2021SC@SDUSC
catalogue
Hash index
In addition to using B-Tree index, postgreSQL can also use hash index. Hash index has faster query speed. This article mainly explains the principle of hash index, compares it with B-Tree, and analyzes the relevant data structure of hash index in the source code.
Hash indexing principle
Hash table
The hash table is also a hash table, and its principle is shown in the figure below
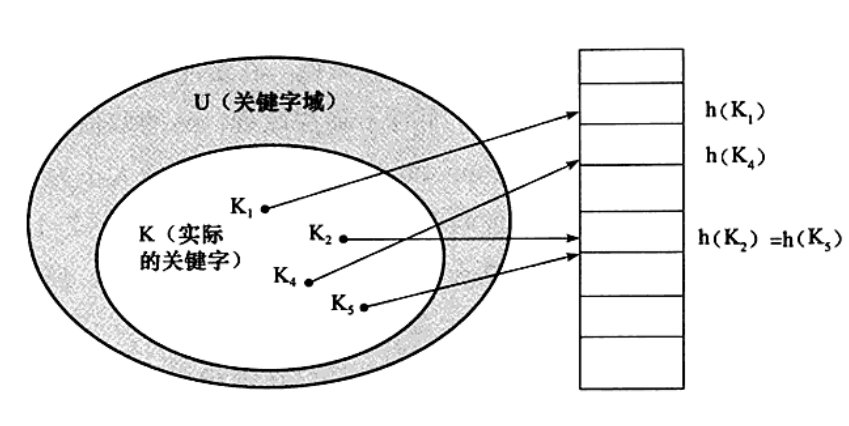
The core of Hash index is to build a Hash table. The main principle is that there is a Hash function in the Hash table, which calculates the bucket number mapped to by looking up the key as a parameter, and assigns the key value to each bucket. Then you still need to traverse the contents of the bucket and return only the matching ctid (line number) with the appropriate Hash code. Since the stored "hash code - ctid" pairs are ordered, this operation can be done efficiently.
At the same time, the Hash index table can be divided into static Hash table and dynamic Hash table. The static Hash table will not increase the number of buckets, while the dynamic Hash table can dynamically increase the number of buckets. PostgreSQL uses the structure of dynamic Hash tables
Hash index structure
Each Hash index structure is as follows. Each Hash index has four types of pages, namely meta page, bucket page, overflow page and bitmap page. Next, we will introduce the relevant data structures of Hash index.
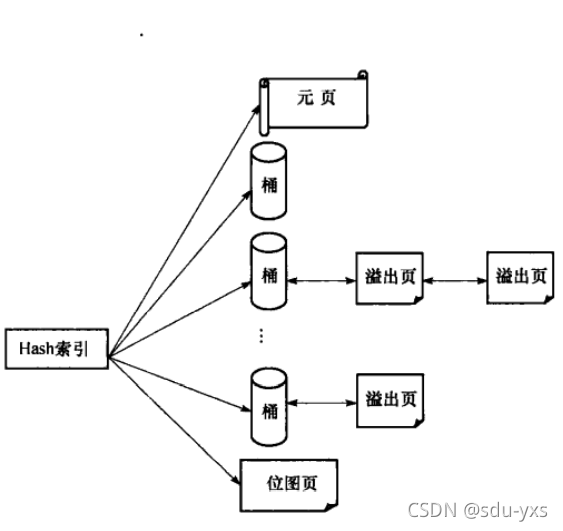
Page structure of Hash
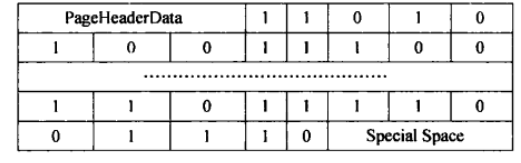
Hash Page structure and B-Tree Similar, and its special space The fields for are populated with HashPageOpaqueData Structure, we start from pg Find out the structure of the source code
typedef struct HashPageOpaqueData
{
BlockNumber hasho_prevblkno; /* Block number of previous page*/
BlockNumber hasho_nextblkno; /* Block number of the next page*/
Bucket hasho_bucket; /* Bucket number belonging to a bucket page*/
uint16 hasho_flag; /* Mark the type of the page */
uint16 hasho_page_id; /* Hash index Id of the page*/
} HashPageOpaqueData;
Yuan page
Each Hash index has a meta page, which is the initial page of the index and does not belong to any bucket. It records the version number of Hash, the number of index tuples recorded by Hash index, bucket information, bitmap and other related information. The information of other pages is also closely related to the meta page. Let's take a look at the data structure of the meta page in pg source code:
typedef struct HashMetaPageData
{
uint32 hashm_magic; /*Hash magic number of the table*/
uint32 hashm_version; /* Hash Version number */
double hashm_ntuples; /*Number of stored tuples*/
uint16 hashm_ffactor; /* Related to Division*/
uint16 hashm_bsize; /* Bucket size*/
uint16 hashm_bmsize; /* The size of the bitmap must be a power of 2 */
uint16 hashm_bmshift; /* log2(Size of bitmap array) */
uint32 hashm_maxbucket; /* Maximum bucket number available */
uint32 hashm_highmask; /* High 16 bit mask of bucket number*/
uint32 hashm_lowmask; /* Lower 16 bit mask of bucket number */
uint32 hashm_ovflpoint; /* Division times */
uint32 hashm_firstfree; /* First possible overflow page number*/
uint32 hashm_nmaps; /* Number of bitmaps */
RegProcedure hashm_procid; /* Hash OID of function*/
uint32 hashm_spares[HASH_MAX_SPLITPOINTS]; /* Total number of overflow pages allocated */
BlockNumber hashm_mapp[HASH_MAX_BITMAPS]; /*The block number of the bitmap*/
} HashMetaPageData;
Bucket page, overflow page, bitmap page
Bucket page: the Hash table consists of multiple buckets, and each bucket consists of one or more pages. The first page of each bucket is called bucket page, and other pages are called overflow pages. Bucket pages are distributed in a power of 2. When the split point recorded in the original page increases, the bucket page increases in a power of 2.
Overflow page: when the content of a tuple exceeds the size of a bucket page, an overflow page needs to be added to the bucket. The overflow page and bucket page are linked through a two-way chain.
Bitmap page: used to manage the overflow page of Hash index and the usage of bitmap page itself. If the tuples on an overflow page are removed, the overflow page will be recycled. The page format of the bitmap is shown in the figure below. It uses bits to indicate whether the bitmap page or overflow page is available. 0 is not available and 1 is available
Advantages and disadvantages compared with B-Tree
advantage
The Hash index has fast execution efficiency and low time complexity. You do not need to go from the root node to the leaf node like the B-Tree index. It can be used for equivalent queries and large field types that the btree index does not support
shortcoming
1. Because the data pointed to by the Hash index is out of order, the Hash index cannot perform range query, but the B + tree can.
2.Hash index cannot be used to avoid data sorting operation. The hash value after hash calculation is stored in the hash index, and the size relationship of the hash value is not necessarily the same as the key value before hash operation.
3 when a large number of Hash conflicts occur, the execution efficiency of Hash index will be reduced and multiple data accesses will be wasted.
summary
The algorithms related to the Hash index of postgreSQL are mainly proposed by Margo Seltzer and Ozan Yigit. The dynamic index table is used. The page structure is composed of meta page, bitmap page, bucket page and overflow page, and the relevant data structure is introduced. In the next article, we will explain the establishment of Hash index.