This article starts with WeChat official account of vivo Internet technology.
Links: https://mp.weixin.qq.com/s/l4vuYpNRjKxQRkRTDhyg2Q
Author: Chen wangrong
Distributed task scheduling framework is almost a necessary tool for every large-scale application. This paper introduces the demand background and pain points of the use of task scheduling framework, explores and practices the use of open-source distributed task scheduling framework commonly used in the industry, and analyzes the advantages and disadvantages of these frameworks and their own business thinking.
1, Business background
1.1 why to use scheduled task scheduling
(1) Time driven processing scenario: send coupons on time, update revenue every day, refresh label data and crowd data every day.
(2) Batch processing data: Monthly batch statistics report data, batch update SMS status, low real-time requirements.
(3) Asynchronous execution decoupling: activity state refresh, asynchronous execution of offline query, and internal logic decoupling.
1.2 use demand and pain points
(1) Task execution monitoring alarm capability.
(2) Tasks can be configured flexibly and dynamically without restart.
(3) Transparent business, low coupling, simple configuration and convenient development.
(4) Easy to test.
(5) High availability, no single point of failure.
(6) The task cannot be executed repeatedly to prevent logic abnormality.
(7) Distributed parallel processing capability of large tasks.
2, Practice and exploration of open source framework
2.1 Java Native Timer and ScheduledExecutorService
2.1.1 Timer use
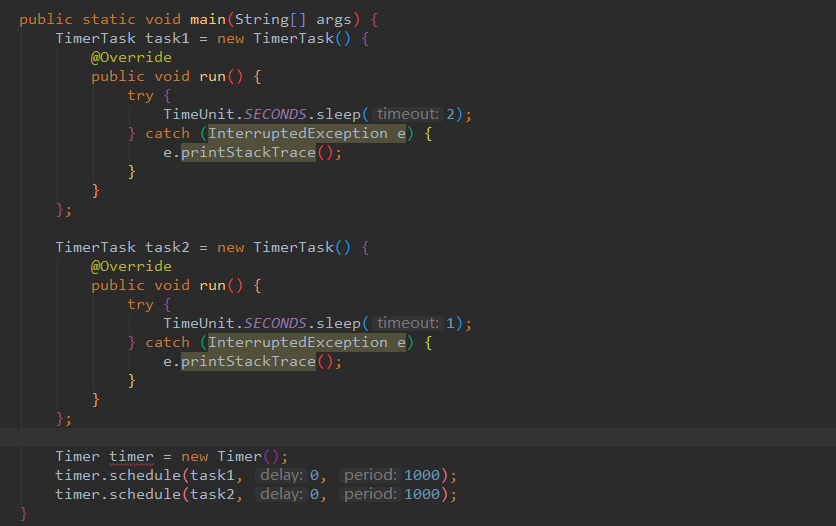
Timer defect:
-
The bottom layer of Timer is to use single thread to process multiple Timer tasks, which means that all tasks are actually serial execution, and the delay of the previous task will affect the execution of the subsequent tasks.
-
Due to the single thread, once a scheduled task is running, and an unhandled exception occurs, not only the current thread will stop, but all scheduled tasks will stop.
-
Timer task execution depends on the absolute system time, and the change of system time will lead to the change of execution plan.
Due to the above defects, try not to use Timer, and use ScheduledThreadPoolExecutor instead of Timer will be explicitly prompted in idea.
2.1.2 use of scheduledexecutorservice
ScheduledExecutorService fixes the defect of Timer. First, the internal implementation of ScheduledExecutorService is ScheduledThreadPool thread pool, which can support concurrent execution of multiple tasks.
If an exception occurs to a task executed by one thread, it will be handled and will not affect the execution of other thread tasks. In addition, the ScheduledExecutorService is based on the delay of time interval, and the execution will not change due to the change of system time.
Of course, ScheduledExecutorService has its own limitations: it can only be scheduled according to the delay of tasks, and can not meet the demand of scheduling based on absolute time and calendar.
2.2 Spring Task
2.2.1 use of spring task
spring task is a lightweight timed task framework independently developed by spring. It does not need to rely on other additional packages, and the configuration is relatively simple.
