Posgres-xl is a good thing? Why?
Posgres-xl is based on postgresql database. Posgres can hoist many databases.
It can do oltp, against mysql, mysql has no analysis function function
It can make oltp, counterbalance oracle, oracle ecology is weak, can not be real-time
It supports json well and competes with mongodb, which is used by fewer and fewer people.
It also horribly supports various language extensions, java, javascript, r, python, haskell...
And open source free, simple and powerful without friends...
Posgres-xl is the cluster version of postgresql MPP, continue to hang large data databases.
It's newer than the green pulm version: it's a family with green pulm, both of which are MPP-based postgresql clusters
But the original version is basically the same as postgresql, and the version of green pulm does not move up....It's cheaper than oracle RAC/Teradata and free to use.
It has more resources than hadoop, no GC, high resource utilization rate based on C language, abundant ecosphere and convenient visualization.
It came out early and had a stable version.
Since it's so good, let's briefly introduce it, especially its application in big data.
Posgres-xl is divided into the following components:
GTM is responsible for global transactions
b. coordinator handles distribution execution
c. datanode is responsible for the underlying processing
Both datanode and coordinator are connected to gtm.
The client connects to coordinator to run sql.
coordinator uses gtm to do some transaction functions and distribute them to datanode for execution
Development Direction of Big Data
What is MPP?
MPP (Massively Parallel Processing), a large-scale parallel processing, is a distributed, parallel and structured database cluster with high performance, high availability and high scalability. It can provide a high cost-effective universal computing platform for the management of ultra-large-scale data, and is widely used to support various data warehouse systems and BI systems.
MPP architecture features:
Parallel execution of tasks
Distributed Data Storage (Localization)
Distributed computing
Horizontal expansion
Consideration and Contrast
Characteristics of Oracle Cluster: Full Storage per Node
Mysql hot standby features: master-slave, full storage per node
MPP-Distributed Relational Database
GreenPlum: Encapsulation based on Postgres XL 8.2, which hasn't been upgraded for years.
Mysql Cluster: It's just been out for two years and its stability and performance are poor.
Postgres XL and Postgres LL is the two clustering modes of Postgresql database, Postgres XL is the mainstream MPP nowadays
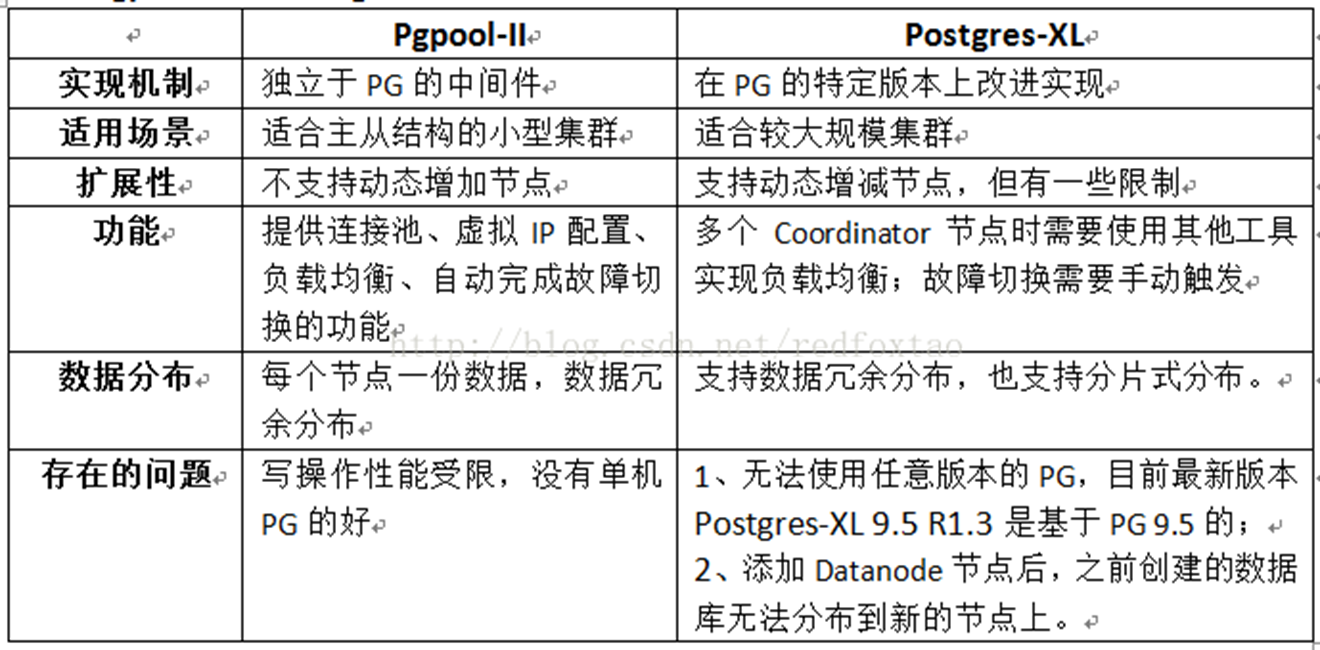
Postgres XL Cluster Architecture
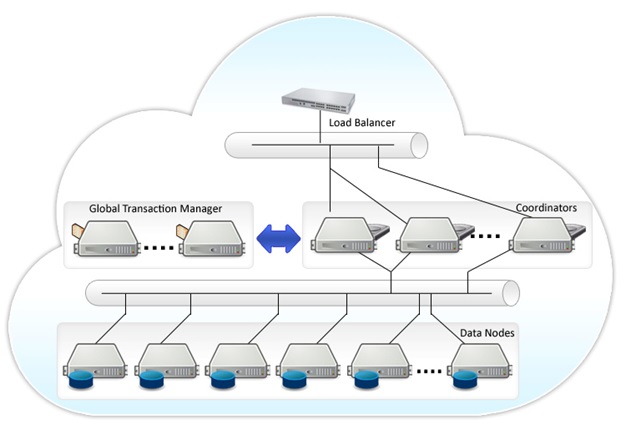
GTM: Global Transaction Manager
Coordinator: Coordinator
Datanode: Data node
GTM-Proxy: GTM Agent
Introduction to Components
Global Transaction Monitor (GTM)
The global transaction manager ensures transaction consistency within the cluster. GTM is responsible for issuing transaction ID s and snapshots as part of its multi-version concurrency control.
Clusters can optionally configure a standby GTM (GTM Standby) to improve availability. In addition, agent GTM can be configured between coordinators to improve scalability and reduce GTM traffic.
GTM Standby
GTM standby node, in pgxc,pgxl, GTM controls all global transaction allocation, if there is a problem, it will cause the whole cluster unavailable, in order to increase availability, increase the standby node. When GTM fails, GTM Standby can be upgraded to GTM to ensure the normal operation of the cluster.
GTM-Proxy
GTM needs to communicate with all Coordinators. To reduce pressure, a GTM-Proxy can be deployed on each Coordinator machine.
Coordinator
