PPASR streaming and non streaming speech recognition
The project will be divided into three stages: beginner ,Progressive class and Final stage Branch, which is currently the final level and continuously maintains the version. PPASR Chinese name PaddlePaddle Chinese speech recognition (PaddlePaddle Automatic Speech Recognition), is a PaddlePaddle based speech recognition framework, PPASR is committed to simple and practical speech recognition project. It can be deployed on servers, Nvidia Jetson devices, and plans to support Android and other mobile devices in the future.
Environment used in the project:
- Anaconda 3
- Python 3.7
- PaddlePaddle 2.2.0
- Windows 10 or Ubuntu 18.04
Model Download
| data set | Use model | Test set word error rate | Download address |
|---|---|---|---|
| aishell(179 hours) | deepspeech2 | 0.077042 | Click download |
| free_st_chinese_mandarin_corpus(109 hours) | deepspeech2 | 0.171830 | Click download |
| thchs_30(34 hours) | deepspeech2 | 0.062654 | Click download |
| Super large data set (more than 1600 hours of real data) + (more than 1300 hours of synthetic data) | deepspeech2 | In training | In training |
explain:
- Here, the word error rate is to use the eval.py program and use the cluster search to decode CTC_ beam_ Calculated by search method.
- In addition to the training data and test data divided by the aishell data set according to the data set itself, the others are divided into training data and test data according to the fixed proportion set by the project.
- The downloaded compressed file already contains mean_std.npz and vocabulary.txt. You need to copy all the extracted files to the project root directory.
Any questions are welcome issue communication
Fast prediction
- Download the model or training model provided by the author, and then execute Export model , using infer_path.py predicts the audio through the parameter -- wav_path specifies the audio path to be predicted to complete speech recognition. Please check for details Model deployment.
python infer_path.py --wav_path=./dataset/test.wav
Output results:
----------- Configuration Arguments ----------- alpha: 1.2 beam_size: 10 beta: 0.35 cutoff_prob: 1.0 cutoff_top_n: 40 decoding_method: ctc_greedy enable_mkldnn: False is_long_audio: False lang_model_path: ./lm/zh_giga.no_cna_cmn.prune01244.klm mean_std_path: ./dataset/mean_std.npz model_dir: ./models/infer/ to_an: True use_gpu: True use_tensorrt: False vocab_path: ./dataset/zh_vocab.txt wav_path: ./dataset/test.wav ------------------------------------------------ Elapsed time: 132, Identification results: In recent years, I not only gave my daughter New Year's greetings with books, but also persuaded my relatives and friends not to give my daughter New Year's money but to send new year's greetings instead, score: 94
Data preparation
- In download_ The data directory is for downloading public data sets and making training data lists and vocabularies. This project provides downloading public Chinese Putonghua voice data sets, namely Aishell, free st Chinese Mandarin corpus and THCHS-30, with a total size of more than 28G. To download these three data, you only need to execute the code. Of course, if you want to train quickly, you can download only one of them. Note: noise.py can be downloaded or not. It is used for data enhancement during training. If you don't want to use noise data enhancement, you don't need to download it.
cd download_data/ python aishell.py python free_st_chinese_mandarin_corpus.py python thchs_30.py python noise.py
Note: the above code only supports execution under Linux. If it is Windows, you can obtain the data in the program_ The URL is downloaded separately. It is recommended to use Xunlei and other download tools, so that the download speed is much faster. Then change the download() function to the absolute path of the file. As follows, I download the file of aishell.py separately, replace the download() function, and then execute the program. The file text will be automatically decompressed to generate a data list.
# Put this line of code filepath = download(url, md5sum, target_dir) # Change to filepath = "D:\\Download\\data_aishell.tgz"
- If developers have their own data sets, they can use their own data sets for training. Of course, they can also train with the data sets downloaded above. The customized voice data needs to conform to the following format. In addition, for the audio sampling rate, 16000Hz is used by default in this project. In create_data.py also provides a unified audio data sampling rate conversion to 16000Hz, as long as is_ change_ frame_ Set the rate parameter to True.
