HashSet
To understand the hashSet, we need to look at its code, so I created a new hashSet, and then ctrl clicked in to see this
public HashSet() {
map = new HashMap<>();
}
We can see that the parameterless constructor of HashSet is actually a map, but here, I have another question. We all know that the map structure is a key value pair, that is (key, value) format, and we only need to enter a value when using set. Then the problem comes. Since the bottom layer of HashSet is HashMap, where is the key of HashMap?
With this question, I went down again and found this
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
We found that when adding, the value we passed in will be placed in the position of key, and a PRESENT will be placed in the place where the value is placed, and the latter is all capitalized. I have a look. It is a constant (because it is modified by final, the value cannot change, which is equivalent to null)
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
It turns out that the data stored in our set is actually the location of the key of the map, which makes sense. Why can't we repeat the set, and we can only put one value in the square data, which was originally placed on the key of the map
As for why map key s cannot be repeated, let's continue to explore HashMap
HashMap
Referring to the exploration method of our HashSet, let's explore HashMap. First, the construction method of HashMap. Let's take a look at the parameterless constructor
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
Huh? What is this loadFactor? Go to see
final float loadFactor; static final float DEFAULT_LOAD_FACTOR = 0.75f;
Oh, it turned out to be a constant or a float type, * * explain DEFAULT_LOAD_FACTOR, it seems to be called a load factor, which defaults to 0.75. My personal understanding is probably something like space utilization. For example, there is a 100 container, but only 75 of the space is available. If I want to put an 80 size thing, I need to expand the capacity of my 100 container to about 80 / 0.75 = 106.67, and I can just put down 80** Understanding is a constant, but we don't see anything useful, such as how map is implemented, so let's continue to look at it
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
I think everyone knows this construction method. If you don't, I'll briefly introduce it. It's almost equivalent to a clone copy. Create a new object from your original map and pass the original map value to him.
But the key is not this constructor. The key is putMapEntries. How does this method put our original < key, value >
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
The code is a little long and I can't understand it all, but it doesn't matter. Just understand the last foreach loop. * * we see that we are clearly a map structure with the format of < key, value >, but what is the format of < key, value >** This foreach loop gives us a good answer. It is stored by Entry. What is Entry?
interface Entry<K,V> {
K getKey();
V getValue();
boolean equals(Object o);
int hashCode();
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
The method annotation is a little long, so you can delete it. If you are interested, you can go back and have a look. The key point I want to express is, do you look familiar with the key, value, hashCode and even equals in the Entry? It's not much different from the node we build the tree. A value and a pointer are not the interface of a node? Moreover, I also saw an interesting thing. We all know that map cannot use iterators, but set can use iterators, but the underlying layer of set is implemented by map, so we can convert map into set for an iteration, which is almost like the following.
Map.Entry<String, String> entry = map.entrySet().iterator().next();
We know that the map is stored with entry < key, value >, and the next one is HashTable
HashTable
Still the same, construction method arrangement... Wait, what did I find
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable
You see, this HashTable implements the Map interface, which shows that HashTable should be similar to HashMap, so why is it necessary for HashTable to exist? Let's look at the construction method
public Hashtable() {
this(11, 0.75f);
}
The front 11 is the capacity, and the back 0.75f is our old friend, the load factor. But it didn't see anything, so we went on.
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
Construct a new empty hash table with the specified initial capacity and the specified load factor. The initHashSeedAsNeeded method is used to initialize the hashSeed parameter, where hashSeed is used to calculate the hash value of the key, which performs bitwise XOR operation with the hashCode of the key. This hashSeed is a random value related to the instance, which is mainly used to solve the hash conflict. What is the hash conflict and how to generate it? Explain that when storing a data, we need to calculate the hash value, use hashCode (), and then put it on the address of the hash value mapping, (the hash value is not necessarily related to the address, but mapped through a hash function). However, the conflict is that the hash values of the two objects are the same, resulting in a conflict.
In the face of hash conflicts, we generally use the chain address method to make an association:
The data corresponding to all conflicting keywords are stored in the same linear linked list.