The coordinator manages user sessions and interacts with GTM and data nodes. The coordinator parses the query plan, generates the query plan, and sends the next serialized global plan to each component in the statement.
Usually this service and data node are deployed together.
Official Installation

Note: In fact, in a production environment, if you have fewer than 20 clusters, you don't even need to use gtm-proxy.
#1)System Initialization Optimization on every nodes cat >> /etc/security/limits.conf << EOF * hard memlock unlimited * soft memlock unlimited * - nofile 65535 EOF setenforce 0 sed -i 's/^SELINUX=.*$/SELINUX=disabled/' /etc/selinux/config systemctl stop firewalld.service systemctl disable firewalld.service cat >/etc/hosts <<EOF 172.31.1.81 neo4j01 172.31.4.146 neo4j02 172.31.3.178 neo4j03 172.31.8.178 neo4j04 EOF #2)create postgres user on every nodes useradd postgres echo Ad@sd119|passwd --stdin postgres echo 'postgres ALL=(ALL) NOPASSWD: ALL' >>/etc/sudoers ###################################################################### #3)Configure ssh authentication to avoid inputing password for pgxc_ctl(run this commad on every nodes) ###################################################################### su - postgres ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 600 authorized_keys cat ~/.ssh/id_rsa.pub | ssh neo4j01 'cat >> ~/.ssh/authorized_keys' ############################################ #4)Install dependency packages on every nodes# ############################################ sudo yum install -y flex bison readline-devel zlib-devel openjade docbook-style-dsssl gcc bzip2 e2fsprogs-devel uuid-devel libuuid-devel make wget wget -c http://download.cashalo.com/schema/postgres-xl-9.5r1.6.tar.bz2 && tar jxf postgres-xl-9.5r1.6.tar.bz2 cd postgres-xl-9.5r1.6 ./configure --prefix=/home/postgres/pgxl9.5 --with-uuid=ossp --with-uuid=ossp && make && make install && cd contrib/ && make && make install #5)Configuring environment variables on every nodes cat >>/home/postgres/.bashrc <<EOF export PGHOME=/home/postgres/pgxl9.5 export LD_LIBRARY_PATH=\$PGHOME/lib:\$LD_LIBRARY_PATH export PATH=\$PGHOME/bin:\$PATH EOF source /home/postgres/.bashrc #6)create data dirsctory on every nodes mkdir -p /home/postgres/data/ #7) just run command pgxc_ctl on neo4j01 pgxc_ctl # then input command prepare prepare # finally run q to exit q #8) Edit file pgxc_ctl.conf (just do int on neo4j01) vim /home/postgres/pgxc_ctl/pgxc_ctl.conf ########################################### #!/usr/bin/env bash pgxcInstallDir=/home/postgres/pgxl9.5 pgxlDATA=/home/postgres/data #---- OVERALL ----------------------------------------------------------------------------- # pgxcOwner=postgres # owner of the Postgres-XC databaseo cluster. Here, we use this # both as linus user and database user. This must be # the super user of each coordinator and datanode. pgxcUser=postgres # OS user of Postgres-XC owner tmpDir=/tmp # temporary dir used in XC servers localTmpDir=$tmpDir # temporary dir used here locally configBackup=n # If you want config file backup, specify y to this value. #configBackupHost=pgxc-linker # host to backup config file #configBackupDir=$HOME/pgxc # Backup directory #configBackupFile=pgxc_ctl.bak # Backup file name --> Need to synchronize when original changed. #---- GTM ------------------------------------------------------------------------------------ # GTM is mandatory. You must have at least (and only) one GTM master in your Postgres-XC cluster. # If GTM crashes and you need to reconfigure it, you can do it by pgxc_update_gtm command to update # GTM master with others. Of course, we provide pgxc_remove_gtm command to remove it. This command # will not stop the current GTM. It is up to the operator. #---- GTM Master ----------------------------------------------- #---- Overall ---- gtmName=gtm1 gtmMasterServer=neo4j01 gtmMasterPort=6666 gtmMasterDir=$pgxlDATA/gtm1 #---- Configuration --- gtmExtraConfig=none # Will be added gtm.conf for both Master and Slave (done at initilization only) gtmMasterSpecificExtraConfig=none # Will be added to Master's gtm.conf (done at initialization only) #---- GTM Slave ----------------------------------------------- # Because GTM is a key component to maintain database consistency, you may want to configure GTM slave # for backup. #---- Overall ------ gtmSlave=y # Specify y if you configure GTM Slave. Otherwise, GTM slave will not be configured and # all the following variables will be reset. gtmSlaveName=gtm2 gtmSlaveServer=neo4j02 # value none means GTM slave is not available. Give none if you don't configure GTM Slave. gtmSlavePort=6666 # Not used if you don't configure GTM slave. gtmSlaveDir=$pgxlDATA/gtm2 # Not used if you don't configure GTM slave. # Please note that when you have GTM failover, then there will be no slave available until you configure the slave # again. (pgxc_add_gtm_slave function will handle it) #---- Configuration ---- gtmSlaveSpecificExtraConfig=none # Will be added to Slave's gtm.conf (done at initialization only) #---- GTM Proxy ------------------------------------------------------------------------------------------------------- # GTM proxy will be selected based upon which server each component runs on. # When fails over to the slave, the slave inherits its master's gtm proxy. It should be # reconfigured based upon the new location. # # To do so, slave should be restarted. So pg_ctl promote -> (edit postgresql.conf and recovery.conf) -> pg_ctl restart # # You don't have to configure GTM Proxy if you dont' configure GTM slave or you are happy if every component connects # to GTM Master directly. If you configure GTL slave, you must configure GTM proxy too. #---- Shortcuts ------ gtmProxyDir=$pgxlDATA/gtm_proxy #---- Overall ------- gtmProxy=n # Specify y if you conifugre at least one GTM proxy. You may not configure gtm proxies # only when you dont' configure GTM slaves. # If you specify this value not to y, the following parameters will be set to default empty values. # If we find there're no valid Proxy server names (means, every servers are specified # as none), then gtmProxy value will be set to "n" and all the entries will be set to # empty values. #gtmProxyNames=(gtm_pxy1 gtm_pxy2 gtm_pxy3 gtm_pxy4) # No used if it is not configured #gtmProxyServers=(neo4j01 neo4j02 neo4j03 neo4j04) # Specify none if you dont' configure it. #gtmProxyPorts=(6660 6666 6666 6666) # Not used if it is not configured. #gtmProxyDirs=($gtmProxyDir $gtmProxyDir $gtmProxyDir $gtmProxyDir) # Not used if it is not configured. #---- Configuration ---- gtmPxyExtraConfig=none # Extra configuration parameter for gtm_proxy. Coordinator section has an example. gtmPxySpecificExtraConfig=(none none none none) #---- Coordinators ---------------------------------------------------------------------------------------------------- #---- shortcuts ---------- coordMasterDir=$pgxlDATA/coord coordSlaveDir=$pgxlDATA/coord_slave coordArchLogDir=$pgxlDATA/coord_archlog #---- Overall ------------ coordNames=(coord1 coord2 coord3 coord4) # Master and slave use the same name coordPorts=(5432 5432 5432 5432) # Master ports poolerPorts=(6667 6667 6667 6667) # Master pooler ports #coordPgHbaEntries=(192.168.29.0/24) # Assumes that all the coordinator (master/slave) accepts coordPgHbaEntries=(0.0.0.0/0) # the same connection # This entry allows only $pgxcOwner to connect. # If you'd like to setup another connection, you should # supply these entries through files specified below. # Note: The above parameter is extracted