Refer to the video tutorial:
**Big data dmp user Portrait System **
Transferred from Qianfeng Teacher Wang Su
1. Introduction to user portrait project
1.1 what is user portrait
The so-called user portrait is to label the user and explain what kind of person the user is.
Specifically, after putting some labels on users, they are divided into different types according to the differences of users' goals, behaviors and views, and then typical features are extracted from each type and given names, photos, some demographic elements, scenes and other descriptions to form a character prototype.
The process is to abstract the customer information into the user portrait, and then abstract the cognition of the customer.
1.2 main dimensions of user portrait
Demographic attribute: who is the user (basic information such as gender, age, occupation, etc.)
Consumer demand: consumer habits and preferences
Purchasing power: income, purchasing power, purchasing frequency and channel
Hobbies: brand preference, personal interest
Social attributes: user activity scenarios (social media, etc.)
1.3 data type of user portrait
Data include dynamic data and static data. The so-called static data, such as gender and age, cannot be changed in a short time; Dynamic data is data related to short-term behavior. For example, today I want to buy a skirt and tomorrow I will go to see pants. This data feature is relatively changeable.
1.4 purpose of user portrait
Kill cooked, recommend (very many) [user portrait is an important data source of the recommendation system], marketing, customer service
Let users and enterprises win-win. Let users quickly find the goods they want, and let enterprises find people who pay for the products.
(1) Micro level
In product design, users' needs are described through user portraits.
In data application, it can be used for recommendation, search and risk control
Combine qualitative analysis and quantitative analysis to conduct data operation and user analysis
Precision marketing
(2) Macro level
Determine the strategic and tactical direction of development
Market segmentation and user clustering, market-oriented
(3) Portrait modeling and prediction
Subdivide population attributes: clarify who, what and why
Purchase Behavior Segmentation: provide key information such as market opportunities and market scale
Product demand segmentation: provide more differentiated and competitive product specifications and business value
Interest and attitude segmentation: provide group category portraits: channel strategy, pricing strategy, product strategy and brand strategy
1.5 steps of user portrait
(1) Determine the target of the portrait
In different product life cycles, or different ways of use, different goals and different needs for portraits, so it is necessary to clarify what the goals and needs are before portrait.
(2) Determine the dimensions of the desired user portrait
Determine the dimensions required by the user's portrait according to the objectives. For example, if you want to recommend goods, you need the factors that can affect the user's choice of goods as the portrait dimension. For example, the user dimension (the user's age and gender will affect the user's choice), the asset dimension (the user's income and other factors will affect the user's choice of price), the behavior dimension (what the user often sees recently should be what he wants to buy), and so on.
(3) Determine the level of the portrait
The more user portrait levels, the smaller the portrait granularity and the clearer the understanding of users. For example, the user dimension can be divided into new users and old users, and then into users' gender, age, etc. This needs to be divided according to the target requirements.
(4) Through the original data, machine learning algorithm is used to label users
Because the original data we get is some disorderly data, we need the algorithm to label users through some features
(5) The tag is transformed into the output of the business through the machine learning algorithm
Everyone will have many tags, which need to be further transformed into the understanding of users. Different weights need to be built for different labels to obtain the output of the business. For example, what kind of products will users with some labels like.
(6) The business generates data, which feeds the business and keeps a closed loop
1.6 common user portrait labels

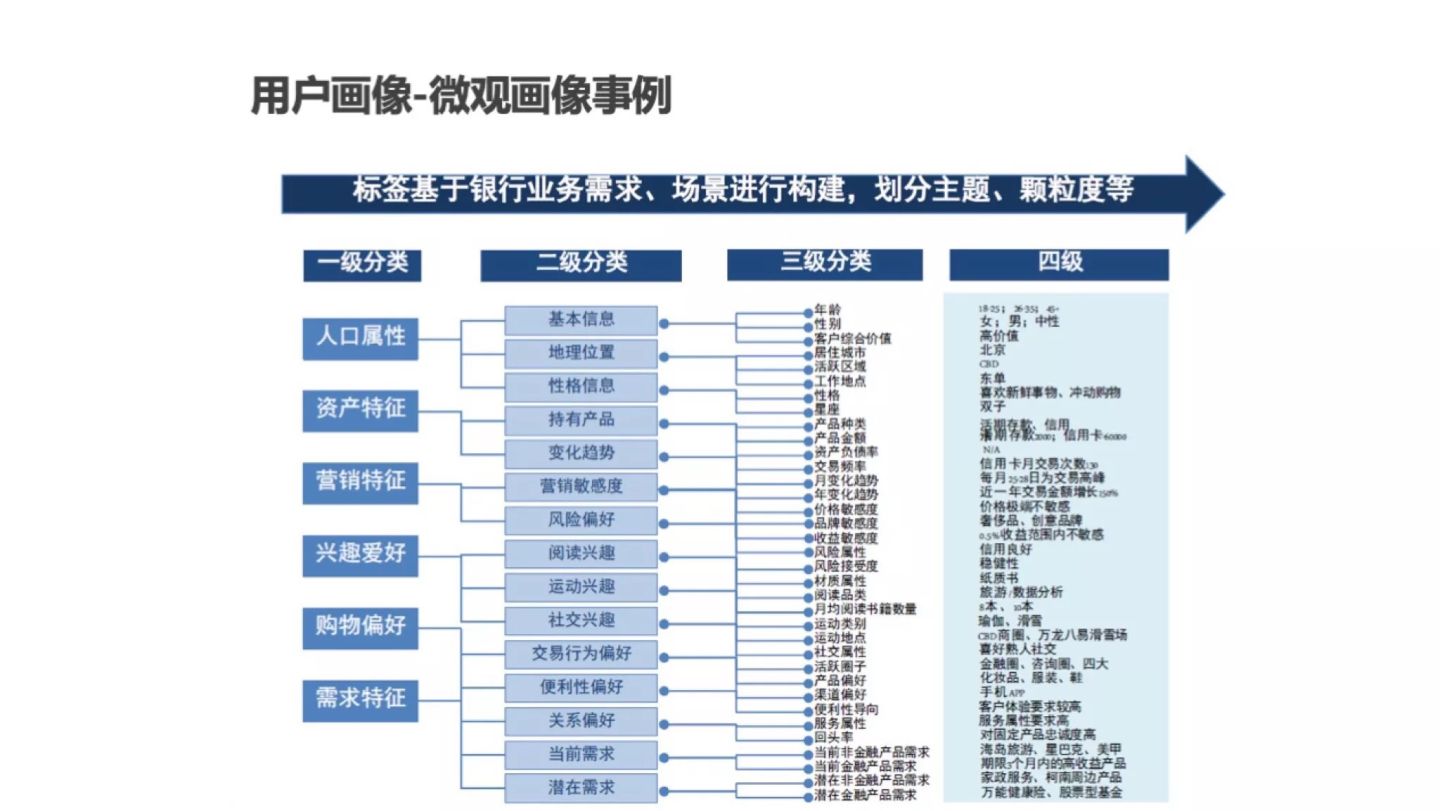
2. System architecture
2.1 overall architecture (offline projects)
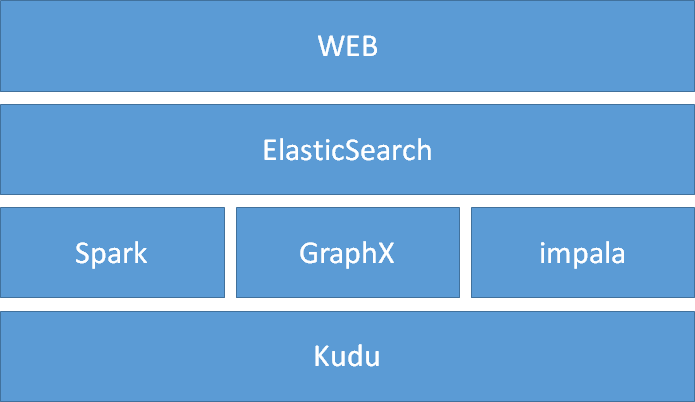
2.2 data processing flow (what to do)
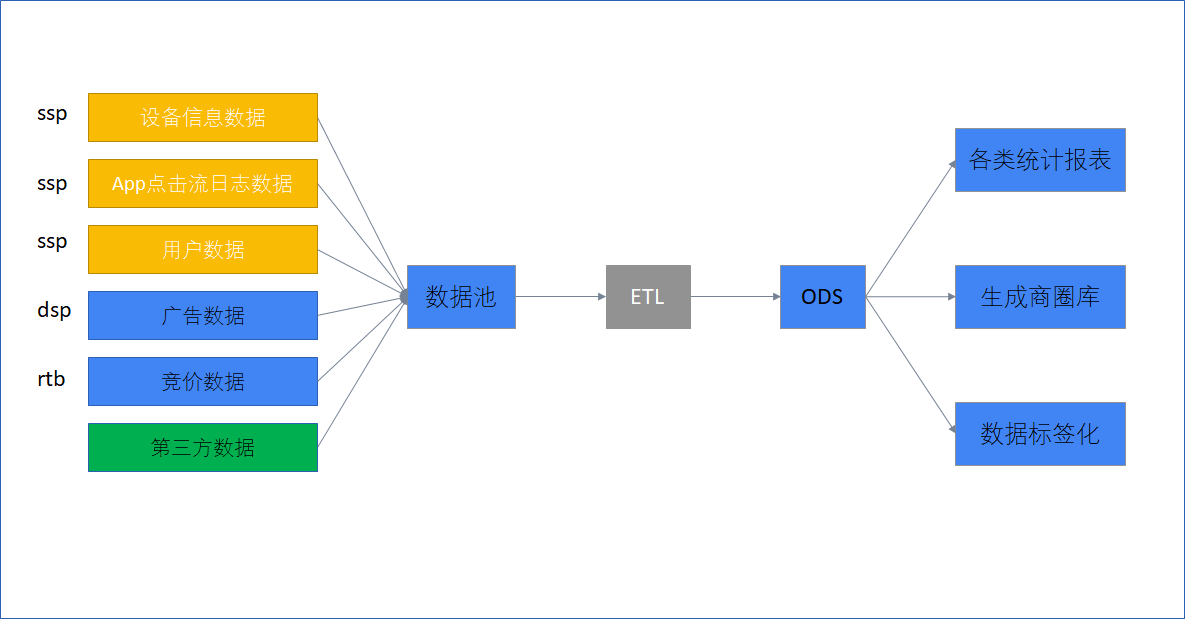
ETL (Extract Tranform Load) is used to describe the process of data extraction, transformation and loading from the source end to the destination end;
ODS (Operational Data Store) operation data store. There is no change in the data of this layer, which directly follows the data structure and data of the peripheral system and is not open to the outside world; It is the temporary storage layer, which is the temporary storage area of interface data to prepare for data processing in the next step.
