit(SourceRecord sourceRecord) {
if (isDataChangeRecord(sourceRecord)) {
TableId tableId = getTableId(sourceRecord);
BinlogOffset position = getBinlogPosition(sourceRecord);
// aligned, all snapshot splits of the table has reached max highWatermark
// note: if the newly received event post is greater than maxwm, it will be distributed directly
if (position.isAtOrBefore(maxSplitHighWatermarkMap.get(tableId))) {
return true;
}
Object[] key =
getSplitKey(
currentBinlogSplit.getSplitKeyType(),
sourceRecord,
statefulTaskContext.getSchemaNameAdjuster());
for (FinishedSnapshotSplitInfo splitInfo : finishedSplitsInfo.get(tableId)) {
/**
* note: The current data value belongs to a snapshot spike & offset greater than HWM, and the data is distributed
*/
if (RecordUtils.splitKeyRangeContains(
key, splitInfo.getSplitStart(), splitInfo.getSplitEnd())
&& position.isAtOrBefore(splitInfo.getHighWatermark())) {
return true;
}
}
// not in the monitored splits scope, do not emit
return false;
}
// always send the schema change event and signal event
// we need record them to state of Flink
return true;
}6. MySQL recordemitter data distribution
SourceReaderBase obtains the DataChangeEvent data collection read by the slice from the queue and converts the data type from the DataChangeEvent of Debezium to the RowData type of Flink.
- SourceReaderBase processes sliced data.
org.apache.flink.connector.base.source.reader.SourceReaderBase#pollNextpublic InputStatus pollNext(ReaderOutput<T> output) throws Exception { // make sure we have a fetch we are working on, or move to the next RecordsWithSplitIds<E> recordsWithSplitId = this.currentFetch; if (recordsWithSplitId == null) { recordsWithSplitId = getNextFetch(output); if (recordsWithSplitId == null) {return trace (finishedoravailablelater());}} / / we need to loop here, because we may have to go across splits while (true) {/ / process one record. / / Note: read a single piece of data from the iterator through MySQL records. Final e record = recordswithsplitid. Nextrecordfromsplit(); if (record! = null) { // emit the record. recordEmitter.emitRecord(record, currentSplitOutput, currentSplitContext.state); LOG.trace("Emitted record: {}", record) ; // We always emit MORE_AVAILABLE here, even though we do not strictly know whether // more is available. If nothing more is available, the next invocation will find // this out and return the correct status. // That means we emit the occasional 'false positive' for availability, but this // saves us doing checks for every record. Ultimately, this is cheaper. return trace(InputStatus.MORE_AVAILABLE); } else if (!moveToNextSplit(recordsWithSplitId, output)) { // The fetch is done and we just discovered that and have not emitted anything, yet. // We need to move to the next fetch. As a shortcut, we call pollNext() here again, // rather than emitting nothing and waiting for the caller to call us again. return pollNext(output); } //Else false through the loop}}private recordswithsplitids < E > getnextfetch (final readeroutput < T > output) {splitfetchermanager. Checkerrors(); log.trace ("getting next source data batch from queue"); / / Note: get data from elementsQueue final recordswithsplitids < E > recordswithsplitid = elementsQueue. Poll(); if (recordsWithSplitId == null || !moveToNextSplit(recordsWithSplitId, output)) { return null; } currentFetch = recordsWithSplitId; return recordsWithSplitId;}- MySQL records returns a single data set.
com.ververica.cdc.connectors.mysql.source.split.MySqlRecords#nextRecordFromSplitpublic SourceRecord nextRecordFromSplit() { final Iterator<SourceRecord> recordsForSplit = this.recordsForCurrentSplit; if (recordsForSplit != null) { if (recordsForSplit.hasNext()) { return recordsForSplit.next(); } else { return null; } } else { throw new IllegalStateException(); }}- MySQL recordemitter converts data to Rowdata through RowDataDebeziumDeserializeSchema.
com.ververica.cdc.connectors.mysql.source.reader.MySqlRecordEmitter#emitRecordpublic void emitRecord(SourceRecord element, SourceOutput<T> output, MySqlSplitState splitState) throws Exception {if (isWatermarkEvent(element)) { BinlogOffset watermark = getWatermark(element); if (isHighWatermarkEvent(element) && splitState.isSnapshotSplitState()) { splitState.asSnapshotSplitState().setHighWatermark (watermark); }} else if (isSchemaChangeEvent(element) && splitState.isBinlogSplitState()) { HistoryRecord historyRecord = getHistoryRecord(element); Array tableChanges = historyRecord.document().getArray(HistoryRecord.Fields.TABLE_CHANGES); TableChanges changes = TABLE_CHANGE_SERIALIZER.deserialize(tableChanges, true) ; for (tablechanges. Tablechange tablechange: changes) {splitstate. Asbinlogsplitstate(). Recordschema (tablechange. Getid(), tablechange);}} else if (isdatachangerecord (element)) {/ / Note: data processing if (splitstate. Isbinlogsplitstate()) {binlogoffset position = getbinlogposition (element) ; splitState.asBinlogSplitState().setStartingOffset(position); } debeziumDeserializationSchema.deserialize( element, new Collector<T>() { @Override public void collect(final T t) { output.collect(t); } @Override public void close() { // do nothing } });} else { // unknown element LOG.info("Meet unknown element {}, just skip.", element);}}RowDataDebeziumDeserializeSchema serialization process.