- Voice files need to be placed in the dataset/audio / directory. For example, we have a wav folder, which is full of voice files, so we store this file in dataset/audio /.
- Then save the data list file in the dataset/annotation / directory, and the program will traverse all the data list files under this file. For example, a my file is stored under this file_ Audio.txt. Its content format is as follows. Each line of data contains the relative path of the voice file and the Chinese text corresponding to the voice file, which are separated by \ t. It should be noted that the Chinese text can only contain pure Chinese, not punctuation marks, Arabic numerals and English letters.
dataset/audio/wav/0175/H0175A0171.wav I need to turn the air conditioner to 20 degrees dataset/audio/wav/0175/H0175A0377.wav Brilliant Chinese dataset/audio/wav/0175/H0175A0470.wav Monitored by Kerry Research Center dataset/audio/wav/0175/H0175A0180.wav Increase the temperature to eighteen
- Finally, execute the following dataset processing program. Please check the program for detailed parameters. This program generates three JSON data lists from our data set, namely manifest.test, manifest.train and manifest.noise. Then create a vocabulary and store all the characters in the vocabulary.txt file, one character per line. Finally, the mean and standard deviation are calculated for normalization. By default, all speech are used to calculate the mean and standard deviation, and the results are saved in mean_std.npz. The above generated files are stored in the dataset / directory. Description of data division: if test.txt exists in dataset/annotation, all test data will use this data; otherwise, 1 / 500 of all data will be used until the specified maximum test data volume.
python create_data.py
Training model
-
In the training process, the first step is to prepare the data set. See the details Data preparation Section, focusing on executing create_ After the data.py program is executed, check whether manifest.test, manifest.train and mean are generated in the dataset directory_ Std.npz and vocabulary.txt, and make sure that they already contain data. Then you can go down and start training.
-
Execute the training script and start training the speech recognition model. Please check the program for detailed parameters. The model will be saved once every training round and every 10000 batch es, and the model will be saved in models / < use_ model>/epoch_*/ In the directory, data enhancement training will be used by default. If you don't want to use data enhancement, just set the parameter augment_ conf_ Set path to None. For data enhancements, see Data enhancement part. If the test is not closed, the test will be executed after each round of training results to calculate the accuracy of the model in the test set. Note that in order to speed up the training, CTC is used by default_ Greedy decoder, use CTC if necessary_ beam_ Search decoder, please set the decoder parameter. If the model folder contains last_ The model folder will automatically load the models in it during training. This is to facilitate training after training is interrupted. There is no need to specify manually. If resume is specified manually_ Model parameter, then resume_ The path specified by model takes precedence. If it is not the original dataset or model structure, you need to delete last_ The model folder.
# Single card training python3 train.py # Multi card training python -m paddle.distributed.launch --gpus '0,1' train.py
The training output results are as follows:
----------- Configuration Arguments ----------- alpha: 2.2 augment_conf_path: conf/augmentation.json batch_size: 32 beam_size: 300 beta: 4.3 cutoff_prob: 0.99 cutoff_top_n: 40 dataset_vocab: dataset/vocabulary.txt decoder: ctc_greedy lang_model_path: lm/zh_giga.no_cna_cmn.prune01244.klm learning_rate: 5e-05 max_duration: 20 mean_std_path: dataset/mean_std.npz min_duration: 0.5 num_epoch: 65 num_proc_bsearch: 10 num_workers: 8 pretrained_model: None resume_model: None save_model_path: models/ test_manifest: dataset/manifest.test train_manifest: dataset/manifest.train use_model: deepspeech2 ------------------------------------------------ ............ [2021-09-17 08:41:16.135825] Train epoch: [24/50], batch: [5900/6349], loss: 3.84609, learning rate: 0.00000688, eta: 10:38:40 [2021-09-17 08:41:38.698795] Train epoch: [24/50], batch: [6000/6349], loss: 0.92967, learning rate: 0.00000688, eta: 8:42:11 [2021-09-17 08:42:04.166192] Train epoch: [24/50], batch: [6100/6349], loss: 2.05670, learning rate: 0.00000688, eta: 10:59:51 [2021-09-17 08:42:26.471328] Train epoch: [24/50], batch: [6200/6349], loss: 3.03502, learning rate: 0.00000688, eta: 11:51:28 [2021-09-17 08:42:50.002897] Train epoch: [24/50], batch: [6300/6349], loss: 2.49653, learning rate: 0.00000688, eta: 12:01:30 ====================================================================== [2021-09-17 08:43:01.954403] Test batch: [0/65], loss: 13.76276, cer: 0.23105 [2021-09-17 08:43:07.817434] Test epoch: 24, time/epoch: 0:24:30.756875, loss: 6.90274, cer: 0.15213 ======================================================================
- In the training process, the program will use VisualDL to record the training results. You can start VisualDL through the following command.