Main steps to be realized: ETL, report statistics (data analysis), generation of business district library, data tagging (core)
2.3 description of main data set (log data file to be analyzed)
- For the integrated log data, one copy per day in json format (offline processing)
- This data set integrates internal and external data, as well as bidding information (related to advertising)
- There are many columns of data, close to 100
| field | explain |
|---|---|
| ip | Real IP of the device |
| sessionid | Session ID |
| advertisersid | Advertiser ID |
| adorderid | AD ID |
| adcreativeid | Advertising creative ID (> = 200000: DSP, < 200000 OSS) |
| adplatformproviderid | Advertising platform provider ID (> = 100000: RTB, < 100000: API) |
| sdkversionnumber | SDK version number |
| adplatformkey | Platform provider key |
| putinmodeltype | For advertisers' delivery mode, 1: display volume delivery, 2: click volume delivery |
| requestmode | Data request method (1: request, 2: display, 3: click) |
| adprice | Advertising price |
| adppprice | Platform provider price |
| requestdate | Request time, format: yyyy-m-dd hh:mm:ss |
| appid | Application id |
| appname | apply name |
| uuid | Unique identification of the device, such as imei or Android |
| device | Device model, such as htc, iphone |
| client | Device type (1: android 2: ios 3: wp) |
| osversion | Device operating system version, such as 4.0 |
| density | The density of the standby screen is 0.75, 1 and 1.5 for android and 1 and 2 for IOS |
| pw | Device screen width |
| ph | Device screen height |
| provincename | Name of the province where the equipment is located |
| cityname | Name of the city where the equipment is located |
| ispid | Operator id |
| ispname | Operator name |
| networkmannerid | Networking mode id |
| networkmannername | Networking mode name |
| iseffective | Valid ID (valid refers to those that can be charged normally) (0: invalid 1: valid) |
| isbilling | Charge or not (0: not charged 1: charged) |
| adspacetype | Advertising space type (1: banner 2: insert screen 3: full screen) |
| adspacetypename | Advertising space type name (banner, insert screen, full screen) |
| devicetype | Device type (1: mobile phone 2: tablet) |
| processnode | Process node (1: request quantity kpi 2: valid request 3: advertisement request) |
| apptype | Application type id |
| district | Name of the county where the equipment is located |
| paymode | For the payment mode of platform providers, 1: display volume delivery (CPM) 2: click volume delivery (CPC) |
| isbid | rtb |
| bidprice | rtb bidding price |
| winprice | Successful rtb bidding price |
| iswin | Successful bidding |
| cur | values:usd|rmb, etc |
| rate | exchange rate |
| cnywinprice | rtb bidding successfully converted to RMB price |
| imei | Mobile phone string code |
| mac | Mobile phone MAC code |
| idfa | Advertising code of mobile APP |
| openudid | Apple device ID |
| androidid | Android device ID |
| rtbprovince | rtb Province |
| rtbcity | rtb City |
| rtbdistrict | rtb area |
| rtbstreet | rtb Street |
| storeurl | app market download address |
| realip | Real ip |
| isqualityapp | Preferred identification |
| bidfloor | floor price |
| aw | Width of advertising space |
| ah | Height of advertising space |
| imeimd5 | imei_md5 |
| macmd5 | mac_md5 |
| idfamd5 | idfa_md5 |
| openudidmd5 | openudid_md5 |
| androididmd5 | androidid_md5 |
| imeisha1 | imei_sha1 |
| macsha1 | mac_sha1 |
| idfasha1 | idfa_sha1 |
| openudidsha1 | openudid_sha1 |
| androididsha1 | androidid_sha1 |
| uuidunknow | uuid_ Unknown UUID ciphertext |
| userid | Platform user id |
| iptype | Indicates the ip library type. 1 is the point media ip library and 2 is the ip geographic information standard library of the Advertising Association. The default is 1 |
| initbidprice | Initial bid |
| adpayment | Advertising consumption after conversion (6 decimal places reserved) |
| agentrate | Agent profit margin |
| lomarkrate | Agency profit margin |
| adxrate | Media profit margin |
| title | title |
| keywords | keyword |
| tagid | Advertising space identification (the value is the video ID number when the video traffic occurs) |
| callbackdate | Callback time format: YYYY/mm/dd hh:mm:ss |
| channelid | Channel ID |
| mediatype | media type |
| User email | |
| tel | User telephone number |
| sex | User gender |
| age | User age |
3. Create the project [ key points of the second day ]
3.1 steps
- Create a Maven project to process data
Maven manages all jar s used in the project
*Modify pom.xml file and add:
- Define dependent version
- Import dependency
- Define profile
- Create scala directories (in src and test respectively)
-
Create the package cn.itbigdata.dmp in the scala directory
-
Write a main program architecture (DMPApp)
-
Add configuration file dev/application.conf
-
Add the directory utils and the parameter resolution class ConfigHolder
3.2 modify pom.xml file [ key ]
- Set dependent version information
<properties>
<scala.version>2.11.8</scala.version>
<scala.version.simple>2.11</scala.version.simple>
<hadoop.version>2.6.1</hadoop.version>
<spark.version>2.3.3</spark.version>
<hive.version>1.1.0</hive.version>
<fastjson.version>1.2.44</fastjson.version>
<geoip.version>1.3.0</geoip.version>
<geoip2.version>2.12.0</geoip2.version>
<config.version>1.2.1</config.version>
</properties>
- Import dependencies of the computing engine
<!-- scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-xml</artifactId>
<version>2.11.0-M4</version>
</dependency>
<!-- hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- spark core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version.simple}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version.simple}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark graphx -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_${scala.version.simple}</artifactId>
<version>${spark.version}</version>
</dependency>
- < font color = Red > import dependency of storage engine (can be omitted) < / font >
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service-rpc</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service</artifactId>
</exclusion>
</exclusions>
<version>${hive.version}</version>
</dependency>
- Import tool dependency
<!-- be used for IP Address translation (longitude, dimension) -->
<dependency>
<groupId>com.maxmind.geoip</groupId>
<artifactId>geoip-api</artifactId>
<version>${geoip.version}</version>
</dependency>
<dependency>
<groupId>com.maxmind.geoip2</groupId>
<artifactId>geoip2</artifactId>
<version>${geoip2.version}</version>
</dependency>
<!-- Convert latitude and longitude to code -->
<dependency>
<groupId>ch.hsr</groupId>
<artifactId>geohash</artifactId>
<version>${geoip.version}</version>
</dependency>
<!-- scala analysis json -->
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-jackson_${scala.version.simple}</artifactId>
<version>3.6.5</version>
</dependency>
<!-- Manage profiles -->
<dependency>
<groupId>com.typesafe</groupId>
<artifactId>config</artifactId>
<version>${config.version}</version>
</dependency>
- < font color = Red > Import compilation configuration (can be omitted) < / font >
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>cn.itcast.dmp.processing.App</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
3.3 creating scala code packages
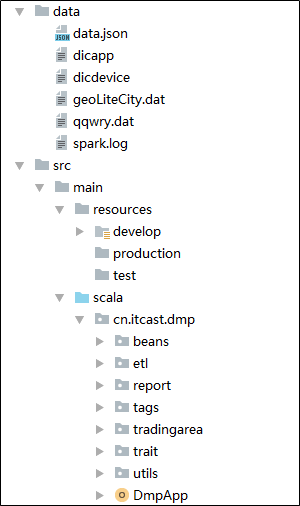
1558338673059.png
-
Create a scala code package under src/main /
-
Create cn.itbigdata.dmp package in scala package
-
Create in cn.itbigdata.dmp package
-
beans (storage class definition)
- etl (etl related processing)
- Report (report processing)
- tradingarea (Business District Library)
- tags (tag processing)
- customtrait (store interface definition)
- utils (storage tool class)
- Establish a data directory in the whole project to store the data to be processed
3.4 DmpApp main program (initialization part)
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
// The main program of the project, where relevant tasks are completed
object DmpApp {
def main(args: Array[String]): Unit = {
// initialization
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("DmpApp")
.set("spark.worker.timeout", "600s")
.set("spark.cores.max", "10")
.set("spark.rpc.askTimeout", "600s")
.set("spark.network.timeout", "600s")
.set("spark.task.maxFailures", "5")
.set("spark.speculation", "true")
.set("spark.driver.allowMultipleContexts", "true")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.buffer.pageSize", "8m")
.set("park.debug.maxToStringFields", "200")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// close resource
spark.close()
}
}
3.5 explanation of spark related parameters
| Parameter name | Default value | Define value |
|---|---|---|
| spark.worker.timeout | 60 | 500 |
| spark.network.timeout | 120s | 600s |
| spark.rpc.askTimeout | spark.network.timeout | 600s |
| spark.cores.max | 10 | |
| spark.task.maxFailures | 4 | 5 |