Use annotation configuration here
2.2.2 Spring Task defects
Spring Task itself does not support persistence, nor does it launch the official distributed cluster mode. It can only be realized by developers' manual expansion in business applications, which cannot meet the needs of visualization and easy configuration.
2.3 forever classic Quartz
2.3.1 basic introduction
Quartz framework is the most famous open source task scheduling tool in Java field, and it is also the actual timing task standard at present. Almost all open source timing task frameworks are built based on quartz core scheduling.
2.3.2 principle analysis
Core components and architecture
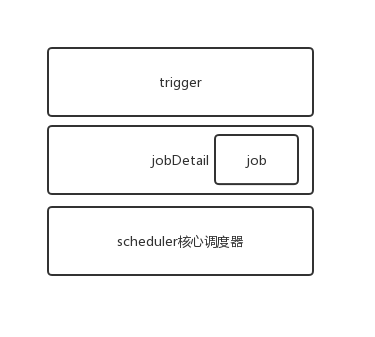

Key concepts
(1) Scheduler: task scheduler. It is the controller that performs task scheduling. In essence, it is a scheduling container, which registers all triggers and corresponding jobdetails, and uses thread pool as the basic component of task operation to improve the efficiency of task execution.
(2) Trigger: trigger, which is used to define the time rule of task scheduling and tell task scheduler when to trigger tasks. CronTrigger is a powerful trigger built on cron expression.
(3) Calendar: a collection of calendar specific points in time. A trigger can contain multiple calendars, which can be used to exclude or contain certain time points.
(4) JobDetail: it is an executable work to describe the Job implementation class and other related static information, such as Job name, listener and other related information.
(5) Job: task execution interface. There is only one execute method to execute the real business logic.
(6) JobStore: task storage mode, mainly including RAMJobStore and JDBC JobStore. RAMJobStore is stored in the memory of the JVM, with the risk of loss and limited quantity. JDBC JobStore is to persist task information into the database, supporting clustering.
2.3.3 practice description
(1) On the basic use of Quartz
-
Please refer to the official documents of Quartz and the online blog practice tutorial.
(2) In order to meet the requirements of dynamic modification and restart without loss, the database is generally used for saving.
-
Quartz itself supports JDBC jobstore, but it has a large number of data tables. For the official recommended configuration, please refer to the official documents. There are more than 10 tables, and the business usage is heavy.
-
When it is used, only the basic trigger configuration, corresponding tasks and tables of related execution logs are needed to meet most of the requirements.
(3) Componentization
-
The configuration information of the quartz dynamic task is persisted to the database, and the data operation is packaged into the basic jar package for use between projects. The reference project only needs to introduce the jar package dependency and configure the corresponding data table, which can be transparent to the quartz configuration when used.
(4) Extension
-
Cluster mode
The high availability of tasks is achieved through failover and load balancing, and the uniqueness of task execution is ensured through database locking mechanism. However, the cluster feature is only used for HA, and the increase of node number will not improve the execution efficiency of a single task, and cannot achieve horizontal expansion.
-
Quartz plug-in
You can extend specific needs, such as adding triggers and task execution logs. Tasks rely on serial processing scenarios. Please refer to: quartz plug-in -- serial scheduling between tasks
2.3.4 defects and deficiencies
(1) The task information needs to be persisted to the business data table, which is coupled with the business.
(2) Scheduling logic and execution logic coexist in the same project. When the machine performance is fixed, business and scheduling will inevitably affect each other.
(3) In the quartz cluster mode, the database exclusive lock is used to obtain the only task, and the task execution does not achieve a perfect load balancing mechanism.