as "host all all 0.0.0.0/0 trust". If you don't want # such setups, specify the value () to this variable and suplly what you want using coordExtraPgHba # and/or coordSpecificExtraPgHba variables. #coordPgHbaEntries=(::1/128) # Same as above but for IPv6 addresses #---- Master ------------- coordMasterServers=(neo4j01 neo4j02 neo4j03 neo4j04) # none means this master is not available coordMasterDirs=($coordMasterDir $coordMasterDir $coordMasterDir $coordMasterDir) coordMaxWALsernder=0 # max_wal_senders: needed to configure slave. If zero value is specified, # it is expected to supply this parameter explicitly by external files # specified in the following. If you don't configure slaves, leave this value to zero. coordMaxWALSenders=($coordMaxWALsernder $coordMaxWALsernder $coordMaxWALsernder $coordMaxWALsernder) # max_wal_senders configuration for each coordinator. #---- Slave ------------- coordSlave=n # Specify y if you configure at least one coordiantor slave. Otherwise, the following # configuration parameters will be set to empty values. # If no effective server names are found (that is, every servers are specified as none), # then coordSlave value will be set to n and all the following values will be set to # empty values. #coordSlaveSync=y # Specify to connect with synchronized mode. #coordSlaveServers=(node07 node08 node09 node06) # none means this slave is not available #coordSlavePorts=(20004 20005 20004 20005) # Master ports #coordSlavePoolerPorts=(20010 20011 20010 20011) # Master pooler ports #coordSlaveDirs=($coordSlaveDir $coordSlaveDir $coordSlaveDir $coordSlaveDir) #coordArchLogDirs=($coordArchLogDir $coordArchLogDir $coordArchLogDir $coordArchLogDir) #---- Configuration files--- # Need these when you'd like setup specific non-default configuration # These files will go to corresponding files for the master. # You may supply your bash script to setup extra config lines and extra pg_hba.conf entries # Or you may supply these files manually. coordExtraConfig=coordExtraConfig # Extra configuration file for coordinators. # This file will be added to all the coordinators' # postgresql.conf # Pleae note that the following sets up minimum parameters which you may want to change. # You can put your postgresql.conf lines here. cat > $coordExtraConfig <<EOF #================================================ # Added to all the coordinator postgresql.conf # Original: $coordExtraConfig log_destination = 'stderr' logging_collector = on log_directory = 'pg_log' listen_addresses = '*' max_connections = 50 EOF # Additional Configuration file for specific coordinator master. # You can define each setting by similar means as above. coordSpecificExtraConfig=(none none none none) coordExtraPgHba=none # Extra entry for pg_hba.conf. This file will be added to all the coordinators' pg_hba.conf coordSpecificExtraPgHba=(none none none none) #----- Additional Slaves ----- # # Please note that this section is just a suggestion how we extend the configuration for # multiple and cascaded replication. They're not used in the current version. # #coordAdditionalSlaves=n # Additional slave can be specified as follows: where you #coordAdditionalSlaveSet=(cad1) # Each specifies set of slaves. This case, two set of slaves are # # configured #cad1_Sync=n # All the slaves at "cad1" are connected with asynchronous mode. # # If not, specify "y" # # The following lines specifies detailed configuration for each # # slave tag, cad1. You can define cad2 similarly. #cad1_Servers=(node08 node09 node06 node07) # Hosts #cad1_dir=$HOME/pgxc/nodes/coord_slave_cad1 #cad1_Dirs=($cad1_dir $cad1_dir $cad1_dir $cad1_dir) #cad1_ArchLogDir=$HOME/pgxc/nodes/coord_archlog_cad1 #cad1_ArchLogDirs=($cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir) #---- Datanodes ------------------------------------------------------------------------------------------------------- #---- Shortcuts -------------- datanodeMasterDir=$pgxlDATA/dn_master datanodeSlaveDir=$pgxlDATA/dn_slave datanodeArchLogDir=$pgxlDATA/datanode_archlog #---- Overall --------------- #primaryDatanode=datanode1 # Primary Node. # At present, xc has a priblem to issue ALTER NODE against the primay node. Until it is fixed, the test will be done # without this feature. primaryDatanode=dn1 # Primary Node. datanodeNames=(dn1 dn2 dn3 dn4) datanodePorts=(5433 5433 5433 5433) # Master ports datanodePoolerPorts=(6668 6668 6668 6668) # Master pooler ports datanodePgHbaEntries=(0.0.0.0/0) # Assumes that all the coordinator (master/slave) accepts # the same connection # This list sets up pg_hba.conf for $pgxcOwner user. # If you'd like to setup other entries, supply them # through extra configuration files specified below. # Note: The above parameter is extracted as "host all all 0.0.0.0/0 trust". If you don't want # such setups, specify the value () to this variable and suplly what you want using datanodeExtraPgHba # and/or datanodeSpecificExtraPgHba variables. #datanodePgHbaEntries=(::1/128) # Same as above but for IPv6 addresses #---- Master ---------------- datanodeMasterServers=(neo4j01 neo4j02 neo4j03 neo4j04) # none means this master is not available. # This means that there should be the master but is down. # The cluster is not operational until the master is # recovered and ready to run. datanodeMasterDirs=($datanodeMasterDir $datanodeMasterDir $datanodeMasterDir $datanodeMasterDir) datanodeMaxWalSender=0 # max_wal_senders: needed to configure slave. If zero value is # specified, it is expected this parameter is explicitly supplied # by external configuration files. # If you don't configure slaves, leave this value zero. datanodeMaxWALSenders=($datanodeMaxWalSender $datanodeMaxWalSender $datanodeMaxWalSender $datanodeMaxWalSender) # max_wal_senders configuration for each datanode #---- Slave ----------------- datanodeSlave=n # Specify y if you configure at least one coordiantor slave. Otherwise, the following # configuration parameters will be set to empty values. # If no effective server names are found (that is, every servers are specified as none), # then datanodeSlave value will be set to n and all the following values will be set to # empty values. #datanodeSlaveServers=(node07 node08 node09 node06) # value none means this slave is not available #datanodeSlavePorts=(20008 20009 20008 20009) # value none means this slave is not available #datanodeSlavePoolerPorts=(20012 20013 20012 20013) # value none means this slave is not available #datanodeSlaveSync=y # If datanode slave is connected in synchronized mode #datanodeSlaveDirs=($datanodeSlaveDir $datanodeSlaveDir $datanodeSlaveDir $datanodeSlaveDir) #datanodeArchLogDirs=( $datanodeArchLogDir $datanodeArchLogDir $datanodeArchLogDir $datanodeArchLogDir ) # ---- Configuration files --- # You may supply your bash script to setup extra config lines and extra pg_hba.conf entries here. # These files will go to corresponding files for the master. # Or you may supply these files manually. datanodeExtraConfig=none # Extra configuration file for datanodes. This file will be added to all the # datanodes' postgresql.conf datanodeSpecificExtraConfig=(none none none none) datanodeExtraPgHba=none # Extra entry for pg_hba.conf. This file will be added to all the datanodes' postgresql.conf datanodeSpecificExtraPgHba=(none none none none) #----- Additional Slaves ----- datanodeAdditionalSlaves=n # Additional slave can be specified as follows: where you # datanodeAdditionalSlaveSet=(dad1 dad2) # Each specifies set of slaves. This case, two set of