| spark.speculation | false | true |
| spark.driver.allowMultipleContexts | false | true |
| spark.serializer | org.apache.spark.serializer.JavaSerializer | org.apache.spark.serializer.KryoSerializer |
| spark.buffer.pageSize | 1M - 64M, system calculation | 8M |
- Spark.worker.timeout: the heartbeat is not reported to the master for a long time due to network failure. After spark.worker.timeout (seconds), the master detects the worker exception, identifies it as DEAD, and removes the worker information and the above executor information;
- Spark. Network. Timeout: the default timeout for all network interactions. Caused by the network or gc, the worker or executor does not receive heartbeat feedback from the executor or task. Increase the value of spark.network.timeout to 300(5min) or higher as appropriate;
- spark.rpc.askTimeout: timeout of RPC call;
- spark.cores.max: the maximum number of CPU cores that each application can apply for;
- spark.task.maxFailures: when task execution fails, it will not directly cause the whole application to go down. It will only go down if spark.task.maxFailures fail after retries for times;
- Spark.specification: speculative execution means that for a slow running task in a Stage, the task will be started again on the executors of other nodes. If one task instance runs successfully, the calculation result of the first completed task will be taken as the final result, and the instances running on other executors will be killed to speed up the running speed;
- spark.driver.allowMultipleContexts: there is only one instance of SparkContext by default. If set to true, multiple instances are allowed;
- spark.serializer: in the spark architecture, objects delivered in the network or cached in memory and hard disk need to be serialized [sent to tasks on the Executor; RDD to be cached (provided that serialization caching is used); broadcast variables; data caching in the shuffle process, etc.); The performance of the default Java serialization method is not high, and the number of bytes occupied after serialization is also large; Kryo's serialization library is also officially recommended. According to the official documents, the performance of kryo serialization mechanism is about 10 times higher than that of Java serialization mechanism;
- spark.buffer.pageSize: the unit of spark memory allocation. There is no default value and the size is between 1M-64M. Spark is calculated according to the jvm heap memory size; The value is too small and the memory allocation efficiency is low; The value is too large, resulting in a waste of memory;
3.6 development environment parameter configuration file
application.conf
// Development environment parameter profile # App information spark.appname="dmpApp" # spark information spark.master="local[*]" spark.worker.timeout="120" spark.cores.max="10" spark.rpc.askTimeout="600s" spark.network.timeout="600s" spark.task.maxFailures="5" spark.speculation="true" spark.driver.allowMultipleContexts="true" spark.serializer="org.apache.spark.serializer.KryoSerializer" spark.buffer.pageSize="8m" # kudu information kudu.master="node1:7051,node2:7051,node3:7051" # Enter information about the data addata.path="data/dataset_main.json" ipdata.geo.path="data/dataset_geoLiteCity.dat" qqwrydat.path="data/dataset_qqwry.dat" installDir.path="data" # Corresponding ETL output information ods.prefix="ods" ad.data.tablename="adinfo" # The output report corresponds to 7 Analysis: regional statistics, advertising region, APP, equipment, network, operator and channel report.region.stat.tablename="RegionStatAnalysis" report.region.tablename="AdRegionAnalysis" report.app.tablename="AppAnalysis" report.device.tablename="DeviceAnalysis" report.network.tablename="NetworkAnalysis" report.isp.tablename="IspAnalysis" report.channel.tablename="ChannelAnalysis" # Gaode API gaoDe.app.key="a94274923065a14222172c9b933f4a4e" gaoDe.url="https://restapi.amap.com/v3/geocode/regeo?" # Geohash (length of key) geohash.key.length=10 # Business District Library trading.area.tablename="tradingArea" # tags non.empty.field="imei,mac,idfa,openudid,androidid,imeimd5,macmd5,idfamd5,openudidmd5,androididmd5,imeisha1,macsha1,idfasha1,openudidsha1,androididsha1" appname.dic.path="data/dic_app" device.dic.path="data/dic_device" tags.table.name.prefix="tags" # Label attenuation factor tag.coeff="0.92" # es related parameters es.cluster.name="cluster_es" es.index.auto.create="true" es.Nodes="192.168.40.164" es.port="9200" es.index.reads.missing.as.empty="true" es.nodes.discovery="false" es.nodes.wan.only="true" es.http.timeout="2000000"
3.7 configuration file parsing class
// Parsing parameter file help class
import com.typesafe.config.ConfigFactory
object ConfigHolder {
private val config = ConfigFactory.load()
// App Info
lazy val sparkAppName: String = config.getString("spark.appname")
// Spark parameters
lazy val sparkMaster: String = config.getString("spark.master")
lazy val sparkParameters: List[(String, String)] = List(
("spark.worker.timeout", config.getString("spark.worker.timeout")),
("spark.cores.max", config.getString("spark.cores.max")),
("spark.rpc.askTimeout", config.getString("spark.rpc.askTimeout")),
("spark.network.timeout", config.getString("spark.network.timeout")),
("spark.task.maxFailures", config.getString("spark.task.maxFailures")),
("spark.speculation", config.getString("spark.speculation")),
("spark.driver.allowMultipleContexts", config.getString("spark.driver.allowMultipleContexts")),
("spark.serializer", config.getString("spark.serializer")),
("spark.buffer.pageSize", config.getString("spark.buffer.pageSize"))
)
// kudu parameters
lazy val kuduMaster: String = config.getString("kudu.master")
// input dataset
lazy val adDataPath: String = config.getString("addata.path")
lazy val ipsDataPath: String = config.getString("ipdata.geo.path")
def ipToRegionFilePath: String = config.getString("qqwrydat.path")
def installDir: String = config.getString("installDir.path")
// output dataset
private lazy val delimiter = "_"
private lazy val odsPrefix: String = config.getString("ods.prefix")
private lazy val adInfoTableName: String = config.getString("ad.data.tablename")
// lazy val ADMainTableName = s"$odsPrefix$delimiter$adInfoTableName$delimiter${DateUtils.getTodayDate()}"
// report
lazy val Report1RegionStatTableName: String = config.getString("report.region.stat.tablename")
lazy val ReportRegionTableName: String = config.getString("report.region.tablename")
lazy val ReportAppTableName: String = config.getString("report.app.tablename")
lazy val ReportDeviceTableName: String = config.getString("report.device.tablename")
lazy val ReportNetworkTableName: String = config.getString("report.network.tablename")
lazy val ReportIspTableName: String = config.getString("report.isp.tablename")
lazy val ReportChannelTableName: String = config.getString("report.channel.tablename")
// GaoDe API
private lazy val gaoDeKey: String = config.getString("gaoDe.app.key")
private lazy val gaoDeTempUrl: String = config.getString("gaoDe.url")
lazy val gaoDeUrl: String = s"$gaoDeTempUrl&key=$gaoDeKey"
// GeoHash
lazy val keyLength: Int = config.getInt("geohash.key.length")
// Business District Library
lazy val tradingAreaTableName: String =config.getString("trading.area.tablename")
// tags
lazy val idFields: String = config.getString("non.empty.field")
lazy val filterSQL: String = idFields
.split(",")
.map(field => s"$field is not null ")
.mkString(" or ")
lazy val appNameDic: String = config.getString("appname.dic.path")
lazy val deviceDic: String = config.getString("device.dic.path")
lazy val tagsTableNamePrefix: String = config.getString("tags.table.name.prefix") + delimiter
lazy val tagCoeff: Double = config.getDouble("tag.coeff")
// Load elasticsearch related parameters
lazy val ESSparkParameters = List(
("cluster.name", config.getString("es.cluster.name")),
("es.index.auto.create", config.getString("es.index.auto.create")),
("es.nodes", config.getString("es.Nodes")),
("es.port", config.getString("es.port")),
("es.index.reads.missing.as.empty", config.getString("es.index.reads.missing.as.empty")),
("es.nodes.discovery", config.getString("es.nodes.discovery")),
("es.nodes.wan.only", config.getString("es.nodes.wan.only")),
("es.http.timeout", config.getString("es.http.timeout"))
)
def main(args: Array[String]): Unit = {
println(ConfigHolder.sparkParameters)
println(ConfigHolder.installDir)
}
}
3.8 DmpApp main program (using configuration file)
import cn.itbigdata.dmp.utils.ConfigHolder
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object DmpApp {
def main(args: Array[String]): Unit = {
// 1. Initialization (SparkConf, SparkSession)
val conf = new SparkConf()
.setAppName(ConfigHolder.sparkAppName)
.setMaster(ConfigHolder.sparkMaster)
.setAll(ConfigHolder.sparkParameters)
val spark: SparkSession = SparkSession.builder()
.config(conf)
.getOrCreate()
spark.sparkContext.setLogLevel("warn")
println("OK!")