visualdl --logdir=log --host=0.0.0.0
- Then access it on the browser http://localhost:8040 You can view the results as follows.
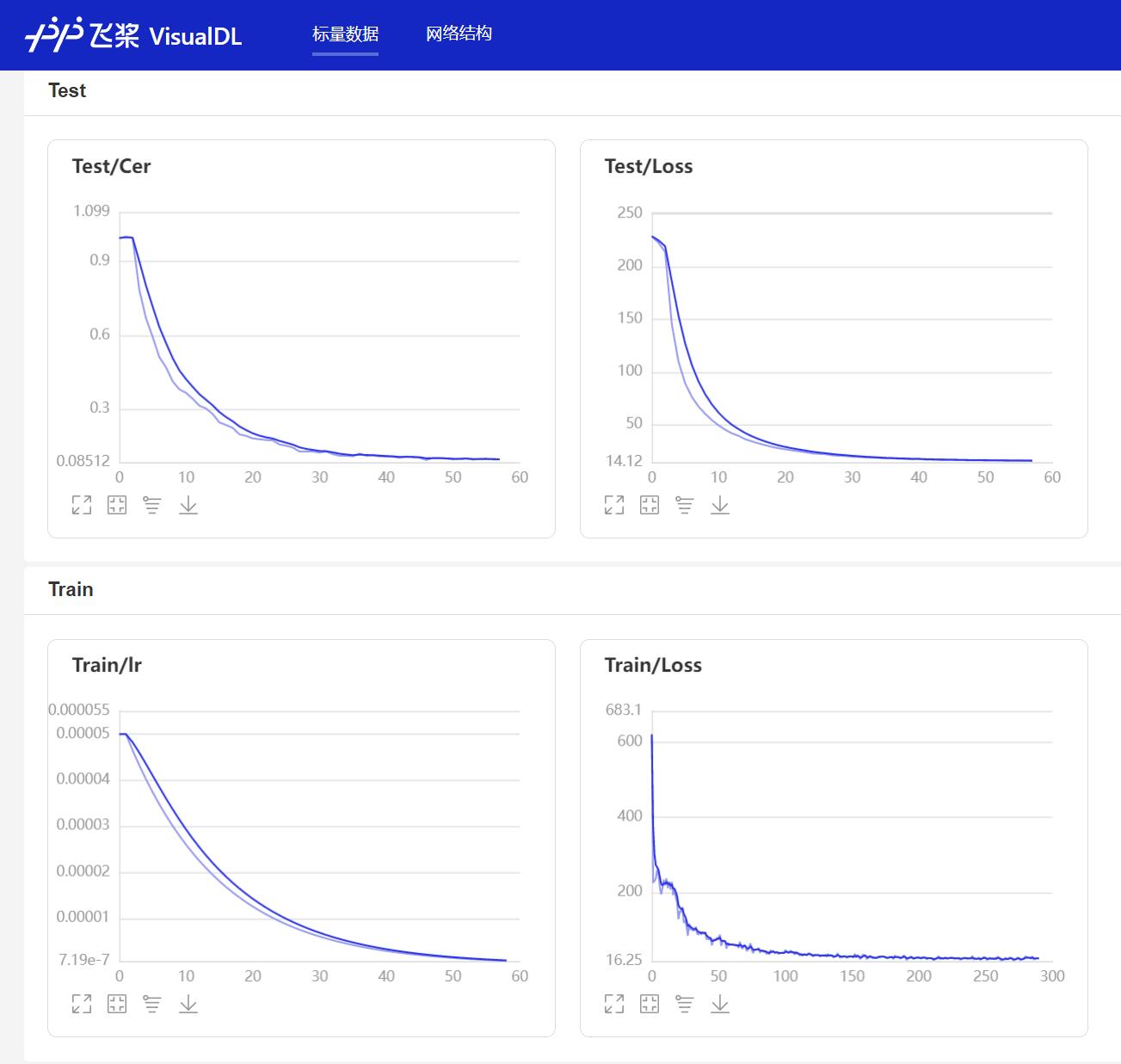
assessment
Execute the following script to evaluate the model and evaluate the performance of the model through the character error rate. Please check the program for detailed parameters.