com.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema#deserializepublic void deserialize(SourceRecord record, Collector<RowData> out) throws Exception { Envelope.Operation op = Envelope.operationFor(record); Struct value = (Struct) record.value(); Schema valueSchema = record.valueSchema(); if (op == Envelope.Operation.CREATE || op == Envelope.Operation.READ) { GenericRowData insert = extractAfterRow(value, valueSchema); validator.validate(insert, RowKind.INSERT); insert.setRowKind(RowKind.INSERT); out.collect(insert); } else if (op == Envelope.Operation.DELETE) { GenericRowData delete = extractBeforeRow(value, valueSchema); validator.validate(delete, RowKind.DELETE); delete.setRowKind(RowKind.DELETE); out.collect(delete); } else { GenericRowData before = extractBeforeRow(value, valueSchema); validator.validate(before, RowKind.UPDATE_BEFORE); before.setRowKind(RowKind.UPDATE_BEFORE); out.collect(before); GenericRowData after = extractAfterRow(value, valueSchema); validator.validate(after, RowKind.UPDATE_AFTER); after.setRowKind(RowKind.UPDATE_AFTER); out.collect(after); }}7. MySQL sourcereader reports the slice reading completion event
After MySQL sourcereader processes a full slice, it will send the completed slice information to MySQL sourceenumerator, including slice ID and HighWatermar, and then continue to send slice requests.
com.ververica.cdc.connectors.mysql.source.reader.MySqlSourceReader#onSplitFinishedprotected void onSplitFinished(Map<String, MySqlSplitState> finishedSplitIds) {for (MySqlSplitState mySqlSplitState : finishedSplitIds.values()) { MySqlSplit mySqlSplit = mySqlSplitState.toMySqlSplit(); finishedUnackedSplits.put(mySqlSplit.splitId(), mySqlSplit.asSnapshotSplit());} /*** Note: send slice completion event * / reportfinishedsnapshotsplifneed(); / / continue sending slice request context. Sendsplitrequest();} private void reportfinishedsnapshotsplifneed() {if (! Finishedunackedsplits. Isempty()) {final map < string, binlogoffset > finishedoffsets = new HashMap < > (); for (MySQL snapshotsplit: finishedunackedsplits. Values()) {/ / Note: send slice ID and maximum offset finishedoffsets.put (split. Splitid(), split. Gethighwatermark());} finishedsnapshotsplitreportevent reportevent = new finishedsnapshotsplitreportevent (finishedoffsets) ; context.sendSourceEventToCoordinator(reportEvent); LOG.debug( "The subtask {} reports offsets of finished snapshot splits {}.", subtaskId, finishedOffsets); }}8. MySQL sourceenumerator allocates incremental slices
After reading all fragments in the full volume phase, MySQL hybridsplitassignor will create BinlogSplit for subsequent incremental reading. When creating BinlogSplit, it will filter the minimum BinlogOffset from all completed full volume slices. Note: the minimum offset of createBinlogSplit in 2.0.0 branch always starts from 0, and this BUG has been repaired in the latest master branch.
private MySqlBinlogSplit createBinlogSplit() { final List<MySqlSnapshotSplit> assignedSnapshotSplit = snapshotSplitAssigner.getAssignedSplits().values().stream() .sorted(Comparator.comparing(MySqlSplit::splitId)) .collect(Collectors.toList()); Map<String, BinlogOffset> splitFinishedOffsets = snapshotSplitAssigner.getSplitFinishedOffsets(); final List<FinishedSnapshotSplitInfo> finishedSnapshotSplitInfos = new ArrayList<>(); final Map<TableId, TableChanges.TableChange> tableSchemas = new HashMap<>(); BinlogOffset minBinlogOffset = null; // note: filter the minimum offset from all assignedsnapshotsplits for (MySQL snapshotsplit split: assignedsnapshotsplit) {/ / find the min binlog offset binlogoffset binlogoffset = splitfinishedoffsets.get (split. Splitid()); if (minbinlogoffset = = null | binlogoffset. CompareTo (minbinlogoffset) < 0) { minBinlogOffset = binlogOffset; } finishedSnapshotSplitInfos.add( new FinishedSnapshotSplitInfo( split.getTableId(), split.splitId(), split.getSplitStart(), split.getSplitEnd(), binlogOffset)) ; tableSchemas.putAll(split.getTableSchemas()); } final MySqlSnapshotSplit lastSnapshotSplit = assignedSnapshotSplit.get(assignedSnapshotSplit.size() - 1).asSnapshotSplit(); return new MySqlBinlogSplit( BINLOG_SPLIT_ID, lastSnapshotSplit.getSplitKeyType() , minBinlogOffset == null ? BinlogOffset.INITIAL_OFFSET : minBinlogOffset, BinlogOffset.NO_STOPPING_OFFSET, finishedSnapshotSplitInfos, tableSchemas);}On December 4-5, Flink Forward Asia 2021 was launched, with 40 + multi industry first-line manufacturers and 80 + dry goods issues around the world, bringing a technical feast for developers.
https://flink-forward.org.cn/
In addition, the first Flink Forward Asia Hackathon was officially launched, and the 10W bonus is waiting for you!
https://www.aliyun.com/page-source//tianchi/promotion/FlinkForwardAsiaHackathon
For more Flink related technical issues, you can scan the code to join the community nail exchange group
For the first time, get the latest technical articles and community trends. Please pay attention to the official account number.

Activity recommendation
Alibaba cloud's enterprise class product based on Apache Flink - real time computing Flink version is now launched:
99 yuan trial Real time computing Flink Edition (monthly package, 10CU) you have the opportunity to get Flink's exclusive custom-made clothes; there is also a 85% discount for 3 months and above!
Learn more about the event: https://www.aliyun.com/product/bigdata/sc