// 1,ETL
// 2. Statement
// 3. Generate business district library
// 4. Tagging
// close resource
spark.close()
}
}
4. ETL development
Requirements:
- Convert the ip address in each line of the data file into longitude, dimension, province and city information;
IP = > longitude, dimension, province, city
*Save the converted data file (one file per day)
Processing steps:
- Read data
- data processing
- Find the ip address in each row of data
- According to the ip address, calculate the corresponding province, city, longitude and latitude, and add them to the tail of each line of data
- Save data
- Other requirements: the data is loaded once a day, and the daily data is stored in a separate file
Difficult problem: data processing (how to convert IP address into province, city, longitude and latitude)
4.1 build ETL architecture
Create a new trait (Processor) to provide a unified interface class for data processing
import org.apache.spark.sql.SparkSession
// Data processing interface
// SparkSession is used for data loading and processing
// KuduContext is used to save data
trait Processor {
def process(spark: SparkSession)
}
Create a new ETLProcessor to be responsible for ETL processing
import cn.itbigdata.dmp.customtrait.Processor
import org.apache.kudu.spark.kudu.KuduContext
import org.apache.spark.sql.SparkSession
object ETLProcessor extends Processor{
override def process(spark: SparkSession): Unit = {
// Define parameters
val sourceDataFile = ConfigHolder.adLogPath
val sinkDataPath = ""
// 1 read data
val sourceDF: DataFrame = spark.read.json(sourceDataFile)
// 2 processing data
// 2.1 find ip
// 2.2 convert ip to province, city, longitude and dimension
val rdd = sourceDF.rdd
.map(row => {
val ip: String = row.getAs[String]("ip")
ip
})
// 2.3 put the province, city, longitude and dimension at the end of the original data
// 3 save data
}
}
4.2 IP address conversion to latitude and longitude
- Use GeoIP to convert the ip address to latitude and longitude
- GeoIP is a set of software tools with IP database
- Geo locates the location information such as longitude and latitude, country / region, province, city and street of the IP according to the visitor's IP
- GeoIP is available in two versions, a free version and a paid version
- The accuracy of the charged version is higher and the update frequency is more frequent
- Because GeoIP reads the local binary IP database, it is very efficient
4.3 IP address conversion
- Pure database, Turn ip into provincial and municipal
- The pure database collects IP address data of ISP s including China Telecom, China Mobile, China Unicom, Great Wall broadband and Juyou broadband
- The pure database is a binary file with open source java code. It can be simply modified and called
case class Location(ip: String, region: String, city: String, longitude: Float, latitude: Float)
private def ipToLocation(ip: String): Location ={
// 1 get service
val service = new LookupService("data/geoLiteCity.dat")
// 2 get Location
val longAndLatLocation = service.getLocation(ip)
// 3. Obtain longitude and dimension
val longitude = longAndLatLocation.longitude
val latitude = longAndLatLocation.latitude
// 4 use the innocence database to obtain provincial and municipal information
val ipService = new IPAddressUtils
val regeinLocation: IPLocation = ipService.getregion(ip)
val region = regeinLocation.getRegion
val city = regeinLocation.getCity
Location(ip, region, city, longitude, latitude)
}
Need to implement help class:
- Calculate the date of the day
import java.util.{Calendar, Date}
import org.apache.commons.lang.time.FastDateFormat
object DateUtils {
def getToday: String = {
val now = new Date
FastDateFormat.getInstance("yyyyMMdd").format(now)
}
def getYesterday: String = {
val calendar: Calendar = Calendar.getInstance
calendar.set(Calendar.HOUR_OF_DAY, -24)
FastDateFormat.getInstance("yyyyMMdd").format(calendar.getTime())
}
def main(args: Array[String]): Unit = {
println(getToday)
println(getYesterday)
}
}
4.4 complete realization of ETL
import java.util.Calendar
import cn.itbigdata.dmp.customtrait.Processor
import cn.itbigdata.dmp.util.iplocation.{IPAddressUtils, IPLocation}
import com.maxmind.geoip.LookupService
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object ETLProcessor extends Processor{
// Define parameters
private val sourceDataFile: String = "data/data.json"
private val sinkDataPath: String = s"outputdata/maindata.${getYesterday}"
private val geoFilePath: String = "data/geoLiteCity.dat"
override def process(spark: SparkSession): Unit = {
// 1 read data
val sourceDF: DataFrame = spark.read.json("data/data.json")
// 2 processing data
// 2.1 find ip
// 2.2 convert ip to province, city, longitude and dimension
import spark.implicits._
val ipDF: DataFrame = sourceDF.rdd
.map { row =>
val ip = row.getAs[String]("ip")
// Convert ip to province, city, longitude and latitude
ip2Location(ip)
}.toDF
// 2.2 join IPDF and sourceDF to add Province, city, longitude and latitude to each line
val sinkDF: DataFrame = sourceDF.join(ipDF, Seq("ip"), "inner")
// 3 save data
sinkDF.write.mode(SaveMode.Overwrite).json(sinkDataPath)
}
case class Location(ip: String, region: String, city: String, longitude: Float, latitude: Float)
private def ip2Location(ip: String): Location ={
// 1 get service
val service = new LookupService(geoFilePath)
// 2 get Location
val longAndLatLocation = service.getLocation(ip)
// 3. Obtain longitude and dimension
val longitude = longAndLatLocation.longitude
val latitude = longAndLatLocation.latitude
// 4 use the innocence database to obtain provincial and municipal information
val ipService = new IPAddressUtils
val regionLocation: IPLocation = ipService.getregion(ip)
val region = regionLocation.getRegion
val city = regionLocation.getCity
Location(ip, region, city, longitude, latitude)
}
private def getYesterday: String = {
val calendar: Calendar = Calendar.getInstance
calendar.set(Calendar.HOUR_OF_DAY, -24)
FastDateFormat.getInstance("yyyyMMdd").format(calendar.getTime())
}
}
5. Report development (data analysis – SparkSQL)
Reports to be processed
- Count the quantity distribution of each region (RegionStatProcessor)
- Statistics of regional distribution of advertising (region analysis processor)
- APP distribution statistics (AppAnalysisProcessor)
- Mobile device type distribution statistics (DeviceAnalysisProcessor)
- Network type distribution statistics (network analysis processor)
- Distribution statistics of network operators (IspAnalysisProcessor)
- Channel distribution statistics (ChannelAnalysisProcessor)
5.1 geographical distribution of data
- Steps of report processing
- Understand business requirements: find out the distribution of data volume according to provincial and municipal grouping
- Source data: daily log data, i.e. ETL result data;
- Target data: saved in a local file, and each report corresponds to a directory;
- Write SQL and test
- code implementation
- Define RegionStatProcessor, which inherits from Processor and implements process method. The specific implementation steps are as follows:
import cn.itbigdata.dmp.customtrait.Processor
import cn.itbigdata.dmp.utils.{ConfigHolder, DateUtils}
import org.apache.spark.sql.{SaveMode, SparkSession}
object RegionStatProcessor extends Processor{
override def process(spark: SparkSession): Unit = {
// Define parameters
val sourceDataPath = s"outputdata/maindata-${DateUtils.getYesterday}"
val sinkDataPath = "output/regionstat"
// read file
val sourceDF = spark.read.json(sourceDataPath)
sourceDF.createOrReplaceTempView("adinfo")
// Processing data
val RegionSQL1 =
"""
|select to_date(now()) as statdate, region, city, count(*) as infocount
| from adinfo
|group by region, city
|""".stripMargin
val sinkDF = spark.sql(RegionSQL1)
sinkDF.show()
// Write file
sinkDF.coalesce(1).write.mode(SaveMode.Append).json(sinkDataPath)
}
}
5.2 regional distribution of advertising
Complete the report in the following modes as required
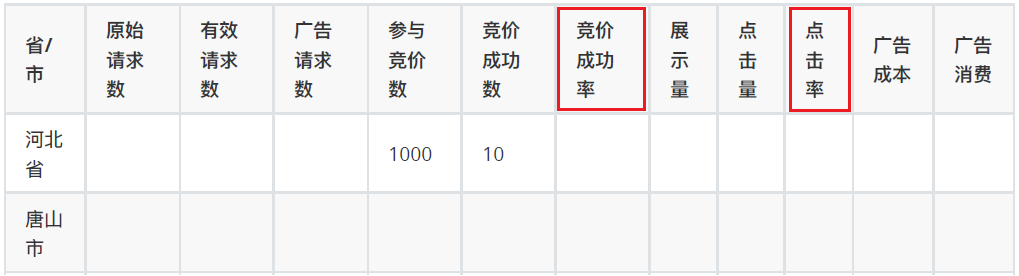
Note: three rates are required: bidding success rate, advertising click through rate and media click through rate
Index calculation logic
| index | explain | adplatformproviderid | requestmode | processnode | iseffective | isbilling | isbid | iswin | adorderid | adcreativeid |
|---|---|---|---|---|---|---|---|---|---|---|
| Original request | Number of all original requests sent | 1 | >=1 | |||||||
| Valid request | Number of valid physical examinations | 1 | >=2 | |||||||
| Advertising request | Number of requests that meet advertising requests | 1 | 3 | |||||||
| Number of bidding participants | Times of participating in bidding | >=100000 | 1 | 1 | 1 | !=0 | ||||
