In the browser environment, some powerful xpath standard methods are not supported (such as the regular matching method matches()), and only limited methods can be used for extraction. Here is a list of my commonly used search skills and experience; update from time to time.
Commonly used
Take the following paging component node structure as an example:
<div class="pageList"> <span data-span style="display:none">.</span> <span class="disabled">‹</span> <span class="current" data-span>1</span> <a href="" style="display:none"></a> <a href="/Program/n-d-2-a-2">2</a> <a href="/Program/n-d-2-a-3">3</a> <a href="/Program/n-d-2-a-4">4</a> <a href="/Program/n-d-2-a-5">5</a> <a href="/Program/n-d-2-a-2">›</a> <a href="/Program/n-d-2-a-30" class="last">... 30</a> </div> <div class="ad"> <a href='xxx'></a> <a href="xxx"><img src="xxx" /></a> </div>
"Or" conditions
Select the "previous" and "next" nodes:
//div[@class="pageList"]/span[@class="current" and @data-span]
"And" conditions
Select the "previous" and "next" nodes:
//div[@class="pageList"]/*[text()="‹" or text()="›" ]
"Non" condition
Select a node that does not contain the attribute of a href:
//div[@class="pageList"]/a[not(@href)]
Contain
Select the a node with the 'Program' attribute in the href attribute:
//div[@class="pageList"]/a[contains(@href,'Program')]
Select the a node with the attribute of "Program" not included in the attribute of "href":
//div[@class="pageList"]/a[not(contains(@href,'Program'))]
Judge whether it is a number
Select a node where the text is a number:
//div[@class="pageList"]/a[string(number(text())) != 'NaN'];
Parent node
Select a node containing img in ad:
//div[@class="ad"]/a/img/parent::a
Adjacent sibling node
Select the first adjacent node in front of node a on page 4 (node a on page 3):
//div[@class="pageList"]/a[text()="4"]/preceding-sibling::a[1]
Select the first adjacent node after node a on page 4 (that is, node a on page 5):
//div[@class="pageList"]/a[text()="4"]/following-sibling::a[1]
Begin or end with a specific character
Select the a-node whose attribute of the href starts with "/ Program" (ends with):
//div[@class="pageList"]/a[starts-with(@href,"/Program")]
context
Select the first three a's:
//div[@class="pageList"]/a[position()<=3]
Select the last a:
//div[@class="pageList"]/a[last()]
Implementation of Xpath method in js
function getElementsByXpath(xpathToExecute, element) { element = (element === undefined)? document:element; var result = []; var nodesSnapshot = document.evaluate(xpathToExecute, element, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null); for (var i = 0; i < nodesSnapshot.snapshotLength; i++) { result.push(nodesSnapshot.snapshotItem(i)); } return result; } //Example of invocation getElementsByXpath('//div') getElementsByXpath('//div', document.body)
Here are the standard axes and operators for easy viewing. The original text of this part comes from http://www.runoob.com/xpath/xpath-tutorial.html
XPath operator
XPath expressions return node sets, strings, logical values, and numbers.
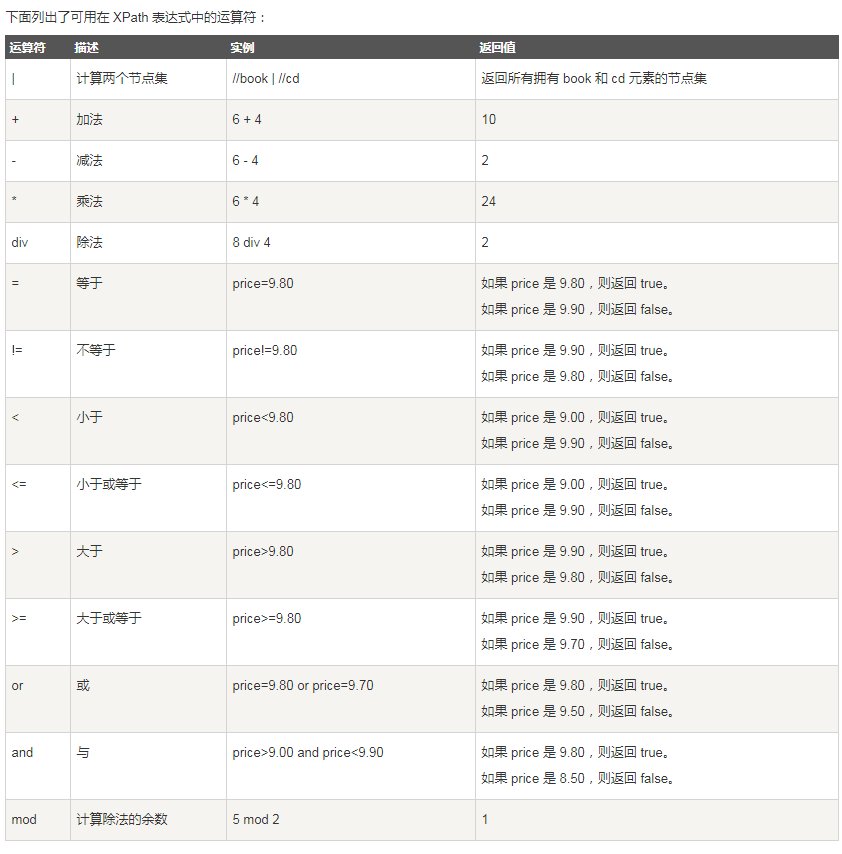
Xpath axis