For example, a group of keywords are {19,14,23,01,68,20,84,27,55,11,10,79}, and its hash function is: H(key)=key MOD 13. The hash table constructed by using the chain address method is shown in Figure 3:
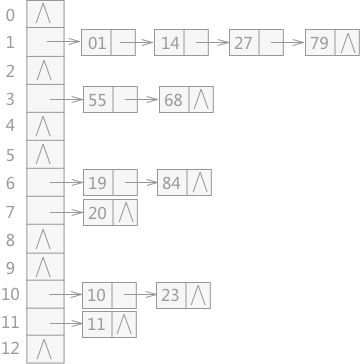
Too many post conflicts lead to too long linked lists. Therefore, after jdk8, red black trees appear. When a certain number is exceeded, the linked list will be turned into red black trees for storage to improve efficiency.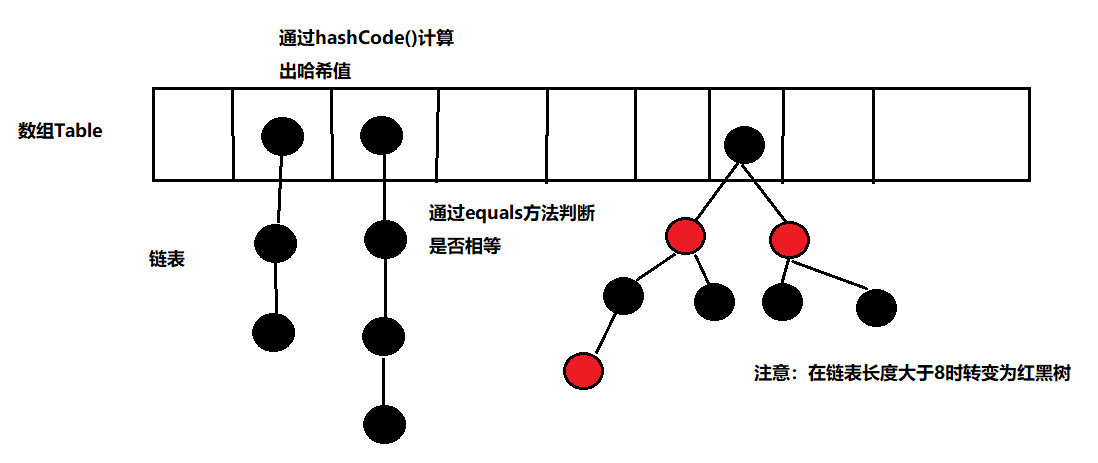
Differences between HashMap and HashTable
1. A null key and any null value are allowed in HashMap, but neither key nor value in HashTable is allowed to be null. As follows:
When HashMap encounters a null key, it will call the putForNullKey method for processing. There is no processing for value, as long as it is an object.
if (key == null) return putForNullKey(value);
When HashTable encounters null, it will directly throw NullPointerException exception information.
if (value == null) {
throw new NullPointerException();
}
2. The HashTable method is synchronous, but the HashMap method is not. Therefore, it is generally recommended to use HashTable if multi-threaded synchronization is involved, and HashMap if it is not involved.
3.HashTable has a contains(Object value), and its function is the same as that of containsValue(Object value).
4. The internal implementation of the two traversal methods is different.
Both Hashtable and HashMap use Iterator. For historical reasons, Hashtable also uses Enumeration.
5. Different hash values are used. HashTable directly uses the hashCode of the object. HashMap recalculates the hash value. The code is as follows:
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;
HashMap recalculates the hash value and uses and instead of modulus:
int hash = hash(k); int i = indexFor(hash, table.length);
6.Hashtable and HashMap are the initial size and capacity expansion methods of their two internal implementation arrays. The default size of hash array in HashTable is 11, and the increase method is old*2+1. The default size of hash array in HashMap is 16, and it must be the exponent of 2. (why should HashMap be expanded in multiples of 2? The reason is to reduce conflicts)