| Number of successful bidding | Number of successful bidding | >=100000 | 1 | 1 | 1 | |||||
| (Advertiser) number of displays | Statistics for advertisers: the number of advertisements finally displayed on the terminal | 2 | 1 | |||||||
| (Advertiser) hits | Statistics for advertisers: the actual number of clicks after the advertisement is displayed | 3 | 1 | |||||||
| Number of (media) displays | For media statistics: the number of advertisements displayed at the terminal | 2 | 1 | 1 | ||||||
| (media) hits | For media statistics: the number of actually clicked advertisements displayed | 3 | 1 | 1 | ||||||
| DSP advertising consumption | winprice/1000 | >=100000 | 1 | 1 | 1 | >200000 | >200000 | |||
| DSP advertising cost | Adptment/1000 | >=100000 | 1 | 1 | 1 | >200000 | >200000 |
DSP advertising consumption = DSP RTB money
DSP advertising cost = money paid by advertisers to DSP
DSP's profit = DSP advertising cost - DSP advertising consumption
Note: corresponding fields:
OriginalRequest,ValidRequest,adRequest
bidsNum,bidsSus,bidRate
adDisplayNum,adClickNum,adClickRate
MediumDisplayNum,MediumClickNum,MediumClickRate
adconsume,adcost
code implementation
import cn.itbigdata.dmp.customtrait.Processor
import cn.itbigdata.dmp.utils.DateUtils
import org.apache.spark.sql.{SaveMode, SparkSession}
object RegionAnalysisProcessor extends Processor{
override def process(spark: SparkSession): Unit = {
// Define parameters
val sourceDataPath = s"outputdata/maindata-${DateUtils.getYesterday}"
val sinkDataPath = "outputdata/regionanalysis"
// read file
val sourceDF = spark.read.json(sourceDataPath)
sourceDF.createOrReplaceTempView("adinfo")
// Processing data
val RegionSQL1 =
"""
|select to_date(now()) statdate, region, city,
| sum(case when requestmode=1 and processnode>=1 then 1 else 0 end) as OriginalRequest,
| sum(case when requestmode=1 and processnode>=2 then 1 else 0 end) as ValidRequest,
| sum(case when requestmode=1 and processnode=3 then 1 else 0 end) as adRequest,
| sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and isbid=1 and adorderid!=0
| then 1 else 0 end) as bidsNum,
| sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and iswin=1
| then 1 else 0 end) as bidsSus,
| sum(case when requestmode=2 and iseffective=1 then 1 else 0 end) as adDisplayNum,
| sum(case when requestmode=3 and iseffective=1 then 1 else 0 end) as adClickNum,
| sum(case when requestmode=2 and iseffective=1 and isbilling=1 then 1 else 0 end) as MediumDisplayNum,
| sum(case when requestmode=3 and iseffective=1 and isbilling=1 then 1 else 0 end) as MediumClickNum,
| sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1
| and iswin=1 and adorderid>200000 and adcreativeid>200000
| then winprice/1000 else 0 end) as adconsume,
| sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1
| and iswin=1 and adorderid>200000 and adcreativeid>200000
| then adpayment/1000 else 0 end) as adcost
| from adinfo
|group by region, city
| """.stripMargin
spark.sql(RegionSQL1).createOrReplaceTempView("tabtemp")
val RegionSQL2 =
"""
|select statdate, region, city,
| OriginalRequest, ValidRequest, adRequest,
| bidsNum, bidsSus, bidsSus/bidsNum as bidRate,
| adDisplayNum, adClickNum, adClickNum/adDisplayNum as adClickRate,
| MediumDisplayNum, MediumClickNum, MediumClickNum/MediumDisplayNum as mediumClickRate,
| adconsume, adcost
| from tabtemp
""".stripMargin
val sinkDF = spark.sql(RegionSQL2)
// Write file
sinkDF.coalesce(1).write.mode(SaveMode.Append).json(sinkDataPath)
}
}
6. Data tagging
6.1 what is data tagging
-
Why label data
-
Analyze data requirements
- The user's demand for data search supports the conditional screening of targeted people. For example:
- Region, even business district
- Gender
- Age
- interest
- equipment
- data format
Target data: (user id, all tags). The label is as follows:
( CH@123485 -> 1.0, KW@word -> 1.0, CT@Beijing ->1.0, Gd @ female - > 1.0, AGE@40 ->1.0, Ta @ Beihai - > 1.0, Ta @ Beach - > 1.0)
*Tag data organization form Map[String, Double]
*Prefix + label; 1.0 is the weight
*Labels to be made
- Advertising type
- channel
- App name
- Gender
- geographical position
- equipment
- key word
- Age
- Business district (temporarily ignored)
- Tagging of log data
-
Calculate tags (AD type, channel, AppName, gender...)
- Extract user ID
- Unified user identification
- Label data landing
6.2 framing
object TagProcessor extends Processor{
override def process(spark: SparkSession, kudu: KuduContext): Unit = {
// Define parameters
val sourceTableName = ConfigHolder.ADMainTableName
val sinkTableName = ""
val keys = ""
// 1 read data
val sourceDF = spark.read
.option("kudu.master", ConfigHolder.kuduMaster)
.option("kudu.table", sourceTableName)
.kudu
// 2 processing data
sourceDF.rdd
.map(row => {
// Advertising type, channel and App name
val adTags = AdTypeTag.make(row)
// Gender, geographical location, equipment
// Keywords, age, business district
})
// 3 save data
}
}
Define interface classes:
import org.apache.spark.sql.Row
trait TagMaker {
def make(row: Row, dic: collection.Map[String, String]=null): Map[String, Double]
}
6.3 labeling
6.3.1 ad type (AdTypeTag)
Field meaning 1: banner; 2: Insert screen; 3: Full screen
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.spark.sql.Row
object AdTypeTag extends TagMaker{
private val adPrefix = "adtype@"
override def make(row: Row, dic: collection.Map[String, String]): Map[String, Double] = {
// 1 value
val adType: Long = row.getAs[Long]("adspacetype")
// 1: banner; 2: Insert screen; 3: Full screen
// 2 Calculation label
adType match {
case 1 => Map(s"${adPrefix}banner" -> 1.0)
case 2 => Map(s"${adPrefix}Insert screen" -> 1.0)
case 3 => Map(s"${adPrefix}Full screen" -> 1.0)
case _ => Map[String, Double]()
}
}
}
6.3.2 channel (ChannelTag)
Field: channelid
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object ChannelTag extends TagMaker{
private val channelPrefix = "channel@"
override def make(row: Row, dic: collection.Map[String, String]=null): Map[String, Double] = {
// 1 value
val channelid = row.getAs[String]("channelid")
// 2 Calculation label
if (StringUtils.isNotBlank(channelid)){
Map(s"${channelPrefix}channelid" -> 1.0)
}
else
Map[String, Double]()
}
def main(args: Array[String]): Unit = {
// Judge whether a string is not empty, the length is not 0, and is not composed of white space (space)
if (!StringUtils.isNotBlank(null)) println("blank1 !")
if (!StringUtils.isNotBlank("")) println("blank2 !")
if (!StringUtils.isNotBlank(" ")) println("blank3 !")
}
}
6.3.3 App name (AppNameTag)
Field: appid; To convert appid to appname
Look up the given dictionary table: dicapp
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object AppNameTag extends TagMaker{
// Get prefix
private val appNamePrefix = "appname@"
override def make(row: Row, dic: collection.Map[String, String]): Map[String, Double] = {
// 1 get location information
val appId = row.getAs[String]("appid")
// 2 calculate and return labels
val appName = dic.getOrElse(appId, "")
if (StringUtils.isNotBlank(appName))
Map(s"${appNamePrefix}$appName" -> 1.0)
else
Map[String, Double]()
}
}
6.3.4 gender (SexTag)
Field: sex;
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object SexTag extends TagMaker{
private val sexPrefix: String = "sex@"
override def make(row: Row, dic: collection.Map[String, String]=null): Map[String, Double] = {
// Get tag information
val sexid: String = row.getAs[String]("sex")
val sex = sexid match {
case "1" => "male"
case "2" => "female"
case _ => "To be filled in"
}
// Calculation return label
if (StringUtils.isNotBlank(sex))
Map(s"$sexPrefix$sex" -> 1.0)
else
Map[String, Double]()
}
}
6.3.5 geographic location (GeoTag)
Fields: region, city
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object GeoTag extends TagMaker{
private val regionPrefix = "region@"
private val cityPrefix = "city@"
override def make(row: Row, dic: collection.Map[String, String]=null): Map[String, Double] = {
// Get tag information
val region = row.getAs[String]("region")
val city = row.getAs[String]("city")
// Calculate and return label information
val regionTag = if (StringUtils.isNotBlank(region))
Map(s"$regionPrefix$region" -> 1.0)
else
Map[String, Double]()
val cityTag = if (StringUtils.isNotBlank(city))
Map(s"$cityPrefix$city" -> 1.0)
else
Map[String, Double]()
regionTag ++ cityTag
}
}
6.3.6 equipment (DeviceTag)
Fields: client, networkmannername, ispname;
Data dictionary: dicdevice
- client: device type (1: android 2: ios 3: wp 4: others)
- networkmannername: name of networking mode (2G, 3G, 4G, others)
- ispname: operator name (Telecom, China Mobile, China Unicom...)