2.4 lightweight artifact XXL job
2.4.1 basic introduction
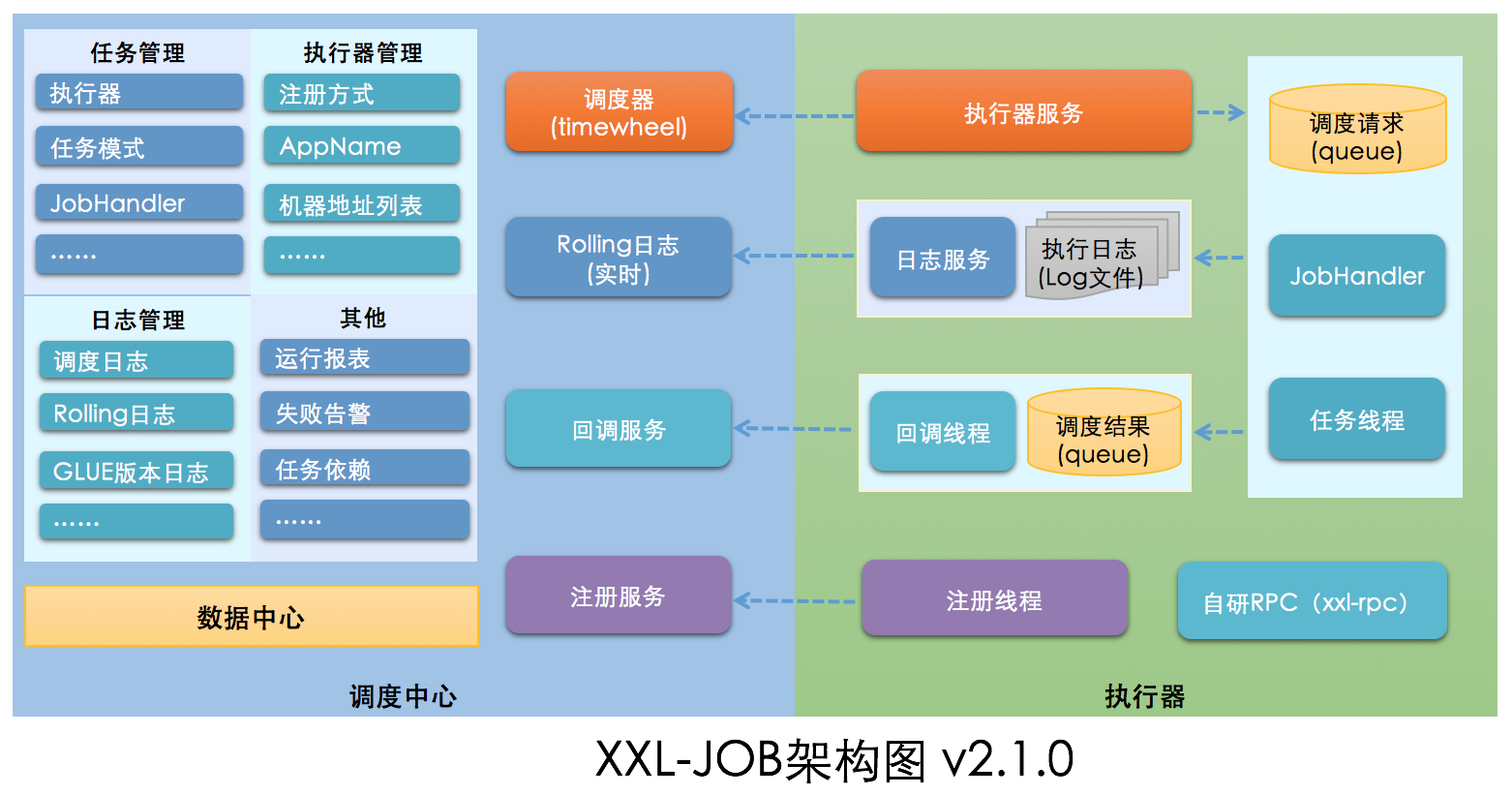
XXL-JOB is a lightweight distributed task scheduling platform. Its main features are platformization, easy deployment, rapid development, simple learning, lightweight, easy expansion, and the code is still in continuous update.
The "scheduling center" is the task scheduling console. The platform itself does not assume the business logic, but is responsible for the unified management and scheduling execution of tasks, and provides the task management platform. The "executor" is responsible for receiving the scheduling and execution of the "scheduling center", which can directly deploy the executor, or integrate the executor into the existing business projects. By decoupling task scheduling control and task execution, business use only needs to pay attention to the development of business logic.