python eval.py --resume_model=models/deepspeech2/best_model
Output results:
----------- Configuration Arguments ----------- alpha: 2.2 batch_size: 32 beam_size: 300 beta: 4.3 cutoff_prob: 0.99 cutoff_top_n: 40 dataset_vocab: dataset/vocabulary.txt decoder: ctc_beam_search lang_model_path: lm/zh_giga.no_cna_cmn.prune01244.klm mean_std_path: dataset/mean_std.npz num_proc_bsearch: 10 num_workers: 8 resume_model: models/deepspeech2/best_model/ test_manifest: dataset/manifest.test use_model: deepspeech2 ------------------------------------------------ W0918 10:33:58.960235 16295 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.0, Runtime API Version: 10.2 W0918 10:33:58.963088 16295 device_context.cc:422] device: 0, cuDNN Version: 7.6. 100%|██████████████████████████████| 45/45 [00:09<00:00, 4.50it/s] Evaluation time: 10 s,Word error rate: 0.095808
Export model
The model saved in training or downloaded from the author is a model parameter. We want to export it as a prediction model. In this way, we can use the model directly without model structure code. At the same time, we can speed up the prediction by using the influence interface. Please check the program for detailed parameters.
python export_model.py --resume_model=models/deepspeech2/epoch_50/
Output results:
----------- Configuration Arguments ----------- dataset_vocab: dataset/vocabulary.txt mean_std_path: dataset/mean_std.npz resume_model: models/deepspeech2/epoch_50 save_model: models/deepspeech2/ use_model: deepspeech2 ------------------------------------------------ [2021-09-18 10:23:47.022243] Successfully recover model parameters and optimization method parameters: models/deepspeech2/epoch_50/model.pdparams Forecast model saved: models/deepspeech2/infer
Local prediction
We can use this script to predict using the model. If the model has not been exported, it needs to be executed Export model The operation exports the model parameters as a prediction model, and identifies them by passing the path of the audio file through the parameter -- wav_path specifies the audio path that needs to be predicted. Support the conversion of Chinese numbers to Arabic numbers, and set the parameter -- to_an can be set to True, which is True by default.
python infer_path.py --wav_path=./dataset/test.wav
Output results:
----------- Configuration Arguments ----------- alpha: 2.2 beam_size: 300 beta: 4.3 cutoff_prob: 0.99 cutoff_top_n: 40 decoder: ctc_beam_search is_long_audio: False lang_model_path: lm/zh_giga.no_cna_cmn.prune01244.klm model_dir: models/deepspeech2/infer/ real_time_demo: False to_an: True use_gpu: True use_model: deepspeech2 vocab_path: dataset/vocabulary.txt wav_path: ./dataset/test.wav ------------------------------------------------ Elapsed time: 101, Identification results: In recent years, I not only gave my daughter New Year's greetings with books, but also persuaded my relatives and friends not to give my daughter New Year's money but to send new year's greetings instead, score: 94
Long speech prediction
Pass parameter -- is_long_audio can specify the use of long speech recognition. In this way, the audio is segmented through VAD, and then the short audio is recognized and spliced to obtain the long speech recognition result.