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object DeviceTag extends TagMaker{
val clientPrefix = "client@"
val networkPrefix = "network@"
val ispPrefix = "isp@"
override def make(row: Row, dic: collection.Map[String, String]): Map[String, Double] = {
// Get tag information
val clientName: String = row.getAs[Long]("client").toString
val networkName: String = row.getAs[Long]("networkmannername").toString
val ispName: String = row.getAs[Long]("ispname").toString
// Calculate and return labels
val clientId = dic.getOrElse(clientName, "D00010004")
val networkId = dic.getOrElse(networkName, "D00020005")
val ispId = dic.getOrElse(ispName, "D00030004")
val clientTag = if (StringUtils.isNotBlank(clientId))
Map(s"$clientPrefix$clientId" -> 1.0)
else
Map[String, Double]()
val networkTag = if (StringUtils.isNotBlank(networkId))
Map(s"$networkPrefix$networkId" -> 1.0)
else
Map[String, Double]()
val ispTag = if (StringUtils.isNotBlank(ispId))
Map(s"$ispPrefix$ispId" -> 1.0)
else
Map[String, Double]()
clientTag ++ networkTag ++ ispTag
}
}
6.3.7 keywords (KeywordTag)
Fields: keywords
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object KeywordsTag extends TagMaker{
private val keywordPrefix = "keyword@"
override def make(row: Row, dic: collection.Map[String, String]): Map[String, Double] = {
row.getAs[String]("keywords")
.split(",")
.filter(word => StringUtils.isNotBlank(word))
.map(word => s"$keywordPrefix$word" -> 1.0)
.toMap
}
}
6.3.8 age (AgeTag)
Field: age
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object AgeTag extends TagMaker{
private val agePrefix = "age@"
override def make(row: Row, dic: collection.Map[String, String]): Map[String, Double] = {
val age = row.getAs[String]("age")
if (StringUtils.isNotBlank(age))
Map(s"$agePrefix$age" -> 1.0)
else
Map[String, Double]()
}
}
6.3.9 main handler (TagProcessor)
import cn.itbigdata.dmp.customtrait.Processor
import cn.itbigdata.dmp.utils.DateUtils
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.sql.SparkSession
object TagProcessor extends Processor{
override def process(spark: SparkSession): Unit = {
// Define parameters
val sourceTableName = s"outputdata/maindata-${DateUtils.getYesterday}"
val appdicFilePath = "data/dicapp"
val deviceFilePath = "data/dicdevice"
val sinkTableName = ""
// 1 read data
val sourceDF = spark.read.json(sourceTableName)
// Read app information (file) and convert it into broadcast variable (optimization)
val appdicMap = spark.sparkContext.textFile(appdicFilePath)
.map(line => {
val arr: Array[String] = line.split("##")
(arr(0), arr(1))
}).collectAsMap()
val appdicBC: Broadcast[collection.Map[String, String]] = spark.sparkContext.broadcast(appdicMap)
// Read dictionary information (file) and convert it to broadcast variables (optimization)
val deviceMap = spark.sparkContext.textFile(deviceFilePath)
.map(line => {
val arr: Array[String] = line.split("##")
(arr(0), arr(1))
}).collectAsMap()
val deviceBC: Broadcast[collection.Map[String, String]] = spark.sparkContext.broadcast(deviceMap)
// 2 processing data
sourceDF.printSchema()
sourceDF.rdd
.map(row => {
// Advertising type, channel and App name
val adTags: Map[String, Double] = AdTypeTag.make(row)
val channelTags: Map[String, Double] = ChannelTag.make(row)
val appNameTags: Map[String, Double] = AppNameTag.make(row, appdicBC.value)
// Gender, geographical location, equipment type
val sexTags = SexTag.make(row)
val geoTags = GeoTag.make(row)
val deviceTags = DeviceTag.make(row, deviceBC.value)
// Keywords, age
val keywordsTags = KeywordsTag.make(row)
val ageTags = AgeTag.make(row)
// Return all data into a large Map
val tags = adTags ++ channelTags ++ appNameTags ++ sexTags ++ geoTags ++ deviceTags ++ keywordsTags ++ ageTags
tags
}).collect.foreach(println)
// 3 save data
}
}
6.4 extracting user ID
-
The log data is specific to a user's single browsing behavior
-
A user may have multiple pieces of data in a day
-
The label is for people
-
Existing problems:
-
Extract the concept of people from the data set so that one person can correspond to one piece of data
- The available user id cannot be found in the log information, so we can only go back to the second place, find the information of the device, and identify the user with the information of the device:
- IMEI: International Mobile Equipment Identity (IMEI), commonly known as mobile phone serial number and mobile phone "serial number", is used to identify each independent mobile phone and other mobile communication equipment in the mobile phone network, which is equivalent to the ID card of the mobile phone. IMEI is written on the motherboard. Reinstalling the APP will not change IMEI. Android 6.0 and above systems require the user to grant read_phone_state permission, which cannot be obtained if the user refuses;
- IDFA: launched in iOS 6, it can monitor the advertising effect and ensure that the user equipment is not tracked by the APP. Changes may occur, such as system reset and restoring the advertisement identifier in the settings. Users can open "restricted advertisement tracking" in settings;
- mac address: hardware identifier, including WiFi mac address and Bluetooth mac address. After iOS 7, it is prohibited;
- OpenUDID: when iOS 5 was released, UDID was abandoned, which caused the majority of developers to find a solution that can replace UDID and is not controlled by apple. Thus, OpenUDID became the most widely used alternative to open source UDID at that time. OpenUDID is very simple to implement in the project, and also supports a series of advertising providers;
- Android ID: when the device is started for the first time, the system will randomly generate a 64 bit number and save it in the form of hexadecimal string, which is ANDROID_ID, which will be reset when the device is wipe;
- The fields in the log data that can be used to identify users include:
- imei,mac,idfa,openudid,androidid
- imeimd5,macmd5,idfamd5,openudidmd5,androididmd5
- imeisha1,macsha1,idfasha1,openudidsha1,androididsha1
- What is invalid data: if all the above 15 fields are empty, this data cannot be associated with any user. This data is useless to us. It is invalid data. This data needs to be removed.
// Filtering is required when 15 fields are empty at the same time
lazy val filterSQL: String = idFields
.split(",")
.map(field => s"$field != ''")
.mkString(" or ")
// Extract user ID
val userIds = getUserIds(row)
// Return label
(userIds.head, (userIds, tags))
// Extract user ID
private def getUserIds(row: Row): List[String] = {
val userIds: List[String] = idFields.split(",")
.map(field => (field, row.getAs[String](field)))
.filter { case (key, value) => StringUtils.isNotBlank(value) }
.map { case (key, value) => s"$key::$value" }.toList
userIds
}
6.5 user identification
- Use fifteen fields (non empty) to jointly identify users
- During data collection:
- The data collected each time may be different fields
- Some fields may also change
- How to identify the data of the same user?
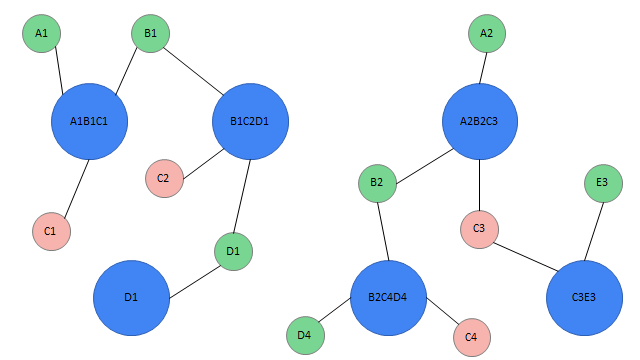
6.6 user identification & data aggregation and consolidation
// Unified user identification; Data aggregation and consolidation
private def graphxAnalysis(rdd: RDD[(List[String], List[(String, Double)])]): RDD[(List[String], List[(String, Double)])] ={
// 1 define vertices (data structure: Long, ""; algorithm: each element in the List can be used as a vertex, and the List itself can also be used as a vertex)
val dotsRDD: RDD[(String, List[String])] = rdd.flatMap{ case (lst1, _) => lst1.map(elem => (elem, lst1)) }
val vertexes: RDD[(Long, String)] = dotsRDD.map { case (id, ids) => (id.hashCode.toLong, "") }
// 2 define edges (data structure: Edge(Long, Long, 0))
val edges: RDD[Edge[Int]] = dotsRDD.map { case (id, ids) => Edge(id.hashCode.toLong, ids.mkString.hashCode.toLong, 0) }
// 3 generation diagram
val graph = Graph(vertexes, edges)
// 4 strongly connected graph
val idRDD: VertexRDD[VertexId] = graph.connectedComponents()
.vertices
// 5 definition data (ids and tags)
val idsRDD: RDD[(VertexId, (List[String], List[(String, Double)]))] =
rdd.map { case (ids, tags) => (ids.mkString.hashCode.toLong, (ids, tags)) }
// 6. join the results of step 4 with the results of step 5, and classify all the data [one user, one classification]
val joinRDD: RDD[(VertexId, (List[String], List[(String, Double)]))] = idRDD.join(idsRDD)
.map { case (key, value) => value }
// 7 data aggregation (data of the same user are put together)
val aggRDD: RDD[(VertexId, (List[String], List[(String, Double)]))] = joinRDD.reduceByKey { case ((bufferIds, bufferTags), (ids, tags)) =>
(bufferIds ++ ids, bufferTags ++ tags)
}
// 8. Data consolidation (de duplication for id and consolidation weight for tags)
val resultRDD: RDD[(List[String], List[(String, Double)])] = aggRDD.map { case (key, (ids, tags)) =>
val newTags = tags.groupBy(x => x._1)
.mapValues(lst => lst.map { case (word, weight) => weight }.sum)
.toList
(ids.distinct, newTags)
}
resultRDD
}
6.7 label landing
When saving data to kudu, please note:
1. Save a table every day (you need to create a new table). Table name: usertags_ Date of the day
2. Data type conversion RDD [(list [string], list [(string, double)])] = > RDD [(string, string)] = > dataframe
- Convert List[String] to String; Pay attention to the definition of separator
- Convert List[(String, Double)] to String. Pay attention to the definition of separator
- Separator: cannot be duplicate with the symbol in the data; The separator must be able to be added and removed.