slaves are # configured # dad1_Sync=n # All the slaves at "cad1" are connected with asynchronous mode. # If not, specify "y" # The following lines specifies detailed configuration for each # slave tag, cad1. You can define cad2 similarly. # dad1_Servers=(node08 node09 node06 node07) # Hosts # dad1_dir=$HOME/pgxc/nodes/coord_slave_cad1 # dad1_Dirs=($cad1_dir $cad1_dir $cad1_dir $cad1_dir) # dad1_ArchLogDir=$HOME/pgxc/nodes/coord_archlog_cad1 # dad1_ArchLogDirs=($cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir) #---- WAL archives ------------------------------------------------------------------------------------------------- walArchive=n # If you'd like to configure WAL archive, edit this section. ####################################################### #8) when u first time to setup cluster(run it just on neo4j01) pgxc_ctl -c /home/postgres/pgxc_ctl/pgxc_ctl.conf init all #9) start cluster(run it just on neo4j01) pgxc_ctl -c /home/postgres/pgxc_ctl/pgxc_ctl.conf start all #10) stop cluster(run it just on neo4j01) pgxc_ctl -c /home/postgres/pgxc_ctl/pgxc_ctl.conf stop all #11) check every one is running(run it just on neo4j01) pgxc_ctl monitor all #12) view System Table (run it just on neo4j01) psql -p5432 select * from pgxc_node;
There are two data tables under postgres-XL, replication table and distribute table.
REPLICATION Replication Tables: In each data node, the data of the table is exactly the same, that is to say, when inserting data, the same data will be inserted in each data node. When reading data, you only need to read data on any data node. Small tables are used.
Tabular grammar:
postgres=# create table rep(col1 int,col2 int)distribute by replication;
DISTRIBUTE table: The inserted data will be allocated to different data node nodes to store according to the splitting rules, that is, sharding technology. Each data node saves only part of the data, and the coordinate node can query the complete data view. Distributed storage, large tables, default
postgres=# CREATE TABLE dist(col1 int, col2 int) DISTRIBUTE BY HASH(col1);
How to verify distributed storage?
Insert 100 rows of data:
postgres=# INSERT INTO rep SELECT generate_series(1,100), generate_series(101, 200); postgres=# INSERT INTO dist SELECT generate_series(1,100), generate_series(101, 200);
Psql-p 5432, accessing and querying the complete data view through Coordinater;
Psql-p 5433, 5433 are the ports of Datanode, at which time only the single node is accessed
How to link to the specified database? Look at the following examples
Psql-p 5432 aa, AA is the specified library name, default is postgres library when not specified, equivalent to default library in hive
Query the distribution of this distribution table data at each node:
postgres=# SELECT xc_node_id, count(*) FROM dist GROUP BY xc_node_id; xc_node_id | count ------------+------- -700122826 | 19 352366662 | 27 -560021589 | 23 823103418 | 31 (4 rows)
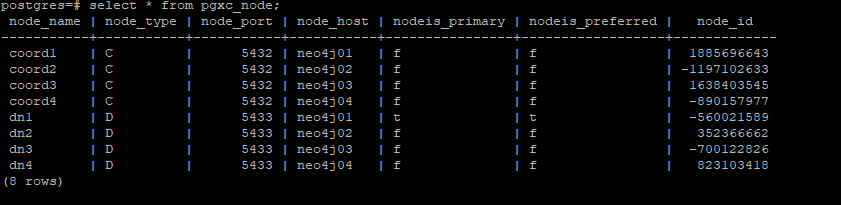
Query ID information for each node
postgres=# select * from pgxc_node;
Let's look at the replication table again.
postgres=# select xc_node_id,count(*) from rep group by xc_node_id; xc_node_id | count ------------+------- -560021589 | 100 (1 row)
Because we query on the neo4j01 node, the id displayed is the id of the neo4j01 node; similarly, if we query on other nodes, we display the id of other nodes. That is to say, when we query the replicated table, it will only walk one node, not many nodes. In view of this feature, if the amount of future data is large, we can take load balancing when querying.
https://www.cnblogs.com/sfnz/p/7908380.html
Psql is a command-line interactive client tool for PostgreSQL. PostgreSQL commands, usages, and grammars are common in the Postgres xl cluster.