python infer_path.py --wav_path=./dataset/test_vad.wav --is_long_audio=True
Output results:
----------- Configuration Arguments ----------- alpha: 2.2 beam_size: 300 beta: 4.3 cutoff_prob: 0.99 cutoff_top_n: 40 decoding_method: ctc_greedy is_long_audio: 1 lang_model_path: ./lm/zh_giga.no_cna_cmn.prune01244.klm model_dir: ./models/deepspeech2/infer/ to_an: True use_gpu: True vocab_path: ./dataset/zh_vocab.txt wav_path: dataset/test_vad.wav ------------------------------------------------ 0th split audio, score: 70, Identification results: Remember the 12 paving, buying spears, random drilling, eating out, you're full. Now there's only one good solution. It's too poor. The smelly power is not tight, and it's still tied to the iron stock of Dali Dagao 1st split audio, score: 86, Identification results: We all talk on our own 2nd split audio, score: 91, Identification results: He wondered if Li Dakang knew the party's organizational principles 3rd split audio, score: 71, Identification results: Li Dafang just asked him to make a long piece, 2 with 1 cool, and he made a note book 4th split audio, score: 76, Identification results: I have to listen to her when he's a bear's paw. Ha ha, he's growing up too fast. He has to talk. What do you say 5th split audio, score: 97, Identification results: His wife always has an accident 6th split audio, score: 63, Identification results: It's the first time 7th split audio, score: 87, Identification results: Ouyangqing is his ex-wife 8th split audio, score: 0, Identification results: 9th split audio, score: 97, Identification results: Let me say one last word 10th split audio, score: 84, Identification results: Can you do me a little favor 11th split audio, score: 86, Identification results: say 12th split audio, score: 85, Identification results: She let Chen Qingquan go. Don't pursue it any more 13th split audio, score: 93, Identification results: This is Chen Qingquan 14th split audio, score: 79, Identification results: Have a baby with you. I'll come 15th split audio, score: 87, Identification results: I don't know anyone 16th split audio, score: 81, Identification results: It's Gao Xiaoqin. Why do you care so wide 17th split audio, score: 94, Identification results: I really take the world as my duty 18th split audio, score: 76, Identification results: You're the best person in the world. That's why you tricked me. Last night, the people in Shanshui Zhangyuan asked me to take photos and practice the board method in my whole life 19th split audio, score: 67, Identification results: It's too late for your career. It's up to changweitai to decide later Final result, elapsed time: 1587, score: 79, Identification results: ,We all said on our own that Li Dakang knew about the party's organizational principles and won the prize if he didn't get it. Li Dafang asked him to make a long piece of it. 2. One piece of it was cool. He made a note of it, Well, I have to listen to her when I'm a bear's paw. Ha ha, he grows up too fast and needs to talk. How can you say, his wife always has an accident? It's urgent. Ouyangqing is his ex-wife. I'll say one last word. Can you do me a little favor and say, don't pursue her if she releases Chen Qingquan? Chen Qingquan, I have a baby with you. I come here. I don't know anyone, It's Gao Xiaoqin's people. Why do you care so much? It's really your responsibility to take the world as your own. You're the best person in the world. That's why you tricked me. Last night, the people in Shanshui Zhangyuan asked me to take photos and practice the board method. Your career is really late. It's up to Changwei platform to decide later
Web deployment
Execute the following command on the server to create a Web service and realize speech recognition by providing HTTP interface. After starting the service, if it is running locally, it can be accessed on the browser http://localhost:5000 Otherwise, it is modified to the corresponding IP address. After opening the page, you can choose to upload long or short voice audio files, or record directly on the page. After recording, click upload. The playback function only supports recorded audio. Support the conversion of Chinese numbers to Arabic numbers, and set the parameter -- to_an can be set to True, which is True by default.