// 3 data landing (kudu)
// Change the List data type to String
import spark.implicits._
val resultDF = mergeRDD.map{ case (ids, tags) =>
(ids.mkString("||"), tags.map{case (key, value) => s"$key->$value"}.mkString("||"))
}.toDF("ids", "tags")
DBUtils.appendData(kudu, resultDF, sinkTableName, keys)
}
// Get yesterday's date
6.8 tag processor
package cn.itcast.dmp.tags
import cn.itcast.dmp.Processor
import cn.itcast.dmp.utils.ConfigHolder
import org.apache.commons.lang3.StringUtils
import org.apache.kudu.spark.kudu.{KuduContext, KuduDataFrameReader}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, SparkSession}
object TagProcessor extends Processor{
override def process(spark: SparkSession, kudu: KuduContext): Unit = {
// Define parameters
val sourceTableName = ConfigHolder.ADMainTableName
val sinkTableName = ""
val keys = ""
val dicAppPath = ConfigHolder.appNameDic
val dicDevicePath = ConfigHolder.deviceDic
val tradingAreaTableName = ConfigHolder.tradingAreaTableName
val filterSQL = ConfigHolder.filterSQL
val idFields = ConfigHolder.idFields
// 1 read data
val sc = spark.sparkContext
val sourceDF = spark.read
.option("kudu.master", ConfigHolder.kuduMaster)
.option("kudu.table", sourceTableName)
.kudu
// Read app dictionary information
val appDic = sc.textFile(dicAppPath)
.map(line => {
val arr = line.split("##")
(arr(0), arr(1))
})
.collect()
.toMap
val appDicBC = sc.broadcast(appDic)
// Read device dictionary information
val deviceDic = sc.textFile(dicDevicePath)
.map(line => {
val arr = line.split("##")
(arr(0), arr(1))
})
.collect()
.toMap
val deviceDicBC = sc.broadcast(deviceDic)
// Read business district information (read; filter; convert to rdd; retrieve data; collect data to driver; convert to map)
// Restrictions: the information in the business district table should not be too large (the filtered size should be less than 20M)
val tradingAreaDic: Map[String, String] = spark.read
.option("kudu.master", ConfigHolder.kuduMaster)
.option("kudu.table", tradingAreaTableName)
.kudu
.filter("areas!=''")
.rdd
.map { case Row(geohash: String, areas: String) => (geohash, areas) }
.collect()
.toMap
val tradingAreaBC = sc.broadcast(tradingAreaDic)
// 2 processing data
// Filter the data whose 15 identification fields are empty
val userTagsRDD: RDD[(List[String], List[(String, Double)])] = sourceDF.filter(filterSQL)
.rdd
.map(row => {
// Advertising type, channel and App name
val adTags = AdTypeTag.make(row)
val channelTags = ChannelTag.make(row)
val appNameTags = AppNameTag.make(row, appDicBC.value)
// Gender, geographical location, equipment
val sexTags = SexTag.make(row, appDicBC.value)
val geoTags = GeoTag.make(row, appDicBC.value)
val deviceTags = DeviceTag.make(row, deviceDicBC.value)
// Keywords, age, business district
val keywordTags = KeywordTag.make(row, appDicBC.value)
val ageTags = AgeTag.make(row, appDicBC.value)
val tradingAreaTags = tradingAreaTag.make(row, tradingAreaDic.value)
// Label merge
val tags = adTags ++ channelTags ++ appNameTags ++ sexTags ++ geoTags ++ deviceTags ++ keywordTags ++ ageTags ++ tradingAreaTags
// Extract user ID
val userIds: List[String] = idFields.split(",")
.map(field => (field, row.getAs[String](field)))
.filter { case (key, value) => StringUtils.isNotBlank(value) }
.map { case (key, value) => s"$key::$value" }.toList
// Return label
(userIds, tags)
})
userTagsRDD.foreach(println)
// 3. Unify user identification and merge data
val mergeRDD: RDD[(List[String], List[(String, Double)])] = graphxAnalysis(logTagsRDD)
// 4 data landing (kudu)
// Change the List data type to String
import spark.implicits._
val resultDF = mergeRDD.map{ case (ids, tags) =>
(ids.mkString("|||"), tags.map{case (key, value) => s"$key->$value"}.mkString("|||"))
}.toDF("ids", "tags")
DBUtils.createTableAndsaveData(kudu, resultDF, sinkTableName, keys)
// close resource
sc.stop()
}
}
7,Spark GraphX
7.1 basic concept of figure calculation
Graph is a mathematical structure used to represent the model relationship between objects. A graph consists of vertices and edges connecting vertices. Vertices are objects and edges are relationships between objects.
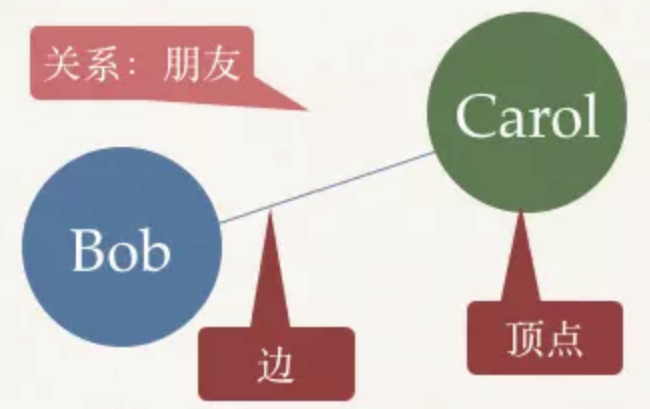
1555407826579.png
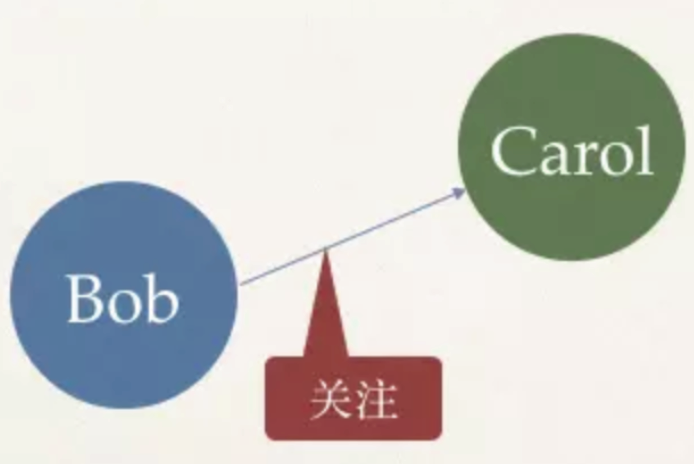
A directed graph is a graph in which the edges between vertices are directional. Examples of directed graphs are followers on Twitter. User Bob pays attention to user Carol, but Carol doesn't pay attention to Bob.
1555407851059.png
A graph is a graph that forms the relationship between different objects through points (objects) and edges (paths)
Figure 7.2 calculation application scenario
1) Shortest path
Shortest path in social networks, there is a six dimensional space theory, which means that there will be no more than five people between you and any stranger, that is, you can know any stranger through five intermediaries at most. This is also a graph algorithm, that is, the shortest path between any two people is less than or equal to 6.
2) Community discovery
Community discovery is used to find the number of triangles (circles) in social networks. It can analyze which circles are more stable and closer. It is used to measure the tightness of community coupling. The more triangles in a person's social circle, the more stable and close his social relationship is. For social networking sites such as Facebook and Twitter, the commonly used social analysis algorithm is community discovery.
3) Recommended algorithm (ALS)
Recommendation algorithm (ALS) als is a matrix decomposition algorithm. For example, if a shopping website wants to recommend goods to users, it needs to know which users are interested in which goods. At this time, a matrix can be constructed through ALS. In this matrix, if the goods purchased by users are 1 and those not purchased by users are 0, At this time, we need to calculate which zeros are likely to become 1
GraphX extends Spark RDD through an elastic distributed attribute graph.
Generally, in graph calculation, the basic data structure expression is:
- Graph = (Vertex,Edge)
- Vertex (vertex / node) (VertexId: Long, info: Any)
- Edge Edge(srcId: VertexId, dstId: VertexId, attr) [attr weight]
7.3 Spark GraphX example 1 (strong connector)
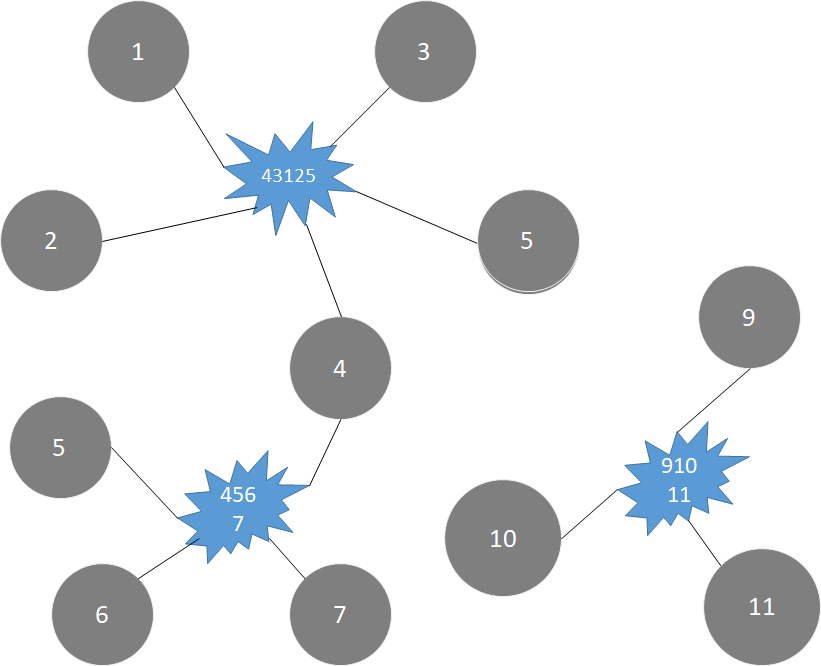
1557105493255.png
| ID | key word | AppName |
|---|---|---|
| 1 | Carola | Group car |
| 2 | Bali, Indonesia | Where to travel |
| 3 | Master Shandao | Know |
| 4 | The king's woman, the beauty has no tears | Youku |
| 5 | World Cup | Sohu |
| 6 | Carina Lau, Hong Kong and Taiwan Entertainment | Phoenix net |
| 7 | Japan and South Korea Entertainment | Pepper direct seeding |
| 9 | AK47 | Jedi survival: stimulating the battlefield |
| 10 | Funny | YY live broadcast |
| 11 | Literature, current politics | Know |
| ID | IDS |
|---|---|
| 1 | 43125 |
| 2 | 43125 |
| 3 | 43125 |
| 4 | 43125 |
| 5 | 43125 |
| 4 | 4567 |
| 5 | 4567 |
| 6 | 4567 |
| 7 | 4567 |
| 9 | 91011 |
| 10 | 91011 |
| 11 | 91011 |
Connected Components algorithm:
1. Define vertex
2. Define edge
3. Generate graph
4. Each connector in the graph is labeled, and the id of the vertex with the smallest sequence number in the connector is taken as the id of the connector
Task:
- Define vertex
- Define edge
- Generate graph
- Generating strongly connected graphs
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object GraphXDemo1 {
def main(args: Array[String]): Unit = {
// 1. Initialize sparkcontext
val conf = new SparkConf()
.setAppName("GraphXDemo1")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
// 2. Define vertices (VertexId: Long, info: Any)
val vertexes: RDD[(VertexId, Map[String, Double])] = sc.makeRDD(List(
(1L, Map("keyword:Carola" -> 1.0, "AppName:Group car" -> 1.0)),
(2L, Map("keyword:Indonesia" -> 1.0, "keyword:Bali" -> 1.0, "AppName:Where to travel" -> 1.0)),
(3L, Map("keyword:Master Shandao" -> 1.0, "AppName:Know" -> 1.0)),
(4L, Map("keyword:The king's Woman" -> 1.0, "keyword:Beauty without tears" -> 1.0, "AppName:Youku" -> 1.0)),
(5L, Map("keyword:World Cup" -> 1.0, "AppName:Sohu" -> 1.0)),
(6L, Map("keyword:Carina Lau" -> 1.0, "keyword:Hong Kong and Taiwan Entertainment" -> 1.0, "AppName:Phoenix net" -> 1.0)),
(7L, Map("keyword:Japan and South Korea Entertainment" -> 1.0, "AppName:Pepper direct seeding" -> 1.0)),
(9L, Map("keyword:AK47" -> 1.0, "AppName:Jedi survival:Stimulate the battlefield" -> 1.0)),
(10L, Map("keyword:Funny" -> 1.0, "AppName:YY live broadcast" -> 1.0)),
(11L, Map("keyword:literature" -> 1.0, "keyword:Current politics" -> 1.0, "AppName:Know" -> 1.0))
))
// 3. Define Edge(srcId: VertexId, dstId: VertexId, attr)
val edges: RDD[Edge[Int]] = sc.makeRDD(List(
Edge(1L, 42125L, 0),
Edge(2L, 42125L, 0),
Edge(3L, 42125L, 0),
Edge(4L, 42125L, 0),
Edge(5L, 42125L, 0),
Edge(4L, 4567L, 0),
Edge(5L, 4567L, 0),
Edge(6L, 4567L, 0),
Edge(7L, 4567L, 0),
Edge(9L, 91011, 0),
Edge(10L, 91011, 0),
Edge(11L, 91011, 0)
))
// 4. Generate diagram; Generate strong connectivity graph
Graph(vertexes, edges)
.connectedComponents()
.vertices
.sortBy(_._2)
.collect()
.foreach(println)
// 5. Resource release
sc.stop()
}
}
7.4 Spark GraphX ex amp le 2 (user identification & data merging)
According to the previous example, we already know how to identify users according to rules and how the program handles them?