It mainly provides several functional modules of task dynamic configuration management, task monitoring and statistical report and scheduling log. It supports a variety of operation modes and routing strategies. It can simply segment data processing based on the number of corresponding actuator machine clusters.
2.4.2 principle analysis
Before version 2.1.0, the core scheduling modules were all based on the quartz framework. In version 2.1.0, we started to develop scheduling components, remove the quartz dependency, and use time round scheduling.
2.4.3 practice description
Detailed configuration and introduction reference Official documents.
2.4.3.1 demo use:
Example 1: to implement simple task configuration, you only need to inherit the IJobHandler abstract class and declare the annotation
@JobHandler(value="offlineTaskJobHandler") to implement business logic. (Note: dubbo is introduced this time, which will be introduced later.).
@JobHandler(value="offlineTaskJobHandler") @Component public class OfflineTaskJobHandler extends IJobHandler { @Reference(check = false,version = "cms-dev",group="cms-service") private OfflineTaskExecutorFacade offlineTaskExecutorFacade; @Override public ReturnT<String> execute(String param) throws Exception { XxlJobLogger.log(" offlineTaskJobHandler start."); try { offlineTaskExecutorFacade.executeOfflineTask(); } catch (Exception e) { XxlJobLogger.log("offlineTaskJobHandler-->exception." , e); return FAIL; } XxlJobLogger.log("XXL-JOB, offlineTaskJobHandler end."); return SUCCESS; } }
Example 2: fragmentation broadcast task.
@JobHandler(value="shardingJobHandler") @Service public class ShardingJobHandler extends IJobHandler { @Override public ReturnT<String> execute(String param) throws Exception { // Fragmentation parameter ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo(); XxlJobLogger.log("Fragment parameter: current fragment No = {}, Total score = {}", shardingVO.getIndex(), shardingVO.getTotal()); // Business logic for (int i = 0; i < shardingVO.getTotal(); i++) { if (i == shardingVO.getIndex()) { XxlJobLogger.log("The first {} slice, Hit slice start processing", i); } else { XxlJobLogger.log("The first {} slice, ignore", i); } } return SUCCESS; } }
2.4.3.2 integrate dubbo
(1) Dubbo spring boot starter and business facade jar package dependency are introduced.
<dependency> <groupId>com.alibaba.spring.boot</groupId> <artifactId>dubbo-spring-boot-starter</artifactId> <version>2.0.0</version> </dependency> <dependency> <groupId>com.demo.service</groupId> <artifactId>xxx-facade</artifactId> <version>1.9-SNAPSHOT</version> </dependency>
(2) The configuration file is added to the dubbo consumer configuration (multiple configuration files can be defined according to the environment and switched through profile).
## Dubbo service consumer configuration spring.dubbo.application.name=xxl-job spring.dubbo.registry.address=zookeeper://zookeeper.xyz:2183 spring.dubbo.port=20880 spring.dubbo.version=demo spring.dubbo.group=demo-service
(3) The code can be injected into the facade interface through @ Reference.
@Reference(check = false,version = "demo",group="demo-service") private OfflineTaskExecutorFacade offlineTaskExecutorFacade;
(4) The startup program adds the @ EnableDubboConfiguration annotation.
@SpringBootApplication @EnableDubboConfiguration public class XxlJobExecutorApplication { public static void main(String[] args) { SpringApplication.run(XxlJobExecutorApplication.class, args); } }
2.4.4 task visualization configuration
The built-in platform project facilitates the developer's management of tasks and the monitoring of execution logs, and provides some functions that are easy to test.