python infer_server.py
The open page is as follows:
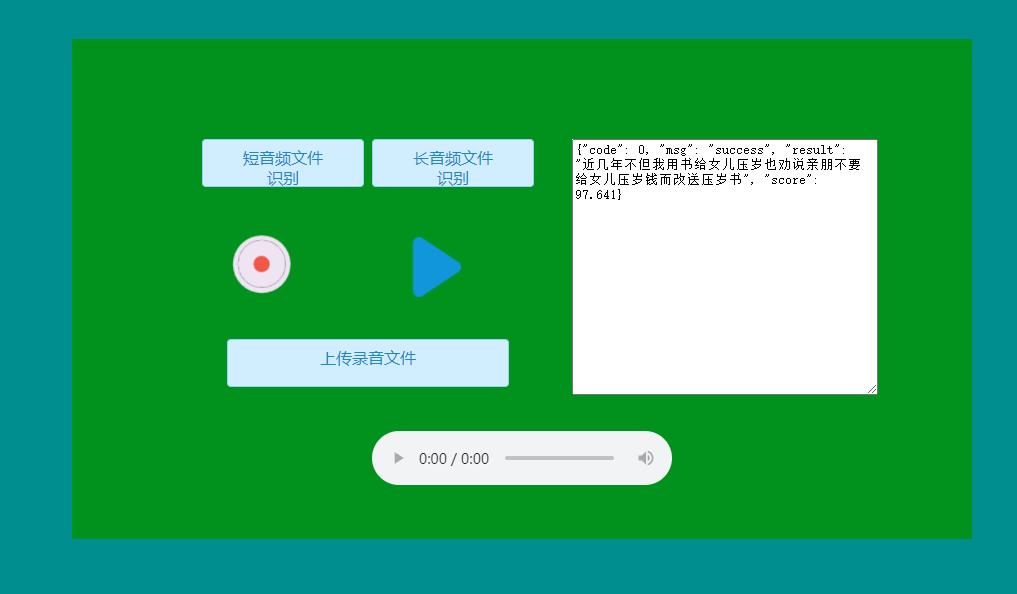
GUI interface deployment
By opening the page, select long speech or short speech on the page for recognition. It also supports recording recognition and plays the recognized audio at the same time. The greedy decoding strategy is used by default. If the cluster search method needs to be used, it needs to be specified when starting the parameters.
python infer_gui.py
The opening interface is as follows:
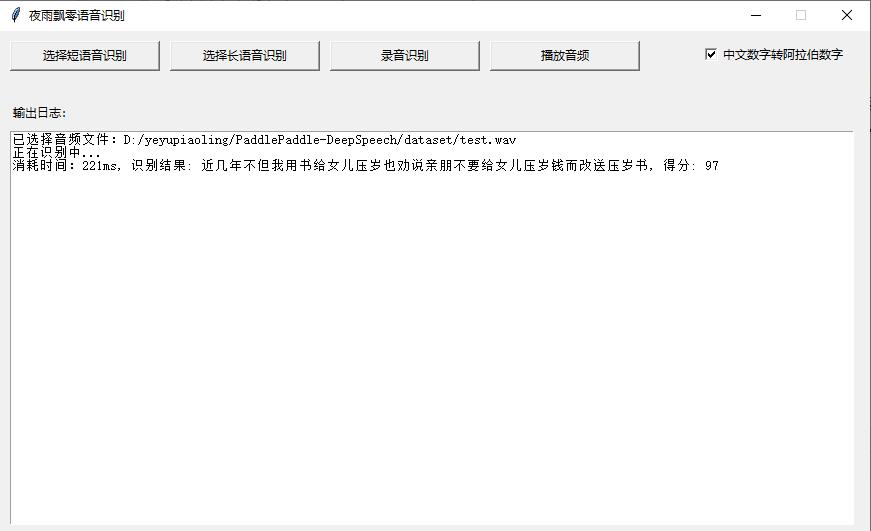
Related items
- Voiceprint recognition based on PaddlePaddle: VoiceprintRecognition-PaddlePaddle
- Speech recognition based on PaddlePaddle static map: PaddlePaddle-DeepSpeech
- Speech recognition based on pytoch: MASR
reference material
- https://github.com/PaddlePaddle/PaddleSpeech
- https://github.com/jiwidi/DeepSpeech-pytorch
- https://github.com/wenet-e2e/WenetSpeech