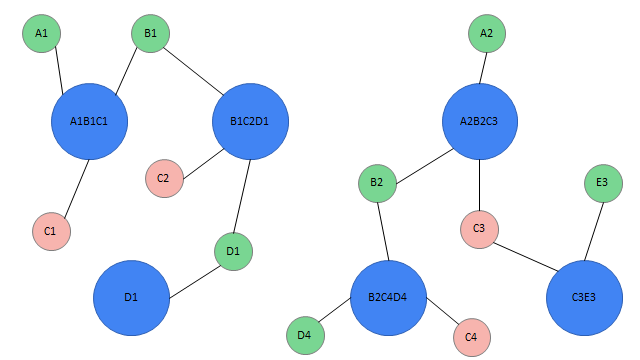
Definition of data:
remarks:
1. The data format defined here is completely consistent with the data format in our program
2. RDD is a tuple, and the first element represents various user IDs; The second element represents the user's label
Task:
1. How many users do the six pieces of data represent
2. Merge data of the same user
val dataRDD: RDD[(List[String], List[(String, Double)])] = sc.makeRDD(List(
(List("a1", "b1", "c1"), List("keyword$Beijing" -> 1.0, "keyword$Shanghai" -> 1.0, "area$Zhongguancun" -> 1.0)),
(List("b1", "c2", "d1"), List("keyword$Shanghai" -> 1.0, "keyword$Tianjin" -> 1.0, "area$Hui Longguan" -> 1.0)),
(List("d1"), List("keyword$Tianjin" -> 1.0, "area$Zhongguancun" -> 1.0)),
(List("a2", "b2", "c3"), List("keyword$big data" -> 1.0, "keyword$spark" -> 1.0, "area$Xierqi" -> 1.0)),
(List("b2", "c4", "d4"), List("keyword$spark" -> 1.0, "area$Wudaokou" -> 1.0)),
(List("c3", "e3"), List("keyword$hive" -> 1.0, "keyword$spark" -> 1.0, "area$Xierqi" -> 1.0))
))
Complete processing steps:
- Define vertex
- Define edge
- Generate graph
- Find strong connectome
- Find data to merge
- Data aggregation
- Data merging
Handler:
import org.apache.spark.graphx.{Edge, Graph, VertexId, VertexRDD}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object GraphXDemo {
def main(args: Array[String]): Unit = {
// initialization
val conf: SparkConf = new SparkConf().setAppName("GraphXDemo").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("error")
// Define data
val dataRDD: RDD[(List[String], List[(String, Double)])] = sc.makeRDD(List(
(List("a1", "b1", "c1"), List("kw$Beijing" -> 1.0, "kw$Shanghai" -> 1.0, "area$Zhongguancun" -> 1.0)),
(List("b1", "c2", "d1"), List("kw$Shanghai" -> 1.0, "kw$Tianjin" -> 1.0, "area$Hui Longguan" -> 1.0)),
(List("d1"), List("kw$Tianjin" -> 1.0, "area$Zhongguancun" -> 1.0)),
(List("a2", "b2", "c3"), List("kw$big data" -> 1.0, "kw$spark" -> 1.0, "area$Xierqi" -> 1.0)),
(List("b2", "c4", "d4"), List("kw$spark" -> 1.0, "area$Wudaokou" -> 1.0)),
(List("c3", "e3"), List("kw$hive" -> 1.0, "kw$spark" -> 1.0, "area$Xierqi" -> 1.0))
))
val value: RDD[(String, List[String], List[(String, Double)])] = dataRDD.flatMap { case (allIds: List[String], tags: List[(String, Double)]) => {
allIds.map { case elem: String => (elem, allIds, tags) }
}
}
// 1 extract each element in the identification information as an id
// Note 1. flatMap is used here to flatten the elements;
// Note 2. The label information is lost here, because this RDD is mainly used to construct vertices and edges, and the tags information is not used
// Note 3. Vertex and edge data require Long, so data type conversion is done here
val dotRDD: RDD[(VertexId, VertexId)] = dataRDD.flatMap { case (allids, tags) =>
// Method 1: easy to understand, not easy to write
// for (id <- allids) yield {
// (id.hashCode.toLong, allids.mkString.hashCode.toLong)
// }
// Method 2: not easy to understand, easy to write. Equivalence of two methods
allids.map(id => (id.hashCode.toLong, allids.mkString.hashCode.toLong))
}
// 2 define vertices
val vertexesRDD: RDD[(VertexId, String)] = dotRDD.map { case (id, ids) => (id, "") }
// 3 define edges (id: single identification information; ids: all identification information)
val edgesRDD: RDD[Edge[Int]] = dotRDD.map { case (id, ids) => Edge(id, ids, 0) }
// 4 generation diagram
val graph = Graph(vertexesRDD, edgesRDD)
// 5 find the strong connectome
val connectRDD: VertexRDD[VertexId] = graph.connectedComponents()
.vertices
// 6 data defining the center point
val centerVertexRDD: RDD[(VertexId, (List[String], List[(String, Double)]))] = dataRDD.map { case (allids, tags) =>
(allids.mkString.hashCode.toLong, (allids, tags))
}
// 7. join the data in steps 5 and 6 to obtain the data to be merged
val allInfoRDD = connectRDD.join(centerVertexRDD)
.map { case (id1, (id2, (allIds, tags))) => (id2, (allIds, tags)) }
// 8 data aggregation (i.e. putting the identity and label of the same user together)
val mergeInfoRDD: RDD[(VertexId, (List[String], List[(String, Double)]))] = allInfoRDD.reduceByKey { case ((bufferList, bufferMap), (allIds, tags)) =>
val newList = bufferList ++ allIds
// Merging of map s
val newMap = bufferMap ++ tags
(newList, newMap)
}
// 9. Data consolidation (allIds: de duplication; tags: consolidation weight)
val resultRDD: RDD[(List[String], Map[String, Double])] = mergeInfoRDD.map { case (key, (allIds, tags)) =>
val newIds = allIds.distinct
// Aggregate according to key; Then the second element of lst obtained by aggregation is accumulated
val newTags = tags.groupBy(x => x._1).mapValues(lst => lst.map(x => x._2).sum)
(newIds, newTags)
}
resultRDD.foreach(println)
sc.stop()
}
// def main(args: Array[String]): Unit = {
// val lst = List(
// ("kw $big data", 1.0),
// ("kw$spark",1.0),
// ("area $Xierqi", 1.0),
// ("kw$spark",1.0),
// ("area $Wudaokou", 1.0),
// ("kw$hive",1.0),
// ("kw$spark",1.0),
// ("area $Xierqi", 1.0)
// )
//
// lst.groupBy(x=> x._1).map{case (key, value) => (key, value.map(x=>x._2).sum)}.foreach(println)
// println("************************************************************")
//
// lst.groupBy(x=> x._1).mapValues(lst => lst.map(x=>x._2).sum).foreach(println)
// println("************************************************************")
}