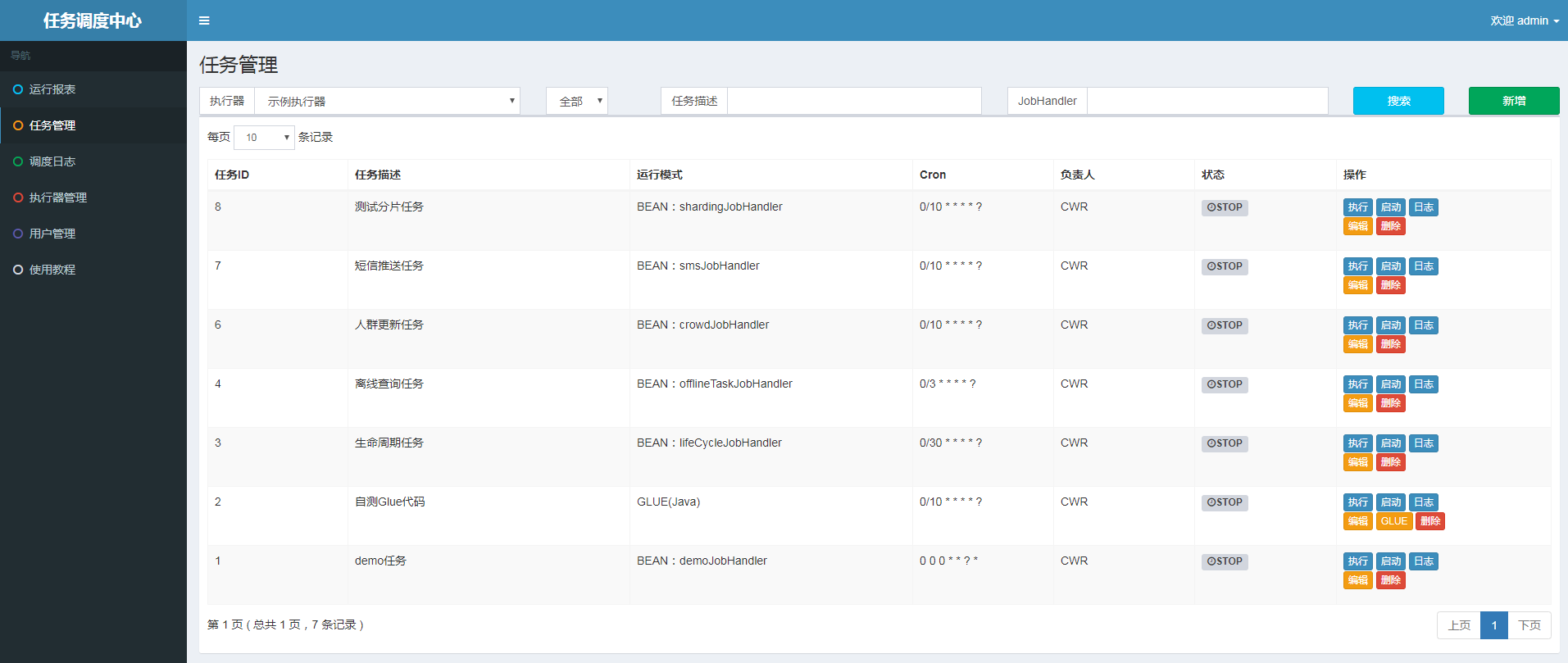
2.4.5 extension
(1) Task monitoring and report optimization.
(2) Extension of task alarm mode, such as adding alarm center, providing internal message and SMS alarm.
(3) Different monitoring alarm and retry strategies in case of abnormal internal execution of actual services.
2.5 highly available elastic job
2.5.1 basic introduction
Elastic job is a distributed scheduling solution, which consists of two independent subprojects, elastic job lite and elastic job cloud.
Elastic job Lite is positioned as a lightweight and decentralized solution, which provides coordination services of distributed tasks in the form of jar packages.
Elastic job cloud uses the solution of Mesos + Docker to provide additional services such as resource governance, application distribution and process isolation.
Unfortunately, there has been no iterative update record for two years.
2.5.2 principle analysis
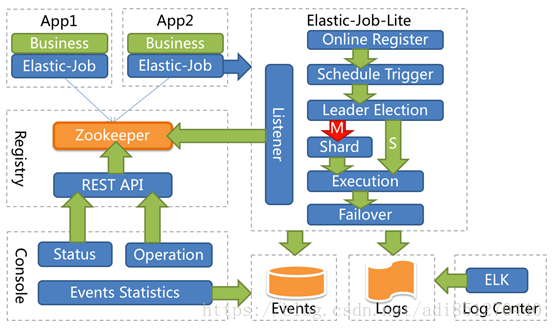

2.5.3 practice description
2.5.3.1 demo use
(1) Install zookeeper, configure the registry config, and add the configuration file to the registry zk configuration.
