Introduction to Presto
- Presto is a distributed SQL query engine developed by Facebook for efficient and real-time data analysis.
- Presto can connect Hive, Mysql, Kafka and other data sources. The most common way to connect Hive data sources is through Presto, which can solve the problem that Hive's MapReduce query takes too long.
- Presto is a memory-based computing engine that does not store data by itself and uses a rich Connector to obtain data from third-party services, such as Hive data sources stored on HDFS, loading data into memory for calculation, and querying data quickly.
Presto's data model
- Catalog: Data sources, such as Hive and Mysql, are data sources. Presto can connect multiple Hives and multiple Mysqls.
- Schema: Like DataBase, there are multiple Schemas under a Catalog;
- Table: Data table, there are multiple data tables under a Schema.
Example Presto query statement:
# Connect multiple data sources for query select * from hive.testdb.tableA a join mysql.testdb.tableB where a.id = b.id # View all data sources supported by Presto show catalogs # View all Schema s show schemas
Query Presto commands through the Presto client
# Port number defaults to 7670--catalog specifies the connection's data source--schema specifies the connection's database ./presto-cli-0.212-executable.jar ip:Port number --catalog hive --schema default
Architecture of Presto
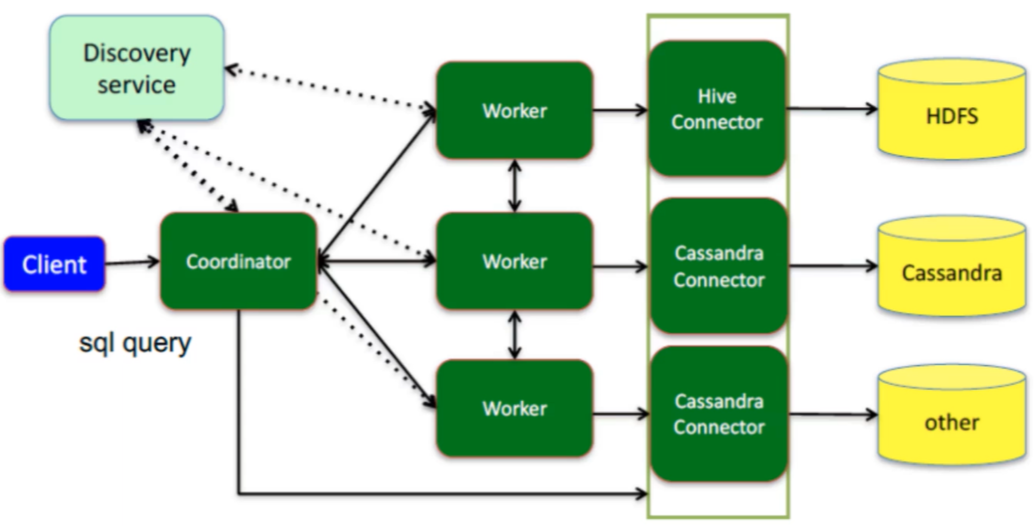
Presto is also a master-slave architecture consisting of three parts: a Coordinator node, a Discovery Server node, and multiple Worker nodes.
Coordinator is the primary node responsible for parsing SQL statements, generating query plans, and distributing execution tasks;
Discovery Server maintains the relationship between Coordinator and Worker and is usually embedded in Coordinator nodes.
The Worker node is responsible for performing query tasks and reading data interactively with the data source.
Schema diagram for Presto connection to Hive data source:
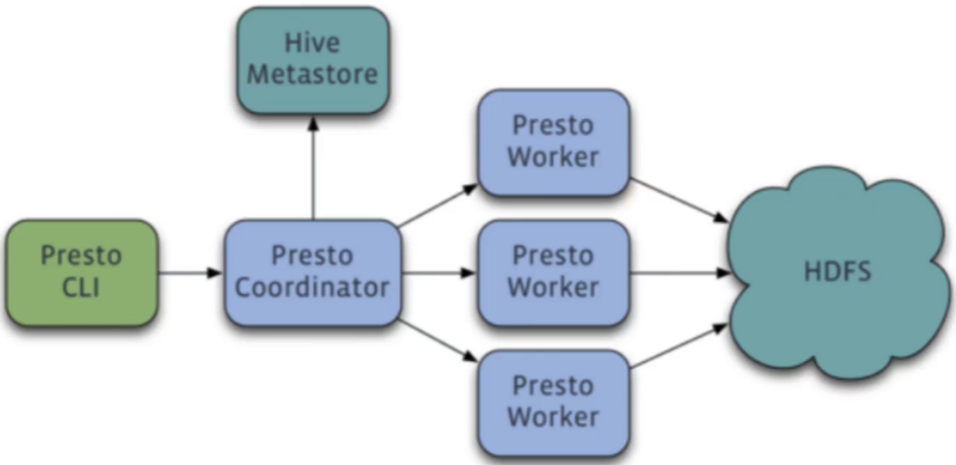
How it works: PrestoCoordinator receives SQL statements sent by Presto clients, parses SQL statements based on Hive's metadata information, generates query plans, and distributes tasks to multiple Worker nodes. Worker nodes read data from HDFS into memory for calculation, and returns the results to Coordinator nodes, which then returns data to Presto clients.
Schema diagram for Presto connection to multiple data sources:
Java Programs Access Presto
In Java programs, Presto is accessed through JDBC, just like Mysql databases are accessed through JDBC, for example:
<!--Import Dependency-->
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-jdbc</artifactId>
<version>0.212</version>
</dependency>
public static void main(String[] args) throws SQLException {
// Register presto driver
try {
Class.forName("com.facebook.presto.jdbc.PrestoDriver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
// Get the presto connection (specify url, username, password)
Connection connection = DriverManager.getConnection("jdbc:presto://192.168.110.112:7670/hive/default", "root", "123456");
// Execute SQL Query
Statement statement = connection.createStatement();
ResultSet res = statement.executeQuery("show tables");
while (res.next()) {
System.out.println(res.getString(1));
}
res.close();
// Suppose table tableA has two fields
ResultSet resultSet = statement.executeQuery("select * from tableA");
while (res.next()) {
System.out.println(resultSet.getString(1) + "---" + resultSet.getString(2));
}
resultSet.close();
connection.close();
}