@Configuration @ConditionalOnExpression("'${regCenter.serverList}'.length() > 0") public class JobRegistryCenterConfig { @Bean(initMethod = "init") public ZookeeperRegistryCenter regCenter(@Value("${regCenter.serverList}") final String serverList, @Value("${regCenter.namespace}") final String namespace) { return new ZookeeperRegistryCenter(new ZookeeperConfiguration(serverList, namespace)); } }
spring.application.name=demo_elasticjob regCenter.serverList=localhost:2181 regCenter.namespace=demo_elasticjob spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl-job?Unicode=true&characterEncoding=UTF-8 spring.datasource.username=user spring.datasource.password=pwd
(2) Configure data source config and add data source configuration to the configuration file.
@Getter @Setter @NoArgsConstructor @AllArgsConstructor @ToString @Configuration @ConfigurationProperties(prefix = "spring.datasource") public class DataSourceProperties { private String url; private String username; private String password; @Bean @Primary public DataSource getDataSource() { DruidDataSource dataSource = new DruidDataSource(); dataSource.setUrl(url); dataSource.setUsername(username); dataSource.setPassword(password); return dataSource; } }
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl-job?Unicode=true&characterEncoding=UTF-8 spring.datasource.username=user spring.datasource.password=pwd
(3) Configure event config.
@Configuration public class JobEventConfig { @Autowired private DataSource dataSource; @Bean public JobEventConfiguration jobEventConfiguration() { return new JobEventRdbConfiguration(dataSource); } }
(4) To facilitate the flexible configuration of different task trigger events, the elastic simple job annotation is added.
@Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) public @interface ElasticSimpleJob { @AliasFor("cron") String value() default ""; @AliasFor("value") String cron() default ""; String jobName() default ""; int shardingTotalCount() default 1; String shardingItemParameters() default ""; String jobParameter() default ""; }
(5) Initialize the configuration.
@Configuration @ConditionalOnExpression("'${elaticjob.zookeeper.server-lists}'.length() > 0") public class ElasticJobAutoConfiguration { @Value("${regCenter.serverList}") private String serverList; @Value("${regCenter.namespace}") private String namespace; @Autowired private ApplicationContext applicationContext; @Autowired private DataSource dataSource; @PostConstruct public void initElasticJob() { ZookeeperRegistryCenter regCenter = new ZookeeperRegistryCenter(new ZookeeperConfiguration(serverList, namespace)); regCenter.init(); Map<String, SimpleJob> map = applicationContext.getBeansOfType(SimpleJob.class); for (Map.Entry<String, SimpleJob> entry : map.entrySet()) { SimpleJob simpleJob = entry.getValue(); ElasticSimpleJob elasticSimpleJobAnnotation = simpleJob.getClass().getAnnotation(ElasticSimpleJob.class); String cron = StringUtils.defaultIfBlank(elasticSimpleJobAnnotation.cron(), elasticSimpleJobAnnotation.value()); SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(JobCoreConfiguration.newBuilder(simpleJob.getClass().getName(), cron, elasticSimpleJobAnnotation.shardingTotalCount()).shardingItemParameters(elasticSimpleJobAnnotation.shardingItemParameters()).build(), simpleJob.getClass().getCanonicalName()); LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true).build(); JobEventRdbConfiguration jobEventRdbConfiguration = new JobEventRdbConfiguration(dataSource); SpringJobScheduler jobScheduler = new SpringJobScheduler(simpleJob, regCenter, liteJobConfiguration, jobEventRdbConfiguration); jobScheduler.init(); } } }
(6) Implement the SimpleJob interface, integrate dubbo according to the above methods, and complete the business logic.
@ElasticSimpleJob( cron = "*/10 * * * * ?", jobName = "OfflineTaskJob", shardingTotalCount = 2, jobParameter = "Test parameters", shardingItemParameters = "0=A,1=B") @Component public class MySimpleJob implements SimpleJob { Logger logger = LoggerFactory.getLogger(OfflineTaskJob.class); @Reference(check = false, version = "cms-dev", group = "cms-service") private OfflineTaskExecutorFacade offlineTaskExecutorFacade; @Override public void execute(ShardingContext shardingContext) { offlineTaskExecutorFacade.executeOfflineTask(); logger.info(String.format("Thread ID: %s, Total number of job segments: %s, " + "Current slice item: %s.Current parameters: %s," + "Job name: %s.Job custom parameters: %s" , Thread.currentThread().getId(), shardingContext.getShardingTotalCount(), shardingContext.getShardingItem(), shardingContext.getShardingParameter(), shardingContext.getJobName(), shardingContext.getJobParameter() )); } }
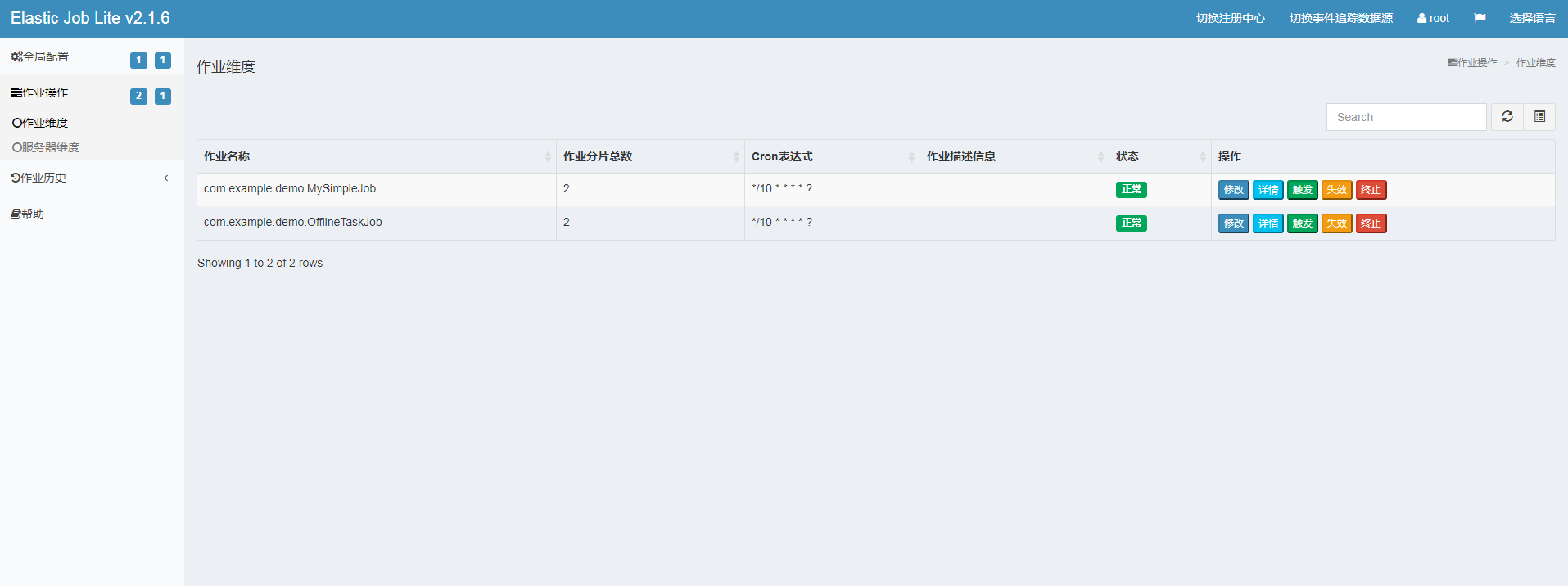
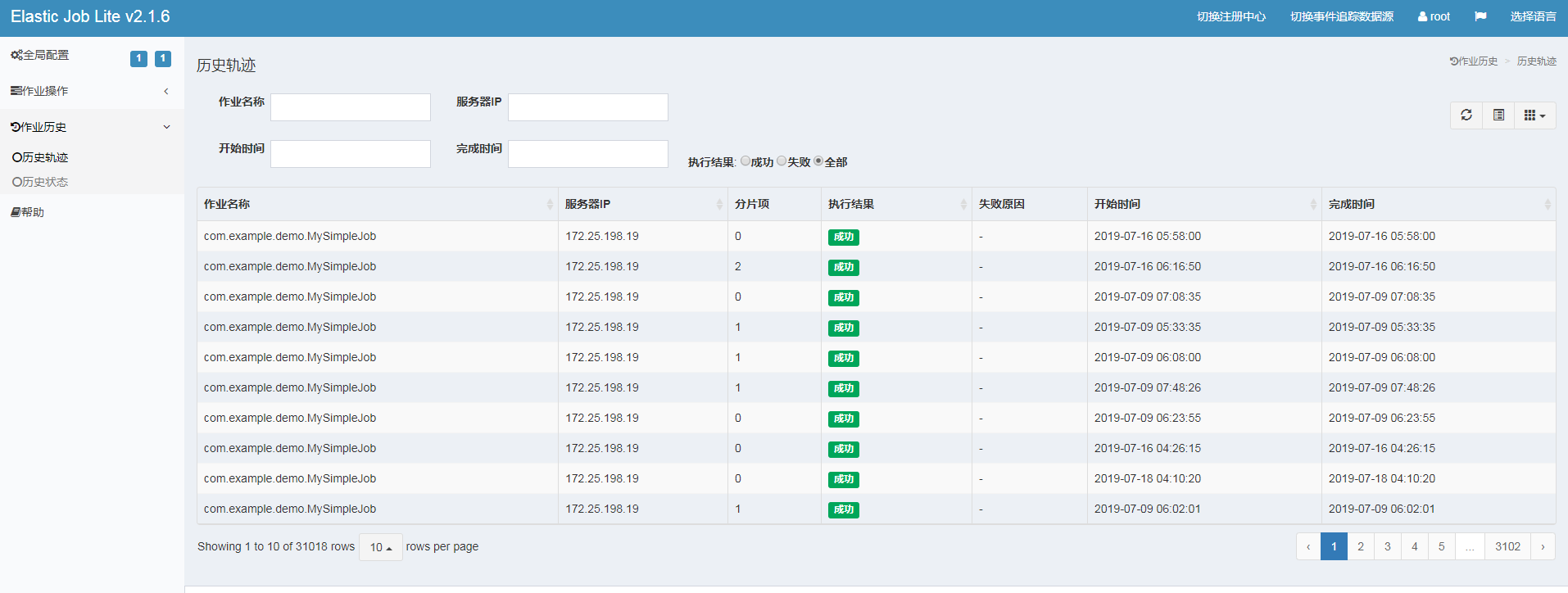
2.6 other open source frameworks
(1) Saturn: Saturn is an open-source distributed task scheduling platform of vipshop, which is modified on the basis of Elastic Job.
(2) SIA-TASK: it is an open-source distributed task scheduling platform of Yixin.
3, Comparison of advantages and disadvantages and adaptation of business scenarios
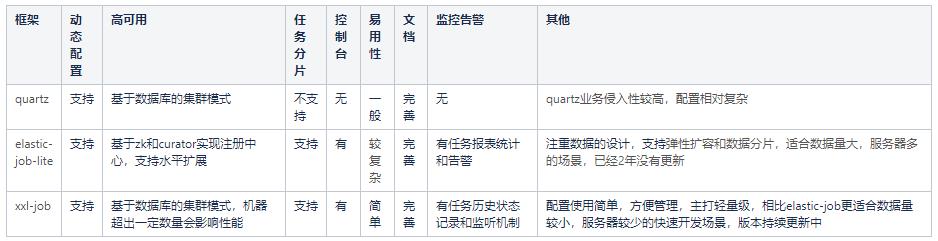
Business thinking:
-
Enrich task monitoring data and alarm strategies.
-
Access unified login and authority control.
-
Further simplify the service access steps.
Four, conclusion
For systems with low concurrency scenario, the configuration and deployment of XXL job is simple and easy to use, without the introduction of redundant components. At the same time, it provides a visual console, which is very friendly and a good choice. We hope to directly use the open source distributed framework capability of the system, and suggest to select the appropriate model according to their own situation.
Attachment: References
More content, please pay attention to vivo Internet technology WeChat official account.

Note: please contact labs2020 for reprint.